golang设计模式——行为模式
文章目录
- 简介
- 模版模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 命令模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
-
- 1 将函数封装为对象
- 2 将函数直接作为参数
- 总结
- 迭代器模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 观察者模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 中介者模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 备忘录模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 解释器模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 状态模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 策略模式
-
- 通俗解释
- 概念
- 应用场景
- 实例演示
- 总结
- 责任链模式
-
- 通俗解释
- 概念
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
- 访问者模式
-
- 通俗解释
- 概念
-
- 分析
-
- 定义分析
- 示意图分析
- 应用场景
- 优点
- 缺点
- 实例演示
- 总结
简介
设计模式是面向对象软件的设计经验,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。每一种设计模式系统的命名、解释和评价了面向对象中一个重要的和重复出现的设计。
行为模式 主要关注对象之间的通信,有以下几种:
- 模版模式(Template Pattern)
- 命令模式(Command Pattern)
- 迭代器模式(Iterator Pattern)
- 观察者模式(Observer Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 解释器模式(Interpreter Pattern)
- 状态模式(State Pattern)
- 策略模式(Strategy Pattern)
- 责任链模式(Chain of Responsibility Pattern)
- 访问者模式(Visitor Pattern)
模版模式
通俗解释
看过《如何说服女生上床》这部经典文章吗?女生从认识到上床的不变的步骤分为巧遇、打破僵局、展开追求、接吻、前戏、动手、爱抚、进去八大步骤 (Template method),但每个步骤针对不同的情况,都有不一样的做法,这就要看你随机应变啦 (具体实现);
模板模式:模板模式准备一个抽象类,将部分逻辑以具体方法以及具体构造子的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。先制定一个顶级逻辑框架,而将逻辑的细节留给具体的子类去实现。
概念
定义一个模板结构,将具体内容延迟到子类去实现。模板控制流程,子类负责实现。

**模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。**TemplateMethod是算法骨架,PrimitiveMethod1和PrimitiveMethod2是骨架中的某些步骤。
在模板模式经典的实现中,模板方法定义为 final,可以避免被子类重写。需要子类重写的方法定义为 abstract,可以强迫子类去实现。
以前用这种定义好算法骨架,具体实现在不同子类的方案时,一般使用的是工厂方法加代理模式。工厂方法能够提供更多的灵活性,但如果一个算法骨架中有10个具体算法,总不能让工厂生产10个不同的对象吧。所以如果算法骨架中有多个具体算法,而这些算法又是高内聚的,用模板模式就很合适。
应用场景
业务开发场景中,模板模式使用频率并不高,但是在框架方面,还是使用的比较频繁的。
- 有多个子类共有的方法,且逻辑相同。
- 重要的、复杂的方法,可以考虑作为模板方法。
优点
- 封装不变部分,扩展可变部分。
- 提取公共代码,便于维护。
- 行为由父类控制,子类实现。
缺点
每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大
实例演示
假设我现在要做一个短信推送的系统,那么需要
- 检查短信字数是否超过限制
- 检查手机号是否正确
- 发送短信
- 返回状态
我们可以发现,在发送短信的时候由于不同的供应商调用的接口不同,所以会有一些实现上的差异,但是他的算法(业务逻辑)是固定的
代码实现:
package template
import "fmt"
// ISMS ISMS
type ISMS interface {
send(content string, phone int) error
}
// SMS 短信发送基类
type sms struct {
ISMS
}
// Valid 校验短信字数
func (s *sms) Valid(content string) error {
if len(content) > 63 {
return fmt.Errorf("content is too long")
}
return nil
}
// Send 发送短信
func (s *sms) Send(content string, phone int) error {
if err := s.Valid(content); err != nil {
return err
}
// 调用子类的方法发送短信
return s.send(content, phone)
}
// TelecomSms 走电信通道
type TelecomSms struct {
*sms
}
// NewTelecomSms NewTelecomSms
func NewTelecomSms() *TelecomSms {
tel := &TelecomSms{}
// 这里有点绕,是因为 go 没有继承,用嵌套结构体的方法进行模拟
// 这里将子类作为接口嵌入父类,就可以让父类的模板方法 Send 调用到子类的函数
// 实际使用中,我们并不会这么写,都是采用组合+接口的方式完成类似的功能
tel.sms = &sms{ISMS: tel}
return tel
}
func (tel *TelecomSms) send(content string, phone int) error {
fmt.Println("send by telecom success")
return nil
}
单元测试:
package template
import (
"testing"
"github.com/stretchr/testify/assert"
)
func Test_sms_Send(t *testing.T) {
tel := NewTelecomSms()
err := tel.Send("test", 1239999)
assert.NoError(t, err)
}
总结
模板模式有两大作用:复用和扩展。其中,复用指的是,所有的子类可以复用父类中提供的模板方法的代码。扩展指的是,框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
命令模式
通俗解释
俺有一个 MM 家里管得特别严,没法见面,只好借助于她弟弟在我们俩之间传送信息,她对我有什么指示,就写一张纸条让她弟弟带给我。这不,她弟弟又传送过来一个 COMMAND,为了感谢他,我请他吃了碗杂酱面,哪知道他说:“我同时给我姐姐三个男朋友送 COMMAND,就数你最小气,才请我吃面。”
命令模式:命令模式把一个请求或者操作封装到一个对象中。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。命令模式允许请求的一方和发送的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否执行,何时被执行以及是怎么被执行的。系统支持命令的撤消。
概念
命令模式是一个高内聚的模式,将一个请求封装成一个对象,从而让你使用不同的请求把客户端参数化,对请求排队或者记录日志,可以提供命令的撤销和恢复功能。命令模式的核心在于引入了命令类,通过命令类来降低发送者和接收者的耦合度,请求发送者只需指定一个命令对象,再通过命令对象来调用请求接收者的处理方法。
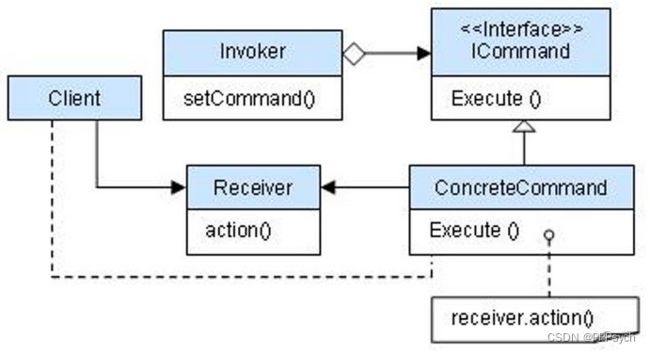
首先我们需要明白什么是命令。命令包括指令和数据。指令是行为,数据影响到指令。如前进3米,前进是指令,3米是数据。
然后我们再看一下各个类的含义。
Command和ConcreteCommand是命令,有Excute函数,代表要做的行为。
ConcreteCommand调用Excute(),最终调用Receiver的Action。这意味ConcreteCommand只是一个容器,真正的操作逻辑在Receiver中。
Invoker包含了所有Command,控制Command何时执行Excute()。
现在我们将上图简化,把Invoker、Receiver去掉,看看是否容易理解了:

通过这个简洁版示意图,我们来看一下为什么要用命令模式:
- 命令包括指令和数据,指令其实对应着操作,操作在代码中对应着函数。
- 命令模式其实是把函数封装成对象,系统能对对象进行各种操作,如排队执行、记录日志、撤销等。
