7月19日上课内容 第四章 shell编辑正则表达式与文本处理器
文本三剑客 grep 查找 sed awk
正则表达式:由一类特殊字符以及文本字符所编写的一种模式,处理文本当中的内容
其中的一些字符不表示字符的字面含义,表示控制或者通配的功能
通配符:匹配文件名和目录名,不能匹配文件的内容
正则表达式:命令结果,文本内容都可以进行匹配
通配符:* 匹配任意一个或者多个字符
? 匹配任意一个字符
[ ] 匹配范围内的任意单个字符[0-9][a-z][A-Z]
正则表达式:
1、基本正则表达式
2、扩展正则表达式
区别仅限于写法上的区别,其他的没有任何不同。
基本正则表达式:
字符匹配,元字符
. 匹配任意单个字符,可以是一个汉字
( ) 表示分组的意思 \(\)就是它原本的意思
需要加转义符\
[ ] 匹配指定范围内的任意单个字符 (相当于通配符) [0-9] [a-z]
[^] 取反,指定范围之外的 以上需要掌握
[[:space:]]包含空格,tab键也算,皇帝空格,回车的空格都算
[[:black:]]空白字符 (只包含空格和tab键(制表符))了解会用即可
例:ls /etc/grep/ | grep "rc[.0-6]" #以rc开头,任意单个字符,0-6的数字

只匹配以rc.为开头的文件,.不是正则

ls /opt/ | grep "t." t后面的任意单个字符
ls /opt/ | grep "t\." 匹配t.

例:过滤/etc/passwd中任意两个字符r t

echo abc | grep a.c
echo abc | grep a\.c
echo abc | grep "a\.c"
用正则表达式一定要用引号引起来,否则会出现歧义

通配符不能完全匹配大小写,真正的大小写,在正则表达式当中。

ls | grep [^a.z].txt 表示匹配不是a或者z的任何字符(了解即可)

正则表达式中表示次数的表达式:
* 匹配前面的字符任意次,0次也行,无数次也行,你有多少我匹配多少,没有也行,贪婪模式。
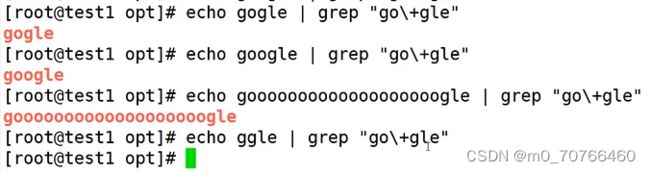
例:匹配go gle中o的次数,0次,无数次都可以

.* 匹配任意长度的字符,至少要有1次,不包括0次。

\? 匹配前面的字符0次或者1次,可有可无。

\+ 匹配前面的字符至少一次,最多可以无数次
\{n\} 匹配前面的字符等于n次,正好等于n才可以匹配(前面的字符必须要连续出现才能匹配)
精确匹配

\{m,n} 匹配前面的字符,最少m次,最多n次

\{,n\} 匹配前面的字符,最多n次 (相当于0到n)

\{n,\} 匹配前面的字符最少n次 (相当于n到无穷)

题:匹配出ip地址,子网掩码,网关地址,用正则表达式来写
192.168.233.10
10.0.0.1
1.1.1.1
IP地址:xxx.xxx.xxx.xxx
0
1-3个数
全部都是数字,没有字母
ip地址 [0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}
0-9范围内的数,最少出现一次,最多出现3次,连续出现四,\.转义成ip地址的.
扩展题:999.999.999,999 把合法的ip地址过滤出来,非法的不显示
位置锚定:以什么为开头,以什么为结尾
^ :以什么为开头,在模式的左侧 (^r)
$:以什么为结尾,在模式的右侧 (r$)

^root$:用于匹配整行,而且整行当中只能有一个root(不能存在第二个root和其他字符)


