Kudu-集群管理、基架感知、透明分层存储管理、性能优化
文章目录
-
- Kudu集群管理
-
- Kudu命令行工具
-
- 命令行工具盘点
- 常见命令
- Kudu Web界面
-
- WebUI端口
- Master Web UI
- Tablet Server Web UI
- 监控和管理工具
-
- 编译和安装
- 使用
- 备份与恢复
- 其他高级主题
-
- 机架感知
-
- 机架感知作用
- 配置机架感知
- 透明分层存储管理
- 索引跳跃式扫描优化
- 资源规划
- 性能调优
-
- 硬件层面优化
- 操作系统层面优化
- 网络优化
- 配置调优
- 透明分层存储案例分析
-
- 需求分析
- 方案设计
-
- 架构设计
- 分层存储设计
- 模拟数据
- 构建数据流水线
- 数据验证
Kudu集群管理
Kudu命令行工具
命令行工具盘点
Kudu在安装时默认就安装了命令行工具,只需要执行Kudu命令就能看到所有的命令分组:
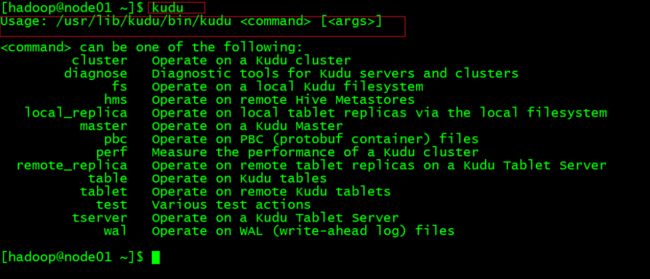
一共有14个分组,组下面才是具体的命令,分组如下:

执行kudu命令组就可以列出下面的子命令:
kudu cluster

常见命令
Kudu提供了丰富的命令行工具方便用户管理集群,这里选择一些常见且命令做一下介绍。
(1)kudu cluster

举例:
sudo -u kudu kudu cluster ksck node01:7051,node02:7051,node03:7051
sudo -u kudu kudu cluster rebalance node01:7051,node02:7051,node03:7051
(2)kudu master

举例:
kudu master list node01:7051,node02:7051,node03:7051
kudu master status node01:7051
(3)kudu tserver

举例:
kudu tserver list node01:7051,node02:7051,node03:7051
kudu tserver status node01:7050
(4)kudu table
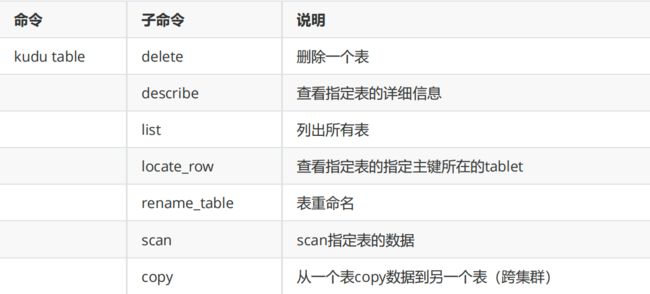
举例:
kudu table list node01:7051,node02:7051,node03:7051
kudu table describe node01:7051,node02:7051,node03:7051 students
kudu table locate_row node01:7051,node02:7051,node03:7051 students '[1]'
kudu table rename_table node01:7051,node02:7051,node03:7051 users user
kudu table scan node01:7051,node02:7051,node03:7051 user -columns=name,age
(5)kudu tablet

举例:
kudu tablet leader_step_down node01:7051,node02:7051,node03:7051 ea5023405f694426abe0c1887726e4cb
(6)kudu perf

举例:
kudu perf table_scan node01:7051,node02:7051,node03:7051 students
Kudu Web界面
WebUI端口
除了命令行工具,我们之前已经看到Kudu提供Master和Tablet Server Web UI,默认端口如下:

Master Web UI
(1)主界面
访问任意一台Master的WebUI即可,如果你没有修改默认端口:
http://node01:8051

下表是对主界面菜单功能的说明:

Tablet Server Web UI
(1)主界面
访问任意一台tserver的WebUI即可,如果你没有修改默认端口:
http://node01:8050

下表是对主界面菜单功能的说明:

监控和管理工具
Github上有一个Kudu的监控管理工具kudu-plus,它使用JavaFX开发的一个桌面应用,见如下链接:
https://github.com/Xchunguang/kudu-plus
编译和安装
(1)克隆代码
git clone https://github.com/Xchunguang/kudu-plus.git
(2)修改kudu-client版本
导入项目到IDEA,然后修改pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<packaging>jarpackaging>
<groupId>com.xuchggroupId>
<artifactId>KuduPlusartifactId>
<version>0.0.1-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.3.RELEASEversion>
<relativePath />
parent>
<properties>
<java.version>1.8java.version>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-
8project.reporting.outputEncoding>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>[1.2.31,)version>
dependency>
<dependency>
<groupId>org.apache.derbygroupId>
<artifactId>derbyartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.0.31version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.4version>
dependency>
<dependency>
<groupId>org.apache.kudugroupId>
<artifactId>kudu-clientartifactId>
<version>1.10.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>com.zenjavagroupId>
<artifactId>javafx-maven-pluginartifactId>
<version>8.8.3version>
<configuration>
<mainClass>com.xuchg.MainApplicationmainClass>
<appName>KuduPlusappName>
<verbose>trueverbose>
<needMenu>trueneedMenu>
<needShortcut>trueneedShortcut>
<jvmArgs>
<jvmArg>-Xms50MjvmArg>
<jvmArg>-Xmx100MjvmArg>
<jvmArg>-XX:MaxPermSize=100MjvmArg>
<jvmArg>-XX:-UseGCOverheadLimitjvmArg>
<jvmArg>-Dvisualvm.display.name=KuduPlusjvmArg>
jvmArgs>
<vendor>大讲台vendor>
<bundleArguments>
<installdirChooser>trueinstalldirChooser>
bundleArguments>
<allPermissions>trueallPermissions>
<nativeReleaseVersion>v1.0.0nativeReleaseVersion>
<description>
KuduPlus是kudu可视化管理工具
description>
configuration>
plugin>
plugins>
build>
project>
(3)编译
mvn clean jfx:native
注意编译JavaFX应用跟普通应用是有区别的
编译完成之后在targetjfxnativeKuduPlus下:

(4)安装
我们targetjfxnativeKuduPlus整个目录拷贝到任意一个你喜欢的目录就算安装好了(绿色版本)。
使用
(1)启动
进入安装目录,点击:
(2)新建连接


(3)连接集群

备份与恢复
从Kudu 1.10.0开始,Kudu通过Apache Spark Job支持完整表备份和增量表备份。 此外,它还支持通过使用Apache Spark还原Job从完整备份和增量备份还原表。
原理:
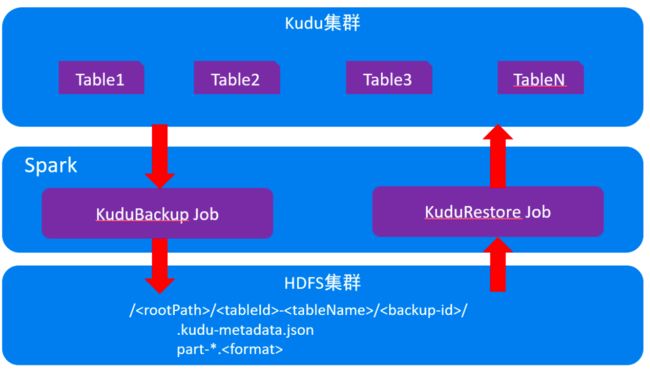
备份表:
cd /usr/lib/kudu
spark-submit --class org.apache.kudu.backup.KuduBackup kudu-backup2_2.11-1.10.0- cdh6.3.0.jar
--kuduMasterAddresses master1-host,master-2-host,master-3-host
--rootPath hdfs:///kudu-backups
foo bar
第一次执行是全量备份,后续执行就是增量备份,可以通过 --forceFull 标志来强制再次执行一次全量备份。
HDFS目录结构:
/<rootPath>/<tableId>-<tableName>/<backup-id>/
.kudu-metadata.json
part-.<format>
目前只支持parquet格式,一个分区对应一个part-.parquet文件。
恢复表:
cd /usr/lib/kudu
spark-submit --class org.apache.kudu.backup.KuduRestore kudu-backup2_2.11- 1.10.0-cdh6.3.0.jar
--kuduMasterAddresses master1-host,master-2-host,master-3-host
--rootPath hdfs:///kudu-backups
foo bar
注意:目前还不支持物理备份
其他高级主题
机架感知
机架感知作用
机架感知通俗的讲就是Kudu能够知道每个Tablet Server处于哪个数据中心的哪个机架,它在副本的负载策略上就可以考虑的更全面,避免同一tablet的多个副本负载到同一机架,从而防止整个机架故障时tablet不可用。
下图是一个很好的例子:

上图中,L0-L2是三个机架,TS0 -TS5是5台Tablet Server,有两张表:
- A表(副本因子=3),包含A0-A3四个tablets
- B表(副本因子=5),包含B0-B2三个tablets
如果Kudu配置了机架感知,它就会发现上面的tablet分布违背了相关规则:
- 副本A0.0和A0.1构成了大多数副本(三分之二),并且位于相同的位置/L0中,一旦L0机架电源或者交换机故障,将只有L1上的A0.2—个tablet副本可用且无法选择出leader(根据Raft协议必须 n/2+1 个副本正常才可以选举,n=总副本数)
- B表的大多数副本集中在TSO-TS4,而TS5非常空闲,在即考虑机架分布式又考虑负载均衡的前提下,需要把B表的相关副本往TS5挪一挪
经过手工负载均衡,负载可能会变成如下样子:

注意:目前还不支持自动复杂均衡。
配置机架感知
本节将告诉大家如何配置Kudu的机架感知:
- 准备机架感知脚本
- 启用机架感知
(1)准备机架感知脚本
vi location_awareness.sh
脚本内容如下:
#!/bin/sh
#
# It's assumed a Kudu cluster consists of nodes with IPv4 addresses in the
# private 192.168.100.0/32 subnet. The nodes are hosted in racks, where
# each rack can contain at most 32 nodes. This results in 8 locations,
# one location per rack.
#
# This example script maps IP addresses into locations assuming that RPC
# endpoints of tablet servers are specified via IPv4 addresses. If tablet
# servers' RPC endpoints are specified using DNS hostnames (and that's how
# it's done by default), the script should consume DNS hostname instead of
# an IP address as an input parameter. Check the `--rpc_bind_addresses` and
# `--rpc_advertised_addresses` command line flags of kudu-tserver for details.
#
# DISCLAIMER:
# This is an example Bourne shell script for Kudu location assignment. Please
# note it's just a toy script created with illustrative-only purpose.
# The error handling and the input validation are minimalistic. Also, the
# network topology choice, supportability and capacity planning aspects of
# this script might be sub-optimal if applied as-is for real-world use cases.
set -e
if [ $# -ne 1 ]; then
echo "usage: $0 "
exit 1
fi
ip_address=$1
shift
suffix=${ip_address##192.168.2.}
if [ -z "${suffix##*.*}" ]; then
# An IP address from a non-controlled subnet: maps into the 'other' location.
echo "/other"
exit 0
fi
# The mapping of the IP addresses
if [ -z "$suffix" -o $suffix -lt 0 -o $suffix -gt 255 ]; then
echo "ERROR: '$ip_address' is not a valid IPv4 address"
exit 2
fi
if [ $suffix -eq 0 -o $suffix -eq 255 ]; then
echo "ERROR: '$ip_address' is a 0xffffff00 IPv4 subnet address"
exit 3
fi
if [ $suffix -lt 32 ]; then
echo "/dc0/rack00"
elif [ $suffix -ge 32 -a $suffix -lt 64 ]; then
echo "/dc0/rack01"
elif [ $suffix -ge 64 -a $suffix -lt 96 ]; then
echo "/dc0/rack02"
elif [ $suffix -ge 96 -a $suffix -lt 128 ]; then
echo "/dc0/rack03"
elif [ $suffix -ge 128 -a $suffix -lt 160 ]; then
echo "/dc0/rack04"
elif [ $suffix -ge 160 -a $suffix -lt 192 ]; then
echo "/dc0/rack05"
elif [ $suffix -ge 192 -a $suffix -lt 224 ]; then
echo "/dc0/rack06"
else
echo "/dc0/rack07"
fi
保存退出后:
sudo chmod +x location_awareness.sh
最后分发到Kudu的各个节点指定目录下:
sudo scp location_awareness.sh root@node01:/usr/share/kudu
sudo scp location_awareness.sh root@node02:/usr/share/kudu
sudo scp location_awareness.sh root@node03:/usr/share/kudu
(2)、启用机架感知
在所有节点上启用机架感知。
-
修改Master配置
sudo vi /etc/kudu/conf/master.gflagfile # 增加如下配置项: --location_mapping_cmd=/usr/share/kudu/location_awareness.sh -
修改Tablet Server
sudo vi /etc/kudu/conf/tserver.gflagfile # 增加如下配置项: sudo vi /etc/kudu/conf/tserver.gflagfile -
重启Master和Tablet Server
kudu-cluster.sh restart
透明分层存储管理
(1)存储选择方法
Kudu是为快速数据上的快速分析场景而生的,但是Kudu的成本并不低,且扩展性并没有那么好(tserver的个数不能太多)。
HDFS旨在以低成本实现无限的可扩展性。它针对数据不可更改的面向批处理的场景进行了优化,当使用Parquet文件格式,可以以极高的吞吐量和效率访问结构化数据。
- 对于数据比较小且不断变化的数据(例如维表)通常全部存放到Kudu
- 当数据不会超过Kudu的扩展范围限制,且能够从Kudu的独特功能中受益时(快速变化、快速分),通常作为大表保存在Kudu
- 当数据量非常大,面向批处理且基本不太可能变更的情况下首选以Parquet格式将数据存储在HDFS中(冷数据)
**(2)基于滑动窗口的透明存储管理方案 **
当您需要两个存储层的优势时,滑动窗口模式是一个有用的解决方案。该方案的主要思路是:
- 使用lmpala创建2张表:Kudu表和Parquet 格式的HDFS表
- 这两张表都是按照时间分区的表,分区粒度取决于数据在Kudu表和HDFS表之间迁移的频率,般是按照年或者月或者曰分区,特殊情况下可以更细粒度
- 在lmpala另外创建一个统一视图,并使用where字句定义一个边界,由该边界决定哪些数据该从哪个表读取
- Kudu中变冷的数据分区会定期的被刷写到HDFS (Parquet)
- 数据刷写之后,在HDFS表新增分区、使用原子的ALTER VIEW 操作把视图的边界往前推移
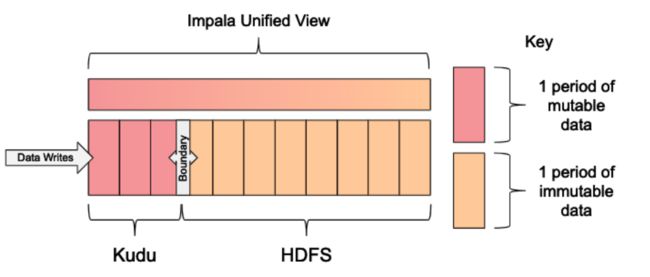
该方案的好处是:
- 流式数据可立即查询
- 可以更新迟到的数据或进行手动更正
- HDFS中存储的数据具有最佳大小,可提高性能并防止小文件降低成本
(3)数据从Kudu迁到HDFS的过程
数据从Kudu迁移到HDFS需要经过下面两个步骤,该过程需要定时自动调度。
-
数据迁移
在第一阶段,将现在不变的数据从Kudu复制到HDFS。即使将数据从Kudu复制到HDFS,在视图中定义的边界也将阻止向用户显示重复数据。此步骤应该包含检查机制,以确保成功完成数据的迁移和卸载。

-
元数据修改
在第二阶段,既然已将数据安全地复制到HDFS,则更改元数据以调整如何显示卸载的分区。 这包括向前移动边界,添加下一个时间窗口的新的Kudu分区以及删除旧的Kudu分区。

索引跳跃式扫描优化
(1)索引跳跃式扫描优化
我们通过如下例子来说明Kudu的索引跳跃式扫描优化,现有如下一张表:
CREATE TABLE metrics (
host STRING,
tstamp INT,
clusterid INT,
role STRING,
PRIMARY KEY (host, tstamp, clusterid)
);
数据是这个样子的:

Kudu在内部会创建主键索引(B-tree),跟上表类似,索引数据按所有主键列的组合排序。当用户查询包含第一主键列(host)时,Kudu将使用索引(因为索引数据主要在第一个主键列上排序)。
如果用户查询不包含第一个主键列而仅包含tstamp列怎么办?tstamp虽然在固定host下是有序的,但全局是无须的,所以无法使用主键索引。在关系型数据库中一般采用二级索引,但是Kudu并不支持二级索引,难道必须全表扫描吗?
Kudu当然不会全表扫描。在下面的查询中,tstamp之前的列为“prefifix column”,列的具体值为“prefifixkey”,在咱们的例子中host就是prefifix column。在索引中首先按照prefifix key排序,相同的prefifix key在按照剩余列的值排序,因此可以使用索引跳转到具有不同prefifix key且tstamp满足条件的行上。
SELECT clusterid FROM metrics WHERE tstamp = 100;