为什么要将函数包装成对象呢?C、C++、Go支持函数指针,但并不是所有语言都有这种特性,这时命令模式就起作用了。而且即使语言支持函数指针,命令的数据部分怎么存放仍是一个问题。
所以简单理解,命令模式就是把请求打包成一个一个Command对象,存储起来,系统根据实际需求进行处理。
应用场景
大家可能感觉命令模式与MQ、工厂模式一样,其实在细节上是有区别的:
- MQ只包含数据,不包含行为,命令模式两者都包含
- 工厂模式需要实时执行,但命令模式可以进行存储,延后执行
优点
- 类间解耦,调用者角色与接收者角色之间没有任何依赖关系,调用者实现功能时只需调用Command抽象类的execute方法就可以,不需要了解到底是哪个接收者执行。
- 可扩展性,Command的子类可以非常容易的扩展,而调用者Invoker和高层次的模块Client不产生严重的代码耦合。
- 命令模式结合其他模式,命令模式可以结合责任链模式,实现命令族解析任务;结合模板方法模式,则可以减少Command子类的膨胀问题。
缺点
如果有N个命令,那么Command子类就有N个,这个类将膨胀得非常大。
实例演示
接下来会有两个例子,第一个是按照原文定义的方式,将函数封装成对象,第二个例子我们直接将函数作为参数传递。
1 将函数封装为对象
假设现在有一个游戏服务,我们正在实现一个游戏后端,使用一个 goroutine 不断接收来自客户端请求的命令,并且将它放置到一个队列当中,然后我们在另外一个 goroutine 中来执行它
代码实现:
package command
import "fmt"
// ICommand 命令
type ICommand interface {
Execute() error
}
// StartCommand 游戏开始运行
type StartCommand struct{}
// NewStartCommand NewStartCommand
func NewStartCommand( /*正常情况下这里会有一些参数*/ ) *StartCommand {
return &StartCommand{}
}
// Execute Execute
func (c *StartCommand) Execute() error {
fmt.Println("game start")
return nil
}
// ArchiveCommand 游戏存档
type ArchiveCommand struct{}
// NewArchiveCommand NewArchiveCommand
func NewArchiveCommand( /*正常情况下这里会有一些参数*/ ) *ArchiveCommand {
return &ArchiveCommand{}
}
// Execute Execute
func (c *ArchiveCommand) Execute() error {
fmt.Println("game archive")
return nil
}
单元测试:
package command
import (
"fmt"
"testing"
"time"
)
func TestDemo(t *testing.T) {
// 用于测试,模拟来自客户端的事件
eventChan := make(chan string)
go func() {
events := []string{"start", "archive", "start", "archive", "start", "start"}
for _, e := range events {
eventChan <- e
}
}()
defer close(eventChan)
// 使用命令队列缓存命令
commands := make(chan ICommand, 1000)
defer close(commands)
go func() {
for {
// 从请求或者其他地方获取相关事件参数
event, ok := <-eventChan
if !ok {
return
}
var command ICommand
switch event {
case "start":
command = NewStartCommand()
case "archive":
command = NewArchiveCommand()
}
// 将命令入队
commands <- command
}
}()
for {
select {
case c := <-commands:
c.Execute()
case <-time.After(1 * time.Second):
fmt.Println("timeout 1s")
return
}
}
}
2 将函数直接作为参数
假设现在有一个游戏服务,我们正在实现一个游戏后端,使用一个 goroutine 不断接收来自客户端请求的命令,并且将它放置到一个队列当中,然后我们在另外一个 goroutine 中来执行它
代码实现:
package command
import "fmt"
// Command 命令
type Command func() error
// StartCommandFunc 返回一个 Command 命令
// 是因为正常情况下不会是这么简单的函数
// 一般都会有一些参数
func StartCommandFunc() Command {
return func() error {
fmt.Println("game start")
return nil
}
}
// ArchiveCommandFunc ArchiveCommandFunc
func ArchiveCommandFunc() Command {
return func() error {
fmt.Println("game archive")
return nil
}
}
单元测试:
package command
import (
"fmt"
"testing"
"time"
)
func TestDemoFunc(t *testing.T) {
// 用于测试,模拟来自客户端的事件
eventChan := make(chan string)
go func() {
events := []string{"start", "archive", "start", "archive", "start", "start"}
for _, e := range events {
eventChan <- e
}
}()
defer close(eventChan)
// 使用命令队列缓存命令
commands := make(chan Command, 1000)
defer close(commands)
go func() {
for {
// 从请求或者其他地方获取相关事件参数
event, ok := <-eventChan
if !ok {
return
}
var command Command
switch event {
case "start":
command = StartCommandFunc()
case "archive":
command = ArchiveCommandFunc()
}
// 将命令入队
commands <- command
}
}()
for {
select {
case c := <-commands:
c()
case <-time.After(1 * time.Second):
fmt.Println("timeout 1s")
return
}
}
}
总结
设计模式是为了解决现实中的问题,我们需要和具体场景相绑定。在解决问题的时候,采用的是不是标准的设计模式并不重要,模式只是手段,手段需要为达成目的服务。
迭代器模式
通俗解释
我爱上了 Mary,不顾一切的向她求婚。Mary:“想要我跟你结婚,得答应我的条件” 我:“什么条件我都答应,你说吧” Mary:“我看上了那个一克拉的钻石” 我:“我买,我买,还有吗?” Mary:“我看上了湖边的那栋别墅” 我:“我买,我买,还有吗?” Mary:“我看上那辆法拉利跑车” 我脑袋嗡的一声,坐在椅子上,一咬牙:“我买,我买,还有吗?”
迭代模式:迭代模式可以顺序访问一个聚集中的元素而不必暴露聚集的内部表象。多个对象聚在一起形成的总体称之为聚集,聚集对象是能够包容一组对象的容器对象。迭代子模式将迭代逻辑封装到一个独立的子对象中,从而与聚集本身隔开。
迭代模式简化了聚集的界面。每一个聚集对象都可以有一个或一个以上的迭代子对象,每一个迭代子的迭代状态可以是彼此独立的。迭代算法可以独立于聚集角色变化。
概念
迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露其内部的表示。把游走的任务放在迭代器上,而不是聚合上。这样简化了聚合的接口和实现,也让责任各得其所。
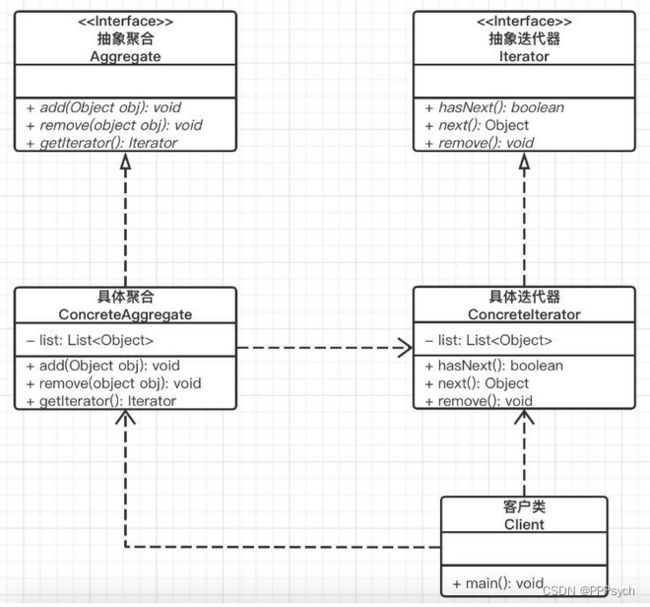
角色:
- 抽象聚合(Aggregate)角色:定义存储、添加、删除聚合对象以及创建迭代器对象的接口。
- 具体聚合(ConcreteAggregate)角色:实现抽象聚合类,返回一个具体迭代器的实例。
- 抽象迭代器(Iterator)角色:定义访问和遍历聚合元素的接口,通常包含 hasNext()、first()、next() 等方法。
- 具体迭代器(Concretelterator)角色:实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
分析:
通过上图可以看出,对于集合Aggregate,其遍历能力被拆了出来,由Iterator负责遍历。
大家可能有疑问,可以用for循环解决的问题,为啥要搞得这么复杂呢?
