一个SpringBoot 项目能处理多少请求?
这篇文章带大家盘一个读者遇到的面试题哈。
根据读者转述,面试官的原问题就是:一个 SpringBoot 项目能同时处理多少请求?
不知道你听到这个问题之后的第一反应是什么。
我大概知道他要问的是哪个方向,但是对于这种只有一句话的面试题,我的第一反应是:会不会有坑?
所以并不会贸然答题,先追问一些消息,比如:这个项目具体是干什么的?项目大概进行了哪些参数配置?使用的 web 容器是什么?部署的服务器配置如何?有哪些接口?接口响应平均时间大概是多少?
这样,在几个问题的拉扯之后,至少在面试题考察的方向方面能基本和面试官达成了一致。
比如前面的面试问题,经过几次拉扯之后,面试官可能会修改为:
一个 SpringBoot 项目,未进行任何特殊配置,全部采用默认设置,这个项目同一时刻,最多能同时处理多少请求?
能处理多少呢?
我也不知道,但是当问题变成上面这样之后,我找到了探索答案的角度。
既然“未进行任何特殊配置”,那我自己搞个 Demo 出来,压一把不就完事了吗?
坐稳扶好,准备发车。

Demo
小手一抖,先搞个 Demo 出来。
这个 Demo 非常的简单,就是通过 idea 创建一个全新的 SpringBoot 项目就行。
我的 SpringBoot 版本使用的是 2.7.13。
整个项目只有这两个依赖:
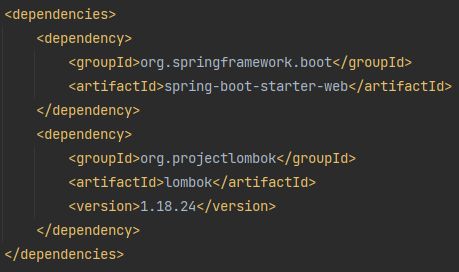
整个项目也只有两个类,要得就是一个空空如也,一清二白。
项目中的 TestController,里面只有一个 getTest 方法,用来测试,方法里面接受到请求之后直接 sleep 一小时。
目的就是直接把当前请求线程占着,这样我们才能知道项目中一共有多少个线程可以使用:
@Slf4j
@RestController
public class TestController {
@GetMapping("/getTest")
public void getTest(int num) throws Exception {
log.info("{} 接受到请求:num={}", Thread.currentThread().getName(), num);
TimeUnit.HOURS.sleep(1);
}
}
项目中的 application.properties 文件也是空的:
这样,一个“未进行任何特殊配置”的 SpringBoot 不就有了吗?
基于这个 Demo,前面的面试题就要变成了:我短时间内不断的调用这个 Demo 的 getTest 方法,最多能调用多少次?
问题是不是又变得更加简单了一点?
那么前面这个“短时间内不断的调用”,用代码怎么表示呢?
很简单,就是在循环中不断的进行接口调用就行了。
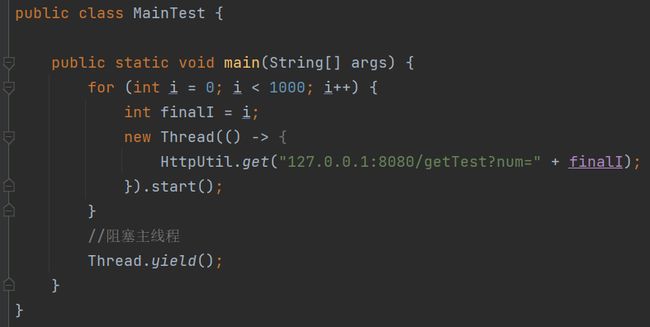
public class MainTest {
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
int finalI = i;
new Thread(() -> {
HttpUtil.get("127.0.0.1:8080/getTest?num=" + finalI);
}).start();
}
//阻塞主线程
Thread.yield();
}
}
当然了,这个地方你用一些压测工具,比如 jmeter 啥的,会显得逼格更高,更专业。我这里就偷个懒,直接上代码了。
答案
经过前面的准备工作,Demo 和测试代码都就绪了。
接下来就是先把 Demo 跑起来:

然后跑一把 MainTest。
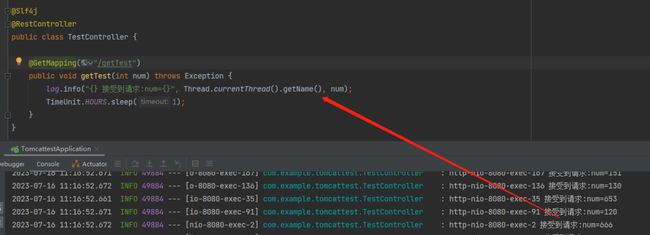
当 MainTest 跑起来之后,Demo 这边就会快速的、大量的输出这样的日志:
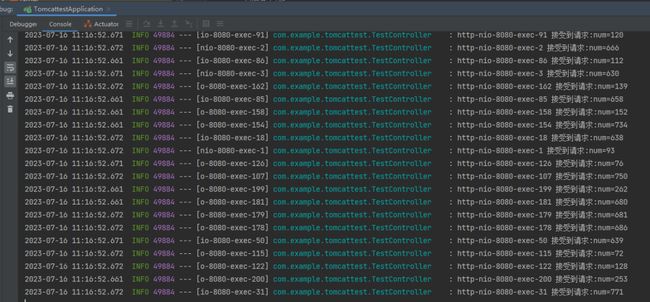
也就是我前面 getTest 方法中写的日志:
好,现在我们回到这个问题:
我短时间内不断的调用这个 Demo 的 getTest 方法,最多能调用多少次?