上图中绿色的是扫描的行,其余的是跳过的。Tablet Server使用索引( prefifix key (host =helium)+tstamp = 100)跳过不匹配的行直接到达第三行并逐步扫描直到不匹配tstamp = 100,就通过下一个prefifix key (host = ubuntu)+tstamp = 100继续跳过不匹配的行。其余prefifix key采用相同的做法,这就叫做Index Skip Scan优化。
(2)性能
-
索引跳跃式扫描优化的性能与前缀列 (prefix column) 的基数(prefix key去重后的数量)负相关
以上面的例子来说:host的基数越低,跳跃扫描性能越高,反之则性能越差。
-
前缀列基数很高时,索引跳跃式扫描优化就不可取了
使用前面的metrics表,官方有一个测试,见下图:
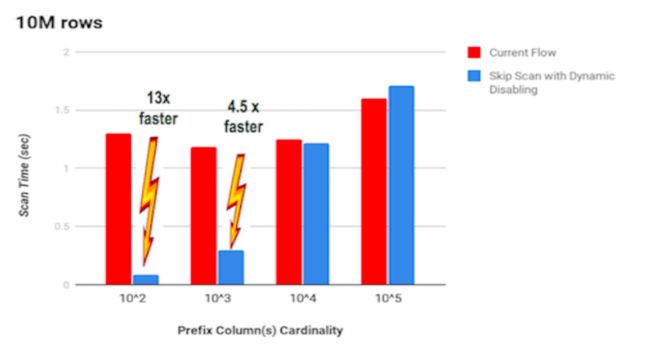
在每个tablet一千万行的数据规模下,当【前缀列host基数>sqrt(number_of_rows_in_tablet)】时,索引跳跃式扫描性能开始下降。 为了解决这个问题:
- Kudu目前在【跳跃次数>sqrt(number_of_rows_in_tablet)】时自动禁用跳跃扫描优化
- 更好的策略Kudu会在未来推出,让我们拭目以待
资源规划
在做资源规划是重点考虑的是tserver,master负载要小很多,回顾已知tserver相关的建议和限制如下:
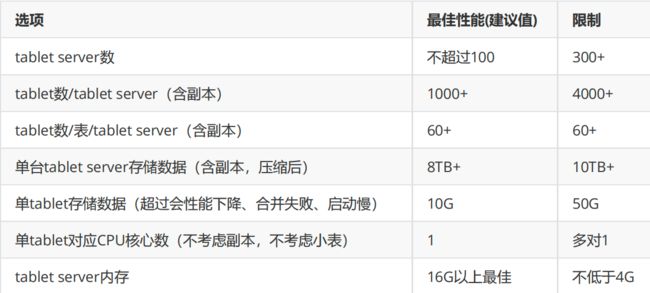
(1)集群规模

这里有一个预估tserver服务器数量的公式供参考:t=d/(k∗(1-p))∗r

示例:
d=120T
K=8T
p=25%
r=3
t=(120 / (8 * (1 - 0.25)))*3 = 60
(2)内存和CPU

(3)磁盘
跟HDFS不一样,Kudu针对SSD做了特别优化,推荐使用SSD:

WAL、metadata、data的目录配置别忘了:
--fs_wal_dir
--fs_metadata_dir
--fs_data_dirs
(4)网卡

性能调优
硬件层面优化
-
tserver的WAL采用M.2接口(NVMe协办议)SSD
Kudu的每一次写入都会先写WAL,WAL是确保数据不丢失的关键,所以一般都会同步写磁盘(顺序写),为了提高性能建议tserver采用M.2接口(NVMe协议)SSD来存储WAL,至少也得是普通SSD (master读写压力小,跟操作系统共享SSD即可)
--fs_wal_dir=/data/kudu/tserver/wal -
数据存储多SSD
tserver负责数据的读写和复制,压力比较大,建议采用多SSD分散读写10。
--fs_data_dirs=/disk1/kudu/tserver/data,/disk2/kudu/tserver/data,/disk3/kudu/tserv er/data
操作系统层面优化
-
文件描述符和线程数限制
操作系统会控制每个用户使用的文件描述符和线程数,Kudu作为数据库肯定比一般应用需要更多文件描述符和线程数。
如果Kudu使用的线程数超过OS的限制,你会在日志中看到如下报错:
pthread_create failed: Resource temporarily unavailable -
降低或者禁用swap使用交换区会导致性能下降,建议降低swap的使用:
sudo su echo "vm. swappiness=10">> /etc/sysctl.conf exit上面参数重启才能生效,可以同时搭配如下命令避免重启:
sudo sysctl vm. swappiness=10检查当前是否生效:
cat /proc/sys/vm /swappiness
网络优化
-
多机架万兆网络
-
双干兆网卡绑定
双干兆网卡绑定可以应对单一网卡故障并提高性能。
配置调优
以下参数没有特别说明的,master和tserver都需要配置。
(1)tserver内存限制
Tablet Server能使用的最大内存量,tablet Server在批量写入数据时并非实时写入磁盘,而是先Cache在内存中,在flflush到磁盘。这个值设置过小时,会造成Kudu数据写入性能显著下降。对于写入性能要求比较高的集群,建议设置更大的值 :
--memory_limit_hard_bytes
还有两个软限制:
## Cgroup 内存软限制,这个限制并不会阻止进程使用超过限额的内存,只是在系统内存不足时,会优先回 收超过限额的进程占用的内存,使之向限定值靠拢,当进程试图占用的内存超过了cgroups的限制,会触发 out of memory,导致进程被kill掉
--memory_limit_soft_percentage=80
(2)tserver维护管理器线程数
Kudu后台对数据进行维护操作,如写入数据时的并发线程数,一般设置为4,建议的是数据目录的3倍 :
--maintenance_manager_num_threads=6
master和tserver都有这个配置只改tserver。
(3)调大tserver block cache容量
分配给Kudu Tablet Server块缓存的最大内存量,建议是2-4G:
--block_cache_capacity_mb=2048
(4) 避免磁盘耗尽
为避免磁盘空间耗尽,应该保留一部分空间:
#默认-1,表示保留1%的磁盘空间,自己配置是必须大于0
--fs_data_dirs_reserved_bytes
(5)容忍磁盘故障
如果某个tablet的数据分散到更多的磁盘,则数据会更加分散,这个值越小每个tablet的数据会更加集中,不过受磁盘故障影响就越小。
#每个tablet的数据分散到几个目录
fs_target_data_dirs_per-tablet=3
透明分层存储案例分析
需求分析
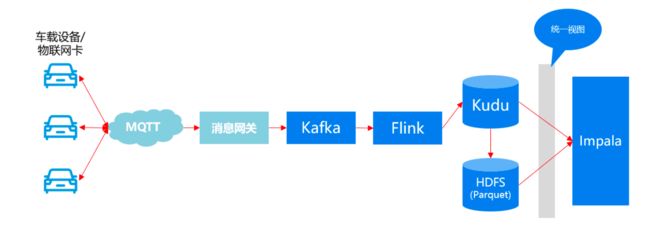
某车联网系统架构如下:

随着业务的发展整体架构存在如下问题:
- 分析模块实时性不高
- 业务系统和报表系统经常出现数据对不上的情况
- HBase可用性不高
- 数据过度冗余成本高、维护复杂
再继续拓展业务之前需要把系统架构进一步升级以解决上述问题。
方案设计
架构设计

上面架构如何解决之前存在问题的:
- Kudu可以实时入库、实时分析
- 车载设备上传的数据只有Kudu+HDFS(Parquet)一份,不存在不一致的问题
- Kudu的tablet有可靠的副本机制,可用性比HBase高
- 车载设备上传的数据只有Kudu+HDFS(Parquet)一份,不存在数据过度冗余问题,可维护性更好
数据流:
分层存储设计

