Ubuntu下的Hadoop安装
二、Hadoop安装
采用版本为hadoop-2.7.7
①JDK的安装
2.1.1 创建文件夹
sudo mkdir /expt
sudo chmod 777 /expt这个出错我参考别的原因也改过来了,
pkexec chmod 0440 /etc/sudoers

2.1.2 移动文件
之前已经解压过了,所以改一下位置就行了
2.1.3 创建软链接
ln -s /expt/jdk1.8.0_141 jdk
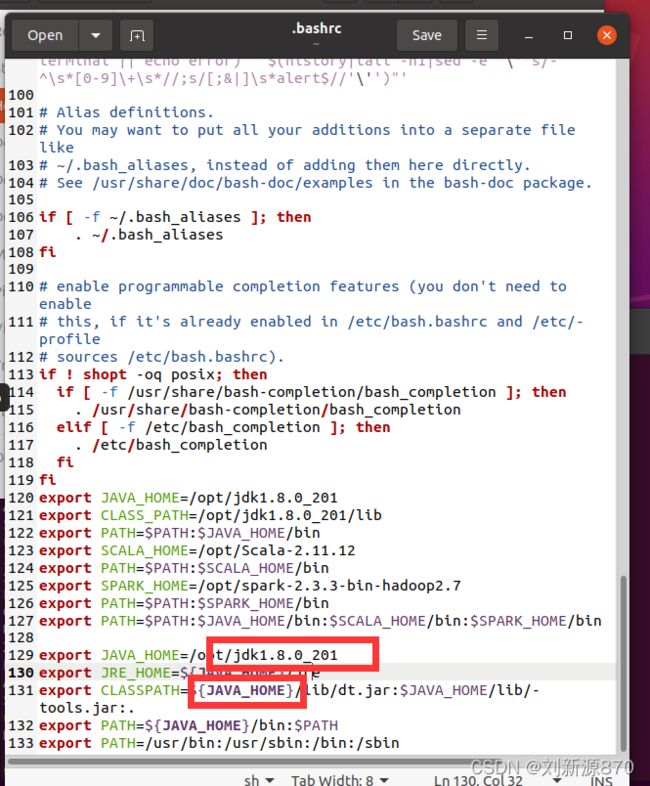
2.1.4配置JDK环境变量
vi ~/.bashrc(我还是不喜欢vi命令,直接进去/目录,然后点击.bashrc)
export JAVA_HOME=~/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=${JAVA_HOME}/bin:$PATH
注意版本一定要填对,括号相当于延续路径
重启配置文件
source ~/.bashrc ![]()
检验是否安装成功
java –version这就是成功了

②ssh免密登录设置
2.2.1 在4612190403主机生成密钥对
ssh-keygen -t rsa连敲三个ender,这个我已经配置过了,

查看ssh
ls ~/.ssh
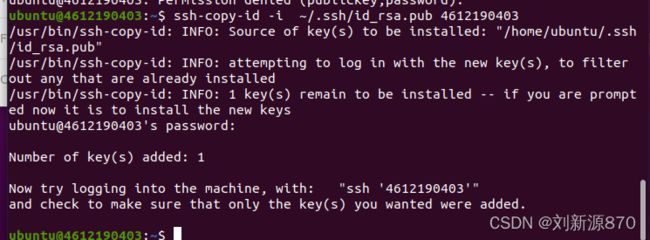
2.2.2 将主机公钥id_rsa.pub复制到4612190403主机上
ssh-copy-id -i ~/.ssh/id_rsa.pub 4612190403
2.2.3 验证免密登录
ssh 4612190403
2.2.4在输入ps -e|grep ssh 检验是否启动
ps -e|grep ssh 
修改/etc/ssh/sshd_config下的端口号(Port)后,重启SSH服务即可生效