其实主要看集合结构的复杂性,如果是普通的数组,可以不需要Iterator,直接使用for循环即可。如果是复杂的集合呢?对于这个集合需要有多种遍历方案呢?
如对于图结构,有广度优先、深度优先两种遍历方式,都在图集合里实现,是否感觉违背了职责单一原则。
所以对于复杂结构,迭代器有如下优势:
- 这种拆分,使集合和迭代器职责更加单一,符合单一职责原则
- 迭代器结构统一,方便使用,使用者无需知道遍历细节便可遍历集合
- 符合开闭原则,可以按照需求自己开发迭代器,无需改动集合类
- 符合里氏替换原则,可以方便的进行迭代方案的更换
通过上面示意图可发现设计思路:迭代器中需要定义first()、isDone()、currentItem()、next() 四个最基本的方法。待遍历的集合对象通过依赖注入传递到迭代器类中。集合可通过CreateIterator() 方法来创建迭代器。
应用场景
迭代器模式一般在library中使用的比较多,毕竟library提供的大多是基础结构。实际业务场景中,很少需要自己编写迭代器。但代码还是要写的,这次写图集合与深度优先遍历迭代器,大家如果对其它类型的图迭代器感兴趣的话,可自行编写。
优点
- 它支持以不同的方式遍历一个聚合对象。
- 迭代器简化了聚合类。
- 在同一个聚合上可以有多个遍历。
- 在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
缺点
由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
实例演示
下面是一个简单的自定义数组类型的例子
代码实现:
package iterator
// Iterator 迭代器接口
type Iterator interface {
HasNext() bool
Next()
// 获取当前元素,由于 Go 1.15 中还没有泛型,所以我们直接返回 interface{}
CurrentItem() interface{}
}
// ArrayInt 数组
type ArrayInt []int
// Iterator 返回迭代器
func (a ArrayInt) Iterator() Iterator {
return &ArrayIntIterator{
arrayInt: a,
index: 0,
}
}
// ArrayIntIterator 数组迭代
type ArrayIntIterator struct {
arrayInt ArrayInt
index int
}
// HasNext 是否有下一个
func (iter *ArrayIntIterator) HasNext() bool {
return iter.index < len(iter.arrayInt)-1
}
// Next 游标加一
func (iter *ArrayIntIterator) Next() {
iter.index++
}
// CurrentItem 获取当前元素
func (iter *ArrayIntIterator) CurrentItem() interface{} {
return iter.arrayInt[iter.index]
}
单元测试:
package iterator
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestArrayInt_Iterator(t *testing.T) {
data := ArrayInt{1, 3, 5, 7, 8}
iterator := data.Iterator()
// i 用于测试
i := 0
for iterator.HasNext() {
assert.Equal(t, data[i], iterator.CurrentItem())
iterator.Next()
i++
}
}
总结
迭代器模式可能对于大部分研发同学来说是不需要的,但对于搞基础框架、搞语言的同学来说应该经常会用。对于迭代器模式,并不是说学习怎么使用,更重要的一点是需要感知设计模式的思想内核。
观察者模式
通俗解释
想知道咱们公司最新 MM 情报吗?加入公司的 MM 情报邮件组就行了,tom 负责搜集情报,他发现的新情报不用一个一个通知我们,直接发布给邮件组,我们作为订阅者(观察者)就可以及时收到情报啦。
观察者模式:观察者模式定义了一种一队多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自动更新自己。
概念
观察者模式(Observer Pattern):定义对象之间的一种一对多依赖关系,让多个观察者对象监听主题对象,当主题对象发生变化时,其相关依赖对象皆得到通知并被自动更新。观察者模式的别名包括发布-订阅(Publish/Subscribe)模式、模型-视图(Model/View)模式、源-监听器(Source/Listener)模式或从属者(Dependents)模式。观察者模式是一种对象行为型模式。
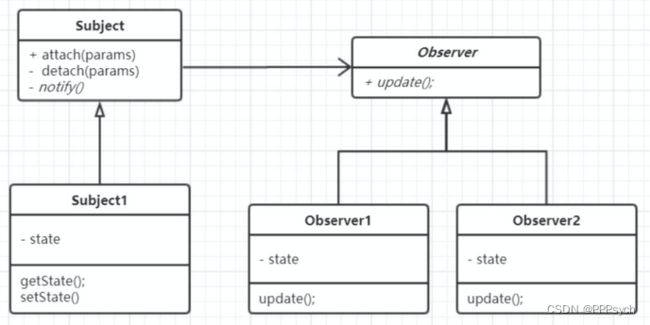
分析:
观察者模式算是比较通用的设计模式了,思路也比较清晰。Subject里有Observer集合,当Subject有更新时,通知各个Observer。Subject为了管理Observer,自身设置了增加、删除功能。
当Subject有更新,通知Observer时,有很多细节值得讨论。
-
第一个问题是使用同步阻塞还是异步非阻塞
- 同步阻塞是最经典的实现方式,主要是为了代码解耦;
- 异步非阻塞除了能实现代码解耦之外,还能提高代码的执行效率;
-
第二个问题是如何保证所有Observer都通知成功。
- 方案一是利用消息队列ACK的能力,Observer订阅消息队列。Subject只需要确保信息通知给消息队列即可。
- 方案二是Subject将失败的通知记录,方便后面进行重试。
- 方案三是定义好规范,例如只对网络失败这种错误进行记录,业务失败类型不管理,由业务自行保证成功。
-
第三个问题是不同进程/系统如何进行通知。
- 进程间的观察者模式解耦更加彻底,一般是基于消息队列来实现,用来实现不同进程间的被观察者和观察者之间的交互。
应用场景
观察者模式的使用场景还是很多的,它和享元模式一样,更多体现的是一种设计理念。
一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。 一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。 一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。 一个对象必须通知其他对象,而并不知道这些对象是谁。 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
优点
- 观察者和被观察者是抽象耦合的。
- 建立一套触发机制。
缺点
- 如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
- 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
实例演示
我们实现一个支持以下功能的事件总线
- 异步不阻塞
- 支持任意参数值
代码实现:
package eventbus
import (
"fmt"
"reflect"
"sync"
)
// Bus Bus
type Bus interface {
Subscribe(topic string, handler interface{}) error
Publish(topic string, args ...interface{})
}
// AsyncEventBus 异步事件总线
type AsyncEventBus struct {
handlers map[string][]reflect.Value
lock sync.Mutex
}
// NewAsyncEventBus new
func NewAsyncEventBus() *AsyncEventBus {
return &AsyncEventBus{
handlers: map[string][]reflect.Value{},
lock: sync.Mutex{},
}
}
// Subscribe 订阅
func (bus *AsyncEventBus) Subscribe(topic string, f interface{}) error {
bus.lock.Lock()
defer bus.lock.Unlock()
v := reflect.ValueOf(f)
if v.Type().Kind() != reflect.Func {
return fmt.Errorf("handler is not a function")
}
handler, ok := bus.handlers[topic]
if !ok {
handler = []reflect.Value{}
}
handler = append(handler, v)
bus.handlers[topic] = handler
return nil
}
// Publish 发布
// 这里异步执行,并且不会等待返回结果
func (bus *AsyncEventBus) Publish(topic string, args ...interface{}) {
handlers, ok := bus.handlers[topic]
if !ok {
fmt.Println("not found handlers in topic:", topic)
return
}
params := make([]reflect.Value, len(args))
for i, arg := range args {
params[i] = reflect.ValueOf(arg)
}
for i := range handlers {
go handlers[i].Call(params)
}
}
单元测试:
package eventbus
import (
"fmt"
"testing"
"time"
)
