Logstash、Mysql、Elasticsearch实现数据互通
Logstash连接Mysql并把数据同步到Es中
-
- 一、Logstash部署
-
-
- Windows:
- Linux:
-
- 二、Logstash连接Mysql
- 三、Logstash通过Mysql同步数据到Es
前期准备:
Logstash7.17.2
Mysql5.7
Elasticsearch7.9.2
一、Logstash部署
Logstash简介:是ELK技术栈中的L,是数据采集引擎,可以从数据库、消息队列等数据源采集数据,设置过滤条件,输出到ElasticSearch等多种数据源中。
Windows:
Logstash实现步骤:
1.下载安装
注意版本要和自己的es版本一致
下载地址https://www.elastic.co/cn/downloads/past-releases#logstash
2.下载后解压Logstash压缩包,在根目录下的config文件夹中复制logstash-sample.conf到bin文件夹中,并改名为logstash.conf文件(主要是需要conf格式,以及之后按照conf参数运行logstash)
3.修改logstash.conf
input {
stdin {
}
jdbc {
# 配置数据库信息
jdbc_connection_string => "jdbc:mysql://localhost:3306/legalretrievalsystem?useUnicode=true&useJDBCCompliantTimezoneShift=true&tinyInt1isBit=false&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "15907007907aB"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "50000"
jdbc_default_timezone => "Asia/Shanghai"
# mysql驱动所在位置建议通过Maven下载
jdbc_driver_library => "E:\repository\mysql\mysql-connector-java\8.0.22\mysql-connector-java-8.0.22.jar"
# 标志目前logstash同步的位置信息(类似offset)。比如id、updatetime。logstash通过这个标志,可以判断目前同步到哪一条数据。
parameters => { "sql_last_value" => "UpdateTime" }
#sql执行语句
statement => "SELECT document_id,document_name,case_cause_name,document_num,court_name,case_type_name,trial_procedure_name,DATE_FORMAT(judgement_date,'%Y-%m-%d')judgement_date,party,legal_auth,full_text,document_type_name,court_level, DATE_FORMAT(create_time,'%Y/%m/%d %H:%i:%s')create_time, DATE_FORMAT(update_time,'%Y/%m/%d %H:%i:%s')update_time,is_deleted FROM legal_document WHERE update_time >=:sql_last_value"
# 定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
#schedule => "* * * * *"
#"*/5 * * * * *" 表示每 5 秒轮询一次。
schedule => "*/5 * * * * *"
# 是否将 sql 中 column 名称转小写
lowercase_column_names => false
#编码格式 UTF-8
codec => plain { charset => "UTF-8"}
}
}
filter {
json {
#要解析的字段名https://blog.51cto.com/wzlinux/2329811
source => "message"
#用 remove_field 参数来删除掉 message 字段https://blog.csdn.net/m0_47454596/article/details/123494564
remove_field => ["message"]
}
# 映射字段匿名 可填可不填
mutate {
rename => { "document_id" => "documentId"}
rename => { "document_name" => "documentName"}
rename => { "case_cause_name" => "caseCauseName"}
rename => { "document_num" => "documentNum"}
rename => { "court_name" => "courtName"}
rename => { "case_type_name" => "caseTypeName"}
rename => { "trial_procedure_name" => "trialProcedureName"}
rename => { "judgement_date" => "judgementDate"}
rename => { "legal_auth" => "legalAuth"}
rename => { "full_text" => "fullText"}
rename => { "document_type_name" => "documentTypeName"}
rename => { "court_level" => "courtLevel"}
rename => { "create_time" => "createTime"}
rename => { "update_time" => "updateTime"}
rename => { "is_deleted" => "isDeleted"}
convert => ["documentId","string"]
#将字段documentId进行类型转化,转化到string(因为document_id已经被重命名为documentId,所以这里是documentId)
}
}
output {
elasticsearch {
#es的ip和端口
hosts => ["127.0.0.1:9200"]
#ES索引名称(自己定义的)
index => "legaldocuments"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{id}"
}
stdout { #标准输出
codec => json_lines
}
}
4.在bin目录下打开cmd,输入命令:
logstash -f logstash.conf
5.打开浏览器,浏览器显示以下内容代表成功。
http://localhost:9600/
![]()
Linux:
https://blog.csdn.net/Amber_1/article/details/124315986
二、Logstash连接Mysql
单表同步:

多表同步:
input {
stdin {}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_DetailTab"
# 其他配置此处省略,参考单表配置
# ...
# ...
#sql执行语句
statement =>"select * from xxx"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
#
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_Tab2"
# 多表同步时,last_run_metadata_path配置的路径应不一致,避免有影响;
# 其他配置此处省略
# ...
# ...
}
}
filter {
json {
#要解析的字段名https://blog.51cto.com/wzlinux/2329811
source => "message"
#用 remove_field 参数来删除掉 message 字段https://blog.csdn.net/m0_47454596/article/details/123494564
remove_field => ["message"]
}
}
output {
# output模块的type需和jdbc模块的type一致
if [type] == "TestDB_DetailTab" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
#hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 单独Es地址
hosts => ["192.168.1.1:9200"]
# 索引名字,必须小写
index => "detailtab1"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
if [type] == "TestDB_Tab2" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
#hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 单独Es地址
hosts => ["192.168.1.1:9200"]
# 索引名字,必须小写
index => "detailtab2"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
}
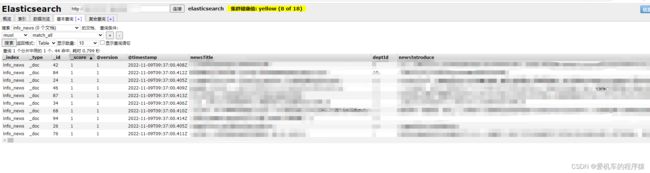
三、Logstash通过Mysql同步数据到Es
改为配置后进入bin下重新启动:logstash -f logstash.conf

查看Es数据是否存进去了