Parquet 文件结构与优势
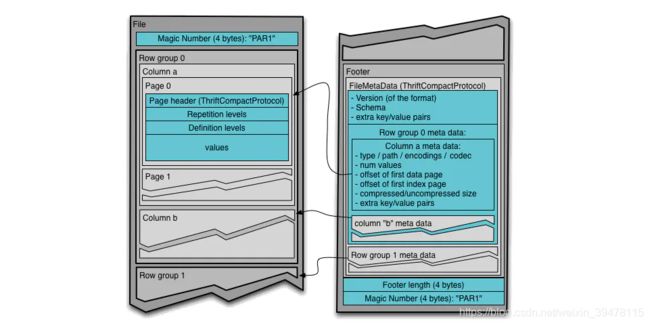
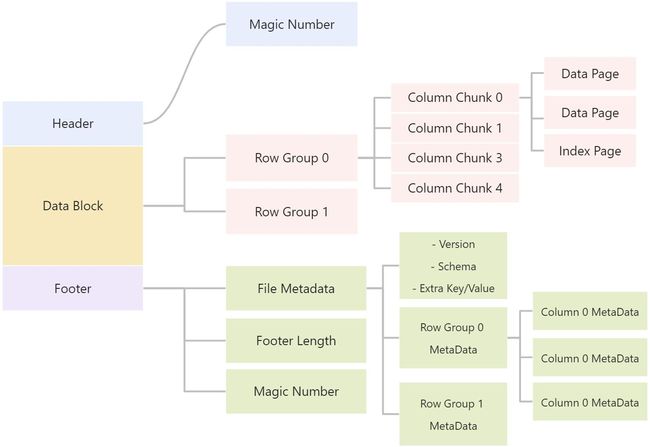
一个 Parquet 文件的内容有 Header、Data Block 和 Footer 三个部分组成。
Header
每个 Parquet 的首尾各有一个大小为 4 bytes ,内容为 PAR1 的 Magic Number,用来标识这个文件是 Parquet 文件。
Data Block
中间的 Data Block 是具体存放数据的区域,由多个行组(Row Group)组成。
行组 (Row Group),是按照行将数据在物理上分成多个单元,每一个行组包含一定的行数。
比如一个文件有10000条数据,被划分成两个 Row Group,那么每个 Row Group 有 5000 行数据。
在每个行组(Row Group)中,数据按列连续的存储在这个行组文件中,每列的所有数据组合成一个 Column Chunk(列块),一个列块拥有相同的数据类型,不同的列块可以有不同的压缩格式。
在每个列块(Column Chunk)中,数据按 Page 为最小单元来存储,Page 按内容分为 Data page 和 Index Page。
这样逐层设计的目的在于:
- 多个 Row Group 可以实现数据的并行;
- 不同的 Column Chunk 用来实现列存储;
- 进一步分割成 Page,可以实现更细粒度的访问;
Footer
Footer部分由 File Metadata、**Footer Length **和 **Magic Number **三部分组成。
Footer Length 是一个 4 字节的数据,用于标识 Footer 部分的大小,帮助找到 Footer 的起始指针位置。
Magic Number同样是PAR1。
File Metada包含了非常重要的信息,包括Schema和每个 Row Group 的 Metadata。
每个 Row Group 的 Metadata 又由各个 Column 的 Metadata 组成,每个 Column Metadata 包含了其Encoding、Offset、Statistic 信息等等。
Parquet 格式的优势:
(1) 列裁剪(offset of first data page -> 列的起始结束位置)
列裁剪的基本思想是,对于没用到的列,则没有必要读取它们的数据去浪费无谓的IO。
Parquet 列式存储方式可以方便地在读取数据到内存之间找到真正需要的列,具体是:
并行的 task 对应一个Parquet的行组(row group),每一个task内部有多个列块,列快连续存储,同一列的数据存储在一起,任务中先去访问 footer 的 File metadata,其中包括每个行组的 metadata,里面的 Column Metadata 记录 offset of first data page 和 offset of first index page,这个记录了每个不同列的起始位置,这样就找到了需要的列的开始和结束位置。
其中 data 和 index 是对数值和字符串数据的处理方式,对于字符变量会存储为key/value对的字典转化为数值
(2)谓词下推(Column Statistic -> 列的range和枚举值信息)
谓词下推的基本思想:
尽可能用过滤表达式提前过滤数据,以使真正执行时能直接跳过无关的数据。
比如这个 SQL:
select item.name, order.* from order , item where order.item_id = item.id and item.category = 'book';
使用谓词下推,会将表达式 item.category = ‘book’ 下推到 join 条件 order.item_id = item.id 之前。
再往高大上的方面说,就是将过滤表达式下推到存储层直接过滤数据,减少传输到计算层的数据量。
比如在 Hive 的 join 过程,Hadoop 的 MapReduce 过程。
Parquet 中 File metadata 记录了每一个 Row group 的 Column statistic,包括数值列的 max/min,字符串列的枚举值信息,比如如果 SQL 语句中对一个数字列过滤 >21 以上的,因此 File 0 的行组 1 和 File 1 的行组 0 不需要读取
File 0
Row Group 0, Column Statistics -> (Min -> 20, Max -> 30)
Row Group 1, Column Statistics -> (Min -> 10, Max -> 20)
File 1
Row Group 0, Column Statistics -> (Min -> 6, Max -> 21)
Row Group 1, Column Statistics -> (Min -> 25, Max -> 45)
对于字符枚举列,先对枚举值做数值映射,如果 SQL 语句中要查找列中是‘leo’的数据,只需要访问 File 1 的行组 1
File 0
Row Group 0, Column 0 -> 0: bruce, 1:cake
Row Group 1, Column 0 -> 0: bruce, 2:kevin
File 1
Row Group 0, Column 0 -> 0: bruce, 1:cake, 2: kevin
Row Group 1, Column 0 -> 0: bruce, 1:cake, 3: leo
(3)压缩效率高,占用空间少,存储成本低
Parquet 这类列式存储有着更高的压缩比,相同类型的数据为一列存储在一起方便压缩,不同列可以采用不同的压缩方式,结合Parquet 的嵌套数据类型,可以通过高效的编码和压缩方式降低存储空间提高 IO 效率