22.Netty源码之解码器
highlight: arduino-light
抽象解码类
https://mp.weixin.qq.com/s/526p5f9fgtZu7yYq5j7LiQ
解码器
Netty 常用解码器类型:
- ByteToMessageDecoder/ReplayingDecoder 将字节流解码为消息对象;
- MessageToMessageDecoder 将一种消息类型解码为另外一种消息类型。
自定义一次解码器ByteToMessageDecoder解码器,如果读到的字节大小为4,那么认为读取到了1个完整的数据包。
java class VersionDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf in, List
自定义二次解码器,用于将String转换为Integer
java class StringToIntegerDecoder extends MessageToMessageDecoder
此时使用一次解码器+二次解码器完成了Byte到String、String到Integer的转换。
为什么要粘包拆包
为什么要粘包
首先你得了解一下TCP/IP协议,在用户数据量非常小的情况下,极端情况下,一个字节,该TCP数据包的有效载荷非常低,传递100字节的数据,需要100次TCP传送,100次ACK,在应用及时性要求不高的情况下,将这100个有效数据拼接成一个数据包,那会缩短到一个TCP数据包,以及一个ack,有效载荷提高了,带宽也节省了。
非极端情况,有可能两个数据包拼接成一个数据包,也有可能一个半的数据包拼接成一个数据包,也有可能两个半的数据包拼接成一个数据包。
为什么要拆包
拆包和粘包是相对的,一端粘了包,另外一端就需要将粘过的包拆开。
举个栗子,发送端将三个数据包粘成两个TCP数据包发送到接收端,接收端就需要根据应用协议将三个数据包拆分成两个数据包
还有一种情况就是用户数据包超过了mss(最大报文长度),那么这个数据包在发送的时候必须拆分成几个数据包,接收端收到之后需要将这些数据包粘合起来之后,再拆开。
拆包的原理
在没有netty的情况下,用户如果自己需要拆包,基本原理就是不断从TCP缓冲区中读取数据,每次读取完都需要判断是否是一个完整的数据包
1.如果当前读取的数据不足以拼接成一个完整的业务数据包,那就保留该数据,继续从tcp缓冲区中读取,直到得到一个完整的数据包
2.如果当前读到的数据加上已经读取的数据足够拼接成一个数据包,那就将已经读取的数据拼接上本次读取的数据,够成一个完整的业务数据包传递到业务逻辑,多余的数据仍然保留,以便和下次读到的数据尝试拼接。
netty 中的拆包也是如上这个原理,内部会有一个累加器,每次读取到数据都会不断累加,然后尝试对累加到的数据进行拆包,拆成一个完整的业务数据包,这个基类叫做 ByteToMessageDecoder,下面我们先详细分析下这个类
同样,我们先看下抽象解码类的继承关系图。
解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。
解码器实现的难度要远大于编码器,因为解码器需要考虑拆包/粘包问题。
由于接收方有可能没有接收到完整的消息,所以解码框架需要对入站的数据做缓冲操作,直至获取到完整的消息。

一次解码器ByteToMessageDecoder
ByteToMessageDecoder 中定义了两个累加器
2种累加器
Cumulator
每次将读取到的数据累加。
方式1:默认是内存复制的方式累加.如果内存不够先扩容。MERGE_CUMULATOR
方式2:组合的方式,避免内存复制。
MERGE_CUMULATOR
默认情况下,会使用 MERGE_CUMULATOR。
MERGE_CUMULATOR 的原理是每次都将读取到的数据通过内存拷贝的方式,拼接到一个大的字节容器中,这个字节容器在 ByteToMessageDecoder中叫做 cumulation。
下面我们看一下 MERGE_CUMULATOR 是如何将新读取到的数据累加到字节容器里的
java public static final Cumulator MERGE_CUMULATOR = new Cumulator() { @Override public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) { try { final ByteBuf buffer; if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes() || cumulation.refCnt() > 1 || cumulation.isReadOnly()) { //按需扩容 buffer = expandCumulation(alloc, cumulation, in.readableBytes()); } else { buffer = cumulation; } buffer.writeBytes(in); return buffer; } finally { in.release(); } } };
netty 中ByteBuf的抽象,使得累加非常简单。通过一个简单的api调用 buffer.writeBytes(in);
便将新数据累加到字节容器中,为了防止字节容器大小不够,在累加之前还进行了扩容处理
java static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) { ByteBuf oldCumulation = cumulation; cumulation = alloc.buffer(oldCumulation.readableBytes() + readable); cumulation.writeBytes(oldCumulation); oldCumulation.release(); return cumulation; }