来,请你告诉我怎么得到这个问题的答案?
我这里就是一个大力出奇迹,直接统计“接受到请求”关键字在日志中出现的次数就行了:
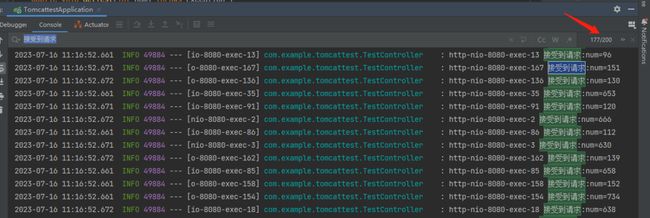
很显然,答案就是:

所以,当面试官问你:一个 SpringBoot 项目能同时处理多少请求?
你装作仔细思考之后,笃定的说:200 次。
面试官微微点头,并等着你继续说下去。
你也暗自欢喜,幸好看了歪歪歪师傅的文章,背了个答案。然后等着面试官继续问其他问题。
气氛突然就尴尬了起来。
接着,你就回家等通知了。

200 次,这个回答是对的,但是你只说 200 次,这个回答就显得有点尬了。
重要的是,这个值是怎么来的?
所以,下面这一部分,你也要背下来。
怎么来的?
在开始探索怎么来的之前,我先问你一个问题,这个 200 个线程,是谁的线程,或者说是谁在管理这个线程?
是 SpringBoot 吗?
肯定不是,SpringBoot 并不是一个 web 容器。
应该是 Tomcat 在管理这 200 个线程。
这一点,我们通过线程 Dump 也能进行验证:
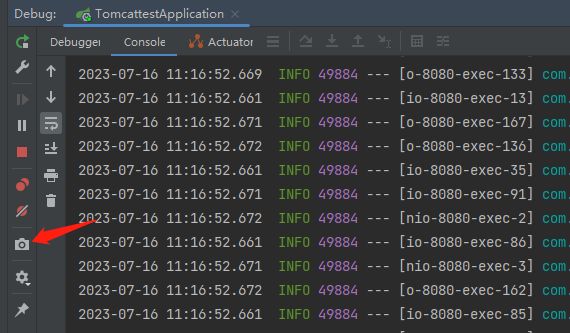
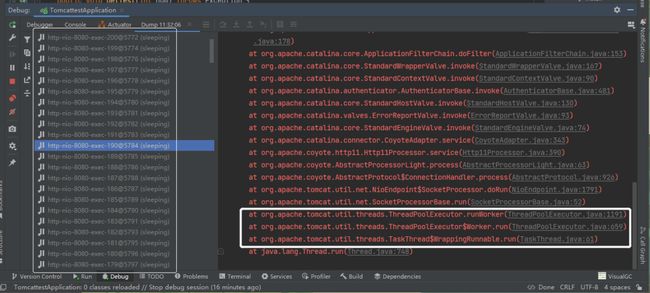
通过线程 Dump 文件,我们可以知道,大量的线程都在 sleep 状态。而点击这些线程,查看其堆栈消息,可以看到 Tomcat、threads、ThreadPoolExecutor 等关键字:
at org.apache.Tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1791)
at org.apache.Tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:52)
at org.apache.Tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191)
at org.apache.Tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659)
at org.apache.Tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
基于“短时间内有 200 个请求被立马处理的”这个现象,结合你背的滚瓜烂熟的、非常扎实的线程池知识,你先大胆的猜一个:Tomcat 默认核心线程数是 200。
接下来,我们就是要去源码里面验证这个猜测是否正确了。
这里我再教你一个不用打断点也能获取到调用栈的方法。
在前面已经展示过了,就是线程 Dump。