^$:空行 匹配空行(只能是空行,空格都不行)以上四个要求掌握

^[[:space:]]$:空行(了解即可)
词首锚定和词尾锚定:
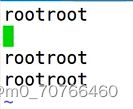
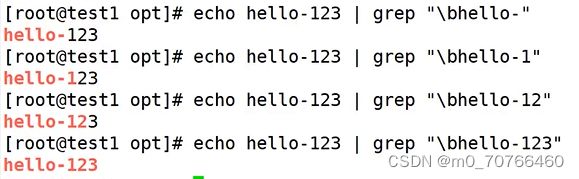
词首锚定:\<或者\b
词尾锚定:\>或者\b
如何确定:看\b的位置
\b的位置就看前面的单词的位置

\
分组:
() 来进行表示
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
ifconfig ens33|grep netmask|grep -E '[0-9]+\.[0-9]+\.[0-9]+\.[0-9]'
\(n\) 表示正好n次,n次表示前面的字符必须要连续出现才能匹配
\{,n\} 只要你出现几次(不连续),都算,除非没有

\|表示逻辑或(\ 管道符)
echo google | grep "\(go\)\{,|\}"
"\(1\|2\)abc"(表示要么是1abc开头要么是2abc开头)
例:echo abcabcabc | grep "\(abc\){3\}"
表示匹配abc3次,abc只能匹配三次,abc一定要连续出现,不连续不行
echo abc123abc123abc123 要匹配到abc一定要用 grep "\(abc\)\{,3\}"
表示最少出现3次abc,无需连续出现

![]()
扩展正则:
没有\,其他一样
* 0次或者无限次
.* 1次或者无限次
? 1次或者0次,可有可无
+
{n}
{n,m}
{,n}
{n,}
grep -E egrep 使用扩展正则
例:
echo 1abc2abc | grep -E "(1|2)abc"
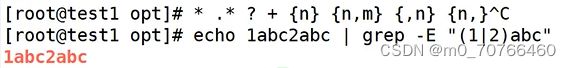
因此推荐使用扩展正则
题1:使用扩展正则匹配
[email protected]
[email protected]
[email protected]
cat test.txt | grep -E "[0-9a-z]{9,11}@[0-9a-z]{2,3}\,[a-z]{2,3}"
分组匹配[0-9a-z]匹配9-11位 2-3位 只能是a-z 2-3位

题2:匹配
cat file.txt
987-123-4567
987 456-1230
(123) 456-7890cat file.txt
987-123-4567
987 456-1230
(123) 456-7890
grep -E '^(\([0-9]+\)|[0-9]+)[ -]?[0-9]+[ -]?[0-9]+' file.txt
作业:
1、显示/etc/passwd中以sh结尾的行;

2、查找/etc/inittab中含有“以s开头,并以d结尾的单词”模式的行

3、查找ifconfig命令结果中1-255之间的整数
先锚定开头,然后依次取个位,再取十位,再取百位,最后比较

4、显示/var/log/secure文件中包含“Failed”或“FAILED”的行;

5、在/etc/passwd中取出默认shell为bash的行;(结尾为bash)
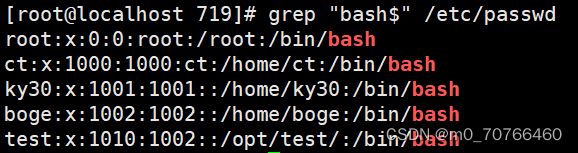
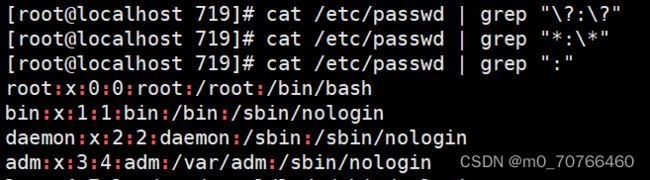
7、高亮显示passwd文件中冒号,及其两侧的字符
匹配;两边的单个字符
egrep ".?:*:.?" /etc/passwd
改为:

---------------------------------------------------------------------------------------------------------------------------------
sed文本处理工具(重点,面试常问,工作中常用)

sed:类似于vim 就是一个文本编辑器,按行来进行编辑和处理
grep sed awk 文本三剑客,都是针对文件内容的行来进行处理的。
sed的主要作用就是对文本内容进行增删改查
sed可以支持正则表达式,也可以支持扩展正则表达式。
sed的工作原理(了解即可):读取,执行,显示三个过程
读取:读取文本没人之后,读取到的内容放到临时的缓冲区,模式空间
执行:在模式空间,根据读取的文本内容,按行执行,除非指定行号,否则会遍历所有行。依次执行,从上往下执行。
显示:执行完之后,把执行结果打印,如果要改变生效,模式空间被修改的内容会写入到指定的文件当中。只是操作,但是不最终写入文件,只展示结果,展示完之后,模式空间的数据会立即删除。
sed:文本内容处理工具
文件过大怎么办 500G
解决方法(也是面试题)
1、 split -l 按行来切 split -b 按大小来切
2、cat 文件名 | sed 处理 适用于中型文件,大型文件,还是先分割的好。
sed的实际操作
sed -e '操作' 文件1 -e '操作' 文件2
只对一个文件操作,可以不加-e
常用选项:
-e 条件操作选项
-f 指定脚本文件来处理输入的内容。把命令写在脚本里。用脚本里的命令来处理第二个文件里面的内容。
-i 立即生效 慎用 先确定完之后再执行
-n 显示script处理之后的结果
操作符:
-s:替换 替换指定字符
d:删除,删除指定的行
a:增加,在当前行的下面插入指定内容
i:增加,在当前行的上面插入指定内容
c:替换,替换整行(常用)
y:替换字符,但是替换前后的字符长度必须一致。123 456√ 123 45×
p:打印
r:扩展正则
sed的核心就是改,删,增,查没有grep强大。
查:sed ' ' /etc/passwd
cat /etc/passwd | sed ' '
也支持重定向输入 sed '' < /etc/passwd
注意:操作符只能用单引号引起来' ' 双引号不行
sed 自己有一个默认输出,p打印会额外再来一行
-n 禁止sed的默认输出->只打印一行

sed -n '=' ky30.txt 只显示行号

sed -n "=;p" ky30.txt
既显示行号,又显示内容

sed 打印指定行,寻址打印
sed -n '$p' ky30.txt 指定打印最后一行
1p 打印第一行 2p打印第二行

行号的范围区间打印:
打印1-3行:
sed -n '1,3p' ky30.txt

打印2-最后一行
sed -n '2,$p' ky30.txt

打印第2行和最后一行
sed -n '2p' ky30.txt

总结:
行号范围打印:,表示到:表示和
奇数行和偶数行打印(了解即可)
sed -n 'n;p' ky30.txt
n的作用就是跳过第一行,打印第二行,再跳过一行,打印下一行,打印偶数行
sed -n 'p;n' ky30.txt 跳过第二行,就是打印奇数行

文本过滤模式:
第一:对包含指定字符串的内容进行打印
sed -n '/o/p' ky30.txt 两个斜杠中间的就是要过滤的内容

所有包含big的行,会全部打印

应用基础正则表达式进行打印
以root为开头
sed -n '/^root/p' /etc/passwd
以bash为结尾
sed -n '/bash$/p' /etc/passwd

使用扩展正则表达式:
-r 表示使用扩展正则 -n表示禁用默认输出
sed -r -n '/(99:){2}/p' /etc/passwd
![]()
在/etc/passwd 当中,过滤出要么是root开头,要么是bash结尾所在的行
sed -r -n '/^root|bash$/p' /etc/passwd

至此,查介绍完毕,接下来我们来看删
sed 'd' ky30.txt
表示删除的意思
![]()
面试题:
怎么样不进入文件就可以删除文件当中的内容,免交换删除。
1、sed -i 'd' ky31.txt (-i表示立即生效)

