【python】基于multiprocessing.Pool实现python并行化的坑和解决方案
坑1:apply_async调用的子函数不执行或执行不彻底的解决方案
解决:使用apply_async时传入error_callback检查报错
from multiprocessing import Pool
def processFolder(idx, folders, o_dir):
train_mesh = TrainMeshes(folders)
output_path = os.path.join(o_dir, str(idx) + '.pkl')
pickle.dump(train_mesh, file=open(output_path, "wb"))
if __name__ == '__main__':
train_mesh_folders = ['mesh1','mesh2']
n_processes = os.cpu_count()
n_processes =2
print('n_processes: ', n_processes)
pool = Pool(processes=n_processes) # 进程池
# split folders into n_processes parts
split_folders = np.array_split(train_mesh_folders, n_processes)
pool.apply_async(processFolder, args=(0, split_folders[0], output_dir,))
pool.apply_async(processFolder, args=(1, split_folders[1], output_dir,))
pool.close()
pool.join()
运行上面多进程的程序,调用的程序只运行了一小部分就退出了,也没个报错。
让人摸不着头脑。
看起来没有报错,其实有报错!!!
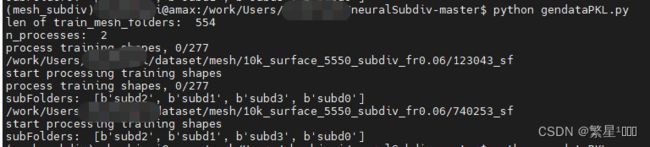
把上面的程序 pool.apply_async中加入error_callback,就发现问题了
from multiprocessing import Pool
def processFolder(idx, folders, o_dir):
train_mesh = TrainMeshes(folders)
output_path = os.path.join(o_dir, str(idx) + '.pkl')
pickle.dump(train_mesh, file=open(output_path, "wb"))
def error_callback(e):
print('error_callback: ', e)
if __name__ == '__main__':
train_mesh_folders = ['mesh1','mesh2']
n_processes = os.cpu_count()
n_processes =2
print('n_processes: ', n_processes)
pool = Pool(processes=n_processes) # 进程池
# split folders into n_processes parts
split_folders = np.array_split(train_mesh_folders, n_processes)
pool.apply_async(processFolder, args=(0, split_folders[0], output_dir,), error_callback=error_callback)
pool.apply_async(processFolder, args=(1, split_folders[1], output_dir,), error_callback=error_callback)
pool.close()
pool.join()
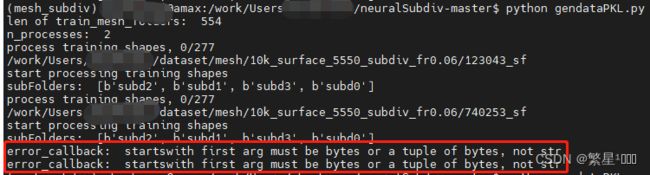
可以看到,有报错!!!!
但也很奇怪,不使用多进程,不会报错。可能我程序写的还是不好。反正改完报错,多进程就能顺利运行了。
参考文献:
Python进程池apply_async的callback函数不执行的解决方案
Python并发编程:为什么传入进程池的目标函数不执行,也没有报错?
坑2:from multiprocessing import Pool进程池中torch有关函数卡住
torch.min(V[:,0])
torch.sparse.FloatTensor(i, v, torch.Size(shape))
实测这两个函数都会卡死
解决:使用线程代替进程 ,改为from multiprocessing.pool import ThreadPool as Pool
def normalizeUnitCube(V):
'''
NORMALIZEUNITCUBE normalize a shape to the bounding box by 0.5,0.5,0.5
Inputs:
V (|V|,3) torch array of vertex positions
Outputs:
V |V|-by-3 torch array of normalized vertex positions
'''
V = V - torch.min(V,0)[0].unsqueeze(0)
# x_min = torch.min(V[:,0])
# y_min = torch.min(V[:,1])
# z_min = torch.min(V[:,2])
# min_bound = torch.tensor([x_min, y_min, z_min]).unsqueeze(0)
# V = V - min_bound
V = V / torch.max(V.view(-1)) / 2.0
return V
上面的函数对点集进行标准化。V是一个二维张量,其实是(Nx3)的顶点列表。
实测用torch.min(V,0)会卡住,用注释的代码才可以。torch.min(V[:,0])才能跑。
def tgp_midPointUp(V, F, subdIter=1):
"""
perform mid point upsampling
"""
Vnp = V.data.numpy()
Fnp = F.data.numpy()
VVnp, FFnp, SSnp = midPointUpsampling(Vnp, Fnp, subdIter)
VV = torch.from_numpy(VVnp).float()
FF = torch.from_numpy(FFnp).long()
SSnp = SSnp.tocoo()
values = SSnp.data
indices = np.vstack((SSnp.row, SSnp.col))
i = torch.LongTensor(indices)
v = torch.FloatTensor(values)
shape = SSnp.shape
SS = torch.sparse.FloatTensor(i, v, torch.Size(shape)) #在这里会卡死
return VV, FF, SS
常用解决办法
- 调用pathos包下的multiprocessing模块代替原生的multiprocessing。pathos中multiprocessing是用dill包改写过的,dill包可以将几乎所有python的类型都serialize,因此都可以被pickle。
- 使用线程代替进程 from multiprocessing.pool import ThreadPool as Pool
- 可以使用 copy_reg 来规避异常
- 把调用的函数写在顶层规避
- 重写类的内部函数规避
参考文献
python多进程踩过的坑