电商缓存的设计思想
文章目录
- 1 问题背景
- 2 前言
- 3 业务背景
- 4 解决思路
-
- 4.1 B端修改售价时更新缓存,C端查询售价时若查不到也构建缓存
- 4.2 C端查询售价的缓存实现
- 4.3 B端保存售价时的缓存实现
- 4.4 B端和C端都写缓存引发的问题
- 4.5 解决办法
- 4.6 B端只删除缓存是否就没问题了呢
- 4.7 解决办法
- 4.8 分布式锁放在事务里面还是包住事务呢
- 4.9 解决办法
1 问题背景
在电商领域,分为B端和C端。B端是提供给卖家使用的,主要用于商品上下架、库存、订单、营销等等。C端主要是面向广大买家,用于展示商品、商品评论、购物车、结算页、活动展示、推荐商品等等。缓存在电商中的地位尤其重要,今天阐述电商的缓存设计思想。
2 前言
本博客阐述的内容来自笔者工作中,是真实的生产环境,非自学的demo那种或本地搭建虚拟机环境那种。仅供笔者自己做笔记总结使用,如有不正确之处请指出。
本文涉及的文字较多,需要耐心阅读,反复阅读品味
3 业务背景
卖家在B端修改了商品的售价,点击保存。买家在C端浏览商品,点击购买。此时的问题是,商品售价的缓存应该在什么时机更新或淘汰呢?
4 解决思路
4.1 B端修改售价时更新缓存,C端查询售价时若查不到也构建缓存
如本小节标题,这是笔者的做法,
B端修改售价时更新缓存,C端查询售价时若查不到也构建缓存。这是很正常很自然的想法。但并发环境下,是有问题的。
注意:本博客提到的无论是
更新缓存还是构建缓存,本质上就是把最新的值弄到缓存里面。而淘汰缓存指的是删除缓存但并不把最新的值写进缓存。
4.2 C端查询售价的缓存实现
为方便后续的阐述,先来看看C端是怎么查询售价的,流程图如下所示:
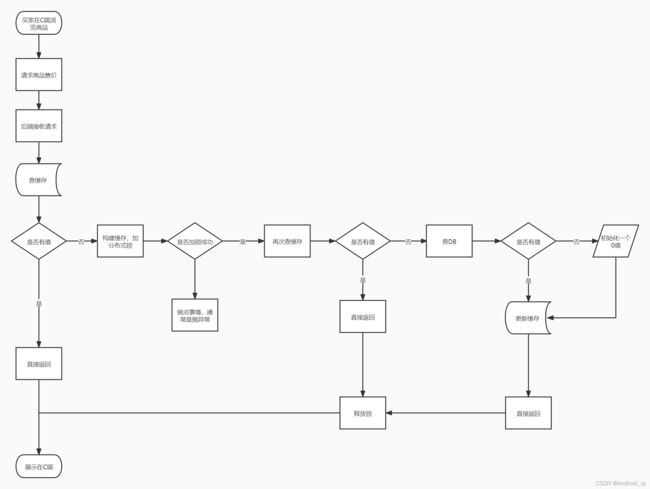
代码如下所示。考虑到C端面向广大的买家,不可以每次查数据都去DB,因此要设计一个缓存,每次请求都先去查缓存。如果缓存没有,那么再去查DB(这一步称为构建缓存)。DB有数据则把值写进缓存,若没有数据要考虑缓存穿透,写一个空对象或具有空值意义的值到缓存里。考虑到并发请求下,不需要每一个请求都去构建缓存,因此给构建缓存的操作加一个分布式锁。因此只需1个线程去构建缓存,降低DB的性能开销。当某个线程拿到锁后,考虑到别的线程可能已经构建好缓存了,因此在查DB前需要再查一遍缓存,有缓存则返回,没有缓存再去查DB构建缓存。
/**
* 查询售价的实现
*/
public BigDecimal getSalePrice(Long skuId) {
// 从缓存查售价
BigDecimal salePrice = cacheService.getSalePrice(skuId);
if (Objects.nonNull(salePrice)) {
return salePrice;
} else {
// 缓存没有证明要构建缓存,加分布式锁
String lockKey = CacheKeyUtils.generateLockKey(skuId);
boolean success = distributedLock.lock(redisKey, 1500L, 3, 500);
if (success) {
try {
// 加锁成功,查DB前再查一次缓存
salePrice = cacheService.getSalePrice(skuId);
if (Objects.nonNull(salePrice)) {
return salePrice;
} else {
// 查DB构建缓存
salePrice = getSalePriceFromDB(skuId);
if (Objects.isNull(salePrice)) {
// 为防止缓存穿透,初始化一个空值进缓存
salePrice = BigDecimal.ZERO;
}
// 更新缓存
cacheService.saveSalePrice(skuId, salePrice);
return salePrice;
}
} finally {