2、cat /dev/null > ky32.txt

补充:指定行号来进行删除
sed -n '3d;p' ky30.txt (删除第3行,打印剩余的所有内容)

sed -n '1,3d;p' ky30.txt 删除1-3行
sed -n '1d;3d;p' ky30.txt 删除1和3行
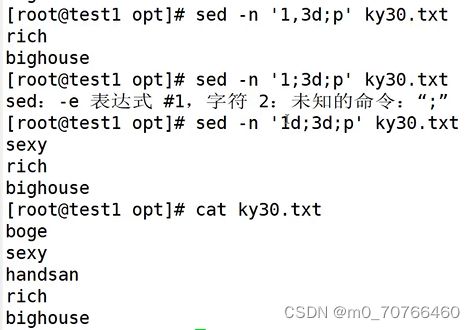
,到 ;和
sed -i -n 直接生效 操作的时候要慎用
匹配字符串的内容删除
sed '/o/d' ky30.txt
sed '/big/d' ky30.txt 指定删除包含big的那一行
sed '/one/,/six/!d' ky30.txt !表示取反的意思
/one/,/six/表示删除不是one到six的行


用正则表达式来删除空行
sed '/^$/d' ky30.txt

sed替换(重点)
s:替换字符串
c:整行替换
y:单字符替换,前后长度要保持一致
s:替换字符串
sed -n 's/root/test/gp' /etc/passwd
把所有的root替换成test
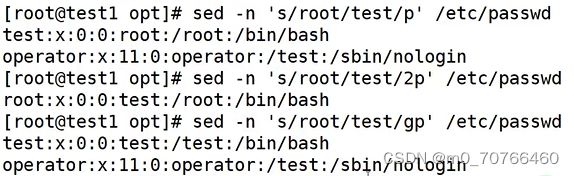
题:以root为开头,把他开头替换成#,就是把root为开头的行,注释掉
sed -n 's/^root/#root/p' /etc/passwd
或者sed -n '/^root/ s/^/#/p' /etc/passwd

字母字符的大小写替换
首字母变成大写 sed 's/[a-z]/\u&/' ky30.txt
所有的字母都变大写 sed 's/[a-z]/\u&/g' ky30.txt

sed -i 's/[a-z]/\l&/g' 全部替换成小写

l&:转换成小写的特殊符号,在使用时,需要转义符
u&:转换成大写的特殊符号,在使用时,需要转义符
g:全部替换,如果不加,只会更改手写字符
整行替换 c(最常用的功能)
sed '/exy/c boge is sexy ' ky30.txt

注:整行替换最好用完整格式,把那一行写出来,否则任意出现歧义

试出来之后,确定可行之后再用-i写进去
y 单字符替换
特点:前后替换的长度必须要一致
不一致就会报错
![]()
而且是全量替换,有多少替换多少
sed 'y/an/12/' ky30.txt
sed 'y/a/1/' ky30.txt

这个用的比较少c s 比较常用
增加
a 在下一行添加
i 在上一行添加

r 在行后读入指定文件的内容
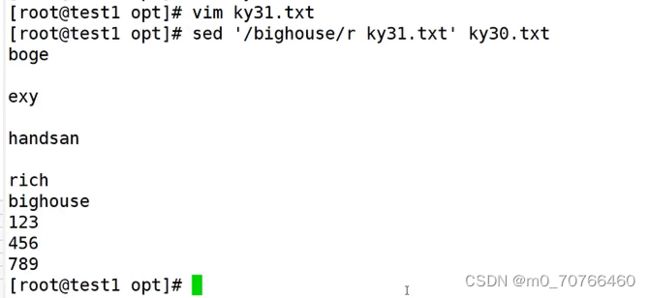
sed '/bighouse/r ky31.txt' ky30.txt
就是在ky30文件的bighouse之后读入ky31的文件的内容
注意:第一个文件是要读取内容的文件,第二个文件才是要指定操作的文件
sed命令当中字符串的位置进行交换
echo ky30boge | sed -r 's/(ky30)(boge)/\2\1/'
使用扩展正则 和字符串替换,再通过分组替换位置的方式,把boge放到ky30的前面
这样就把ky30和boge的顺序交换了
bogeky30 (也是面试题,要会)

