Flink - sink算子
水善利万物而不争,处众人之所恶,故几于道
文章目录
1. Kafka_Sink
2. Kafka_Sink - 自定义序列化器
3. Redis_Sink_String
4. Redis_Sink_list
5. Redis_Sink_set
6. Redis_Sink_hash
7. 有界流数据写入到ES
8. 无界流数据写入到ES
9. 自定义sink - mysql_Sink
10. Jdbc_Sink
官方文档 - Flink1.13

1. Kafka_Sink
addSink(new FlinkKafkaProducer< String>(kafka_address,topic,序列化器)
要先添加依赖:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.12artifactId>
<version>1.13.6version>
dependency>
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
stream
.keyBy(WaterSensor::getId)
.sum("vc")
.map(JSON::toJSONString)
.addSink(new FlinkKafkaProducer<String>(
"hadoop101:9092", // kafaka地址
"flink_sink_kafka", //要写入的Kafkatopic
new SimpleStringSchema() // 序列化器
));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

2. Kafka_Sink - 自定义序列化器
自定义序列化器,new FlinkKafkaProducer()的时候,选择四个参数的构造方法,然后使用new KafkaSerializationSchema序列化器。然后重写serialize方法
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
Properties sinkConfig = new Properties();
sinkConfig.setProperty("bootstrap.servers","hadoop101:9092");
stream
.keyBy(WaterSensor::getId)
.sum("vc")
.addSink(new FlinkKafkaProducer<WaterSensor>(
"defaultTopic", // 默认发往的topic ,一般用不上
new KafkaSerializationSchema<WaterSensor>() { // 自定义的序列化器
@Override
public ProducerRecord<byte[], byte[]> serialize(
WaterSensor waterSensor,
@Nullable Long aLong
) {
String s = JSON.toJSONString(waterSensor);
return new ProducerRecord<>("flink_sink_kafka",s.getBytes(StandardCharsets.UTF_8));
}
},
sinkConfig, // Kafka的配置
FlinkKafkaProducer.Semantic.AT_LEAST_ONCE // 一致性语义:现在只能传入至少一次
));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

3. Redis_Sink_String
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到String结构里面
添加依赖:
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.83version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.1.5version>
dependency>
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
/*
往redis里面写字符串,string 命令提示符用set
假设写的key是id,value是整个json格式的字符串
key value
sensor_1 json格式字符串
*/
// new一个单机版的配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop101")
.setPort(6379)
.setMaxTotal(100) //最大连接数量
.setMaxIdle(10) // 连接池里面的最大空闲
.setMinIdle(2) // 连接池里面的最小空闲
.setTimeout(10*1000) // 超时时间
.build();
// 写出到redis中
result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {
// 返回命令描述符:往不同的数据结构写数据用的方法不一样
@Override
public RedisCommandDescription getCommandDescription() {
// 写入到字符串,用set
return new RedisCommandDescription(RedisCommand.SET);
}
@Override
public String getKeyFromData(WaterSensor waterSensor) {
return waterSensor.getId();
}
@Override
public String getValueFromData(WaterSensor waterSensor) {
return JSON.toJSONString(waterSensor);
}
}));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