func sub1(msg1, msg2 string) {
time.Sleep(1 * time.Microsecond)
fmt.Printf("sub1, %s %s\n", msg1, msg2)
}
func sub2(msg1, msg2 string) {
fmt.Printf("sub2, %s %s\n", msg1, msg2)
}
func TestAsyncEventBus_Publish(t *testing.T) {
bus := NewAsyncEventBus()
bus.Subscribe("topic:1", sub1)
bus.Subscribe("topic:1", sub2)
bus.Publish("topic:1", "test1", "test2")
bus.Publish("topic:1", "testA", "testB")
time.Sleep(1 * time.Second)
}
运行结果:
=== RUN TestAsyncEventBus_Publish
sub2, testA testB
sub2, test1 test2
sub1, testA testB
sub1, test1 test2
--- PASS: TestAsyncEventBus_Publish (1.01s)
总结
实际上,设计模式要干的事情就是解耦。创建型模式是将创建和使用代码解耦,结构型模式是将不同功能代码解耦,行为型模式是将不同的行为代码解耦,具体到观察者模式,它是将观察者和被观察者代码解耦。
中介者模式
通俗解释
四个 MM 打麻将,相互之间谁应该给谁多少钱算不清楚了,幸亏当时我在旁边,按照各自的筹码数算钱,赚了钱的从我这里拿,赔了钱的也付给我,一切就 OK 啦,俺得到了四个 MM 的电话。调停者模式:调停者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使他们可以松散偶合。
概念
中介者模式(Mediator Pattern):用一个对象来封装一系列的对象交互,中介者使各对象不需要显示地相互引用,从而使耦合松散,而且可以独立地改变它们之间的交互。就像租房找中介类似,租房者只需和中介交流即可,而不用直接和各个房东交流。

分析:
对于定义,大家比较容易理解。由中介者控制所有的交互,Colleague对象无需相互感知。
使用中介者模式有个前提,Colleague之间相互影响,即一个Colleague的变化会影响其它Colleague。
我们再来看示意图。通过示意图可以看出
- Mediator包含所有Colleague,这是中介者能控制所有交互的基础
- Colleague包含Mediator,Colleague变化可直接通知Mediator,这是Colleague无需知道其它Colleague的基础,只需知道Mediator即可
根据前面提到的前提和示意图,我们思考的再深一些,ConcreteColleague是否有相同父类并不重要,只要Mediator包含所有ConcreteColleague,ConcreteColleague有Mediator,中介者模式依然有效。
应用场景
- 系统中对象之间存在比较复杂的引用关系,导致它们之间的依赖关系结构混乱而且难以复用该对象。
- 想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
优点
- 降低了类的复杂度,将一对多转化成了一对一。
- 各个类之间的解耦。
- 符合迪米特原则。
缺点
中介者会庞大,变得复杂难以维护。
实例演示
假设我们现在有一个较为复杂的对话框,里面包括,登录组件,注册组件,以及选择框
- 当选择框选择“登录”时,展示登录相关组件
- 当选择框选择“注册”时,展示注册相关组件
代码实现:
package mediator
import (
"fmt"
"reflect"
)
// Input 假设这表示一个输入框
type Input string
// String String
func (i Input) String() string {
return string(i)
}
// Selection 假设这表示一个选择框
type Selection string
// Selected 当前选中的对象
func (s Selection) Selected() string {
return string(s)
}
// Button 假设这表示一个按钮
type Button struct {
onClick func()
}
// SetOnClick 添加点击事件回调
func (b *Button) SetOnClick(f func()) {
b.onClick = f
}
// IMediator 中介模式接口
type IMediator interface {
HandleEvent(component interface{})
}
// Dialog 对话框组件
type Dialog struct {
LoginButton *Button
RegButton *Button
Selection *Selection
UsernameInput *Input
PasswordInput *Input
RepeatPasswordInput *Input
}
// HandleEvent HandleEvent
func (d *Dialog) HandleEvent(component interface{}) {
switch {
case reflect.DeepEqual(component, d.Selection):
if d.Selection.Selected() == "登录" {
fmt.Println("select login")
fmt.Printf("show: %s\n", d.UsernameInput)
fmt.Printf("show: %s\n", d.PasswordInput)
} else if d.Selection.Selected() == "注册" {
fmt.Println("select register")
fmt.Printf("show: %s\n", d.UsernameInput)
fmt.Printf("show: %s\n", d.PasswordInput)
fmt.Printf("show: %s\n", d.RepeatPasswordInput)
}
// others, 如果点击了登录按钮,注册按钮
}
}
单元测试:
package mediator
import "testing"
func TestDemo(t *testing.T) {
usernameInput := Input("username input")
passwordInput := Input("password input")
repeatPwdInput := Input("repeat password input")
selection := Selection("登录")
d := &Dialog{
Selection: &selection,
UsernameInput: &usernameInput,
PasswordInput: &passwordInput,
RepeatPasswordInput: &repeatPwdInput,
}
d.HandleEvent(&selection)
regSelection := Selection("注册")
d.Selection = ®Selection
d.HandleEvent(®Selection)
}
总结
中介者模式算是聚而歼之的模式,因为从分而治之上讲,对应的操作应该让每一个Colleague自行管理,但这样做,Colleague之间需要相互了解,沟通成本太高。
如果收拢到Mediator,整体效率会高很多,但Mediator存在成为上帝类的可能,反而导致不好维护。
备忘录模式
通俗解释
同时跟几个 MM 聊天时,一定要记清楚刚才跟 MM 说了些什么话,不然 MM 发现了会不高兴的哦,幸亏我有个备忘录,刚才与哪个 MM 说了什么话我都拷贝一份放到备忘录里面保存,这样可以随时察看以前的记录啦。
备忘录模式:备忘录对象是一个用来存储另外一个对象内部状态的快照的对象。备忘录模式的用意是在不破坏封装的条件下,将一个对象的状态捉住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。
概念
所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。
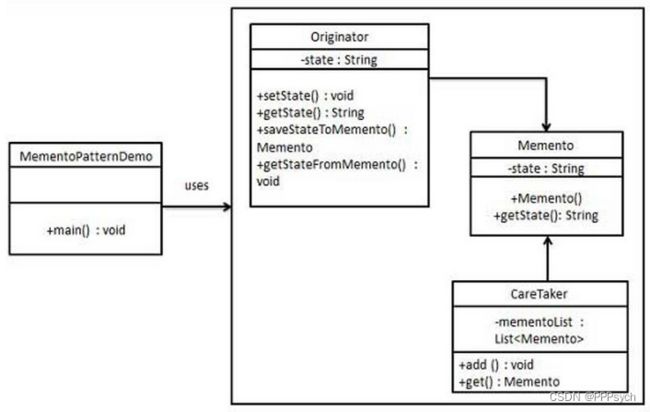
分析:
从定义上看,除了不破坏封装性外,其它都比较容易理解。对于不破坏封装性,我觉得有两点:
- 备忘录是Originator自己创建的
- 备忘录应该只有获取相关的接口,不应该有修改相关的接口
Caretaker是做什么用的呢?备忘录不是只备忘一份,可能备忘多份,Caretaker就是管理众多备忘录的。
Originator通过CreateMemento创建备忘录,通过SetMemento恢复到指定状态。
为什么备份的时候使用的是Memento而不是直接使用Originator呢?这是因为Memento只保存数据,如果将Originator保存,则表示将功能也进行保存,属于不该保存的而保存了。
另外只保存数据还有一个好处,即使解析出数据,也不知道如何使用,只有Originator知道真正的口诀。
应用场景
保存以及恢复数据相关业务场景,想要恢复到之前的状态。例如:游戏或者文档,经常使用到备份相关的功能。
优点
- 为用户提供一种可恢复的机制
- 实现了信息的封装,使得用户不需要关心状态的保存细节
缺点
消耗资源。
实例演示
玩游戏打Boss的时候,一般会做存档,失败了重新来
代码实现:
package main
import (
"container/list"
"fmt"
)
/**
* @Description: 备忘录
*/
type Memento struct {
mario *Mario
}
func (m *Memento) GetMario() *Mario {
return m.mario