扩容也是一个内存拷贝操作,新增的大小即是新读取数据的大小。
ByteToMessageDecoder:拆包原理
利用NIO进行网络编程时,往往需要将读取到的字节数或者字节缓冲区解码为业务可以使用的POJO对象。
Netty提供了ByteToMessageDecoder抽象工具解码类。
用户的解码器继承ByteToMessageDecoder,只需要实现decode()方法,即可完成ByteBuf到POJO对象的解码。 不过ByteToMessageDecoder没有考虑TCP粘包和组包等场景,读半包需要用户自己处理,因此我们可以继承更高级的解码器进行半包处理。
首先,我们看下ByteToMessageDecoder的子类FixedLengthFrameDecoder定义的方法:
```java public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter { /* channelRead方法是每次从TCP缓冲区读到数据都会调用的方法 触发点在AbstractNioByteChannel的read方法中 里面有个while循环不断读取,读取到一次就触发一次channelRead。
1.累加数据到字节容器cumulation。 2.将累加到的数据的字节容器传递给业务进行业务拆包 3.清理字节容器 4.传递业务数据包给业务解码器处理 */ @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { //if开始 判断类型是否匹配 if (msg instanceof ByteBuf) { CodecOutputList out = CodecOutputList.newInstance(); try { ByteBuf data = (ByteBuf) msg; //1.累加数据 //if:当前累加器没有数据,就直接跳过内存拷贝,直接将字节容器的指针指向新读取的数据。 //else:调用累加器累加数据至字节容器 first = cumulation == null; if (first) { //数据累加器 cumulation = data; } else { cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data); } //调用decode方法 //2.将累加到的数据传递给业务进行拆包 //将尝试将字节容器的数据拆分成业务数据包塞到业务数据容器out中 callDecode(ctx, cumulation, out); } catch (DecoderException e) { throw e; } } catch (Exception e) { throw new DecoderException(e); } finally {
//何为可读:writerIndex > readerIndex //何为不可读:writerIndex <= readerIndex //不可读说明已经读完了! //如果累加器不等于空 也不可读 //那么执行清理逻辑 if (cumulation != null && !cumulation.isReadable()) { //3.清理字节容器 //业务拆包完成之后,只是从字节容器中取走了数据。 //但是这部分空间对于字节容器来说依然保留着。 //而字节容器每次累加字节数据的时候都是将字节数据追加到尾部 //如果不对字节容器做清理,那么时间一长就会OOM。 //正常情况下,其实每次读取完数据,netty都会在下面这个discardSomeReadBytes方法中 //将字节容器清理 //只不过,当发送端发送数据过快,channelReadComplete可能会很久才被调用一次 //如果一次数据读取完毕之后,可能接收端一边收,发送端一边发。 //这里的读取完毕指的是接收端在某个时间不再接受到数据为止。 //发现仍然没有拆到一个完整的用户数据包,即使该channel的设置为非自动读取 //也会触发一次读取操作 ctx.read(),该操作会重新向selector注册op_read事件 //以便于下一次能读到数据之后拼接成一个完整的数据包 //所以为了防止发送端发送数据过快,netty会在每次读取到一次数据 //业务拆包之后对字节字节容器做清理,清理部分的代码如下 numReads = 0; cumulation.release(); cumulation = null; } else if (++ numReads >= discardAfterReads) { //如果字节容器当前已无数据可读取,直接销毁字节容器 //并且标注一下当前字节容器一次数据也没读取 //如果连续16次,discardAfterReads的默认值为16 //字节容器中仍然有未被业务拆包器读取的数据, //那就做一次压缩,有效数据段整体移到容器首部 numReads = 0; discardSomeReadBytes(); } int size = out.size(); firedChannelRead |= out.insertSinceRecycled(); //4.传递业务数据包给业务解码器处理 //触发channelRead事件 将拆到的业务数据包都传递到后续的handler //这样就可以把一个个完整的业务数据包传递到后续的业务解码器进行解码,随后处理业务逻辑 fireChannelRead(ctx, out, size); out.recycle(); } //if开始对应的else判断类型是否匹配 } else { ctx.fireChannelRead(msg); } } } //frameLength=4,如果先发送2字节再发送2字节 //那么是否存在解码出现异常的情况? //答案:不会,因为有一个死循环 //比如发送方先发送了2字节的数据,然后发送方又发来了2字节 //首先原子累加器累加2字节传入callDecode方法的in,in是累加器cumulation //in.isReadable()判断可读,调用decode方法,decode方法会判断如果不够4字节 直接return跳出死循环 //然后发送方又发来2字节,然后继续累加到原子累加器 //判断可读调用decode方法。