题1:ky30ergedage排序
echo ky30ergedage | sed -r 's/(ky30)(erge)(dage)/\3\2\1/'
dageergeky30
![]()
题2:echo 波哥真的帅 倒序排序
echo 波哥真的帅 | sed -r 's/(.)(.)(.)(.)(.)/\5\4\3\2\1/'
.既可以代表任意字符,也可以代表任意汉字
![]()
-f 指定脚本文件
前一个文件的命令对另外一个文件进行操作
例1:
vim 123.txt
把ipaddr=192.168.233.10 整行替换为 10.10.10.10
![]()
vim 456.txt
ipaddr=192.168.233.10
![]()
sed -i -f 123.txt 456.txt
要处理的文件在前面,被处理的文件后面

例2:
vim ky30.txt

用另外一个文件对他进行操作,把空格替换成下划线
解法:
vim一个sed 文件
在里面输入 s/ /_/g(全部替换成下划线)
![]()
sed -f sed.txt ky30.txt

这种方式用的比较少,比较繁琐,会用即可,要知道原理,面试可能会问
面试题(笔试题,很难)
vim num.txt
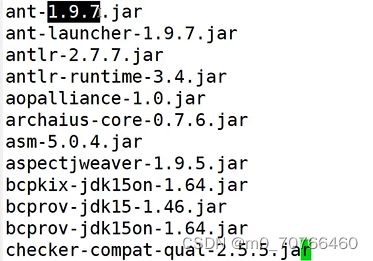
通过sed分组替换位置的方式,提取版本号(1.9.7等)
cat num.txt | sed -r 's/(.*)-(.*)(\.jar)/\1\2\3/'
完整匹配出了3部分

只匹配第二部分
第一部分就是前面的部分 第三部分就是.jar
cat num.txt | sed -r 's/(.*)-(.*)(\.jar)/\2/'
只要在.*- 前面的都包含在第一部分里面 -到.jar就是第二部分了

用扩展正则来写简单一点
grep -E "[0-9]+\." num.txt

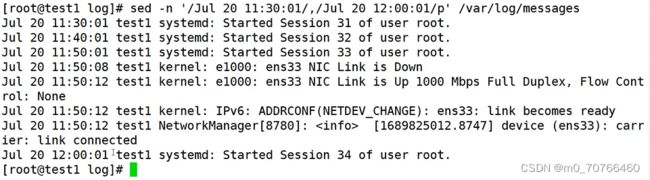
题2:查看指定时间范围内的日志内容(非常重要,面试会问,工作中用得到,非常好用)
例如查看十一点半到十二点之间的日志
sed -n '/Jul 20 11:30:01/,/Jul 20 12;00:01/p' /var/log/messages
需要注意一下日志的格式 不同日志开头的时间格式不一定相同 需要先看一下日志文件的格式长什么样 再把它截取出来 时间中间用逗号隔开
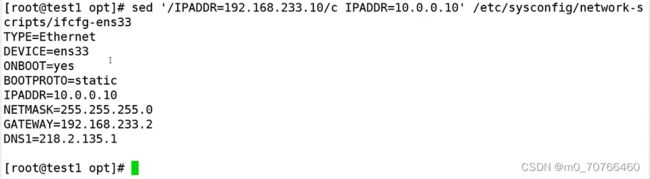
题3:修改网卡的ip地址
把192.168.233.10 修改为10.0.0.10
![]()
sed '/IPADDR=192.168.233.10/c IPADDR=10.0.0.10' /etc/sysconfig/network-scripts/ifcfg-ens33
整行替换
要生效加 -i 即可
综上:sed的主要作用,就是对文本内容进行增删改查
sed 可以支持扩展正则表达式 \{n} \{n,m\} \{,m\} \{n,\} 可以不用加\
sed 使用-i的时候,要慎用,先调试好了,再使用!
作业:sed写一个pxe自动装机的脚本,一键实现:pxe到无人值守