右边就是一个线程完整的调用栈:
从这个调用栈中,由于我们要找的是 Tomcat 线程池相关的源码,所以第一次出现相关关键字的地方就是这一行:
org.apache.Tomcat.util.threads.ThreadPoolExecutor.Worker#run
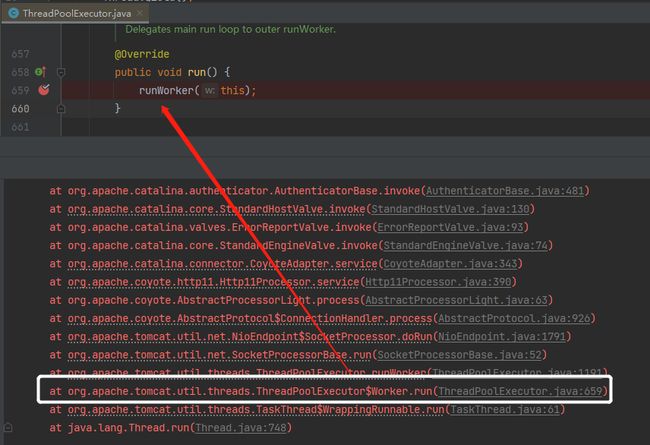
然后我们在这一行打上断点。
重启项目,开始调试。
进入 runWorker 之后,这部分代码看起来就非常眼熟了:
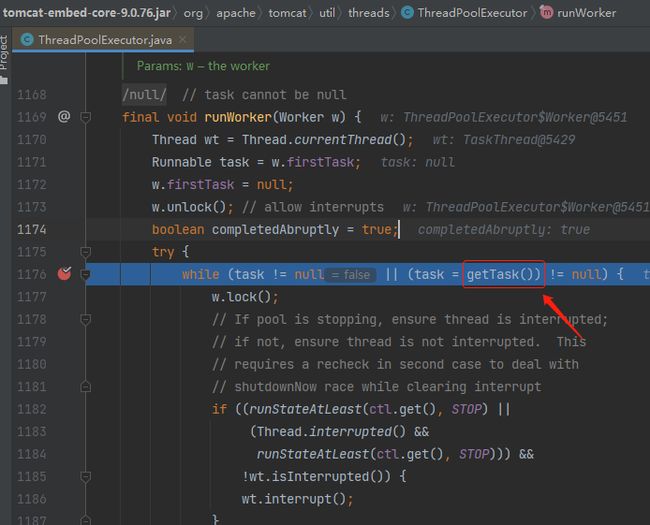
简直和 JDK 里面的线程池源码一模一样。
如果你熟悉 JDK 线程池源码的话,调试 Tomcat 的线程池,那个感觉,就像是回家一样。
如果你不熟悉的话,我建议你尽快去熟悉熟悉。
随着断点往下走,在 getTask 方法里面,可以看到关于线程池的几个关键参数:
org.apache.Tomcat.util.threads.ThreadPoolExecutor#getTask
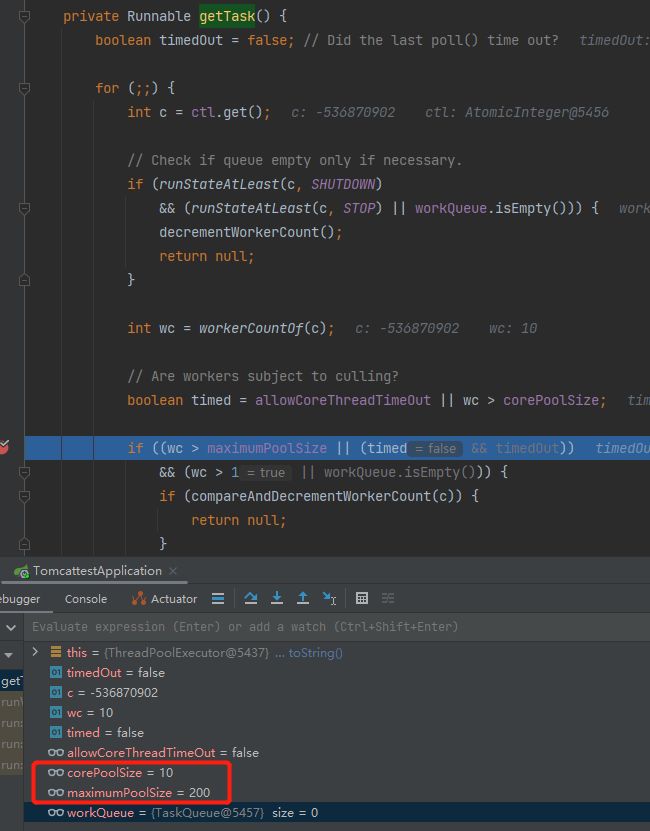
corePoolSize,核心线程数,值为 10。
maximumPoolSize,最大线程数,值为 200。
而且基于 maximumPoolSize 这个参数,你往前翻代码,会发现这个默认值就是 200:
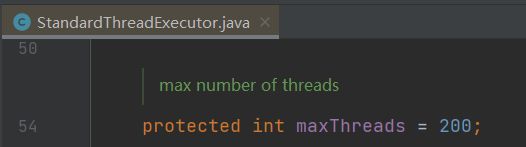
好,到这里,你发现你之前猜测的“Tomcat 默认核心线程数是 200”是不对的。
但是你一点也不慌,再次结合你背的滚瓜烂熟的、非常扎实的线程池知识。
并在心里又默念了一次:当线程池接受到任务之后,先启用核心线程数,再使用队列长度,最后启用最大线程数。
因为我们前面验证了,Tomcat 可以同时间处理 200 个请求,而它的线程池核心线程数只有 10,最大线程数是 200。
这说明,我前面这个测试用例,把队列给塞满了,从而导致 Tomcat 线程池启用了最大线程数:
嗯,一定是这样的!
那么,现在的关键问题就是:Tomcat 线程池默认的队列长度是多少呢?
在当前的这个 Debug 模式下,队列长度可以通过 Alt+F8 进行查看:
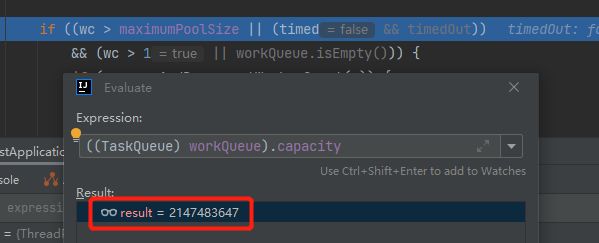
wc,这个值是 Integer.MAX_VALUE,这么大?
我一共也才 1000 个任务,不可能被占满啊?
一个线程池:
-
核心线程数,值为 10。
-
最大线程数,值为 200。
-
队列长度,值为 Integer.MAX_VALUE。
1000 个比较耗时的任务过来之后,应该是只有 10 个线程在工作,然后剩下的 990 个进队列才对啊?