distributedLock.releaseLock(lockKey);
}
} else {
// 加锁失败,做点操作,一般是抛出异常
throw ProductException.GET_REDIS_LOCK_ERROR;
}
}
}
/**
* 更新缓存的具体实现
*/
public void saveSalePrice(Long skuId, BigDecimal salePrice) {
String redisKey = CacheKeyUtils.generateSalePriceKey(skuId);
redisTemplate.opsForValue().set(redisKey, salePrice, 1, TimeUnit.DAYS);
}
4.3 B端保存售价时的缓存实现
代码如下图所示:
public void cacheSalePrice(Long skuId, BigDecimal salePrice) {
String redisKey = CacheKeyUtils.generateSalePriceKey(skuId);
redisTemplate.opsForValue().set(redisKey, salePrice, 1, TimeUnit.DAYS);
}
4.4 B端和C端都写缓存引发的问题
如下图所示:
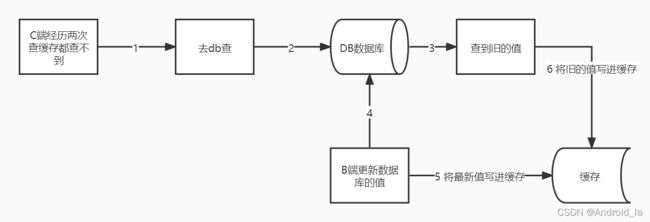
如上图,C端经历两次查询缓存都查不到值,那么就要去查DB,查到旧的值。同时B端将最新值更新到DB并写进缓存。随后C端将拿到旧的值写到缓存。这样会将旧的值存入缓存,除非缓存过期被淘汰,否则每次查询都只会去缓存拿值并且该值是旧的,如此下来生产环境会造成严重的经济损失。这就是两处同时写缓存的坏处,当出现并发情况下,会存在将旧的值写进缓存的场景。
4.5 解决办法
由于存在两处写缓存才会造成上面的问题,那么我们只需要有一处写缓存即可。考虑到主要是C端查询比较多,当它查不到的时候再去构建缓存。因此选择在C端查询的时候写缓存。而在B端只做删除缓存
4.6 B端只删除缓存是否就没问题了呢
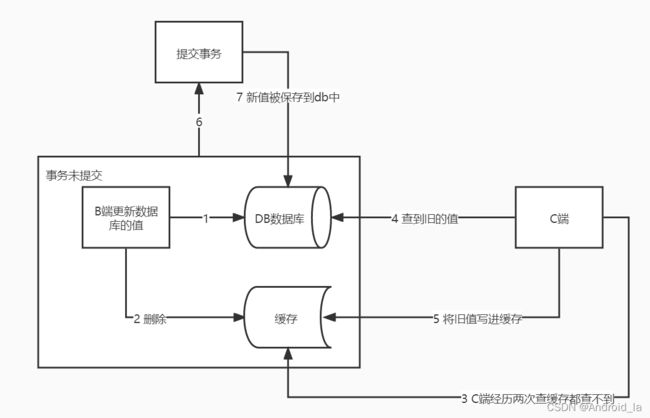
电商的大部分编辑功能中,如编辑商品,编辑之后要保存。保存涉及到更新数据库以及操作缓存。流程图如下所示:
下面是保存商品的伪代码:
@Transactional
public void saveSpu(Spu spu) {
// 更新数据库
spuDao.save(spu);
// 更新缓存
spuCache.delete(spu);
}
如上所示,这是一个保存商品的业务方法,该方法加了@Transactional开启事务的注解,方法实现由更新数据库以及操作缓存组成。当A事务执行到删除缓存,但是未提交。而C端去缓存查商品查不到就去DB查并写到缓存,此时将旧的值写进缓存。A事务提交。最终结果将是缓存里面存的是旧值,DB中存的是新值。
4.7 解决办法
将删除缓存的操作放在事务外面,即使旧值被写进缓存,事务提交完后,执行事务外的删除缓存操作就能将缓存的旧值删除。
4.8 分布式锁放在事务里面还是包住事务呢
为了解决接口的幂等性,常常使用分布式锁。但业务方法常常有事务,再加上大并发量,分布式锁的位置放得不恰当会造成某些问题。
场景:批量插入税费接口。税费针对地区维度,比如广州设置一个税费5元,广西设置一个税费6元。某些情况下,用户连续点了好多次保存接口,导致发出多次请求,从而出现若干线程执行批量插入税费接口。又或者批量插入执行的效率慢,当前的请求还没有执行完,又来了若干次请求。
针对上述场景,如果分布式锁放在事务里面,多个事务查到DB里面没有广州、广西的税费,都执行insert操作。多个事务都未提交,导致大家都不知道有别的事务要将广州、广西的税费插入DB。那么将会有重复的广州、广西的税费插入到DB中。最终结果可能会有DB的锁竞争、出现重复的数据、等待锁超时等等。
4.9 解决办法
用分布式锁包住事务,使得同一时间只有一个线程执行事务操作。