}
/**
* @Description: 管理备忘录
*/
type Caretaker struct {
stack *list.List
}
/**
* @Description: 保存备忘录
* @receiver c
* @param m
*/
func (c *Caretaker) Save(m *Memento) {
c.stack.PushBack(m)
}
/**
* @Description: 获取上一个备忘录
* @receiver c
* @return *Memento
*/
func (c *Caretaker) Pop() *Memento {
e := c.stack.Back()
c.stack.Remove(e)
return e.Value.(*Memento)
}
type Mario struct {
score int64
status MarioStatus
}
/**
* @Description: 展示信息和分数
* @receiver m
*/
func (m *Mario) ShowInfo() {
m.status.Name()
fmt.Println("当前分数为:", m.score)
}
/**
* @Description: 创建备忘录
* @receiver m
*/
func (m *Mario) CreateMemento() *Memento {
return &Memento{
mario: &Mario{
score: m.score,
status: m.status,
},
}
}
/**
* @Description: 恢复数据
* @receiver m
* @param mem
*/
func (m *Mario) SetMemento(mem *Memento) {
m.score = mem.mario.score
m.status = mem.mario.status
}
type MarioStatus interface {
Name()
ObtainMushroom()
ObtainCape()
MeetMonster()
SetMario(mario *Mario)
}
/**
* @Description: 小马里奥
*/
type SmallMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (s *SmallMarioStatus) SetMario(mario *Mario) {
s.mario = mario
}
func (s *SmallMarioStatus) Name() {
fmt.Println("小马里奥")
}
/**
* @Description: 获得蘑菇变为超级马里奥
* @receiver s
*/
func (s *SmallMarioStatus) ObtainMushroom() {
s.mario.status = &SuperMarioStatus{
mario: s.mario,
}
s.mario.score += 100
}
/**
* @Description: 获得斗篷变为斗篷马里奥
* @receiver s
*/
func (s *SmallMarioStatus) ObtainCape() {
s.mario.status = &CapeMarioStatus{
mario: s.mario,
}
s.mario.score += 200
}
/**
* @Description: 遇到怪兽减100
* @receiver s
*/
func (s *SmallMarioStatus) MeetMonster() {
s.mario.score -= 100
}
/**
* @Description: 超级马里奥
*/
type SuperMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (s *SuperMarioStatus) SetMario(mario *Mario) {
s.mario = mario
}
func (s *SuperMarioStatus) Name() {
fmt.Println("超级马里奥")
}
/**
* @Description: 获得蘑菇无变化
* @receiver s
*/
func (s *SuperMarioStatus) ObtainMushroom() {
}
/**
* @Description:获得斗篷变为斗篷马里奥
* @receiver s
*/
func (s *SuperMarioStatus) ObtainCape() {
s.mario.status = &CapeMarioStatus{
mario: s.mario,
}
s.mario.score += 200
}
/**
* @Description: 遇到怪兽变为小马里奥
* @receiver s
*/
func (s *SuperMarioStatus) MeetMonster() {
s.mario.status = &SmallMarioStatus{
mario: s.mario,
}
s.mario.score -= 200
}
/**
* @Description: 斗篷马里奥
*/
type CapeMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (c *CapeMarioStatus) SetMario(mario *Mario) {
c.mario = mario
}
func (c *CapeMarioStatus) Name() {
fmt.Println("斗篷马里奥")
}
/**
* @Description:获得蘑菇无变化
* @receiver c
*/
func (c *CapeMarioStatus) ObtainMushroom() {
}
/**
* @Description: 获得斗篷无变化
* @receiver c
*/
func (c *CapeMarioStatus) ObtainCape() {
}
/**
* @Description: 遇到怪兽变为小马里奥
* @receiver c
*/
func (c *CapeMarioStatus) MeetMonster() {
c.mario.status = &SmallMarioStatus{
mario: c.mario,
}
c.mario.score -= 200
}
func main() {
caretaker := &Caretaker{
stack: list.New(),
}
mario := Mario{
status: &SmallMarioStatus{},
score: 0,
}
mario.status.SetMario(&mario)
mario.status.Name()
fmt.Println("-------------------获得蘑菇\n")
mario.status.ObtainMushroom()
mario.status.Name()
fmt.Println("-------------------获得斗篷\n")
mario.status.ObtainCape()
fmt.Println("-------------------备份一下,要打怪了,当前状态为\n")
mario.ShowInfo()
caretaker.Save(mario.CreateMemento())
fmt.Println("-------------------开始打怪\n")
mario.status.Name()
fmt.Println("-------------------遇到怪兽\n")
mario.status.MeetMonster()
fmt.Println("-------------------打怪失败,目前状态为\n")
mario.ShowInfo()
fmt.Println("-------------------恢复状态,重新打怪\n")
mario.SetMemento(caretaker.Pop())
mario.ShowInfo()
}
运行结果:
➜go run main.go
小马里奥
——————-获得蘑菇
超级马里奥
——————-获得斗篷
——————-备份一下,要打怪了,当前状态为
斗篷马里奥
当前分数为: 300
——————-开始打怪
斗篷马里奥
——————-遇到怪兽
——————-打怪失败,目前状态为
小马里奥
当前分数为: 100
——————-恢复状态,重新打怪
斗篷马里奥
当前分数为: 300
总结
备忘录模式虽然不常用,但是对合适的场景还是很有帮助的。
解释器模式
通俗解释
俺有一个《泡 MM 真经》,上面有各种泡 MM 的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟 MM 约会时,只要做一个 Interpreter,照着上面的脚本执行就可以了。
解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。
在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何排列组合都是一个语言。
概念
解释器模式(Interpreter Pattern):给定一个语言,定义它的文法的一种表示。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。简单来说,就是为了解释一种语言,而为语言创建的解释器。

分析:
通过定义可以看出,“语言”必然存在规则,而且规则可能相对复杂。对于每一条规则,可以设置对应的类来翻译。
模式定义与示意图完全对应,解释器Expression用于翻译Context,由于Context包含内容类型不同,对这些不同类型的内容创建不同解释器进行解释。
举个例子,假设定义一个新的加减乘除语言,对于 8 + 2 - 5这种情况,新的语言为 8 2 5 + -。在这个例子中,Context就是8 2 5 + -,新语言包含数字和运算符,我们就可以创建数字解释器和运算符解释器,对数字和运算符进行解释。
为什么要用解释器模式呢?