4. Redis_Sink_list
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 list 结构里面
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
// key是id,value是处理后的json格式字符串
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop101")
.setPort(6379)
.setMaxTotal(100) //最大连接数量
.setMaxIdle(10) // 连接池里面的最大空闲
.setMinIdle(2) // 连接池里面的最小空闲
.setTimeout(10*1000) // 超时时间
.build();
result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {
@Override
public RedisCommandDescription getCommandDescription() {
// 写入list
return new RedisCommandDescription(RedisCommand.RPUSH);
}
@Override
public String getKeyFromData(WaterSensor waterSensor) {
return waterSensor.getId();
}
@Override
public String getValueFromData(WaterSensor waterSensor) {
return JSON.toJSONString(waterSensor);
}
}));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:
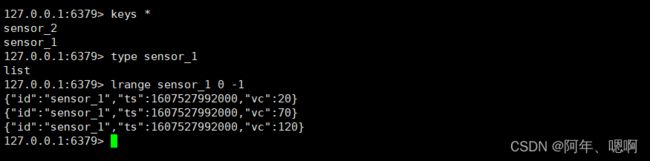
5. Redis_Sink_set
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 set 结构里面
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop101")
.setPort(6379)
.setMaxTotal(100)
.setMaxIdle(10)
.setMinIdle(2)
.setTimeout(10*1000)
.build();
result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {
@Override
public RedisCommandDescription getCommandDescription() {
// 数据写入set集合
return new RedisCommandDescription(RedisCommand.SADD);
}
@Override
public String getKeyFromData(WaterSensor waterSensor) {
return waterSensor.getId();
}
@Override
public String getValueFromData(WaterSensor waterSensor) {
return JSON.toJSONString(waterSensor);
}
}));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:
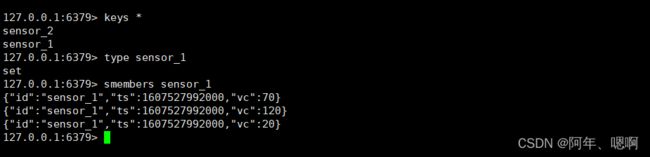
6. Redis_Sink_hash
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 hash结构里面
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop101")
.setPort(6379)
.setMaxTotal(100)
.setMaxIdle(10)
.setMinIdle(2)
.setTimeout(10*1000)
.build();
result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {
@Override
public RedisCommandDescription getCommandDescription() {
// 数据写入hash
return new RedisCommandDescription(RedisCommand.HSET,"a");
}
@Override
public String getKeyFromData(WaterSensor waterSensor) {
return waterSensor.getId();
}
@Override
public String getValueFromData(WaterSensor waterSensor) {
return JSON.toJSONString(waterSensor);
}
}));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

