【计算机视觉|人脸建模】深度学习时代的3D人脸重建调查报告
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:3D Face Reconstruction in Deep Learning Era: A Survey
链接:3D Face Reconstruction in Deep Learning Era: A Survey - PubMed (nih.gov)
摘要
随着深度学习的出现和图形处理单元的广泛应用,3D人脸重建已成为生物特征识别最引人入胜的主题。本文探讨了3D人脸重建技术的各个方面。文中讨论了五种技术,分别是
- deep learning(DL,深度学习)
- epipolar geometry(EG,极线几何,对极几何)
- one-shot learning(OSL,单次学习,单样本学习)
- 3D morphable model(3DMM,3D可变形模型)
- shape from shading methods(SFS,基于阴影形状的重建,由灰度恢复深度)
本文深入分析了使用深度学习技术进行3D人脸重建。从软件、硬件、优点和缺点的角度讨论了不同人脸重建技术的性能分析。也讨论了3D人脸重建技术的挑战和未来发展方向。
1 简介
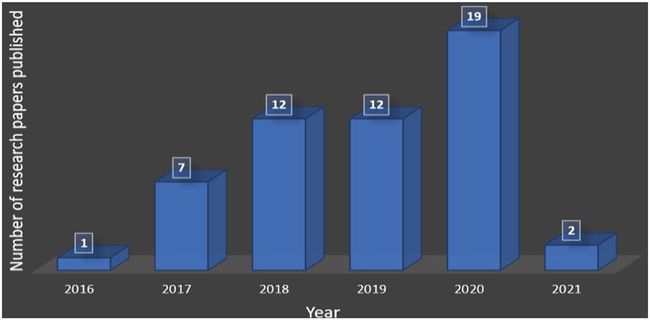
3D人脸重建是生物特征识别中的一个问题,其发展速度因深度学习模型的出现而加快。过去五年里,许多3D人脸识别研究的贡献者都取得了进步(见图1)。开发了诸如再演绎和语音驱动的动画、面部操纵、视频配音、虚拟化妆、投影映射、面部衰老以及面部替换等各种应用[1]。
图1:2016-2021年在3D人脸重建中发表的研究论文数量
3D人脸重建面临许多挑战,如遮挡物移除、化妆移除、表情转移和年龄预测。
遮挡物可以是内部的或外部的。一些众所周知的内部遮挡物包括头发、胡须、髭须和侧脸。外部遮挡物发生在其他物体/人遮挡了面部的一部分,例如眼镜、手、瓶子、纸张和口罩[2]。
推动3D人脸重建研究增长的主要原因是多核心中央处理器(CPU)、智能手机、图形处理器(GPU)以及诸如谷歌云平台(GCP)、亚马逊网络服务(AWS)和微软Azure等云应用的可用性[3-5]。
3D数据用
- voxels(立体像素,体素,pixel+volume+element)
- point cloud(点云)
- a 3D mesh that GPUs can process(可以被GPU处理的3D网格)
表示(见图2)。近期,研究人员已经开始进行4D人脸识别的研究[6, 7]。图3展示了3D人脸重建的分类。
图2:3D人脸图像:a RGB图像、b深度图像、c网格图像、d点云图像、e体素图像
图3:3D人脸重建的分类

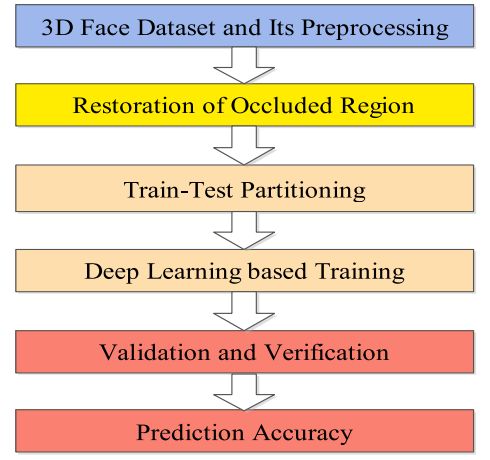
1.1 3D人脸重建的一般框架
基于3D重建的面部识别框架涉及预处理、深度学习和预测。图4显示了3D面部修复技术涉及的阶段,可以获取各种形式的3D图像,所有这些都有基于需要的不同预处理步骤。
图4:3D人脸重建问题的一般框架[9]
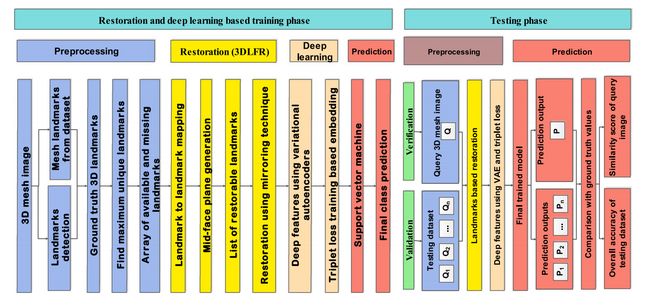
面部对齐(Face alignment)可能会也可能不会在发送到重建阶段之前进行。Sharma和Kumar [2, 8, 9]在他们的重建技术中就并未使用面部对齐。
可以使用各种技术进行面部重建,例如基于3DMM的重建、基于EG的重建、基于OSL的重建、基于DL的重建和基于SFS的重建。此外,预测阶段需要作为面部重建的结果。预测可以运用于面部识别、情感识别、性别识别或年龄估计的应用。
1.2 词云
词云展示了3D人脸重建的前100个关键词(见图5)。
图5:3D人脸重建文献的词云

从这个词云中,与面部重建算法相关的关键词如"3D面部"、“像素”、"图像"和"重建"被广泛使用。"3D人脸重建"这个关键词吸引了研究人员作为面部识别技术的问题领域。
面部重建涉及完成被遮挡的面部图像。大多数3D面部重建技术在重建过程中使用2D图像[10-12]。最近,研究人员已经开始研究网格和体素图像[2, 8]。生成对抗网络(GANs)用于2D面部的面部交换和面部特征修改[13]。这些还有待使用深度学习技术来探索。
该论文的动机在于对深度学习中的3D点云(deep learning of 3d point clouds)[14]和行人重识别(person re-identifcation)[15]进行详细的研究调查。如图1所示,在过去的五年中,3D面部研究随着时间的推移而不断增长。大多数重建研究都偏好使用基于GAN的深度学习技术。本文旨在研究使用深度学习技术进行3D面部重建及其在实际场景中的应用。
本文的贡献包括:
- 讨论了各种3D面部重建技术的优缺点。
- 提出了3D面部重建技术的硬件和软件要求。
- 调查了3D面部重建的数据集、性能评估指标和适用性。
- 探讨了当前和未来3D面部重建技术面临的挑战。
本文的剩余部分组织如下:第2节介绍了3D人脸重建技术的变体。第3节讨论了性能评估指标,第4节介绍了用于重建技术的数据集。第5节讨论了重建过程的工具和技术。第6节探讨了3D面部重建的潜在应用。第7节总结了当前的研究挑战和未来的研究方向。第8节提供了结论性的评论。
2 3D人脸重建技术
3D人脸重建技术被广泛地分为五个主要类别,包括基于3D可变形模型(3DMM)的重建、基于深度学习(DL)的重建、基于极线几何(EG)的重建、基于单次学习(OSL)的重建和基于阴影形状(SFS)的重建。图6展示了3D面部重建技术。大多数研究人员正在研究混合(hybrid)面部重建技术,并被认为是第六类。
图6:3D人脸重建技术

2.1 基于3DMM的重建
3D可变形模型(3DMM)是用于面部外观和形状的生成模型 [16]。要生成的所有面部都处于密集的点对点对应关系中,这可以通过面部注册过程实现。形态面(morphs)通过密集对应关系生成。该技术的重点是将面部颜色和形状与其他因素(如照明,亮度,对比度等)分离开来 [17]。
3DMM由Blanz和Vetter [18]引入。文献中提供了3DMM的变体 [19-23]。这些模型使用低维表示来表达面部表情、纹理和身份。Basel Face Model(BFM)是可公开获取的3DMM模型之一。该模型是通过将与从迭代最近点(ICP)和主成分分析(PCA)得到的扫描面对应的模板网格进行注册而构建的 [24]。
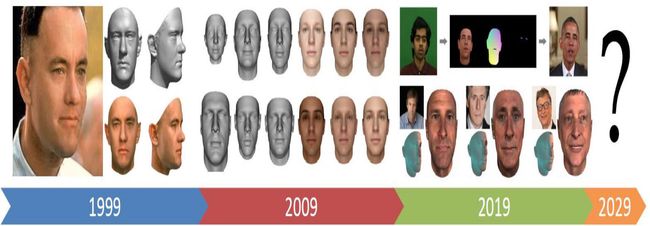
图7展示了在过去20年中3DMM的逐步改进情况 [18,25-28]。图中呈现了来自Blanz和Vetter 1999年原始论文[18]、2009年第一个公开可用的可变形模型[25]、最先进的面部再现结果[28]和GAN模型[27]的结果。
图7:过去二十年中3DMM的逐步改进 [17]
Maninchedda等人 [29] 提出了一种基于3D极线几何的、解决人脸被眼镜遮挡情况下的自动重建方法。他们提出了一种变化分割模型(variational segmentation model),可以表示各种各样的眼镜。
Zhang等人 [30] 提出了从RGB-D传感器捕获的单个数据帧中重建密集的3D人脸点云的方法。使用K-Means聚类算法捕获了面部区域的初始点云。然后使用人工神经网络(ANN)估计点云的邻域。
此外,径向基函数(RBF)插值被用来实现以点云为中心的3D人脸的最终逼近。
Jiang等人 [31] 基于3DMM提出了一种3D人脸恢复算法(PIFR)。输入图像被规范化以获取更多有关面部标志可见性的信息。该方法的优点是具有位姿不变的面部重建能力。然而,重建需要在大位姿下进行改进。
在计算机视觉领域中,大位姿(large pose)通常指人脸或物体在图像中的朝向、角度或旋转角度等因素发生较大变化的情况,例如旋转、缩放和平移等。在人脸重建中,大位姿通常指面部被摆放在非正面朝向,或者面部被部分遮挡的情况。这些情况都增加了面部识别和重建的难度。
Wu等人 [32] 提出了一种使用单张图像进行3D面部表情重建的技术。使用级联回归框架计算3DMM的参数。在特征提取阶段,使用梯度方向直方图(HOG)和关键点偏移。
Kollias等人 [33] 提出了一种新技术,用于合成面部表情和正/负情感程度。基于价值-唤醒(VA)技术,从4DFAB数据集[34]中注释了600K帧。该技术适用于野外面部数据集。但是,4DFAB数据集并非公开可用。
Lyu等人[35]提出了一个由2D图像生成高分辨率图像的Pixel-Face数据集。为进行3D面部重建,提出了Pixel-3DM。然而,该研究未考虑外部遮挡情况。
2.2 基于DL的重建
3D生成对抗网络(3DGAN)和3D卷积神经网络(3DCNN)是用于3D面部重建的深度学习技术 [27]。这些方法的主要优点是高保真度和更高的准确性和平均绝对误差(MAE)表现。然而,训练GAN需要很长时间。可以通过面部身份保持(FIP)方法在规范视图下进行面部重建 [36]。