重启ssh
sudo /etc/init.d/ssh restart③ hadoop解压与系统变量配置
2.3.1 设置Hadoop配置文件
#创建文件夹
mkdir /expt/server
mkdir /expt/data
mkdir /expt/data/hddata下载hadoop-2.7.7.tar.gz
Apache Hadoop
把hadoop解压移动到 /expt/server里面
tar zxvf hadoop-2.7.7.tar.gz -C /expt/server
2.3.2 创建软链接
ln -s /expt/server/hadoop-2.7.7 hadoop 
2.3.3 配置环境变量还是去~/.bashrc,同样的source
export HADOOP_HOME=~/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc2.3.4 设置Hadoop配置文件
cd /home/ubuntu/Desktop/hadoop2.3.5 配置hadoop-env.sh
这个一定要改成自己连接的jdk
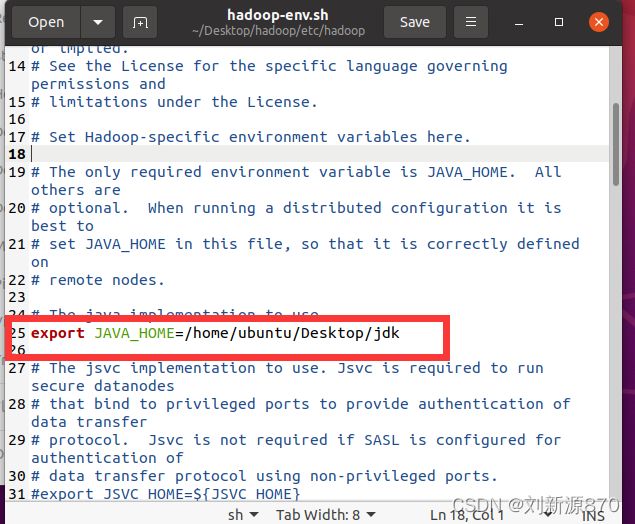
2.3.6 配置core-site.xml
注意
fs.defaultFS
hdfs://4612190403:9000
hadoop.tmp.dir
/expt/data/hddata

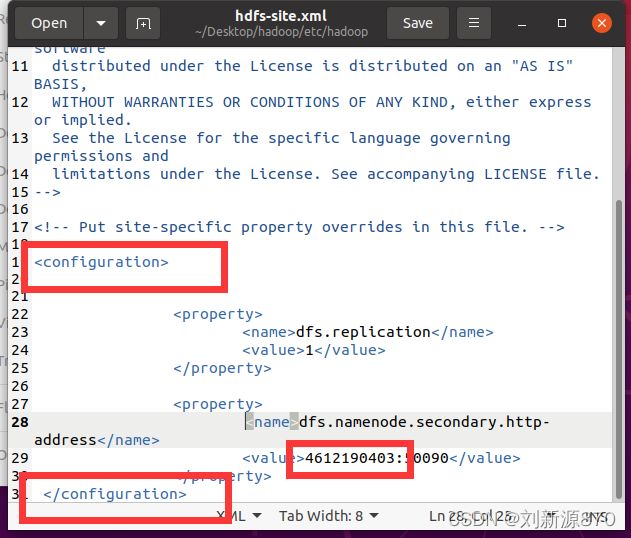
2.3.7 配置hdfs-site.xml
注意修改自己的用户名和对应configuration
dfs.replication
1
dfs.namenode.secondary.http-address
4612190403:50090
2.3.8 配置mapred-site.xml
先把这个文件复制一下,在配置新文件
cp mapred-site.xml.template mapred-site.xml![]()
mapreduce.framework.name
yarn

2.3.9 配置yarn-site.xml
yarn.resourcemanager.hostname
4612190403
yarn.nodemanager.aux-services
mapreduce_shuffle

2.3.10 hadoop格式化(只能做一次格式化)
hdfs namenode -format
2.3.11 启动HDFS和YARN, 启动Hadoop,验证Hadoop进程
start-all.sh 
jps 
2.3.12测试Hadoop
(1) 创建一个文本文件data.txt
cd ~
vi data.txt
Hello World
Hello Hadoop ![]()

(2)在HDFS创建input文件夹
hdfs dfs -mkdir /input ![]()
(3) 将data.txt上传到HDFS,并查看结果
hdfs dfs -put data.txt /input
hdfs dfs -ls /input #查看结果

(4)运行MapReduce WordCount例子
cd /home/ubuntu/Desktop/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /input/data.txt /output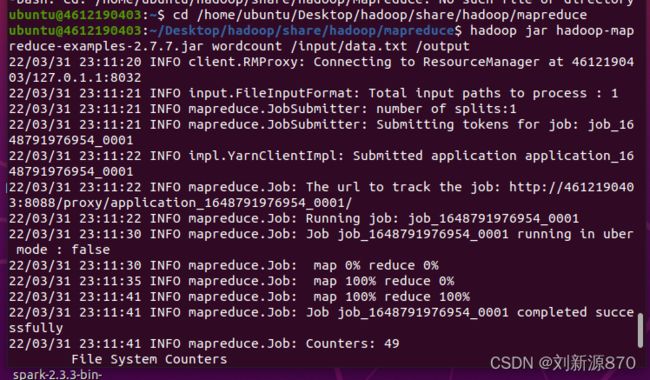
(5)查看结果,显示正确。
hdfs dfs -cat /output/part-r-00000
这样就彻底完成了,错误一般都是环境配置问题