主要是为了将语法解析的工作拆分到各个小类中,以此来避免大而全的解析类。
如果打算用解释器模式,一般的做法是,将语法规则拆分成一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
应用场景
如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题,比如 SQL解析、日志解析。
优点
- 可扩展性比较好,灵活。
- 增加了新的解释表达式的方式。
- 易于实现简单文法。
缺点
- 可利用场景比较少。
- 对于复杂的文法比较难维护。
- 解释器模式会引起类膨胀。
- 解释器模式采用递归调用方法。
实例演示
假设我们现在有一个监控系统,现在需要实现一个告警模块,可以根据输入的告警规则来决定是否触发告警
- 告警规则支持 &&、>、< 3种运算符
- 其中 >、< 优先级比 && 更高
代码实现:
package interpreter
import (
"fmt"
"regexp"
"strconv"
"strings"
)
// AlertRule 告警规则
type AlertRule struct {
expression IExpression
}
// NewAlertRule NewAlertRule
func NewAlertRule(rule string) (*AlertRule, error) {
exp, err := NewAndExpression(rule)
return &AlertRule{expression: exp}, err
}
// Interpret 判断告警是否触发
func (r AlertRule) Interpret(stats map[string]float64) bool {
return r.expression.Interpret(stats)
}
// IExpression 表达式接口
type IExpression interface {
Interpret(stats map[string]float64) bool
}
// GreaterExpression >
type GreaterExpression struct {
key string
value float64
}
// Interpret Interpret
func (g GreaterExpression) Interpret(stats map[string]float64) bool {
v, ok := stats[g.key]
if !ok {
return false
}
return v > g.value
}
// NewGreaterExpression NewGreaterExpression
func NewGreaterExpression(exp string) (*GreaterExpression, error) {
data := regexp.MustCompile(`\s+`).Split(strings.TrimSpace(exp), -1)
if len(data) != 3 || data[1] != ">" {
return nil, fmt.Errorf("exp is invalid: %s", exp)
}
val, err := strconv.ParseFloat(data[2], 10)
if err != nil {
return nil, fmt.Errorf("exp is invalid: %s", exp)
}
return &GreaterExpression{
key: data[0],
value: val,
}, nil
}
// LessExpression <
type LessExpression struct {
key string
value float64
}
// Interpret Interpret
func (g LessExpression) Interpret(stats map[string]float64) bool {
v, ok := stats[g.key]
if !ok {
return false
}
return v < g.value
}
// NewLessExpression NewLessExpression
func NewLessExpression(exp string) (*LessExpression, error) {
data := regexp.MustCompile(`\s+`).Split(strings.TrimSpace(exp), -1)
if len(data) != 3 || data[1] != "<" {
return nil, fmt.Errorf("exp is invalid: %s", exp)
}
val, err := strconv.ParseFloat(data[2], 10)
if err != nil {
return nil, fmt.Errorf("exp is invalid: %s", exp)
}
return &LessExpression{
key: data[0],
value: val,
}, nil
}
// AndExpression &&
type AndExpression struct {
expressions []IExpression
}
// Interpret Interpret
func (e AndExpression) Interpret(stats map[string]float64) bool {
for _, expression := range e.expressions {
if !expression.Interpret(stats) {
return false
}
}
return true
}
// NewAndExpression NewAndExpression
func NewAndExpression(exp string) (*AndExpression, error) {
exps := strings.Split(exp, "&&")
expressions := make([]IExpression, len(exps))
for i, e := range exps {
var expression IExpression
var err error
switch {
case strings.Contains(e, ">"):
expression, err = NewGreaterExpression(e)
case strings.Contains(e, "<"):
expression, err = NewLessExpression(e)
default:
err = fmt.Errorf("exp is invalid: %s", exp)
}
if err != nil {
return nil, err
}
expressions[i] = expression
}
return &AndExpression{expressions: expressions}, nil
}
单元测试:
package interpreter
import (
"testing"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/require"
)
func TestAlertRule_Interpret(t *testing.T) {
stats := map[string]float64{
"a": 1,
"b": 2,
"c": 3,
}
tests := []struct {
name string
stats map[string]float64
rule string
want bool
}{
{
name: "case1",
stats: stats,
rule: "a > 1 && b > 10 && c < 5",
want: false,
},
{
name: "case2",
stats: stats,
rule: "a < 2 && b > 10 && c < 5",
want: false,
},
{
name: "case3",
stats: stats,
rule: "a < 5 && b > 1 && c < 10",
want: false,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
r, err := NewAlertRule(tt.rule)
require.NoError(t, err)
assert.Equal(t, tt.want, r.Interpret(tt.stats))
})
}
}
总结
解释器模式主要是分而治之,将翻译功能分开管理,方便维护。翻译器模式理解难度和使用难度不大,主要是使用场景比较受限。
状态模式
通俗解释
跟 MM 交往时,一定要注意她的状态哦,在不同的状态时她的行为会有不同,比如你约她今天晚上去看电影,对你没兴趣的 MM 就会说 “有事情啦”,对你不讨厌但还没喜欢上的 MM 就会说 “好啊,不过可以带上我同事么?”,已经喜欢上你的 MM 就会说 “几点钟?看完电影再去泡吧怎么样?”,当然你看电影过程中表现良好的话,也可以把 MM 的状态从不讨厌不喜欢变成喜欢哦。
状态模式:状态模式允许一个对象在其内部状态改变的时候改变行为。这个对象看上去象是改变了它的类一样。状态模式把所研究的对象的行为包装在不同的状态对象里,每一个状态对象都属于一个抽象状态类的一个子类。
状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。状态模式需要对每一个系统可能取得的状态创立一个状态类的子类。当系统的状态变化时,系统便改变所选的子类。
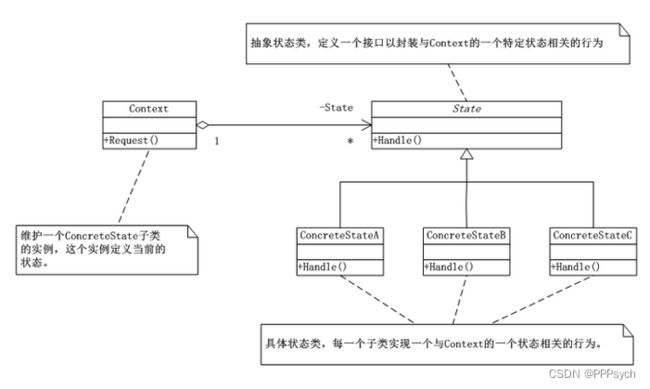
概念
在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。
在状态模式中,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
分析
状态机有3个组成部分:状态(State)、事件(Event)、动作(Action)。事件触发状态的转移及动作的执行。
只看定义和UML,可能比较难理解使用状态模式有什么好处,举个例子就清晰了。
假设有四种状态A、B、C、D,同时有四种触发事件E1、E2、E3、E4,如果不使用状态模式,写出来的样子是这样的:
func E1() {
if status == "A" {
//状态迁移+动作执行
} else if status == "B" {
//状态迁移+动作执行
} else if status == "C" {
//状态迁移+动作执行
} else if status == "D" {
//状态迁移+动作执行
}
}
func E2() {
if status == "A" {
//状态迁移+动作执行
} else if status == "B" {
//状态迁移+动作执行
} else if status == "C" {
//状态迁移+动作执行
} else if status == "D" {
//状态迁移+动作执行
}
}
单看伪代码可能觉得还好,但是细想一想,如果动作执行比较复杂,代码是不是就很丑了。后期如果状态或者事件变更,如何确保每一处都进行了更改?这时候状态模式便起作用了。
我们创建四个类,如UML中的ConcreteStateA、ConcreteStateB、ConcreteStateC、ConcreteStateD,分别代表四种状态。每个状态类中有4个Handle函数,分别对应4个事件。通过这种方式,将糅杂在一起的逻辑进行了拆分,代码看起来优雅了很多。
应用场景
一个对象存个多个状态(不同状态下行为不同),且状态之间可以可相互切换。
优点
- 封装了转换规则。
- 枚举可能的状态,在枚举状态之前需要确定状态种类。
- 将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。
缺点
- 状态多的业务场景导致类目数量增加,导致系统非常复杂。
- 状态模式对"开闭原则"的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源代码,否则无法切换到新增状态,而且修改某个状态类的行为也需修改对应类的源代码。
实例演示
一般游戏中使用状态模式相对多一些。本次借用《设计模式之美》里超级马里奥的例子,使用超级马里奥介绍实在是太合适了,因为马里奥有多种状态、多种触发事件,特别适合使用状态模式
分析:马里奥状态有小马里奥(Small Mario)、超级马里奥(Super Mario)、斗篷马里奥(Cape Mario),小马里奥吃了蘑菇变为超级马里奥,小马里奥和超级马里奥获得斗篷变成斗篷马里奥,超级马里奥和斗篷马里奥碰到怪物变成小马里奥。
代码实现:
package main
import "fmt"
type Mario struct {
score int64
status MarioStatus
}
type MarioStatus interface {
Name()
ObtainMushroom()
ObtainCape()
MeetMonster()
SetMario(mario *Mario)
}
/**
* @Description: 小马里奥
*/
type SmallMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (s *SmallMarioStatus) SetMario(mario *Mario) {
s.mario = mario
}
func (s *SmallMarioStatus) Name() {
fmt.Println("小马里奥")
}
/**
* @Description: 获得蘑菇变为超级马里奥
* @receiver s
*/
func (s *SmallMarioStatus) ObtainMushroom() {
s.mario.status = &SuperMarioStatus{
mario: s.mario,
}
s.mario.score += 100
}
/**
* @Description: 获得斗篷变为斗篷马里奥
* @receiver s
*/
func (s *SmallMarioStatus) ObtainCape() {
s.mario.status = &CapeMarioStatus{
mario: s.mario,
}
s.mario.score += 200
}
/**
* @Description: 遇到怪兽减100
* @receiver s
*/
func (s *SmallMarioStatus) MeetMonster() {
s.mario.score -= 100
}
/**
* @Description: 超级马里奥
*/
type SuperMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (s *SuperMarioStatus) SetMario(mario *Mario) {
s.mario = mario
}
func (s *SuperMarioStatus) Name() {
fmt.Println("超级马里奥")
}
/**
* @Description: 获得蘑菇无变化
* @receiver s
*/
func (s *SuperMarioStatus) ObtainMushroom() {
}
/**
* @Description:获得斗篷变为斗篷马里奥
* @receiver s
*/
func (s *SuperMarioStatus) ObtainCape() {
s.mario.status = &CapeMarioStatus{
mario: s.mario,
}
s.mario.score += 200
}
/**
* @Description: 遇到怪兽变为小马里奥
* @receiver s
*/
func (s *SuperMarioStatus) MeetMonster() {
s.mario.status = &SmallMarioStatus{
mario: s.mario,
}
s.mario.score -= 200
}
/**
* @Description: 斗篷马里奥
*/
type CapeMarioStatus struct {
mario *Mario
}
/**
* @Description: 设置马里奥
* @receiver s
* @param mario
*/
func (c *CapeMarioStatus) SetMario(mario *Mario) {
c.mario = mario
}
func (c *CapeMarioStatus) Name() {
fmt.Println("斗篷马里奥")
}
/**
* @Description:获得蘑菇无变化
* @receiver c
*/
func (c *CapeMarioStatus) ObtainMushroom() {
}
/**
* @Description: 获得斗篷无变化
* @receiver c
*/
func (c *CapeMarioStatus) ObtainCape() {
}
/**
* @Description: 遇到怪兽变为小马里奥
* @receiver c
*/
func (c *CapeMarioStatus) MeetMonster() {
c.mario.status = &SmallMarioStatus{
mario: c.mario,
}
c.mario.score -= 200
}
func main() {
mario := Mario{
status: &SmallMarioStatus{},
score: 0,
}
mario.status.SetMario(&mario)
mario.status.Name()