Tang等人 [37] 引入了一种用于在新的照明情况下生成图像的多层生成式深度学习模型。在面部识别中,训练语料库负责为多视角感知器提供标签。使用面部几何从单个图像扩充合成数据[38]。
Richardson等人 [39] 提出了上述重建的无监督版本。使用有监督CNN实现面部动画任务[40]。使用深度卷积神经网络(DCNNs)来恢复3D纹理和形状。在[41]中,面部纹理恢复提供了比3DMM [42] 更好的细节。
图8展示了使用遮挡区域的恢复进行3D面部识别的不同阶段。
图8:采用恢复技术进行3D面部识别的不同阶段 [9]
Kim等人 [26] 提出了一种基于深度卷积神经网络的3D面部识别算法。使用3D面部增强技术,可以使用3D面部的单次扫描合成各种面部表情。基于迁移学习的模型训练速度更快。然而,当3D点云图像转换为2.5D图像时,会丢失3D数据。
2.5D通常是指深度信息被限制为单个平面(例如2D图像),这个平面上的每个像素点都有与之相关联的深度值。在3D人脸识别中,将3D面部数据转换为2.5D图像的过程是将每个3D点的深度值映射到2D图像上对应的像素点上,从而得到每个像素点的深度信息。这种方法可以减少数据的维度,简化计算和减小储存空间的需求,但是会丢失3D信息的一部分,因此可能影响面部识别的精度。
Gilani等人 [43] 提出了一种用于开发标注的3D人脸大语料库的技术。他们训练了一个面部识别3D卷积神经网络(FR3DNet),用于识别100K人的310万张3D人脸。测试是基于1853人的31,860张图像进行的。
Thies等人[44]提出了一种神经语音木偶技术(neural voice puppetry technique),用于从源输入音频生成逼真的输出视频。这基于使用潜在的3D模型空间的DeepSpeech循环神经网络。Audio2ExpressionNet负责将输入音频转换为特定的面部表情。
Li等人 [45] 提出了SymmFCNet,一种对称一致的卷积神经网络,用于使用另一半面部进行重建缺失像素。SymmFCNet包括照明重新加权变形和生成重建子网。依赖多个网络是一个显著的缺点。
Han等人 [46] 提出了一个素描系统,通过修改面部特征创建3D漫画照片。设计了一种非传统的深度学习方法来获取顶点显着性图。他们使用FaceWarehouse数据集[20]进行训练和测试。优点是将2D图像转换为3D面部漫画模型。然而,在有眼镜的情况下,漫画质量会受到影响。此外,重建会受到不同光照条件的影响。
Moschoglou等人[47]实现了一个自编码器,如3DFaceGAN,用于建模3D面部表面分布。重建损失和对抗损失用于生成器和鉴别器。缺点是GAN难以训练,不能应用于实时3D面部解决方案。
2.3 基于EG的重建
基于极线几何的面部重建方法使用同一主体的多个非合成透视图像生成单个3D图像 [48]。这些技术的主要优点是良好的几何保真度。校准相机和正交图像是这些技术所面临的两个主要挑战。图9展示了从中心视角和子孔径图像中获得的水平和垂直极线平面图像(EPIs)。
图9:a 3D面部曲线对应的极线平面图像,b 水平EPI,c 垂直EPI [48]
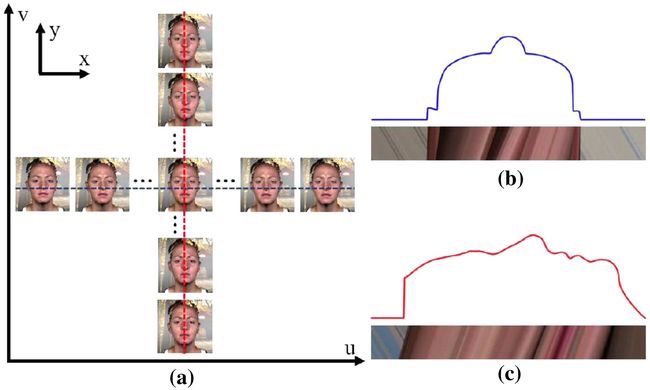
Anbarjafari等人 [49] 提出了一种新的技术,用于生成由手机摄像头捕获的3D面部。总共使用了68个面部标记将面部划分为四个区域。在纹理创建、加权区域创建、模型变形和合成过程中使用了不同的阶段。这种技术的主要优点是从特征点获得的良好泛化能力。但是,它依赖于具有良好头部形状的数据集,这会影响整体质量。
2.4 基于OSL的重建
基于单次学习的重建方法使用个体的单个图像来重新创建3D识别模型 [50]。该技术利用每个主体的单个图像来训练模型。因此,这些技术训练速度更快,同时也产生了有希望的结果 [51]。然而,这种方法无法推广到视频。现在,基于单次学习的3D重建是一个活跃的研究领域。
为了训练从2D到3D图像的映射模型,需要真实的3D模型。一些研究者使用深度预测来重建3D结构 [52, 53]。而其他技术直接预测3D形状[54, 55]。很少有研究通过利用一个2D图像进行3D面部重建[38,39]。
通过使用深度神经网络和模型参数向量,可以获得3D面部的最佳参数值。在[56,57]上已经取得了主要的改进。然而,这种方法无法充分处理姿势变化。这种技术的主要缺点是创建多视角3D面部和重建降级。图10展示了基于单次拍摄的面部重建技术的一般框架。
图10:基于OSL的3D人脸重建的总体框架
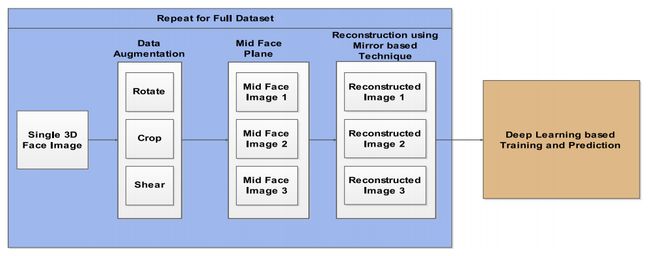
Xing等人 [58] 提出了一种使用单个图像进行3D面部重建的技术,而不考虑真实的3D形状。面部模型渲染被用于重建过程中。使用微调引导方法发送反馈以进一步改善渲染质量。这种技术提供了从2D图像重建3D形状的方法。然而,缺点是使用刚体变换进行预处理。
2.5 基于SFS的重建
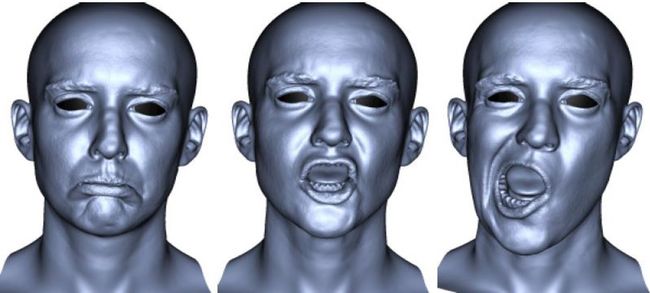
形状恢复(SFS)方法基于从阴影和照明线索中恢复3D形状[59, 60]。它使用产生良好形状模型的图像。然而,当形状估计对目标的阴影产生干扰时,遮挡无法处理。它在非正面面部视图下的光照下运作良好(见图11)。
图11:3D面部形状恢复 a 2D图像,b 3D深度图像,c 纹理投影,d 反照率直方图[59]

Jiang等人[61]的方法受到使用RGB-D和单目视频进行面部动画的启发。通过将参数模型拟合到输入图像,对目标3D面部进行粗略估计的计算完成。这种技术的主要缺点是从单个2D图像重建3D图像。相反,SFS技术依赖于关于面部几何的预定义知识,例如面部对称性。
2.6 基于混合学习的重建
基于混合学习的重建(Hybrid Learning‑based Reconstruction)
Richardson等人[38]提出了一种使用几何形状生成具有逼真面部图像的数据库的技术。使用ResNet模型[62]构建了所提出的网络。这种技术无法恢复具有不同面部属性的图像。它未能将训练过程推广到新的面部生成。
Liu等人[63]提出了一种使用3DMM混合和形状恢复方法进行3D面部重建的技术。绘制了平均绝对误差(MAE)以达到重建误差的收敛。
Richardson等人[39]提出了一种单次学习模型,用于提取粗到细的面部形状。使用CoarseNet和FineNet进行粗面部特征的恢复。高细节面部重建包括单个图像中的皱纹。然而,它无法推广训练数据中可用的面部特征。对合成数据的依赖是另一个缺点。
Jackson等人[51]提出了一种基于CNN的模型,用于使用单个2D面部图像重建3D面部几何。此方法不需要任何类型的面部对齐。它适用于各种类型的表情和姿势。
Tewari等人[64]提出了一种基于卷积自编码器网络的生成模型,用于面部重建。他们使用了AlexNet [65]和VGGFace [66]模型。然而,在有胡须或外部物体等遮挡情况下,该方法失败了。
Dou等人[67]提出了一种基于深度神经网络(DNN)的技术,用于使用单个2D图像进行端到端的3D面部重建。多任务损失函数和融合CNN被混合用于人脸识别。这种方法的主要优点是具有端到端模型的简化框架。然而,该方法的缺点是依赖于合成数据。
Han等人[68]提出了一种基于CNN深度学习的草图系统,用于3D面部和卡通建模。通常,通过MAYA和ZBrush生成丰富的面部表情。然而,它包括基于手势的用户交互。形状级输入与完全连接层的输出相结合,以生成双线性输出。
Hsu等人[69]提出了两种不同的跨姿态人脸识别方法。一种技术基于3D重建,另一种方法使用深度CNN构建。面部组件是从2D面部库构建的。使用2D面部组件重建了3D表面。基于CNN的模型可以轻松处理野外特征。基于3D组件的方法不具有很好的泛化性。
Feng等人[48]开发了FaceLFnet,使用Epipolar Plane Images(EPI)来恢复3D面部。他们使用CNN恢复垂直和水平3D面部曲线。使用3D面部合成了逼真的光场图像。在训练过程中使用了80个不同人的14K面部扫描,共计1100万个面部曲线/EPI。该模型是医学应用的优选选择。然而,这种技术需要大量的极线平面图像曲线。
Zhang等人[70]提出了一种使用可塑面孔和稀疏光度立体结合的3D面部重建技术。优化技术用于每个像素的照明方向以及高精度照明。在输入图像和几何代理上执行语义分割,以重建皱纹、眉毛、痣和毛孔等细节。平均几何误差用于验证重建质量。这种技术依赖于照射在面部上的光。
Tran等人[71]提出了一种基于凸起映射的3D面部重建技术。使用卷积编码器-解码器方法估计凸起映射。最大池化和修正线性单元(ReLU)与卷积层一起使用。该技术的主要缺点是未优化的软对称实现较慢。
Feng等人[72]提出了一个由135个人的2K张面部图像组成的基准数据集。在所提出的数据集上评估了五种不同的3D面部重建方法。
Feng等人[73]提出了一种基于纹理坐标UV位置图的3D面部重建技术,称为位置图回归网络(PRN)。CNN从单次2D图像回归3D形状。加权损失函数在卷积过程中使用不同的权重形式,即权重掩码。UV位置图也可以泛化。然而,在实际场景中应用困难。
Liu等人[74]提出了一种基于编码器-解码器的网络,用于从2D图像回归3D面部形状。联合损失基于3D面部重建和识别误差计算。然而,联合损失函数会影响面部形状的质量。
Chinaev等人[75]开发了一种基于CNN的模型,用于使用移动设备进行3D面部重建。在测试阶段使用了MobileFace CNN。这种方法在移动设备上的训练速度很快,可以实时应用。然而,在预处理阶段使用可塑模型对3D面部进行注释是昂贵的。
Gecer等人[27]提出了一种基于DCNN和GAN的3D面部重建技术。在UV空间中,GAN用于训练生成器生成面部纹理。在可微分渲染器和GAN上制定了非传统的3DMM拟合策略。
Deng等人[76]提出了一种基于CNN的单次拍摄面部重建方法,用于弱监督学习。感知级和图像级损失结合。该技术的优点是大姿态和遮挡不变性。然而,在预测阶段,模型的置信度在遮挡方面较低。
Yuan等人[77]提出了一种使用3DMM和GAN的3D面部恢复技术,用于遮挡的面部。使用局部鉴别器和全局鉴别器验证3D面部的质量。面部特征点的语义映射导致在遮挡下生成合成面部。相比之下,多个鉴别器会增加时间复杂度。
Luo等人[78]实现了一种用于3D面部恢复的Siamese CNN方法。他们利用加权参数距离成本(WPDC)和对比成本函数验证重建方法的质量。然而,在野外没有测试面部识别,训练图像数量较少。
Gecer等人[79]提出了一种基于GAN的方法,用于合成高质量的3D面部。使用条件GAN进行表情增强。从300W-LP数据集中随机综合了10K个新的个体身份。该技术生成具有精细细节的高质量3D面部。然而,GAN难以训练,不能应用于实时解决方案。
Chen等人[80]提出了一种使用自我监督的3DMM可训练VGG编码器的3D面部重建技术。使用两阶段框架回归3DMM参数以重建面部细节。在正常遮挡下生成具有良好质量的面部。使用UV空间捕获面部细节。然而,该模型在极端遮挡、表情和大姿态上失败。CelebA [81]数据集用于训练,CelebA与LFW [82]数据集一起用于测试过程。
Ren等人[83]为3D面部点视频去模糊开发了一个编码器-解码器框架。通过渲染分支和3D面部重建预测身份知识和面部结构。面部去模糊是在处理姿态变化的视频时的挑战。该技术的主要缺点是高计算成本。
Tu等人[10]开发了一种用于2D面部图像的2D辅助自我监督学习(2DASL)技术。使用关键点的噪声信息来提高3D面部模型的质量。开发了自我批评学习来改善3D面部模型。两个数据集,即AFLW-LFPA [84]和AFLW2000-3D [85],用于3D面部恢复和面部对齐。这种方法适用于野外2D面部以及嘈杂的关键点。然而,它依赖于2D到3D关键点注释。
Liu等人[86]提出了一种用于生成姿态和表情标准化(PEN)3D面部的自动方法。该技术的优点是从单个2D图像进行重建和3D面部识别在姿态和表情上不变。然而,它不具备遮挡不变性。
Lin等人[24]实现了一种基于野外单次图像的3D面部重建技术。使用图卷积网络生成高密度面部纹理。FaceWarehouse [20]以及CelebA [81]数据库用于训练。
Ye等人[87]提出了一个大规模的3D漫画数据集。他们生成了一个基于PCA的线性3D可塑建模,用于漫画形状。从pinterest.com和WebCaricature数据集[88]中收集了6.1K个肖像漫画图像。已合成高质量的3D漫画。然而,对于遮挡的输入面部图像,漫画的质量不好。
Lattas等人[89]提出了一种使用任意图像生成高质量3D面部重建的技术。基于几何和反射率收集了200个不同主题的大规模数据库。训练图像转换网络以估计高光和漫反射反照率。该技术使用GAN生成高分辨率的头像。然而,它无法生成深色皮肤主题的头像。
Zhang等人[90]提出了一种用于漫画的自动关键点检测和3D面部恢复技术。使用漫画的2D图像来回归3D漫画的方向和形状。ResNet模型用于将输入图像编码为潜空间。解码器与全连接层一起用于在漫画上生成3D关键点。
Deng等人[91]提出了一种DISentangled precisely-COntrollable(DiscoFaceGAN)潜在嵌入,用于表示具有各种姿势、表情和照明的虚假人物。通过将渲染面孔与真实面孔进行比较,采用对比学习来促进解缠绕。面部生成在表情、姿势和照明上是精确的。在低光和极端姿势下生成模型的质量较低。
Li等人[92]提出了一种3D面部重建技术,用于估计3D面部的姿势,使用粗到细估计。他们使用自适应加权方法生成3D模型。该技术的优点是对局部遮挡和极端姿势具有鲁棒性。然而,当遮挡时2D和3D关键点被错误估计时,模型会失败。
Chaudhuri等人[93]提出了一种深度学习方法,用于训练个性化的动态反照率图和表情混合形状。以照片逼真的方式生成3D面部恢复。面部解析损失和混合形状梯度损失捕捉了重建混合形状的语义含义。这种技术在野外视频中进行训练,并生成了高质量的3D面部和面部运动从一个人到另一个人的转移。它在外部遮挡下表现不佳。
Shang等人[94]提出了一种自我监督学习技术,用于遮挡感知视图合成。使用三个不同的损失函数,即深度一致性损失、像素一致性损失和基于关键点的极线损失,进行多维一致性。重建是通过遮挡感知方法完成的。它在外部遮挡(如手、眼镜等)下表现不佳。
Cai等人[95]提出了Attention Guided GAN(AGGAN),能够使用2.5D图像进行3D面部重建。AGGAN使用自编码器技术从深度图像生成3D体素图像。使用基于注意力的GAN进行2.5D到3D面部映射。该技术处理广泛的头部姿势和表情。然而,在大张嘴的情况下,无法完全重建面部表情。
Xu等人[96]提出了一种训练头部几何模型而不使用3D基准数据的方法。使用CNN训练具有头部几何的深度合成图像,而无需优化。使用GAN和3D变形进行头部姿势操作。
表1呈现了3D面部重建技术的比较分析。
表1:3D面部重建技术的比较分析
表2总结了3D面部重建技术的优缺点。
表2:3D面部重建技术的优缺点比较
3 性能评估标准
性能评估措施对于了解训练模型的质量很重要。有多种评估指标,包括平均绝对误差(MAE)、均方误差(MSE)、归一化平均误差(NME)、均方根误差(RMSE)、交叉熵损失(CE)、曲线下面积(AUC)、交集联合比(IoU)、峰值信噪比(PSNR)、接收器操作特征曲线(ROC)和结构相似性指数(SSIM)。
表3总结了3D面部重建技术的性能评估措施。
表3:从性能指标评估3D面部重建技术
在面部重建过程中,最重要的性能评估措施是MAE、MSE、NME、RMSE和对抗性损失。这些是五个广泛使用的性能评估措施。对抗性损失自2019年以来随着GAN在3D图像中的出现而被使用。
4 用于人脸识别的数据集
表4展示了用于3D面部重建技术的数据集的详细描述。
表4:所用数据集的详细说明
对不同数据集的分析突显了一个事实,即大多数3D面部数据集都是公开可用的数据集。与2D面部公开数据集相比,它们没有足够数量的图像来训练模型。这使得3D面部的研究更加有趣,因为可扩展性因素尚未得到测试,已经成为一个活跃的研究领域。值得一提的是,仅有三个数据集,即Bosphorus、Kinect-FaceDB和UMBDB数据集,具有被遮挡的图像,用于遮挡去除。
5 用于3D人脸重建的工具和技术
表5介绍了在图形处理单元(GPU)的硬件、随机存取存储器(RAM)的大小、中央处理单元(CPU)以及简要应用方面使用的技术。比较突显了深度学习在3D面部重建中的重要性。GPU在基于深度学习的模型中扮演着至关重要的角色。随着Google Collaboratory的出现,GPU现在是免费可用的。
表5:3D人脸重建技术、硬件和应用的比较分析
6 应用
基于人工智能的AI+X技术[128],其中X是面部识别领域的专业知识,大量应用受到3D面部重建的影响。面部操纵、语音驱动的动画和再现、视频配音、虚拟化妆、投影映射、面部替换、面部老化和医学上的3D打印是一些众所周知的应用。这些应用在接下来的子章节中将会讨论。
6.1 面部操纵
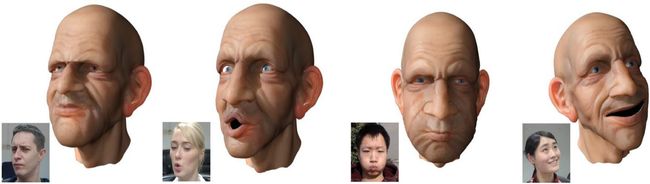
游戏和电影行业使用基于视频的面部动画中的面部克隆或操纵。表情和情感通过视频流从用户传输到目标角色。当艺术家为电影中的动画角色配音时,3D面部重建可以帮助将表情从艺术家传输到角色。图12展示了数字化头像实时演示中的操纵示例[129,130]。
图12:实时人脸木偶戏[129]
6.2 语音驱动的动画和再现
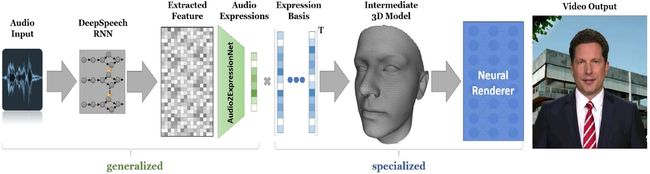
Zollhofer等人[1]讨论了各种基于视频的面部再现工作。大多数方法依赖于使用参数化面部模型对源脸和目标脸进行重建。图13展示了神经语音操纵的管道架构[44]。音频输入通过基于循环神经网络的深度语音进行特征提取。此外,基于自动编码器的表情特征与3D模型一起传输到神经渲染器,以接收语音驱动的动画。
图13:神经语音木偶
6.3 视频配音
配音是电影制作中的重要部分,其中在原始场景中添加或替换音频轨道。原始演员的声音需要用配音演员的声音替换。这个过程需要对配音演员进行充分的训练,以使其的音频与原始演员的口型同步 [131]。为了最小化视觉配音中的差异,需要对口型进行动态重建,以补充配音演员所说的对话。这涉及将配音演员的口部运动与演员的嘴部运动进行映射 [132]。因此,使用图像交换或传递参数的技术。
图14展示了VDub [131]和启用现场配音的Face2Face的视觉配音。图14显示了DeepFake在6.S191中的示例 [133],展示了课程讲师使用深度学习将自己的声音配成著名人士的示例。
图14:6.S191中的DeepFake示例[133]
6.4 虚拟化妆
虚拟化妆在在线平台上的使用非常普遍,用于会议和视频聊天,其中呈现出漂亮的外观是不可或缺的。它包括数字图像变化,如涂抹合适的口红、面罩等。这对美容产品公司非常有用,因为他们可以进行数字广告,消费者可以在他们的图像上实时体验产品的效果。它是通过使用不同的重建算法实现的。
合成的虚拟纹身已经显示出可以调整到面部表情[134](见图15a)。
Viswanathan等人[135]提出了一个系统,在该系统中,将两个面部图像作为输入,一个为睁眼状态,另一个为闭眼状态。提出了一种增强现实的面部,用于向面部添加一个或多个化妆形状、层、颜色和质地。
Nam等人[136]提出了一种基于增强现实的唇部化妆方法,该方法使用像素单位化妆与多边形单位化妆相比,如图15b所示。
图15:a 合成虚拟纹身[134]和,b 基于增强现实的像素单位口红化妆[136]
6.5 投影映射
投影映射使用投影仪来修改真实世界图像的特征或表情。这种技术用于给静态图像带来生命,并给它们提供视觉展示。在2D和3D图像中使用不同的方法进行投影映射,以改变人的外貌。图16展示了名为Face-Forge [137]的实时投影映射系统。
图16:基于FaceForge的实时投影映射[137]

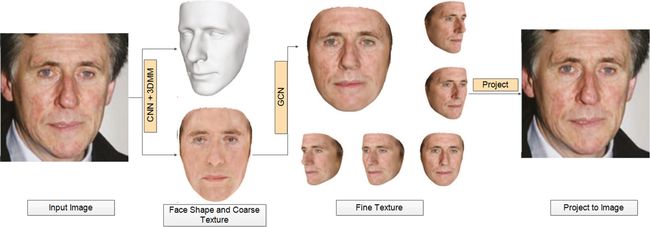
Lin等人[24]提出了一种3D面部投影技术,通过将输入图像通过CNN并将信息与3DMM结合,从而得到面部的精细纹理(见图17)。
图17:结合3DMM模型的2D面投影映射[24]
6.6 面部替换
面部替换通常在娱乐行业中使用,其中源脸部被目标脸替换。这种技术基于身份、面部特征和两个脸部(源和目标)的表情等参数。源脸部需要被渲染,以使其符合目标脸的条件。Adobe After Effects是电影和动画行业中广泛使用的工具,可以帮助进行面部替换[138](见图18)。
图18:表情不变的人脸替换系统[138]

6.7 面部老化
面部衰老是将3D面部图像转换为4D的有效技术。如果可以使用衰老GAN合成单个3D图像,那将有助于创建4D数据集。面部衰老也称为年龄进展或年龄合成,因为它通过改变面部特征来使面部“复活”。使用各种技术增强面部特征,以便保留原始图像。图19显示了使用年龄条件GAN(ACGAN)[139]进行面部转换的过程。
图19:使用ACGAN的脸部变换[139]
Shi等人[140]使用GAN进行面部衰老,因为不同的面部部位在时间上具有不同的衰老速度。因此,他们使用基于注意力的条件GAN,使用规范化来处理分段面部衰老。
Fang等人[141]提出了一种渐进的面部衰老方法,使用GAN生成器级别的三重损失函数。复杂的转换损失帮助他们有效地处理面部衰老。
Huang等人[142]使用渐进GAN处理三个方面的面部衰老,如身份保持、高保真度和衰老准确性。Liu等人[143]提出了一种可控制的GAN,用于操作输入面部图像的潜在空间以控制面部衰老。
Yadav等人[144]提出了使用同一人的两个不同图像在各种年龄差距下进行面部识别的方法。
Sharma等人[145]使用CycleGAN的管道进行年龄进展,使用增强超分辨率GAN进行高保真度的融合GAN。
Liu等人[146]提出了一种面部衰老方法,用于对年轻面孔进行建模,对面部外观和几何变换进行建模。
如表6所示,面部重建可以在三种不同类型的设置中使用。面部操纵、语音驱动的动画和面部再现都是基于动画的面部重建的示例。面部替换和视频配音是基于视频的应用的两个示例。面部衰老、虚拟化妆和投影映射是一些最常见的3D面部应用。
表6:3D人脸重建技术的应用
7 挑战与未来研究方向
本节讨论了3D面部重建过程中所面临的主要挑战,随后介绍了未来研究的方向。
7.1 目前的挑战
目前3D面部重建面临的挑战包括遮挡去除、化妆品去除、表情转移和年龄预测。这些将在接下来的小节中进行讨论。
7.1.1 遮挡去除
遮挡去除是3D面部重建的一个具有挑战性的任务。研究人员正在使用体素和3D地标来处理3D面部遮挡 [2, 8, 9]。
Sharma和Kumar [2]开发了一种基于体素的面部重建技术。在重建过程后,他们使用变分自编码器、双向LSTM和三元损失训练的管道来实现3D面部识别。
Sharma和Kumar [20]提出了一种基于体素的面部重建和识别方法。他们使用基于博弈理论的生成器和鉴别器来生成三元组。在缺失信息被重建后,遮挡被移除。Sharma和Kumar [22]使用3D面部地标构建了一种一次学习的3D面部重建技术(见图20)。
图20:基于面部标志的三维人脸重建[9]
7.1.2 涂抹化妆品及其去除
在COVID-19大流行期间的虚拟会议中进行化妆和化妆品去除是具有挑战性的[154-156]。
MakeupBag [154]提出了一种自动化妆风格转移技术,通过解决化妆品分离和面部化妆问题。MakeupBag的主要优点在于它在进行化妆转移时考虑了肤色和颜色(如图21所示)。
图21:MakeupBag基于从参考面部到目标面部应用化妆的输出[154]。

Li等人[155]提出了一种化妆不变的人脸验证系统。他们使用语义感知的化妆品清洁器(SAMC)在各种表情和姿势下去除面部化妆品。该技术在定位脸部化妆区域的同时无监督地工作,并使用介于0到1之间的注意力图,表示化妆程度。
Horita和Aizawa [156]提出了一种基于样式和潜在向量引导的生成对抗网络(SLGAN)。他们使用可控制的GAN来使用户可以调整化妆品的阴影效果(见图22)。
图22:基于GAN的化妆品转移和去除[156]
7.1.3 表情转移
表情转移是一个活跃的问题,特别是随着GAN的出现。
Wu等人[157]提出了ReenactGAN,一种能够将人的表情从源视频转移到目标视频的方法。他们采用基于编码器解码器的模型来进行从源到目标的脸部转换。变换器使用了三个损失函数进行评估,即循环损失、对抗损失和形状约束损失。图23展示了唐纳德·特朗普重现表情的图像。
图23:使用ReenactGAN[157]的表达转移

深度伪造是一个令人担忧的问题,其中面部表情和上下文是不同的。
Nirkin等人[158]提出了一种深度伪造检测方法,用于检测身份操纵和人脸替换。在深度伪造图像中,面部区域通过针对要改变的面部进行上下文变化来进行操作。
Tolosana等人[159]对四种深度伪造方法进行了调查,包括全面合成、身份交换、面部属性操作和表情交换。
7.1.4 年龄预测
由于深度伪造和生成对抗网络[140,142],面部可以变形为其他年龄,如图24所示。因此,对一个人的年龄预测的挑战超出了想象,特别是在身份证或社交网络平台上的虚假面孔上。
图24:GAN进行性面部衰老的结果[142]
Fang等人[141]提出了一种基于GAN的面部年龄模拟技术。所提出的Triple-GAN模型使用三元翻译损失来建模年龄模式之间的相互关系。他们使用基于编码器解码器的生成器和鉴别器进行年龄分类。
Kumar等人[160]在基于GAN模型[161]的潜在空间上采用强化学习。他们使用马尔可夫决策过程(MDP)进行语义操纵。
Pham等人[162]提出了一种半监督的GAN技术来生成逼真的面部图像。他们在训练网络时使用真实数据和目标年龄合成面部图像。
Zhu等人[163]使用基于注意力的条件GAN技术,以目标高保真度合成面部图像。
7.2 未来的挑战
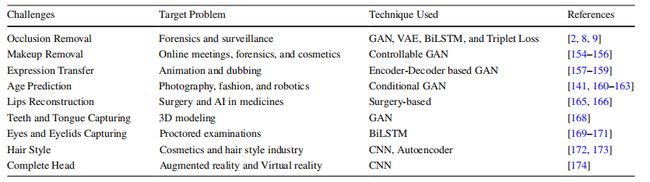
无监督学习在3D面部重建中仍然是一个开放性问题。最近,[164]提出了关于3D对称可变形物体的解决方法。在这篇论文中,详细讨论了一些未来的3D面部重建可能性,例如唇部重建、牙齿和舌头捕捉、眼睛和眼睑捕捉、发型重建和完整头部重建。这些挑战为从事3D面部重建领域的研究人员提出了任务。
7.2.1 唇部重建
唇部是口部区域最关键的组成部分之一。各种名人进行唇部手术,包括唇部提升手术、唇部缩小手术和唇部增大手术[165,166]。
Heidekrueger等人[165]调查了女性偏爱的唇比例。结论是性别、年龄、职业和国家可能会影响下唇比例的偏好。
Baudoin等人[166]对上唇美学进行了综述。研究了从填充剂到皮肤磨削和手术切除等不同的治疗选择。
Zollhofer等人[1]在图25中展示了唇部重建作为3D面部重建的一种应用。在[167]中,唇部的视频重建了唇部的滚动、拉伸和弯曲。
图25:高质量的唇形重建[1]
7.2.2 牙齿和舌头捕捉
在文献中,很少有研究工作关注捕捉口腔内部。在基于GAN的2D面部重建中重建牙齿和舌头是一项困难的任务。胡须或髭须可能使得捕捉牙齿和舌头变得困难。在[163]中,讨论了一个统计模型。重建牙齿区域有不同的应用,比如,制作数字化头像的内容和基于面部几何的牙齿修复(参见图26)。
图26:牙齿重建及其应用[168]

7.2.3 眼睛和眼睑捕捉
Wang等人[170]展示了从RGB视频中进行3D眼球注视估计和面部重建。
Wen等人[169]提出了一种实时跟踪和重建3D眼睑的技术(参见图27)。这种方法与面部和眼球追踪系统相结合,以实现具有详细眼部区域的完整面部。在[171]中,使用了双向LSTM进行眼睑追踪。
图27:基于语义边缘的眼睑追踪[169]

7.2.4 发型重建
在3D面部上,发型重建是一项具有挑战性的任务。基于体积变分自编码器的3D头发合成[172]在图28中展示。
图28:使用体积变分自编码器进行的3D头发合成[172]

Ye等人[173]提出了一个基于编码器-解码器技术的发丝重建模型。它使用基于发型的定向地图生成了一个体积向量场。在生成编码器-解码器格式的架构时,他们使用了CNN层的混合,跳跃连接,全连接层,和反卷积层。在训练过程中,结构和内容损失被用作评估指标。
7.2.5 完整头部重建
3D人头重建是一个活跃的研究领域。
He等人[174]提出了一个全头驱动的3D面部重建。生成了输入图像和重建结果,带有侧视纹理(参见图29)。他们采用了反照率参数化模型来补充头部纹理图。卷积网络被用于面部和头发区域的分割。在虚拟现实以及头像生成中,人头重建有各种应用。
图29:完整头部重建[174]

表7展示了挑战和未来的方向,以及他们的目标问题。
表7:3D面部重建的挑战和未来研究方向
8 结论
本文对3D面部重建技术进行了详细的调查和深入的研究。
初步讨论了六种重建技术。观察结果是,可扩展性是3D面部问题的最大挑战,因为3D面部没有足够大的公开可用数据集。大多数研究人员已经在RGB-D图像上进行了工作。
随着深度学习的发展,对网格图像或体素图像的工作存在硬件约束。
讨论了与真实世界中的3D面部重建相关的当前和未来挑战。这个领域是一个开放的研究领域,有许多挑战,特别是与生成对抗网络(GANs)和深度伪造的能力相关的挑战。在
- 嘴唇重建
- 口腔内部重建
- 眼睑重建
- 各种头发的造型
- 完整头部重建
方面,这个研究还未被充分探索。
声明 利益冲突:代表所有作者,通讯作者声明没有利益冲突。
参考文献
- Zollhöfer M, Thies J, Garrido P 等 (2018) 单眼3D面部重建、跟踪和应用的最新进展. 计算图形论坛 37(2):523–550. https://doi.org/10.1111/cgf.13382
- Sharma S, Kumar V (2020) 使用序列深度学习的体素-based 3D面部重建及其在面部识别中的应用. 多媒体工具应用 79:17303–17330. https://doi.org/10.1007/s11042-020-08688-x
- 云视觉API | Google Cloud. https://cloud.google.com/vision/docs/face-tutorial. 访问日期:2021年1月12日
- AWS Marketplace: Deep Vision API. https://aws.amazon.com/marketplace/pp/Deep-Vision-AI-Inc-Deep-Vision-API/B07JHXVZ4M. 访问日期:2021年1月12日
- 计算机视觉 | Microsoft Azure. https://azure.microsoft.com/en-in/services/cognitive-services/computer-vision/. 访问日期:2021年1月12日
- Koujan MR, Dochev N, Roussos A (2020) 使用LSFM模型实现实时单眼4D面部重建. 预印版arXiv:2006.10499.
- Behzad M, Vo N, Li X, Zhao G (2021) 朝向稀疏感知4D情感识别的超越面部阅读. 神经计算 458:297–307
- Sharma S, Kumar V (2020) 利用博弈论和模拟退火进行体素-based 3D遮挡不变的面部识别. 多媒体工具和应用 79(35):26517–26547
- Sharma S, Kumar V (2021) 使用变分自动编码器和三元损失进行基于3D标记点的面部恢复以供识别. IET生物测量 10(1):87–98. https://doi.org/10.1049/bme2.12005
- Tu X, Zhao J, Xie M 等 (2020) 在Wild中由2D面部图像辅助的单张图像3D面部重建. IEEE Trans Multimed 23:1160–1172. https://doi.org/10.1109/TMM.2020.2993962
- Bulat A, Tzimiropoulos G 我们离解决2D和3D面部对齐问题有多远?(以及一个包含230,000个3D面部标记点的数据集). 在: IEEE国际计算机视觉会议(ICCV)论文集, 页码: 1021–1030
- Zhu X, Lei Z, Liu X 等 (2016) 跨大姿态的面部对齐:一个3D解决方案. 计算机视觉和模式识别 (CVPR), 页码: 146–155
- Gu S, Bao J, Yang H 等 (2019) 利用条件GAN进行面部遮罩引导的肖像编辑. 在: 2019年IEEE计算机社区计算机视觉模式识别会议论文集 2019-June:3431–3440. doi: https://doi.org/10.1109/CVPR.2019.00355
- Guo Y, Wang H, Hu Q 等 (2020) 针对3D点云的深度学习:一项调查. IEEE Trans Pattern Anal Mach Intell 43(12):4338–4364. https://doi.org/10.1109/tpami.2020.3005434
- Ye M, Shen J, Lin G 等 (2021) 针对人员重识别的深度学习:调查和展望. IEEE Trans Pattern Anal Mach Intell 8828:1–1. https://doi.org/10.1109/tpami.2021.3054775
- Tran L, Liu X 非线性3D面部形态模型. 在: IEEE计算机视觉和模式识别会议论文集, 页码: 7346–7355
- Egger B, Smith WAP, Tewari A 等 (2020) 3D形态面部模型—过去、现在和未来. ACM Trans Graph 39(5):1–38. https://doi.org/10.1145/3395208
- Blanz V, Vetter T (1999) 基于3D形态模型拟合的面部识别. IEEE Trans Pattern Anal Mach Intell 25(9):1063–1074
- Booth J, Roussos A, Ponniah A 等 (2018) 大规模3D形态模型. Int J Comput Vis 126:233–254. https://doi.org/10.1007/s11263-017-1009-7
- Cao C, Weng Y, Zhou S 等 (2014) FaceWarehouse: 一个用于视觉计算的3D面部表情数据库. IEEE Trans Vis Comput Graph 20:413–425. https://doi.org/10.1109/TVCG.2013.249
- Gerig T, Morel-Forster A, Blumer C 等 (2018) 形态面部模型 - 一个开放的框架. 在: 13th IEEE国际自动面部手势识别会议论文集, FG. 页码: 75–82. https://doi.org/10.1109/FG.2018.00021
- Huber P, Hu G, Tena R 等 (2016) 一种多分辨率3D形态面部模型和拟合框架. 在: 计算机视觉、成像和计算机图形理论与应用的第11次联合会议论文集, 页码: 79–86. SciTePress.
- Li T, Bolkart T 等 (2017) 从4D扫描中学习面部形状和表情的模型. ACM Trans Graphics 36(6):1–17. https://doi.org/10.1145/3130800.3130813
- Lin J, Yuan Y, Shao T, Zhou K (2020) 利用图卷积网络实现高保真3D面部重建. 计算机视觉模式识别 (CVPR). https://doi.org/10.1109/cvpr42600.2020.00593
- Paysan P, Knothe R, Amberg B 等 (2009) 一个用于姿态和照明不变面部识别的3D面部模型. 在: 第6届IEEE国际高级视频和基于信号的监视会议, AVSS 2009. 页码: 296–301
- Kim D, Hernandez M, Choi J, Medioni G (2018) 深度3D面部识别. IEEE国际生物特征联合会议 (IJCB), IJCB 2017 2018-January:133–142. https://doi.org/10.1109/BTAS.2017.8272691
- Gecer B, Ploumpis S, Kotsia I, Zafeiriou S (2019) Ganfit: 使用生成对抗网络进行高保真3D面部重建. 在: IEEE/CVF计算机视觉和模式识别会议论文集:1155–1164. https://doi.org/10.1109/CVPR.2019.00125
- Kim H, Garrido P, Tewari A 等 (2018) 深度视频肖像. ACM Trans Graphics 37:1–14. https://doi.org/10.1145/3197517.3201283
- Maninchedda F, Oswald MR, Pollefeys M (2017) 快速重建戴眼镜的面部3D模型. 在: IEEE/CVF 计算机视觉和模式识别会议(CVPR). https://doi.org/10.1109/CVPR.2017.490
- Zhang S, Yu H, Wang T 等 (2018) 在非限制环境中从单一深度图像进行密集的3D面部重建. 虚拟现实 22(1):37–46. https://doi.org/10.1007/s10055-017-0311-6
- Jiang L, Wu X, Kittler J (2018) 姿态不变的3D面部重建. 1–8. arXiv预印本arXiv:1811.05295
- Wu F, Li S, Zhao T等 (2019) 使用地标位移进行级联回归的3D面部重建. 模式识别信件 125:766–772. https://doi.org/10.1016/j.patrec.2019.07.017
- Kollias D, Cheng S, Ververas E等 (2020) 深度神经网络增强:生成面部用于情感分析. 国际计算机视觉期刊 128:1455–1484. https://doi.org/10.1007/s11263-020-01304-3
- 4DFAB: A Large Scale 4D Facial Expression Database for Biometric Applications | DeepAI. https://deepai.org/publication/4dfab-a-large-scale-4d-facial-expression-database-for-biometric-applications. 访问于 2020年10月14日
- Lyu J, Li X, Zhu X, Cheng C (2020) Pixel-Face: A Large-Scale, High-Resolution Benchmark for 3D Face Reconstruction. arXiv 预印本 arXiv:2008.12444
- Zhu Z, Luo P, Wang X, Tang X (2013) 深度学习身份保持面部空间. 在: IEEE 国际计算机视觉会议论文集. 电子与电气工程师协会,页码: 113–120
- Tang Y, Salakhutdinov R, Hinton G (2012) 深度 Lambertian 网络. arXiv 预印本 arXiv:1206.6445
- Richardson E, Sela M, Kimmel R (2016) 通过从合成数据学习进行3D面部重建. 在: 2016年第4届3D视觉国际会议,3DV 2016 论文集. 电子与电气工程师协会,页码: 460–467
- Richardson E, Sela M, Or-El R, Kimmel R (2017) 从单张图片学习详细的面部重建. 在: IEEE 计算机视觉和模式识别会议论文集,页码: 1259–1268
- Laine S, Karras T, Aila T, 等 (2016) 使用深度神经网络进行面部表现捕获. arXiv 预印本 arXiv:1609.06536,3
- Nair V, Susskind J, Hinton GE (2008) 通过学习反转生成性黑箱进行合成分析. 在: 国际人工神经网络会议,页码: 971–981
- Peng X, Feris RS, Wang X, Metaxas DN (2016) 一个用于连续面部对齐的循环编码器-解码器网络. 在: 欧洲计算机视觉会议,页码: 38–56.
- Zulqarnain Gilani S, Mian A (2018) 从数百万个3D扫描中学习进行大规模的3D面部识别. 在: IEEE 计算机学会计算机视觉和模式识别会议论文集,页码: 1896–1905. https://doi.org/10.1109/CVPR.2018.00203
- Thies J, Elgharib M, Tewari A, 等 (2019) 神经声音操控:音频驱动的面部再现. 在: 欧洲计算机视觉会议,页码: 716–731
- Li X, Hu G, Zhu J等 (2020) 学习对称一致的深度CNN用于面部完成. IEEE 图像处理交易 29:7641–7655. https://doi.org/10.1109/TIP.2020.3005241
- Han X, Hou K, Du D等 (2020) CaricatureShop: 个性化与照片级别的漫画素描。IEEE视觉与计算机图形学交易 26:2349–2361. https://doi.org/10.1109/TVCG.2018.2886007
- Moschoglou S, Ploumpis S, Nicolaou MA等 (2020) 3DFaceGAN: 3D面部表征、生成和转换的对抗性网络。国际计算机视觉期刊 128(10):2534–2551. https://doi.org/10.1007/s11263-020-01329-8
- Feng M, Zulqarnain Gilani S, Wang Y等 (2018) “从光场图像进行3D面部重建: 一种无需模型的方法”。计算机科学讲座笔记(包括人工智能讲座笔记子系列和生物信息学讲座笔记子系列)11214 LNCS: 508–526. https://doi.org/10.1007/978-3-030-01249-6_31
- Anbarjafari G, Haamer RE, LÜSi I等 (2019) “使用移动电话进行基于区域的最佳拟合融合的3D面部重建,用于基于虚拟现实的社交媒体”。波兰科学院科技科学公报. 67: 125–132. https://doi.org/10.24425/bpas.2019.127341
- Kim H, Zollhöfer M, Tewari A等 (2018) “InverseFaceNet: 深度单眼逆面渲染”。在IEEE计算机视觉和模式识别会议论文集,页4625–4634。
- Jackson AS, Bulat A, Argyriou V, Tzimiropoulos G (2017) “通过直接体积CNN回归从单一图像重建大姿态3D面部”。在IEEE计算机视觉国际会议论文集2017-Octob:1031–1039。https://doi.org/10.1109/ICCV.2017.117
- Eigen D, Puhrsch C, Fergus R (2014) “使用多尺度深度网络从单一图像预测深度图”。预印版arXiv:1406.2283。
- Saxena A, Chung SH, Ng AY (2008) “从单一静态图像进行3-D深度重建”。国际计算机视觉杂志76:53–69。https://doi.org/10.1007/s11263-007-0071-y
- Tulsiani S, Zhou T, Efros AA, Malik J (2017) “通过可微射线一致性进行单视图重建的多视图监督”。在IEEE计算机视觉和模式识别会议论文集,页2626–2634。
- Tatarchenko M, Dosovitskiy A, Brox T (2017) “八叉树生成网络: 高分辨率3D输出的高效卷积架构”。在IEEE计算机视觉国际会议论文集,页2088–2096。
- Roth J, Tong Y, Liu X (2016) “从无约束的照片集合进行3D面部的自适应重建”。在IEEE计算机视觉和模式识别会议论文集,页4197–4206。
- Kemelmacher-Shlizerman I, Seitz SM (2011) “在野外的面部重建”。在IEEE计算机视觉国际会议论文集,页1746–1753。
- Xing Y, Tewari R, Mendonça PRS (2019) “一种自我监督的引导方法用于单图像3D面部重建”。在2019年IEEE应用计算视觉冬季会议论文集,WACV 2019:1014–1023。https://doi.org/10.1109/WACV.2019.00113
- Kemelmacher-Shlizerman I, Basri R (2011) “使用单一参考面形状从单一图像进行3D面部重建”。IEEE模式分析与机器智能交易33:394–405。https://doi.org/10.1109/TPAMI.2010.63
- Sengupta S, Lichy D, Kanazawa A等 (2020) “SfSNet: 学习在野外的面部形状、反射率和光照”。IEEE模式分析与机器智能交易。https://doi.org/10.1109/TPAMI.2020.3046915
- Jiang L, Zhang J, Deng B等 (2018) “从单一图像重建包含几何细节的3D面部”。IEEE图像处理交易27:4756–4770。https://doi.org/10.1109/TIP.2018.2845697
- He K, Zhang X, Ren S, Sun J (2016) “用于图像识别的深度残差学习”。在IEEE计算机视觉和模式识别会议论文集,页770–778。
- Liu F, Zeng D, Li J, Zhao Q, jun (2017) “在形状空间中通过级联回归进行3D面部重建”。信息技术和电子工程前沿18:1978–1990。https://doi.org/10.1631/FITEE.1700253
- Tewari A, Zollhöfer M, Kim H等 (2017) MoFA: 以模型为基础的深度卷积面部自动编码器用于无监督的单眼重建。在: 2017年IEEE国际计算机视觉会议工作论文集,ICCVW 2017 2018-Janua:1274-1283。https://doi.org/10.1109/ICCVW.2017.153
- Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet分类的深度卷积神经网络。神经信息处理系统进展25: 1097-1105
- 牛津大学视觉几何组。http://www.robots.ox.ac.uk/~vgg/data/vgg_face/。访问于2020年10月13日
- Dou P, Shah SK, Kakadiaris IA (2017) 深度神经网络的端到端3D面部重建。在: 第30届IEEE计算机视觉模式识别会议,CVPR,1503-1512。https://doi.org/10.1109/CVPR.2017.164
- Han X, Gao C, Yu Y (2017) DeepSketch2Face: 一个基于深度学习的3D面部和漫画模型的素描系统。ACM图形交易36: 1-12。https://doi.org/10.1145/3072959.3073629
- Hsu GS, Shie HC, Hsieh CH, Chan JS (2018) 快速定位3D组件重建和CNN用于跨姿势识别。IEEE电路和系统视频技术交易28: 3194-3207。https://doi.org/10.1109/TCSVT.2017.2748379
- Cao X, Chen Z, Chen A等 (2018) 稀疏光度3D面部重建,由形态模型指导。IEEE计算机学会计算机视觉模式识别会议论文集。https://doi.org/10.1109/CVPR.2018.00487
- Tran AT, Hassner T, Masi I等 (2018) 极端3D面部重建:看穿遮挡。IEEE计算机学会计算机视觉模式识别会议论文集。https://doi.org/10.1109/CVPR.2018.00414
- Feng ZH, Huber P, Kittler J等 (2018) 对野外2D面部图像的密集3D重建的评估。在: 第13届IEEE国际自动面部手势识别会议,FG 2018 780-786。https://doi.org/10.1109/FG.2018.00123
- Feng Y, Wu F, Shao X等 (2018) 与位置图回归网络的联合3D面部重建和密集对齐。计算机科学讲座笔记(包括人工智能讲座笔记生物信息学讲座笔记的子系列)11218 LNCS:557-574。https://doi.org/10.1007/978-3-030-01264-9_33
- Liu F, Zhu R, Zeng D等 (2018) 在3D面部形状中解开特征,以进行联合面部重建和识别。IEEE计算机学会计算机视觉模式识别会议论文集。https://doi.org/10.1109/CVPR.2018.00547
- Chinaev N, Chigorin A, Laptev I (2019) MobileFace: 通过高效的CNN回归进行3D面部重建。在: Leal-Taixé Laura, Roth Stefan(编辑)计算机视觉 - ECCV 2018研讨会:德国慕尼黑,2018年9月8-14日,论文集,第四部分。Springer International Publishing, Cham, pp 15-30。https://doi.org/10.1007/978-3-030-11018-5_3
- Deng Y, Yang J, Xu S等 (2019) 使用弱监督学习进行精确的3D面部重建:从单图像到图像集。IEEE计算机学会计算机视觉模式识别研讨会2019-June:285-295。https://doi.org/10.1109/CVPRW.2019.00038
- Yuan X, Park IK (2019) 使用3D形态模型和生成对抗网络进行面部去遮挡。在: IEEE国际计算机视觉会议论文集2019-Octob:10061-10070。https://doi.org/10.1109/ICCV.2019.01016
- Luo Y, Tu X, Xie M (2019) 学习鲁棒的3D面部重建和判别性身份表示。2019年第二届IEEE信息通信信号处理国际会议,ICICSP 2019 317-321。https://doi.org/10.1109/ICICSP48821.2019.8958506
- Gecer B, Lattas A, Ploumpis S等 (2019) 合成耦合3D面部模式的干线-支线生成对抗网络。欧洲计算机视觉会议。Springer,Cham,pp 415-433
- Chen Y, Wu F, Wang Z等 (2019) 自我监督学习的详细3D面部重建。IEEE图像处理交易29:8696-8705
- 大规模名人面部特征(CelebA)数据集。http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html. 于2020年10月13日访问
- 野外标记面部(LFW)数据集 | Kaggle。https://www.kaggle.com/jessicali9530/lfw-dataset. 于2020年10月13日访问
- Ren W, Yang J, Deng S, 等. (2019) 使用3D面部先验进行面部视频去模糊。在IEEE国际计算机视觉会议论文集中。2019-Octob:9387-9396. https://doi.org/10.1109/ICCV.2019.00948
- Jourabloo A, Liu X (2015) 对姿态不变的3D面部进行对齐。在IEEE国际计算机视觉会议论文集中。pp 3694-3702
- Cheng S, Kotsia I, Pantic M, 等. (2018) 4DFAB:一个用于生物识别应用的大规模4D面部表情数据库。https://arxiv.org/pdf/1712.01443v2.pdf. 于2020年10月14日访问
- Liu F, Zhao Q, Liu X, Zeng D (2020) 联合面部对齐和3D面部重建在面部识别中的应用。IEEE图形模式分析与机器智能交易。42:664-678. https://doi.org/10.1109/TPAMI.2018.2885995
- Ye Z, Yi R, Yu M, 等 (2020) 3D-CariGAN:从面部照片到3D漫画生成的端到端解决方案。1-17. arXiv预印本arXiv:2003.06841
- Huo J, Li W, Shi Y, 等. (2017) 网络漫画:用于漫画识别的基准测试。arXiv预印本arXiv:1703.03230
- Lattas A, Moschoglou S, Gecer B, 等 (2020) AvatarMe:真实可渲染的“实地”3D面部重建。757-766. https://doi.org/10.1109/cvpr42600.2020.00084
- Cai H, Guo Y, Peng Z, Zhang J (2021) 使用非线性参数模型进行漫画的关键点检测和3D面部重建。图形模型115:101103. https://doi.org/10.1016/j.gmod.2021.101103
- Deng Y, Yang J, Chen D, 等 (2020) 通过3D模仿-对比学习进行解开和可控的面部图像生成。https://doi.org/10.1109/cvpr42600.2020.00520
- Li K, Yang J, Jiao N, 等 (2020) 从单个图像进行自适应的3D面部重建。1-11. arXiv预印本arXiv:2007.03979
- Chaudhuri B, Vesdapunt N, Shapiro L, Wang B (2020) 为提高面部重建和动作重定向的个性化面部建模。在Vedaldi A, Bischof H, Brox T, Frahm J-M (eds) 计算机视觉 - ECCV 2020:第16届欧洲会议,格拉斯哥,英国,2020年8月23-28日,论文集,第五部分。Springer International Publishing, Cham, pp 142-160. https://doi.org/10.1007/978-3-030-58558-7_9
- Shang J, Shen T, Li S, 等 (2020) 自我监督的单目3D面部重建通过考虑遮挡的多视图几何一致性。在计算机视觉-ECCV 2020:第16届欧洲会议,格拉斯哥,英国,2020年8月23-28日,论文集,第十五部分16 (pp. 53-70). Springer International Publishing
- Cai X, Yu H, Lou J, 等 (2020) 使用关注引导的生成对抗网络从深度视图中恢复3D面部几何形状。arXiv预印本arXiv:2009.00938
- Xu S, Yang J, Chen D, 等 (2020) 从单个图像进行深度3D肖像。7707-7717. https://doi.org/10.1109/cvpr42600.2020.00773
- Zhang J, Lin L, Zhu J, Hoi SCH (2021) 弱监督的多面3D重建。1-9. arXiv预印本arXiv:2101.02000
- Köstinger M, Wohlhart P, Roth PM, Bischof H (2011) 野外注释的面部标记:面部标记定位的大规模、真实世界数据库。IEEE国际计算机视觉会议论文集。https://doi.org/10.1109/ICCVW.2011.6130513
- ICG - AFLW。https://www.tugraz.at/institute/icg/research/teambischof/lrs/downloads/afw/. 于2020年10月14日访问
- Tu X, Zhao J, Jiang Z等 (2019) 野外2D人脸图像辅助的单图像3D人脸重建. IEEE Trans Multimed. https://doi.org/10.1109/TMM.2020.2993962
- Moschoglou S, Papaioannou A, Sagonas C等 (2017) AgeDB: 第一个手动采集的野外年龄数据库. 在IEEE计算机视觉和模式识别会议的论文集,第51-59页
- Morphace. https://faces.dmi.unibas.ch/bfm/main.php?nav=1-1-0&id=details. 访问于2020年10月14日
- Savran A, Alyüz N, Dibeklioğlu H等 (2008) 用于3D面部分析的博斯普鲁斯数据库. 欧洲生物识别和身份管理研讨会. Springer, Berlin, Heidelberg, 第47-56页
- 3D面部表情数据库 - 宾汉姆顿大学. http://www.cs.binghamton.edu/~lijun/Research/3DFE/3DFE_Analysis.html. 访问于2020年10月13日
- 生物特征与安全研究中心. http://www.cbsr.ia.ac.cn/english/3DFace Databases.asp. 访问于2020年10月14日
- Yi D, Lei Z, Liao S, Li SZ (2014) 从零开始学习人脸表征. arXiv预印本 arXiv:1411.7923
- 在野外的正侧面名人. http://www.cfpw.io/. 访问于2020年10月14日
- Yang H, Zhu H, Wang Y等 (2020) FaceScape: 大规模高质量3D人脸数据集和详细可操纵的3D面部预测. 598-607
- FaceWarehouse. http://kunzhou.net/zjugaps/facewarehouse/. 访问于2020年10月13日
- Phillips PJ, Flynn PJ, Scruggs T等 (2005) 人脸识别大挑战概述. 在2005年IEEE计算机协会计算机视觉和模式识别会议(CVPR’05),第1卷: 947-954页
- MORENO, A. (2004) GavabDB : 一个3D人脸数据库. 在第二届COST275互联网生物识别工作论文集,2004年,75-80页
- Le V, Brandt J, Lin Z等 (2012) 交互式面部特征定位. 计算机科学讲座笔记(包括人工智能讲座笔记生物信息学讲座笔记)7574 LNCS:679-692. https://doi.org/10.1007/978-3-642-33712-3_49
- IJB-A数据集请求表 | NIST. https://www.nist.gov/itl/iad/image-group/ijb-dataset-request-form. 访问于2020年10月14日
- Min R, Kose N, Dugelay JL (2014) KinectfaceDB: 用于面部识别的Kinect数据库. IEEE Trans Syst Man, Cybern Syst 44:1534-1548. https://doi.org/10.1109/TSMC.2014.2331215
- Belhumeur PN, Jacobs DW, Kriegman DJ, Kumar N (2011) 使用一致的示例定位面部部位. IEEE计算机学会计算机视觉模式识别会议论文集. https://doi.org/10.1109/CVPR.2011.5995602
- Bagdanov AD, Del Bimbo A, Masi I (2011) Forence 2D/3D混合面部数据集. 在2011年ACM联合工作室的人类手势和行为理解工作坊 - J-HGBU '11的论文集. ACM出版社,美国纽约,第79页
- Notre Dame CVRL. https://cvrl.nd.edu/projects/data/#nd-2006-data-set. 访问于2020年10月13日
- 德州大学奥斯汀分校图像和视频工程实验室. http://live.ece.utexas.edu/research/texas3dfr/. 访问于2020年10月14日
- Le HA, Kakadiaris IA (2017) UHDB31: 一个用于更好理解姿态和照明变化下的面部识别的数据集. 在2017年IEEE国际计算机视觉研讨会(ICCVW)论文集. IEEE, 第2555-2563页
- Colombo A, Cusano C, Schettini R (2011) UMB-DB: 一个部分遮挡的3D面部数据库. 在IEEE国际计算机视觉会议论文集,第2113-2119页
- Parkhi OM, Vedaldi A, Zisserman A, (2015) 深度面部识别. 第1-12页
- Sanderson C (2002) VidTIMIT数据库. (No. REP_WORK). IDIAP
- Son Chung J, Nagrani A, Zisserman A, (2018) VoxCeleb2: 深度 声纹识别。arXiv 预印本 arXiv:1806.05622
- YouTube Faces Database : 主页。https://www.cs.tau.ac.il/~wolf/ytfaces/ 。访问于 2020年10月14日
- 300-VW | 计算机视觉在线。https://computervisiononline/.com/dataset/1105138793 。访问于 2020年10月13日
- i·bug - 资源 - 300 Faces In-the-Wild Challenge (300- W), ICCV 2013。https://ibug.doc.ic.ac.uk/resources/300-W/ 。访问于 2020年10月14日
- Vijayan V, Bowyer K, Flynn P (2011) 3D 双胞胎和表情挑战。在:IEEE 国际计算机视觉会议论文集。pp 2100–2105
- AI + X: 不要更换职业,加入 AI - YouTube。http://www.youtube.com/watch?v=4Ai7wmUGFNA 。访问于2021年2月5日
- Cao C, Hou Q, Zhou K (2014) 用于实时面部追踪和动画的位移动态表达回归。在:ACM 图形学交易。计算机协会,pp 1–10
- Bouaziz S, Wang Y, Pauly M (2013) 实时面部动画的在线建模。ACM Trans Graph 32:1–10。https://doi.org/10.1145/2461912.2461976
- Garrido P, Valgaerts L, Sarmadi H 等 (2015) VDub: 修改演员面部视频,以与配音音轨有可信度的视觉对齐。计算机图形论坛 34:193–204。https://doi.org/10.1111/cgf.12552
- Thies J, Zollhöfer M, Stamminger M, 等 Face2Face: RGB 视频的实时面部捕获和重演
- MIT 深度学习介绍 | 6.S191 - YouTube。https://www.youtube.com/watch?v=5tvmMX8r_OM 。访问于 2021年2月8日
- Garrido P, Valgaerts L, Wu C, Theobalt C (2013) 从单目视频重建详细的动态面部几何。ACM Trans Graph 32:1–10。https://doi.org/10.1145/2508363.2508380
- Viswanathan S, Heisters IES, Evangelista BP, 等。 (2021) 生成增强现实化妆效果的系统和方法。U.S. Patent 10,885,697
- Nam H, Lee J, Park JI (2020) 使用 RGB 摄像头的交互式像素单元 AR 唇部化妆系统。广播工程杂志 25(7):1042–51
- Siegl C, Lange V, Stamminger M, 等 FaceForge: 无标记非刚性面部多投影映射
- 使用静态图像和面部工具在视频中替换面部 - After Effects 教程 - YouTube。https://www.youtube.com/watch?v=x7T5jiUpUiE 。访问于 2021年2月6日
- Antipov G, Baccouche M 和 Dugelay JL, (2017), 用条件生成对抗网络进行面部老化。在:IEEE 国际图像处理会议 (ICIP),pp. 2089–2093
- Shi C, Zhang J, Yao Y 等 (2020) CAN-GAN: 有条件注意标准化的生成对抗网络用于面部年龄合成。模式识别信件 138:520–526。https://doi.org/10.1016/j.patrec.2020.08.021
- Fang H, Deng W, Zhong Y, Hu J (2020) Triple-GAN: 使用三重转化损失进行渐进式面部老化。在:IEEE 计算社团会议计算机视觉模式识别研讨会 2020年6月:3500–3509。https://doi.org/10.1109/CVPRW50498.2020.00410
- Huang Z, Chen S, Zhang J, Shan H (2020) PFA-GAN: 用生成对抗网络进行渐进式面部老化。IEEE 交易信息取证和安全。https://doi.org/10.1109/TIFS.2020.3047753
- Liu S, Li D, Cao T 等 (2020) 基于 GAN 的面部属性编辑。IEEE 授权 8:34854–34867。https://doi.org/10.1109/ACCESS.2020.2974043
- Yadav D, Kohli N, Vatsa M, 等 (2020) Age gap reducer-GAN 用于识别年龄间隔的脸。在:25th 国际模式识别会议 (ICPR),pp 10090–10097
- Sharma N, Sharma R, Jindal N (2020) 利用生成对抗网络进行面部年龄进展和增强超分辨率的改进技术. 无线个人通信 114:2215-2233. https://doi.org/10.1007/s11277-020-07473-1
- Liu L, Yu H, Wang S 等 (2021) 学习形状和纹理进程以实现儿童面部老化. 信号处理图像通讯 93:116127. https://doi.org/10.1016/j.image.2020.116127
- Nirkin Y, Keller Y, Hassner T (2019) FSGAN: 不受主题影响的面部替换和再演. 在:IEEE/CVF 国际计算机视觉会议论文集,第 7184-7193 页
- Tripathy S, Kannala J, Rahtu E (2020) ICface: 使用GAN 进行可解释和可控的面部再演. 在:IEEE/CVF 计算机视觉应用的冬季会议论文集,第 3385-3394 页
- Ha S, Kersner M, Kim B, 等 (2019) MarioNETte: 少次样本面部再演,保留未见过的目标的身份. arXiv 34:10893-10900
- Zhang J, Zeng † Xianfang, Wang M, 等 (2020) FReeNet: 多身份面部再演. 在:IEEE/CVF 计算机视觉和模式识别会议论文集,第 5326-5335 页.
- Zeng X, Pan Y, Wang M, 等 (2020) 实现真实面部再演的自我监督身份和姿势的解耦. arXiv 34:12757-12764
- Ding X, Raziei Z, Larson EC, 等 (2020) 利用深度学习和主观评估进行换脸检测. EURASIP 信息安全杂志,第 1-12 页
- Zukerman J, Paglia M, Sager C, 等 (2019) 视频操作与面部替换. U.S. 专利 10,446,189
- Hoshen D (2020) MakeupBag: 分离化妆提取和应用. arXiv 预印本 rXiv:2012.02157
- Li Y, Huang H, Yu J, 等 (2020) 美容意识的化妆清洁器. arXiv 预印本 arXiv:2004.09147
- Horita D, Aizawa K (2020) SLGAN: 风格和潜在引导的生成对抗网络,用于理想的化妆转移和去除. arXiv 预印本 arXiv:2009.07557
- Wu W, Zhang Y, Li C, 等 (2018) ReenactGAN: 通过边界转移学习再现面部. 在:欧洲计算机视觉会议 (ECCV) 论文集,第 603-619 页
- Nirkin Y, Wolf L, Keller Y, Hassner T (2020) 基于面部及其上下文间差异的 DeepFake 检测. arXiv 预印本 arXiv:2008.12262.
- Tolosana R, Vera-Rodriguez R, Fierrez J 等 (2020) 深度伪造及其后果:面部操纵和假设检测的调查. 信息融合 64:131-148
- Shubham K, Venkatesh G, Sachdev R, 等 (2020) 在预先训练的GAN的潜在空间上学习一个深度强化学习策略进行语义年龄操作. 在:2021 国际神经网络联合会议 (IJCNN),第 1-8 页. IEEE
- Karras T, Aila T, Laine S, Lehtinen J (2017) GANs的逐步增长,以提高质量、稳定性和变异. arXiv 预印本 arXiv:1710.10196
- Pham QTM, Yang J, Shin J (2020) 半监督 FaceGAN 用于面部年龄进度和回归与合成配对图像. 电子 9:1-16. https://doi.org/10.3390/electronics9040603
- Zhu H, Huang Z, Shan H, Zhang J (2020) 全局观察,局部衰老:带有注意力机制的面部衰老 Haiping Zhu Zhizhong Huang Hongming Shan 上海智能信息处理重点实验室,复旦大学计算机科学学院,中国,200433. ICASSP 2020 - 2020 IEEE 国际音频、语音和信号处理大会论文集 1963–1967
- Wu S, Rupprecht C, Vedaldi A (2021) 在野外的图像中无监督学习可能对称的可变形3D物体. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2021.3076536
- Heidekrueger PI, Juran S, Szpalski C 等 (2017) 当前首选的女性唇部比例. J Cranio-Maxillofacial Surg 45:655-660. https://doi.org/10.1016/j.jcms.2017.01.038
- Baudoin J, Meuli JN, di Summa PG 等 (2019) 上唇美容复原的全面指南. J Cosmet Dermatol 18:444-450
- Garrido P, Zollhöfer M, Wu C 等 (2016) 从单目视频中进行嘴唇的纠正3D重建. ACM Trans Graph 35:1-11. https://doi.org/10.1145/2980179.2982419
- Wu C, Bradley D, Garrido P 等 (2016) 基于模型的牙齿重建. ACM Trans Graph 35(6):220-221. https://doi.org/10.1145/2980179.2980233
- Wen Q, Xu F, Lu M, Yong JH (2017) 从语义边缘进行实时3D眼皮追踪. ACM Trans Graph 36:1-11. https://doi.org/10.1145/3130800.3130837
- Wang C, Shi F, Xia S, Chai J (2016) 使用单个RGB相机进行实时3D眼睛凝视动画. ACM Trans Graph 35:1-14. https://doi.org/10.1145/2897824.2925947
- Zhou X, Lin J, Jiang J, Chen S (2019) 学习一个改进的itracker结合双向LSTM的3D凝视估计器. 在: IEEE国际多媒体和博览会论文集. IEEE计算机协会, pp 850-855
- Li H, Hu L, Saito S (2020) 使用体积变分自编码器进行3D头发合成. ACM Transactions on Graphics (TOG) 37(6):1-12
- Ye Z, Li G, Yao B, Xian C (2020) HAO-CNN: 基于体积矢量场的有意识的头发重建. Comput Animat Virtual Worlds 31:e1945. https://doi.org/10.1002/cav.1945
- He H, Li G, Ye Z 等 (2019) 数据驱动的3D人头重建. Comput Graph 80:85-96. https://doi.org/10.1016/j.cag.2019.03.008
出版商声明: Springer Nature对于出版地图和机构所属关系中的司法主张保持中立。