难道我八股文背错了?
这个时候不要慌,嗦根辣条冷静一下。

目前已知的是核心线程数,值为 10。这 10 个线程的工作流程是符合我们认知的。
但是第 11 个任务过来的时候,本应该进入队列去排队。
现在看起来,是直接启用最大线程数了。
所以,我们先把测试用例修改一下:
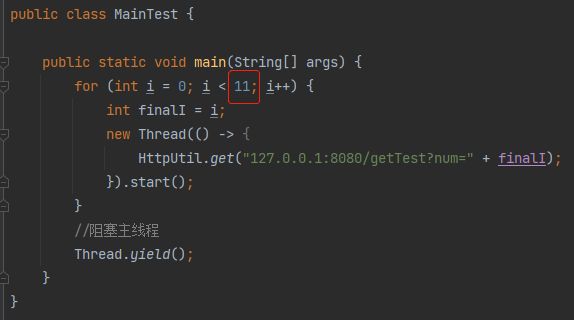
那么问题就来了:最后一个请求到底是怎么提交到线程池里面的?
前面说了,Tomcat 的线程池源码和 JDK 的基本一样。
往线程池里面提交任务的时候,会执行 execute 这个方法:
org.apache.Tomcat.util.threads.ThreadPoolExecutor#execute(java.lang.Runnable)
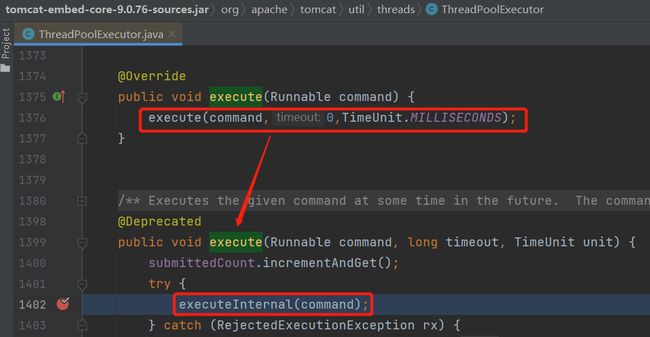
对于 Tomcat 它会调用到 executeInternal 这个方法:
org.apache.Tomcat.util.threads.ThreadPoolExecutor#executeInternal
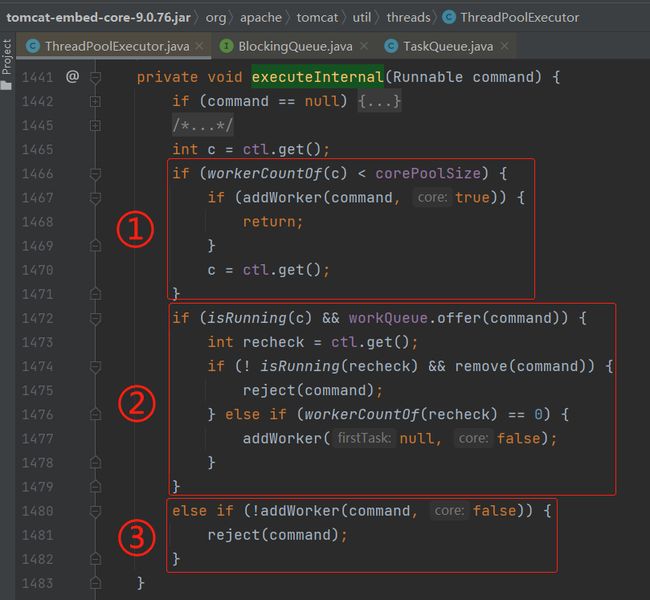
这个方法里面,标号为 ① 的地方,就是判断当前工作线程数是否小于核心线程数,小于则直接调用 addWorker 方法,创建线程。
标号为 ② 的地方主要是调用了 offer 方法,看看队列里面是否还能继续添加任务。
如果不能继续添加,说明队列满了,则来到标号为 ③ 的地方,看看是否能执行 addWorker 方法,创建非核心线程,即启用最大线程数。
把这个逻辑捋顺之后,接下来我们应该去看哪部分的代码,就很清晰了。
主要就是去看 workQueue.offer(command) 这个逻辑。
如果返回 true 则表示加入到队列,返回 false 则表示启用最大线程数嘛。
这个 workQueue 是 TaskQueue,看起来一点也不眼熟:
当然不眼熟了,因为这个是 Tomcat 自己基于 LinkedBlockingQueue 搞的一个队列。
问题的答案就藏在 TaskQueue 的 offer 方法里面。

所以我重点带你盘一下这个 offer 方法:
org.apache.Tomcat.util.threads.TaskQueue#offer
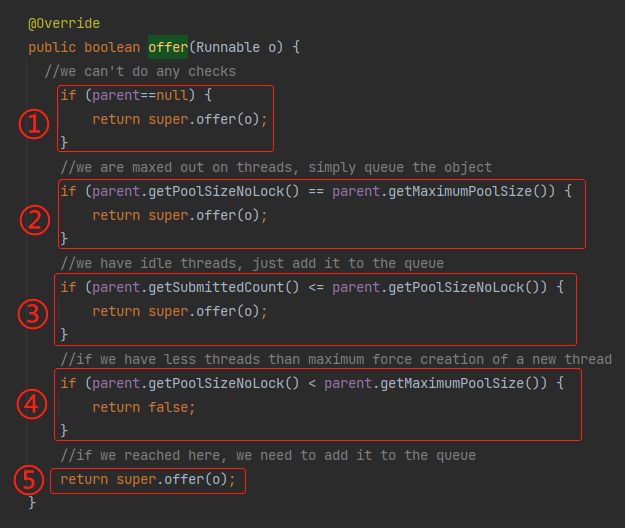
标号为 ① 的地方,判断了 parent 是否为 null,如果是则直接调用父类的 offer 方法。说明要启用这个逻辑,我们的 parent 不能为 null。
那么这个 parent 是什么玩意,从哪里来的呢?