7. 有界流数据写入到ES中
new ElasticsearchSink.Builder()
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
List<HttpHost> hosts = Arrays.asList(
new HttpHost("hadoop101", 9200),
new HttpHost("hadoop102", 9200),
new HttpHost("hadoop103", 9200)
);
ElasticsearchSink.Builder<WaterSensor> builder = new ElasticsearchSink.Builder<WaterSensor>(
hosts,
new ElasticsearchSinkFunction<WaterSensor>() {
@Override
public void process(WaterSensor element, // 需要写出的元素
RuntimeContext runtimeContext, // 运行时上下文 不是context上下文对象
RequestIndexer requestIndexer) { // 把要写出的数据,封装到RequestIndexer里面
String msg = JSON.toJSONString(element);
IndexRequest ir = Requests
.indexRequest("sensor")
.type("_doc") // 定义type的时候, 不能下划线开头. _doc是唯一的特殊情况
.id(element.getId()) // 定义每条数据的id. 如果不指定id, 会随机分配一个id. id重复的时候会更新数据
.source(msg, XContentType.JSON);
requestIndexer.add(ir); // 把ir存入到indexer, 就会自动的写入到es中
}
}
);
result.addSink(builder.build());
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
8. 无界流数据写入到ES
和有界差不多 ,只不过把数据源换成socket,然后因为无界流,它高效不是你来一条就刷出去,所以设置刷新时间、大小、条数,才能看到结果。public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> result = env.socketTextStream("hadoop101",9999)
.map(line->{
String[] data = line.split(",");
return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));
})
.keyBy(WaterSensor::getId)
.sum("vc");
List<HttpHost> hosts = Arrays.asList(
new HttpHost("hadoop101", 9200),
new HttpHost("hadoop102", 9200),
new HttpHost("hadoop103", 9200)
);
ElasticsearchSink.Builder<WaterSensor> builder = new ElasticsearchSink.Builder<WaterSensor>(
hosts,
new ElasticsearchSinkFunction<WaterSensor>() {
@Override
public void process(WaterSensor element, // 需要写出的元素
RuntimeContext runtimeContext, // 运行时上下文 不是context上下文对象
RequestIndexer requestIndexer) { // 把要写出的数据,封装到RequestIndexer里面
String msg = JSON.toJSONString(element);
IndexRequest ir = Requests
.indexRequest("sensor")
.type("_doc") // 定义type的时候, 不能下划线开头. _doc是唯一的特殊情况
.id(element.getId()) // 定义每条数据的id. 如果不指定id, 会随机分配一个id. id重复的时候会更新数据
.source(msg, XContentType.JSON);
requestIndexer.add(ir); // 把ir存入到indexer, 就会自动的写入到es中
}
}
);
// 自动刷新时间
builder.setBulkFlushInterval(2000); // 默认不会根据时间自动刷新
builder.setBulkFlushMaxSizeMb(1024); // 当批次中的数据大于等于这个值刷新
builder.setBulkFlushMaxActions(2); // 每来多少条数据刷新一次
// 这三个是或的关系,只要有一个满足就会刷新
result.addSink(builder.build());
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
9. 自定义sink - mysql_Sink
需要写一个类,实现RichSinkFunction,然后实现invoke方法。这里因为是写MySQL所以需要建立连接,那就用Rich版本。
记得导入MySQL依赖
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
result.addSink(new MySqlSink());
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MySqlSink extends RichSinkFunction<WaterSensor> {
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName("com.mysql.cj.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:mysql://hadoop101:3306/test?useSSL=false", "root", "123456");
}
@Override
public void close() throws Exception {
if (connection!=null){
connection.close();
}
}
// 调用:每来一条元素,这个方法执行一次
@Override
public void invoke(WaterSensor value, Context context) throws Exception {
// jdbc的方式想MySQL写数据
// String sql = "insert into sensor(id,ts,vc)values(?,?,?)";
//如果主键不重复就新增,主键重复就更新
// String sql = "insert into sensor(id,ts,vc)values(?,?,?) duplicate key update vc=?";
String sql = "replace into sensor(id,ts,vc)values(?,?,?)";
// 1. 得到预处理语句
PreparedStatement ps = connection.prepareStatement(sql);
// 2. 给sql中的占位符进行赋值
ps.setString(1,value.getId());
ps.setLong(2,value.getTs());
ps.setInt(3,value.getVc());
// ps.setInt(4,value.getVc());
// 3. 执行
ps.execute();
// 4. 提交
// connection.commit(); MySQL默认自动提交,所以这个地方不用调用
// 5. 关闭预处理
ps.close();
}
}
运行结果:

10. Jdbc_Sink
addSink(JdbcSink.sink(sql,JdbcStatementBuilder,执行参数,连接参数)
对于jdbc数据库,我们其实没必要自定义,因为官方给我们了一个JDBC Sink -> 官方JDBC Sink 传送门
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbc_2.11artifactId>
<version>1.13.6version>
dependency>
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));
waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));
DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);
SingleOutputStreamOperator<WaterSensor> result = stream
.keyBy(WaterSensor::getId)
.sum("vc");
result.addSink(JdbcSink.sink(
"replace into sensor(id,ts,vc)values(?,?,?)",
new JdbcStatementBuilder<WaterSensor>() {
@Override
public void accept(
PreparedStatement ps,
WaterSensor waterSensor) throws SQLException {
// 只做一件事:给占位符赋值
ps.setString(1,waterSensor.getId());
ps.setLong(2,waterSensor.getTs());
ps.setInt(3,waterSensor.getVc());
}
},
new JdbcExecutionOptions.Builder() //设置执行参数
.withBatchSize(1024) // 刷新大小上限
.withBatchIntervalMs(2000) //刷新间隔
.withMaxRetries(3) // 重试次数
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://hadoop101:3306/test?useSSL=false")
.withUsername("root")
.withPassword("123456")
.build()
));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:
