NoSql数据库,是怎么解决我们高并发场景下MySql表现的不足
通过前面几天的学习,我们在面对高并发流量时,为了应对大量读写请求,特此将我们的普通存储系统开发成了一套分布式存储系统。主要基于读写分离主从复制以及数据分库分表实现的。不清楚的可以再回去看看啊数据库读写分离方案,实现高性能数据库集群,数据库分库分表后,我们生产环境怎么实现不停机数据迁移
后来又有朋友问我,如果他们的业务还在继续增长,都成国内独角兽的行业了,之前动态分的1024个库表每个表都达到了亿级别的,那时,各方面又出现了各种性能瓶颈了,还需要再分库分表吗?如果你的感受业务都达到了这种维度,那这个时候,我就建议不要再去继续折腾分库分表了,我们用NoSql数据库去缓解我们现有系统的性能瓶颈,并不是直接替换哈。这种情况下我们应该怎么做呢?今天我们就来讲一讲NoSql数据库和我们现有关系型数据库怎么协作来为我们业务服务。
什么是NoSql
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL",指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。那NoSql发展到现在都有哪有比较成熟的且常用的类型呢,下面我来简单列举下我们日常开发中接触比较多的NoSql:
-
Redis :基于KV存储结构,由于是使用内存存储,所以读写性能都极高,也是高于现在的关系型数据库的。一般如果我们业务中对性能要求比较高的话,就可以使用redis。
-
Hbase:列式存储数据库,和我们以行为单位的关系型数据库不一样,它是采取列式存储的,通过id查询速度很快,一般我们的大量离线任务数据就可以存在这里
-
MongoDB:文档型数据库,像一个json对象,其优点就是字段可以随意更换和增加,比如,我们一个复杂业务中可能会频繁的增加字段,而且还很多且期初并不能完全知道有哪些字段,这种的存储业务MongoDB这种文档型数据库非常方便。
为什么要使用NoSql呢?
NoSql的出现解决了我们现有数据库的很多不足之处,例如:
-
解决了关系型数据库在面对大数据量下各种扩容麻烦的问题
-
解决了关系型数据库在性能上表现的不足问题
-
其不用变更原有的数据结构。
你可能会疑问,那NoSql既然这么多优点,那我们直接都换成NoSql的得了,不要关系型数据库mysql这样的了。我并不推荐这么干,其实在我们实际开发中,像MySQL这类的关系型数据库拥有强大的事务以及SQL查询能力,这些是nosql尚不能带给我们的,我们需要关系型数据库的特性才能满足我们的业务需求,其次,你引入nosql的数据库还需要我们的运维人员对其熟悉才能很好的为我们业务服务。所以,NoSql和关系型数据库是互补的关系,它可以用来解决我们现有数据库的不足,从而使得我们业务向着更好的良态去发展。接下来,我们看看该怎么使用NoSql来对我们的关系型数据库进行互补。
使用NoSql来提升写入性能
我们知道我们的关系型数据库数据是存在磁盘上的,其中访问磁盘有两种方式:顺序IO以及随机IO。如果是随机IO访问则会进行磁盘寻道,这个是相当耗时的,一般的,这种随机IO访问磁盘要比顺序IO慢很多很多。所以,这里要想提高我们写入性能的话就需要尽量减少磁盘的随机IO.
比如,我们的MySql的InnoDB存储引擎,它更新binlog相关的操作则是在做顺序IO,而更新数据文件以及更新索引文件则是在做随机IO。这里我解释下,怕有些朋友看不懂,因为日志文件是在后面追加的,所以是顺序IO,而更新数据是需要先找到位置的,所以是随机IO。尽管MySql在这块做了很大的优化,比如WAL啊,写入的时候先写内存啊,但是还是会出现随机IO。
引入NoSQL数据库如何来解决这种问题
大部分NoSQl数据库是基于LSM树的存储引擎,那这个LSM树(Log-Structured Merge Tree)算法比我们MySql的B+ 树在提升写性能上有什么优越呢?下面我们就来看看LSM树是怎么做的。
任何事物一方面的优越都是牺牲其中的某些其他方面所带来的的,LSM树同样是,它是牺牲了一定的读性能来提高写入的性能的,像Hbase、LevelDB以及Cassandra都是基于这种算法来实现的存储引擎,具体是怎么做的呢?
-
在写入数据的时候,首先写入到一个叫MemTable的内存结构中,其中MemTable中数据是按照写入的key来排序的。
-
同时通过写Write Ahead Log的方式将数据备份一份到磁盘上,防止数据丢失。
-
当MemTable数据增加到一定的量级之后,就会被刷新成一个新的文件SSTable(Sorted String Table)。
-
当SSTable文件达到一定数量之后,就将他们进行合并操作,为了减少文件的数量,这个过程速度很快,因为每个SSTable都是有序的。
-
当我们需要从LSM中读取数据的时候,我们首先读取MemTable数据,如果读取不到,再去读取SSTable数据,查找效率很高,因为存储数据是有序的,由于我们有多个SSTable文件,所以我们读取的效率要低于B+数的索引。

所以,现在我们就知道了NoSql数据库对于关系型数据库读写性能的缺陷进行了互补。
引用NoSql提供存储服务
现在有这么一个场景,我在电商网站需要根据某一商品的其中特点去查询出,比如,现在我现在要搜一个华为手机,然后想买我合适尺寸的。这里你应该怎么来查询呢,在传统的关系型数据库中应该是这样的“select * from t_product where name like '华为%'”,其实,这样是用不到我们的name索引的,只有%华为才能用上我们的name索引,而且上面那么的条件搜索,我难道都使用like吗?显然这是不可取的,那这个时候,我这里建议上Elasticsearch。目前,我们公司的酒店搜索就是使用ES的。ES是基于“倒排索引”来实现的,下面我给大家科普下什么是倒排索引
倒排索引意思就是在我们所需要的数据列中进行分词,然后将分词和我们的记录ID行程映射关系,如下图:

首先,我们将我们的商品名称进行分词,然后在和商品ID建立映射关系,如下图所示:
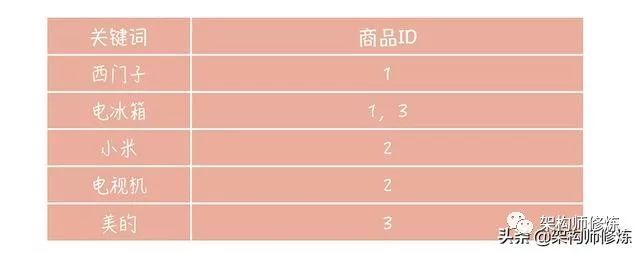
好,当用户搜索(电冰箱)的时候,我们就给他展示商品ID为1和3的商品:西门子电冰箱和电冰箱。
所以,当我们业务中需要大量全文搜索的需求的时候,我们就可以直接使用Elasticsearch这个NoSql数据库
NoSql如何可扩展
我们前面开发了一套基于分库分表的分布式存储系统,但是当我们的业务持续猛增的话,我们的这套存储系统可能在扩展上比较费力。然而,我们如果采用MongoDB来接管,那就方便很多了,比如我们酒店的评论量,每天都增长巨快,MongoDB天生容易支撑可扩展。它具体表现有三个方面:
1,副本集Replica,副本的概念大家应该很明白了,就是冗余多份数据保证数据不丢失的,就和我们前面的主从分离是一个意思。不仅提供读服务还提供了写服务。
2,分片Shard,意思就是将数据分到不同的片上进行存储,联系我们的分库分表就好理解了,对于Sharding我们来说下他的工作原理:
-
MongoDB sharding 一共有三个角色:Shard Server、Config Server、Router Server
-
Shard Server是独立的Mongod 进程,真正存数据的地方
-
Config Server 也是一组Mongod进程,存储元数据的地方,比如那个数据在哪个分片上,这些config中都有
-
Router Server 不存储数据,是一个路由,通过他路由到合适的Shard Server。
即我们来请求的时候,首先到达我们的路由层Router Server,然后路由到Config Server,看数据在哪个Shard 上,最后就直接能到正确的Shard Server 上。
3,负载均衡,MongoDB发现各个Shard Server数据分配不均的话,就会Balancer 进程对数据做重新的分配。如果扩容的时候,直接增加Shard Server就行了,数据会自动分到新的Shard上去。
所以,NoSql 的MongoDB就很好了弥补了我们分库分表太大的业务扩容难的问题。
总结,今天我们分享了NoSql数据库可以帮助我们更好的面对大数据量和高性能,主要讲到了采用顺序IO访问磁盘以提高读写性能,全文检索代替我们复杂且性能低下的like操作,同时,天然的高扩展解决后期大数据扩容难的问题。但是,NoSql并不是说直接能替换我们的MySQL,他们是互补的关系。如果大家喜欢,或者对大家有帮助,就关注我,我会一直分享业界流行技术方案,我们共同学习共同进步。
下一篇预告:数据库以及NoSQL相关的专题
在公众号【架构师修炼】菜单中可自行获取专属架构视频资料,包括不限于 java架构、python系列、人工智能系列、架构系列,以及最新面试、小程序、大前端均无私奉献,你会感谢我的
往期精选
你的成神之路我已替你铺好,没铺你来捶我
数据库分库分表,手把手教你怎么去动态扩容索容
每天百万交易的支付系统,生产环境该怎么设置JVM堆内存大小
数据库分库分表后,我们生产环境怎么实现不停机数据迁移
Zookeeper实现分布式锁详细步骤,你一定要知道