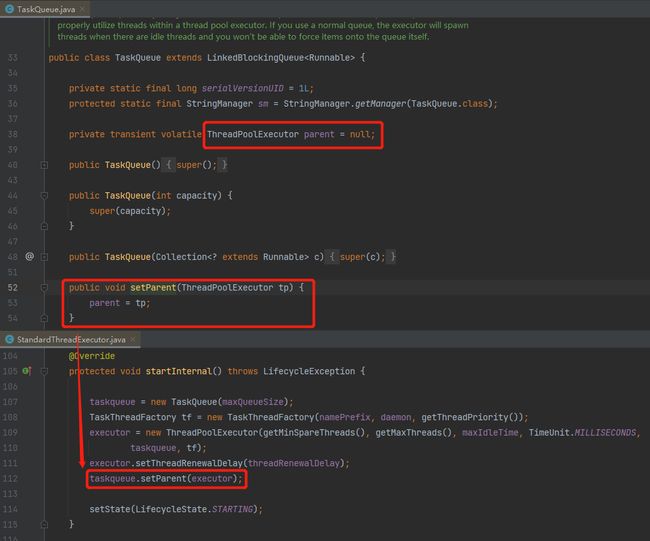
parent 就是 Tomcat 线程池,通过其 set 方法可以知道,是在线程池完成初始化之后,进行了赋值。
也就是说,你可以理解为,在 Tomcat 的场景下,parent 不会为空。
标号为 ② 的地方,调用了 getPoolSizeNoLock 方法:
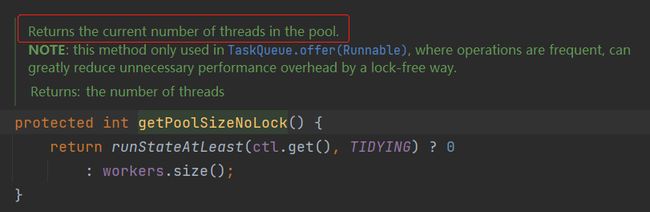
这个方法是获取当前线程池中有多个线程。
所以如果这个表达式为 true:
parent.getPoolSizeNoLock() == parent.getMaximumPoolSize()
就表明当前线程池的线程数已经是配置的最大线程数了,那就调用 offer 方法,把当前请求放到到队列里面去。
标号为 ③ 的地方,是判断已经提交到线程池里面待执行或者正在执行的任务个数,是否比当前线程池的线程数还少。
如果是,则说明当前线程池有空闲线程可以执行任务,则把任务放到队列里面去,就会被空闲线程给取走执行。
然后,关键的来了,标号为 ④ 的地方。
如果当前线程池的线程数比线程池配置的最大线程数还少,则返回 false。
前面说了,offer 方法返回 false,会出现什么情况?
是不是直接开始到上图中标号为 ③ 的地方,去尝试添加非核心线程了?
也就是启用最大线程数这个配置了。
所以,朋友们,这个是什么情况?
这个情况确实就和我们背的线程池的八股文不一样了啊。
JDK 的线程池,是先使用核心线程数配置,接着使用队列长度,最后再使用最大线程配置。
Tomcat 的线程池,就是先使用核心线程数配置,再使用最大线程配置,最后才使用队列长度。
所以,以后当面试官给你说:我们聊聊线程池的工作机制吧?
你就先追问一句:你是说的 JDK 的线程池呢还是 Tomcat 的线程池呢,因为这两个在运行机制上有一点差异。
然后,你就看他的表情。
如果透露出一丝丝迟疑,然后轻描淡写的说一句:那就对比着说一下吧。
那么恭喜你,在这个题目上开始掌握了一点主动权。
最后,为了让你更加深刻的理解到 Tomcat 线程池和 JDK 线程池的不一样,我给你搞一个直接复制过去就能运行的代码。
当你把 taskqueue.setParent(executor) 这行代码注释掉的时候,它的运行机制就是 JDK 的线程池。
当存在这行代码的时候,它的运行机制就变成了 Tomcat 的线程池。
玩去吧。
import org.apache.tomcat.util.threads.TaskQueue;
import org.apache.tomcat.util.threads.TaskThreadFactory;
import org.apache.tomcat.util.threads.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class TomcatThreadPoolExecutorTest {
public static void main(String[] args) throws InterruptedException {
String namePrefix = "歪歪歪-exec-";
boolean daemon = true;
TaskQueue taskqueue = new TaskQueue(300);
TaskThreadFactory tf = new TaskThreadFactory(namePrefix, daemon, Thread.NORM_PRIORITY);
ThreadPoolExecutor executor = new ThreadPoolExecutor(5,
150, 60000, TimeUnit.MILLISECONDS, taskqueue, tf);
taskqueue.setParent(executor);
for (int i = 0; i < 300; i++) {
try {
executor.execute(() -> {
logStatus(executor, "创建任务");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
Thread.currentThread().join();
}
private static void logStatus(ThreadPoolExecutor executor, String name) {
TaskQueue queue = (TaskQueue) executor.getQueue();
System.out.println(Thread.currentThread().getName() + "-" + name + "-:" +
"核心线程数:" + executor.getCorePoolSize() +
"\t活动线程数:" + executor.getActiveCount() +
"\t最大线程数:" + executor.getMaximumPoolSize() +
"\t总任务数:" + executor.getTaskCount() +
"\t当前排队线程数:" + queue.size() +
"\t队列剩余大小:" + queue.remainingCapacity());
}
}
等等
如果你之前确实没了解过 Tomcat 线程池的工作机制,那么看到这里的时候也许你会觉得确实是有一点点收获。
但是,注意我要说但是了。
还记得最开始的时候面试官的问题吗?
面试官的原问题就是:一个 SpringBoot 项目能同时处理多少请求?
那么请问,前面我讲了这么大一坨 Tomcat 线程池运行原理,这个回答,和这个问题匹配吗?
是的,除了最开始提出的 200 这个数值之外,并不匹配,甚至在面试官的眼里完全是答非所问了。
所以,为了把这两个“并不匹配”的东西比较顺畅的链接起来,你必须要先回答面试官的问题,然后再开始扩展。
比如这样答:一个未进行任何特殊配置,全部采用默认设置的 SpringBoot 项目,这个项目同一时刻最多能同时处理多少请求,取决于我们使用的 web 容器,而 SpringBoot 默认使用的是 Tomcat。
Tomcat 的默认核心线程数是 10,最大线程数 200,队列长度是无限长。但是由于其运行机制和 JDK 线程池不一样,在核心线程数满了之后,会直接启用最大线程数。所以,在默认的配置下,同一时刻,可以处理 200 个请求。
在实际使用过程中,应该基于服务实际情况和服务器配置等相关消息,对该参数进行评估设置。
这个回答就算是差不多了。
但是,如果很不幸,如果你遇到了我,为了验证你是真的自己去摸索过,还是仅仅只是看了几篇文章,我可能还会追问一下:
那么其他什么都不动,如果我仅仅加入 server.tomcat.max-connections=10 这个配置呢,那么这个时候最多能处理多少个请求?
你可能就要猜了:10 个。
是的,我重新提交 1000 个任务过来,在控制台输出的确实是 10 个,
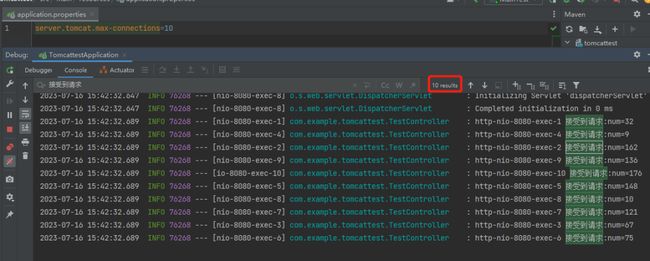
那么 max-connections 这个参数它怎么也能控制请求个数呢?
为什么在前面的分析过程中我们并没有注意到这个参数呢?
首先我们看一下它的默认值:

因为它的默认值是 8192,比最大线程数 200 大,这个参数并没有限制到我们,所以我们没有关注到它。
当我们把它调整为 10 的时候,小于最大线程数 200,它就开始变成限制项了。
那么 max-connections 这个参数到底是干啥的呢?
你先自己去摸索摸索吧。
同时,还有这样的一个参数,默认是 100:
server.tomcat.accept-count=100

它又是干什么的呢?
“和连接数有关”,我只能提示到这里了,自己去摸索吧。

再等等
通过前面的分析,我们知道了,要回答“一个 SpringBoot 项目默认能处理的任务数”,这个问题,得先明确其使用的 web 容器。
那么问题又来了:SpringBoot 内置了哪些容器呢?
Tomcat、Jetty、Netty、Undertow
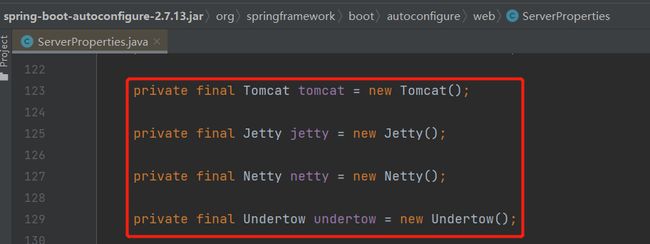
前面我们都是基于 Tomcat 分析的,如果我们换一个容器呢?
比如换成 Undertow,这个玩意我只是听过,没有实际使用过,它对我来说就是一个黑盒。
管它的,先换了再说。
从 Tomcat 换成 Undertow,只需要修改 Maven 依赖即可,其他什么都不需要动:
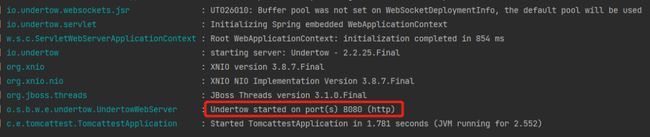
再次启动项目,从日志可以发现已经修改为了 Undertow 容器:
此时我再次执行 MainTest 方法,还是提交 1000 个请求:
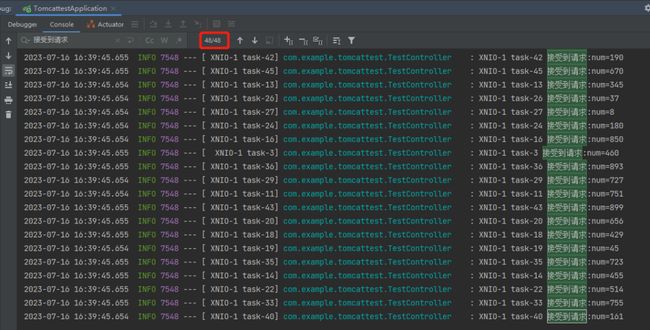
从日志来看,发现只有 48 个请求被处理了。
就很懵逼,48 是怎么回事儿,怎么都不是一个整数呢,这让强迫症很难受啊。
这个时候你的想法是什么,是不是想要看看 48 这个数字到底是从哪里来的?