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List out) { try { while (in.isReadable()) { int outSize = out.size(); //判断out有数据就触发fireChannelRead //out什么时候有的数据? //在子类的decode方法中 if (outSize > 0) { fireChannelRead(ctx, out, outSize); out.clear(); if (ctx.isRemoved()) { break; } outSize = 0; } //decode在这里被调用 //decode中时,不能执行完handler remove清理操作。 //那decode完之后需要清理数据。 int oldInputLength = in.readableBytes(); decodeRemovalReentryProtection(ctx, in, out); if (ctx.isRemoved()) { break; } if (outSize == out.size()) { if (oldInputLength == in.readableBytes()) { break; } else { continue; } } if (oldInputLength == in.readableBytes()) { throw new DecoderException( StringUtil.simpleClassName(getClass()) + ".decode() did not read anything but decoded a message."); } if (isSingleDecode()) { break; } } } catch (DecoderException e) { throw e; } catch (Exception cause) { throw new DecoderException(cause); } } final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List out) throws Exception { decodeState = STATECALLINGCHILDDECODE; try { //模板模式 decode(ctx, in, out); } finally { boolean removePending = decodeState == STATEHANDLERREMOVEDPENDING; decodeState = STATE_INIT; if (removePending) { handlerRemoved(ctx); } } } //模板模式 //netty中对各种用户协议的支持就体现在这个抽象函数中 //传进去的in是累加器累加的数据 //是当前读取到的未被消费的所有的数据,以及业务协议包容器,所有的拆包器最终都实现了该抽象方法 //业务拆包完成之后,如果发现并没有拆到一个完整的数据包,这个时候又分两种情况 //1.一个是拆包器什么数据也没读取,可能数据还不够业务拆包器处理,直接break等待新的数据 //2.拆包器已读取部分数据,说明解码器仍然在工作,继续解码 protected abstract void decode (ChannelHandlerContext ctx, ByteBuf in, List out) throws Exception; //我们看下子类FixedLengthFrameDecoder#decode方法 @Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List out) throws Exception { //判断返回的字节不为空就加入 out Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } } protected Object decode( @SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception { //判断累加器中的字节数小于固定长度的字节长度 if (in.readableBytes() < frameLength) { //返回空 return null; } else { //否则返回可读的字节数 这里很重要 return in.readRetainedSlice(frameLength); } } protected void decodeLast (ChannelHandlerContext ctx, ByteBuf in, List out) throws Exception { if (in.isReadable()) { decodeRemovalReentryProtection(ctx, in, out); } } } ```
decode() 是用户必须实现的抽象方法,在该方法在调用时需要传入接收的数据 ByteBuf,及用来添加编码后消息的 List。
由于 TCP 粘包问题,ByteBuf 中可能包含多个有效的报文,或者不够一个完整的报文。
Netty 会重复回调 decode() 方法,直到没有解码出新的完整报文可以添加到 List 当中,或者 ByteBuf 没有更多可读取的数据为止。
如果此时 List 的内容不为空,那么会传递给 ChannelPipeline 中的下一个ChannelInboundHandler。触发channelRead方法。
此外 ByteToMessageDecoder 还定义了 decodeLast() 方法。
为什么抽象解码器要比编码器多一个 decodeLast() 方法呢?