以电池温度数据为例,进行分层存储设计如下:
(1)核心字段说明
假定电池温度数据有如下核心字段:
{
deviceid:3455224435.
platenumber:"京A-12345"
batteryid: 123
detecttime:"2019-01-01",
temperature:45.5
}
网关服务会把原始的mqtt消息转换为json。
注意:为了实验效果我这里的detecttime精确到天,实际业务中肯定是精确到毫秒。
(2) Kudu表
数据首先会写入Kudu表,在lmpala中的建表语句如下:
CREATE TABLE battery_temp_data_kudu
(
deviceid INT,
batteryid TINYINT,
detecttime TIMESTAMP,
platenumber STRING,
temperature DECIMAL(4,1),
PRIMARY KEY(deviceid,batteryid,detecttime)
)
PARTITION BY
HASH(deviceid) PARTITIONS 6,
RANGE(detecttime) (
PARTITION '2019-01-01' <= VALUES < '2019-02-01',
PARTITION '2019-02-01' <= VALUES < '2019-03-01',
PARTITION '2019-03-01' <= VALUES < '2019-04-01',
PARTITION '2019-04-01' <= VALUES < '2019-05-01'
)
STORED AS KUDU;
INSERT INTO battery_temp_data_kudu VALUES
(345522443, 1,"2019-01-01","苏A-12345",23.5),
(345552443, 2,"2019-01-01","苏A-12345",45.6),
(345578443, 3,"2019-01-01","苏A-12345",56.7);
(3)HDFS表
Kudu表中的数据会定期刷写成Parquet文件加载到HDFS表,在Impala中的建表语句如下:
CREATE TABLE battery_temp_data_parquet
(
deviceid INT,
batteryid TINYINT,
detecttime TIMESTAMP,
platenumber STRING,
temperature DECIMAL(4,1)
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET;
(4)同一视图
Kudu和HDFS两张表的数据需要对外提供统一视图,以确保检索和分析数据的完整性、一致性,在Impala中的创建统一视图的语句如下:
CREATE VIEW battery_temp_data_view AS
SELECT deviceid, batteryid, detecttime, platenumber, temperature
FROM battery_temp_data_kudu
WHERE detecttime >= "2019-01-01"
UNION ALL
SELECT deviceid, batteryid, detecttime, platenumber, temperature
FROM battery_temp_data_parquet
WHERE detecttime < "2019-01-01"
AND year = year(detecttime)
AND month = month(detecttime)
AND day = day(detecttime);
注意1:where子句中的边界可以确保数据在两个表之间复制是不会读取重复数据
注意2:从HDFS表查询数据时用AND指定了年月日,这样可以谓词下推直接跳过不必要的分区
注意3:要使用UNION ALL,UNION虽然会去重但是性能差,去重是由where子句指定的边界来搞定的
(5)数据迁移语句与执行脚本
Kudu表中的数据定期迁移到HDFS表的脚本window_data_move.sql:
INSERT INTO ${var:hdfs_table} PARTITION (year, month, day)
SELECT *, year(detecttime), month(detecttime), day(detecttime)
FROM ${var:kudu_table}
WHERE detecttime >= add_months("${var:new_boundary_time}", -1)
AND detecttime < "${var:new_boundary_time}";
COMPUTE INCREMENTAL STATS ${var:hdfs_table};
注意:COMPUTE INCREMENTAL STATS指Impala会对HDFS表的各个分区进行统计,对查询性能有帮助,不是必需的。
执行脚本如下:
impala-shell -i node02:21000 -f window_data_move.sql
--var=kudu_table=battery_temp_data_kudu
--var=hdfs_table=battery_temp_data_parquet
--var=new_boundary_time="2019-02-01"
(6)修改视图语句与执行脚本
修改统一视图脚本window_view_alter.sql:
ALTER VIEW ${var:view_name} AS
SELECT deviceid, batteryid, detecttime, platenumber, temperature
FROM ${var:kudu_table}
WHERE detecttime >= "${var:new_boundary_time}"
UNION ALL
SELECT deviceid, batteryid, detecttime, platenumber, temperature
FROM ${var:hdfs_table}
WHERE detecttime < "${var:new_boundary_time}"
AND year = year(detecttime)
AND month = month(detecttime)
AND day = day(detecttime);
执行脚本如下:
impala-shell -i node02:21000 -f window_view_alter.sql
--var=view_name=battery_temp_data_view
--var=kudu_table=battery_temp_data_kudu
--var=hdfs_table=battery_temp_data_parquet
--var=new_boundary_time="2019-02-01"
(7)删除和新建Kudu表分区语句与执行脚本
删除和新建kudu表分区的语句window_partition_shift.sql:
ALTER TABLE ${var:kudu_table}
ADD RANGE PARTITION add_months("${var:new_boundary_time}",
${var:window_length}) <= VALUES < add_months("${var:new_boundary_time}",
${var:window_length} + 1);
ALTER TABLE ${var:kudu_table}
DROP RANGE PARTITION add_months("${var:new_boundary_time}", -1)
<= VALUES < "${var:new_boundary_time}";
执行脚本如下:
impala-shell -i node02:21000 -f window_partition_shift.sql
--var=kudu_table=battery_temp_data_kudu
--var=new_boundary_time="2019-02-01"
--var=window_length=3
模拟数据
我们直接利用之前的工程,新增如下依赖:
<dependency>
<groupId>com.github.javafakergroupId>
<artifactId>javafakerartifactId>
<version>1.0.1version>
dependency>
创建com.djt.kudu.datasimulator.BatteryTempDateSimulator类:
package com.djt.kudu.datasimulator;
import com.github.javafaker.Faker;
import org.apache.kudu.Schema;
import org.apache.kudu.client.*;
import org.junit.Test;
import java.math.BigDecimal;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Locale;
public class BatteryTempDateSimulator {
private static final String KUDU_MASTER =
"node01:7051,node02:7051,node03:7051";
public static void simulator(String detecttime) throws Exception{
Faker faker = new Faker(new Locale("zh-CN"));
List<String> shortNames =
Arrays.asList("苏","京","津","晋","冀","蒙","辽","吉","浙","闽");