怎么看?
之前找 Tomcat 的 200 的时候不是才教了你的嘛,直接往 Undertow 上套就行了嘛。
打线程 Dump,然后看堆栈消息:
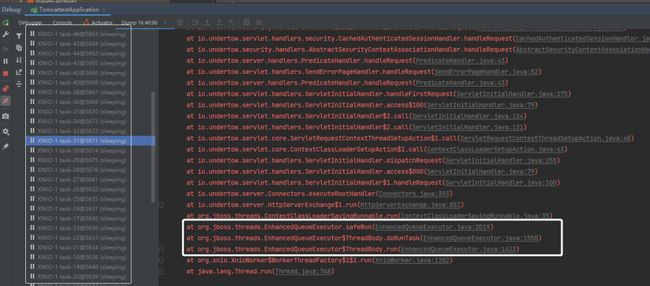
发现 EnhancedQueueExecutor 这个线程池,接着在这个类里面去找构建线程池时的参数。
很容易就找到了这个构造方法:
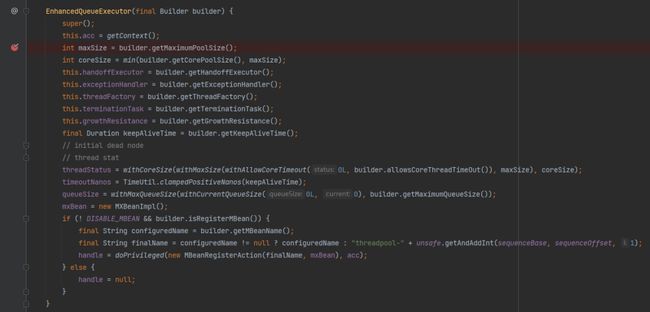
所以,在这里打上断点,重启项目。
通过 Debug 可以知道,关键参数都是从 builder 里面来的。
而 builder 里面,coreSize 和 maxSize 都是 48,队列长度是 Integer.MAX_VALUE。
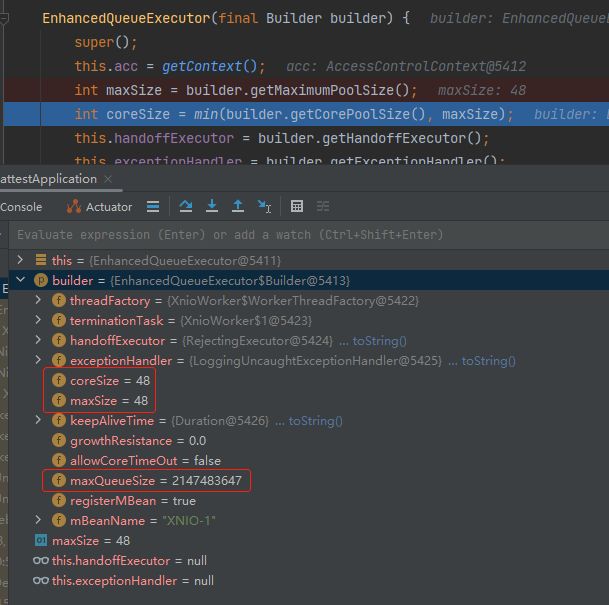
所以看一下 Builder 里面的 coreSize 是怎么来的。
点过来发现 coreSize 的默认值是 16:
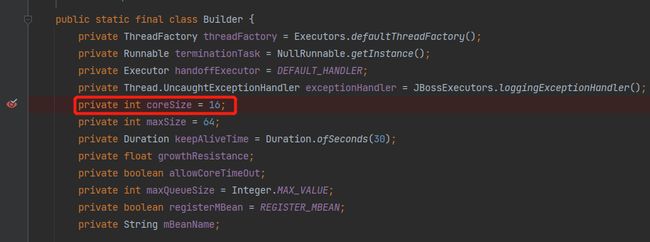
不要慌,再打断点,再重启项目。
然后你会在它的 setCorePoolSize 方法处停下来,而这个方法的入参就是我们要找的 48:
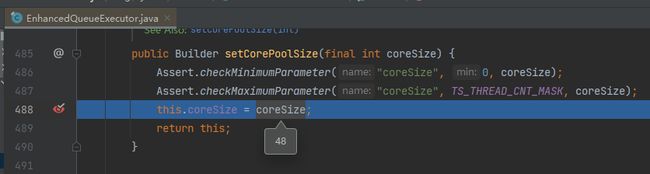
顺藤摸瓜,重复几次打断点、重启的动作之后,你会找到 48 是一个名为 WORKER_TASK_CORE_THREADS 的变量,是从这里来的:
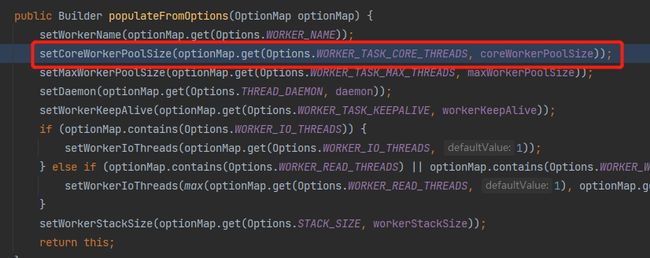
而 WORKER_TASK_CORE_THREADS 这个变量设置的地方是这样的:
io.undertow.Undertow#start
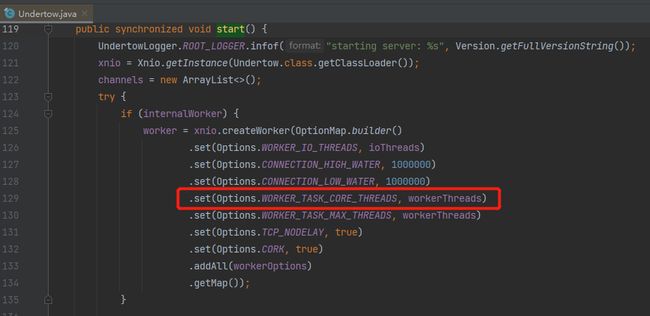
而这里的 workerThreads 取值是这样的:
io.undertow.Undertow.Builder#Builder
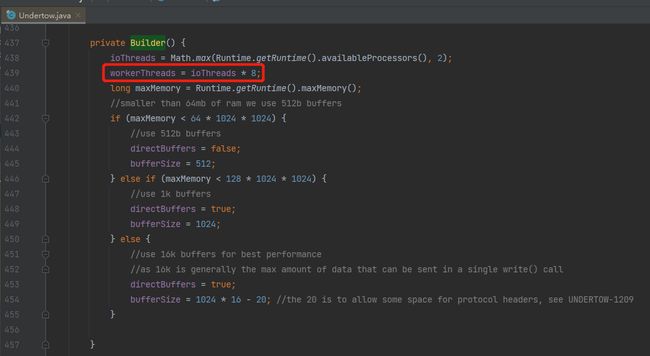