因为 decodeLast 在 Channel 关闭后会被调用一次,主要用于处理 ByteBuf 最后剩余的字节数据。
Netty 中 decodeLast 的默认实现只是简单调用了 decode() 方法。如果有特殊的业务需求,则可以通过重写 decodeLast() 方法扩展自定义逻辑。
ByteToMessageDecoder 还有一个抽象子类是 ReplayingDecoder。
它封装了缓冲区的管理,在读取缓冲区数据时,你无须再对字节长度进行检查。因为如果没有足够长度的字节数据,ReplayingDecoder 将终止解码操作。
ReplayingDecoder 的性能相比直接使用 ByteToMessageDecoder 要慢,大部分情况下并不推荐使用 ReplayingDecoder。
二次解码器MessageToMessageDecoder
MessageToMessageDecoder实际上是Nety的二次解码器,从SocketChannel读取到的TCP数据报是ByteBuffer,先将解码为Java对象,再二次解码为POJO对象,因此称之为二次解码器。 以HTTP+XML协议栈为例,第一次解码是将字节数组解码成HttpRequest对象,然后对HttpRequest消息中的消息体字符串进行二次解码,将XML格式的字符串解码为POJO对象。 由于二次解码器是将一个POJO解码为另一个POJO,一般不涉及半包处理。
MessageToMessageDecoder 与 ByteToMessageDecoder 作用类似。
都是将一种消息类型的编码成另外一种消息类型。
与 ByteToMessageDecoder 不同的是 MessageToMessageDecoder 并不会对数据报文进行缓存,它主要用作转换消息模型。
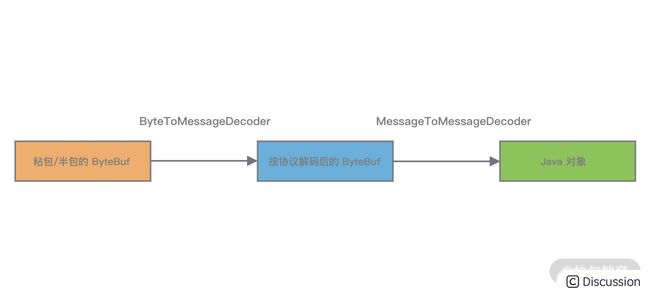
比较推荐的做法是使用 ByteToMessageDecoder 解析 TCP 协议,解决拆包/粘包问题。解析得到有效的 ByteBuf 数据,然后传递给后续的 MessageToMessageDecoder 做数据对象的转换,具体流程如下图所示。
三种常用的解码器
FixedLengthFrameDecoder
DelimiterBasedFrameDecoder
LengthFieldBasedFrameDecoder
固定长度:FixedLengthFrameDecoder
public class FixedLengthFrameDecoder extends ByteToMessageDecoder { private final int frameLength; public FixedLengthFrameDecoder(int frameLength) { checkPositive(frameLength, "frameLength"); this.frameLength = frameLength; } @Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List
通信协议实战★
在之前通信协议设计中我们提到了协议的基本要素并给出了一个较为通用的协议示例。
下面我们通过 Netty 的编辑码框架实现该协议的解码器,加深我们对 Netty 编解码框架的理解。
其实dubbo和rocketMq都是这种方式。
在实现协议编码器之前,我们首先需要清楚一个问题:如何判断 ByteBuf 是否存在完整的报文?
最常用的做法就是通过读取消息长度 dataLength 进行判断。
如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。
在该协议前面的消息头部分包含了魔数、协议版本号、数据长度等固定字段,共 14 个字节。
固定字段长度和数据长度可以作为我们判断消息完整性的依据,具体编码器实现逻辑示例如下:
java /* +---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | +---------------------------------------------------------------+ */ @Override public final void decode(ChannelHandlerContext ctx, ByteBuf in, List
总结
Netty 提供了一组 ChannelHandler 实现的抽象类,在项目开发中基于这些抽象类实现自定义的编解码器具备较好的可扩展性,最后我们通过具体示例协议的实战加深了对编解码器的理解。
当然 Netty 在编解码方面所做的工作远不止于此。它还提供了丰富的开箱即用的编解码器,下节课我们便一起探索实用的编解码技巧。