//1、获取KuduClient
KuduClient client = null;
KuduTable table = null;
KuduSession session = null;
String tableName = "impala::default.battery_temp_data_kudu";
try{
client = new KuduClient.KuduClientBuilder(KUDU_MASTER).build();
//2、打开表KuduTable
table = client.openTable(tableName);
//3、创建会话KuduSession
session = client.newSession();
session.setFlushInterval(1000);
//4、循环插入数据
for (int i = 0; i < 1000000; i++) {
Insert insert = table.newInsert();
PartialRow row=insert.getRow();
//生成模拟数据
int deviceid =
faker.number().numberBetween(100000000,999999999);
String platenumber =
shortNames.get(faker.number().numberBetween(0,9))+"-
"+faker.number().numberBetween(100000,999999);
int batteryid = faker.number().numberBetween(1,20);
double temperature = faker.number().randomDouble(1,15,100);
row.addInt("deviceid",deviceid);
row.addString("platenumber",platenumber);
row.addByte("batteryid",Byte.parseByte(batteryid+""));
row.addDecimal("temperature",BigDecimal.valueOf(temperature));
row.addTimestamp("detecttime", Timestamp.valueOf(detecttime));
session.apply(insert);
}
//5、session关闭
session.close();
//判断错误数
if(session.countPendingErrors()!=0){
RowErrorsAndOverflowStatus result = session.getPendingErrors();
if(result.isOverflowed()){
System.out.println("----------------------buffer溢出!--------
--------------");
}
RowError[] errs = result.getRowErrors();
for(RowError error:errs){
System.out.println(error);
}
}
}finally {
//6、关闭资源
if(null!=client){
client.close();
}
}
}
public static void main(String[] args) throws Exception {
simulator("2019-01-02 00:00:00");
}
@Test
public void testSelect() throws KuduException {
//1、获取KuduClient
KuduClient client = null;
//2、打开表
KuduTable table = null;
String tableName = "impala::default.battery_temp_data_kudu";
try {
client = new KuduClient.KuduClientBuilder(KUDU_MASTER).build();
table = client.openTable(tableName);
//3、指定查询条件
Schema schema = table.getSchema();
List<String> columnNames = new ArrayList<>();
columnNames.add("deviceid");
columnNames.add("batteryid");
columnNames.add("detecttime");
columnNames.add("platenumber");
columnNames.add("temperature");
//4、获取扫描器
KuduScanner scanner = client.newScannerBuilder(table)
.setProjectedColumnNames(columnNames)
.build();
//5、查询并处理结果集
int resCount = 0;
while (scanner.hasMoreRows()){
RowResultIterator results = scanner.nextRows();
while (results.hasNext()){
RowResult res = results.next();
int deviceid = res.getInt("deviceid");
String batteryid = res.getByte("batteryid")+"";
String detecttime =
res.getTimestamp("detecttime").toString();
String platenumber = res.getString("platenumber");
String temperature=res.getDecimal("temperature").toString();
System.out.printf("deviceid=%d,batteryid=%s,detecttime=%s,platenumber=%s,temper
ature=%srn",deviceid,batteryid,detecttime,platenumber,temperature);
resCount++;
}
}
System.out.println("resCount="+resCount);
scanner.close();
}finally {
//7、回收资源
if(null!=client){
client.close();
}
}
}
}
构建数据流水线
按照如下步骤来执行:
- 建表s
- 开启模拟程序
- 模拟数据迁移
数据验证
我们通过以下几条语句,来证明Impala统一视图的有效性(分层架构的有效性):
select count(1) from battery_temp_data_kudu where detecttime >= "2019-01-01" and
detecttime< "2019-02-01";
select count(1) from battery_temp_data_kudu where detecttime >= "2019-02-01" and
detecttime< "2019-03-01";
select count(1) from battery_temp_data_kudu where detecttime >= "2019-03-01" and
detecttime< "2019-04-01";
select count(1) from battery_temp_data_kudu where detecttime >= "2019-04-01" and
detecttime< "2019-05-01";
select count(1) from battery_temp_data_parquet where detecttime >= "2019-01-01"
and detecttime< "2019-02-01";
select count(1) from battery_temp_data_parquet where detecttime >= "2019-02-01"
and detecttime< "2019-03-01";
select count(1) from battery_temp_data_parquet where detecttime >= "2019-03-01"
and detecttime< "2019-04-01";
select count(1) from battery_temp_data_parquet where detecttime >= "2019-04-01"
and detecttime< "2019-05-01";
select count(1) from battery_temp_data_view where detecttime >= "2019-01-01" and
detecttime< "2019-02-01";
select count(1) from battery_temp_data_view where detecttime >= "2019-02-01" and
detecttime< "2019-03-01";
select count(1) from battery_temp_data_view where detecttime >= "2019-03-01" and
detecttime< "2019-04-01";
select count(1) from battery_temp_data_view where detecttime >= "2019-04-01" and
detecttime< "2019-05-01";