取的是机器的 CPU 个数乘以 8。
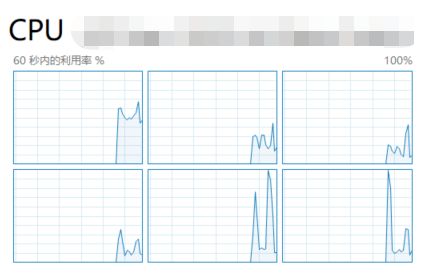
所以我这里是 6*8=48。
哦,真相大白,原来 48 是这样来的。
没意思。
确实没意思,但是既然都已经替换为 Undertow 了,那么你去研究一下它的 NIO ByteBuffer、NIO Channel、BufferPool、XNIO Worker、IO 线程池、Worker 线程池...
然后再和 Tomcat 对比着学,
就开始有点意思了。

最后再等等
这篇文章是基于“一个 SpringBoot 项目能同时处理多少请求?”这个面试题出发的。
但是经过我们前面简单的分析,你也知道,这个问题如果在没有加一些特定的前提条件的情况下,答案是各不一样的。
比如我再给你举一个例子,还是我们的 Demo,只是使用一下 @Async 注解,其他什么都不变:
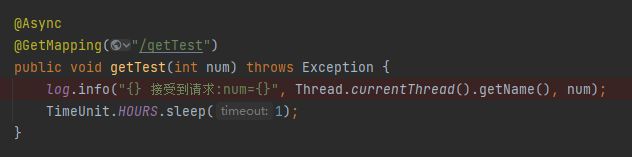
再次启动项目,发起访问,日志输出变成了这样:
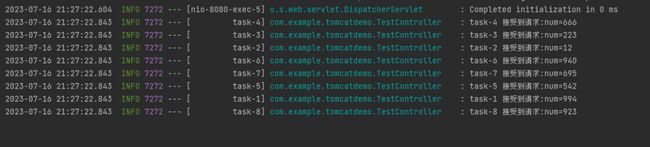
同时能处理的请求,直接从 Tomcat 的默认 200 个变成了 8 个?
因为 @Async 注解对应的线程池,默认的核心线程数是 8。
所以你看,稍微一变化,答案看起来又不一样了,同时这个请求在内部流转的过程也不一样了,又是一个可以铺开谈的点。
在面试过程中也是这样的,不要急于答题,当你觉得面试官问题描述的不清楚的地方,你可以先试探性的问一下,看看能不能挖掘出一点他没有说出来的默认条件。
当“默认条件”挖掘的越多,你的回答就会更容易被面试官接受。而这个挖掘的过程,也是面试过程中一个重要的表现环节。
而且,有时候,面试官就喜欢给出这样的“模糊”的问题,因为问题越模糊,坑就越多,当面试者跳进自己挖好的坑里面的时候,就是结束一次交锋的时候;当面试者看出来自己挖好的坑,并绕过去的时候,也是结束一轮交锋的时候。
所以,不要急于答题,多想,多问。不管是对于面试者还是面试官,一个好的面试体验,一定不是没有互动的一问一答,而是一个相互拉锯的过程。