fmt.Println("-------------------获得蘑菇\n")
mario.status.ObtainMushroom()
mario.status.Name()
fmt.Println("-------------------获得斗篷\n")
mario.status.ObtainCape()
mario.status.Name()
fmt.Println("-------------------遇到怪兽\n")
mario.status.MeetMonster()
mario.status.Name()
}
运行结果:
➜go run main.go
小马里奥
——————-获得蘑菇
超级马里奥
——————-获得斗篷
斗篷马里奥
——————-遇到怪兽
小马里奥
总结
仔细看上面的代码
- 对事件触发状态的转移及动作的执行的改动会很简单
- 可快速增加新的事件
- 增加新的状态也方便,只需添加新的状态类,少量修改已有代码
坏处就是类特别多,类里的函数也会特别多,即使这些函数根本无用。不过能获得更好的扩展性,还是值得的。
策略模式
通俗解释
跟不同类型的 MM 约会,要用不同的策略,有的请电影比较好,有的则去吃小吃效果不错,有的去海边浪漫最合适,单目的都是为了得到 MM 的芳心,我的追 MM 锦囊中有好多 Strategy 哦。策略模式:策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。
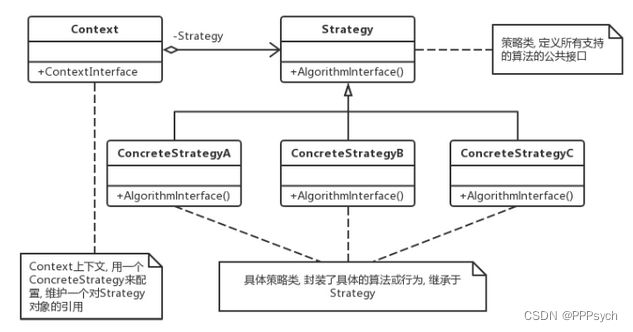
策略模式使得算法可以在不影响到客户端的情况下发生变化。策略模把行为和环境分开。环境类负责维持和查询行为类,各种算法在具体的策略类中提供。由于算法和环境独立开来,算法的增减,修改都不会影响到环境和客户端。
概念
策略模式(Strategy pattern)鼓励使用多种算法来解决一个问题,其杀手级特性是能够在运行时透明地切换算法(客户端代码对变化无感知)。因此,如果你有两种算法,并且知道其中一种对少量输入效果更好,另一种对大量输入效果更好,则可以使用策略模式在运行时基于输入数据决定使用哪种算法。
官方sort包就是使用了策略模式,sort 包含了插入排序、堆排序、快速排序和归并排序,对使用者来说不用关心 sort 使用了那种排序方法。
分析:
单看策略模式,主要利用多态性。但策略模式往往不单独使用,它会和工厂模式配合使用。此时策略模式便可解耦策略的定义、创建、使用。
策略模式加工厂模式,能够达到去除if-else和switch的效果,主要靠工厂模式加持,借助于“查表法”找到指定策略进行使用。
应用场景
策略模式的应用场景还是蛮广泛的,处理同一类问题如果有多种算法,就可以使用策略模式。如根据不同活动计算优惠价格、根据商品不同类型计算税率等。
最近有一个实际业务场景可以使用策略模式,计算跨境商品税费。
跨境商品的税费和两方面有关,一是商品是否含税,二是商品类型,不同类型对应税率不一样,如常规商品和酒类商品税率不一样、税的计算方式也不一样。
所以只要知道商品是否含税、商品类型就能找到对应的计算方案。如果我们使用if-else来写,会不优雅,因为商品类型比较多,而且计算逻辑也相对复杂,所以我们可以利用查表法进行优化。
税费计算接口被交易侧调用,交易调用的时候会传商品是否含税,商品类型由项目组自行维护。那我们来看一下具体实现。
实例演示
在保存文件的时候,由于政策或者其他的原因可能需要选择不同的存储方式,敏感数据我们需要加密存储,不敏感的数据我们可以直接明文保存。
代码实现:
package strategy
import (
"fmt"
"io/ioutil"
"os"
)
// StorageStrategy 存储策略
type StorageStrategy interface {
Save(name string, data []byte) error
}
var strategys = map[string]StorageStrategy{
"file": &fileStorage{},
"encrypt_file": &encryptFileStorage{},
}
// NewStorageStrategy NewStorageStrategy
func NewStorageStrategy(t string) (StorageStrategy, error) {
s, ok := strategys[t]
if !ok {
return nil, fmt.Errorf("not found StorageStrategy: %s", t)
}
return s, nil
}
// FileStorage 保存到文件
type fileStorage struct{}
// Save Save
func (s *fileStorage) Save(name string, data []byte) error {
return ioutil.WriteFile(name, data, os.ModeAppend)
}
// encryptFileStorage 加密保存到文件
type encryptFileStorage struct{}
// Save Save
func (s *encryptFileStorage) Save(name string, data []byte) error {
// 加密
data, err := encrypt(data)
if err != nil {
return err
}
return ioutil.WriteFile(name, data, os.ModeAppend)
}
func encrypt(data []byte) ([]byte, error) {
// 这里实现加密算法
return data, nil
}
单元测试:
package strategy
import (
"testing"
"github.com/stretchr/testify/assert"
)
func Test_demo(t *testing.T) {
// 假设这里获取数据,以及数据是否敏感
data, sensitive := getData()
strategyType := "file"
if sensitive {
strategyType = "encrypt_file"
}
storage, err := NewStorageStrategy(strategyType)
assert.NoError(t, err)
assert.NoError(t, storage.Save("./test.txt", data))
}
// getData 获取数据的方法
// 返回数据,以及数据是否敏感
func getData() ([]byte, bool) {
return []byte("test data"), false
}
总结
策略模式很好的体现了开闭原则,也说明即使是很小的优化设计,也能给项目开发带来巨大的便利。当然,这种便利会在维护的时候得到充分体现。
责任链模式
通俗解释
晚上去上英语课,为了好开溜坐到了最后一排,哇,前面坐了好几个漂亮的 MM 哎,找张纸条,写上 “Hi, 可以做我的女朋友吗?如果不愿意请向前传”,纸条就一个接一个的传上去了,糟糕,传到第一排的 MM 把纸条传给老师了,听说是个老处女呀,快跑!
责任链模式:在责任链模式中,很多对象由每一个对象对其下家的引用而接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。客户并不知道链上的哪一个对象最终处理这个请求,系统可以在不影响客户端的情况下动态的重新组织链和分配责任。处理者有两个选择:承担责任或者把责任推给下家。一个请求可以最终不被任何接收端对象所接受。
概念
责任链(Chain of Responsibility,也称职责链)模式的定义:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
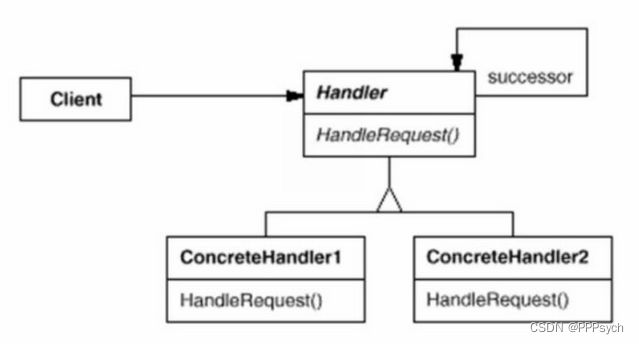
责任链模式的本质是解耦请求与处理,让请求在处理链中能进行传递与被处理;理解责任链模式应当理解其模式,而不是其具体实现。责任链模式的独到之处是将其节点处理者组合成了链式结构,并允许节点自身决定是否进行请求处理或转发,相当于让请求流动起来。
责任链模式主要包含以下角色:
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
分析:
责任链模式的定义已经将模式说的比较清楚了,一个请求需要被多个对象进行处理,可以将处理对象连成一条链,挨个处理请求。
连成链的方式比较多样,可以用示意图中展示的那样,一个处理对象使用SetSuccessor引用下一个处理对象。也可以使用array或者list存储所有处理对象,使用循环方式遍历。
对于第二种方式,是否感觉有些像观察者两者具体实现、目的都差不多,主要区别在观察者模式中的处理对象功能可能完全不相似,而且观察者模式主要负责将信息传递给处理对象即可。责任链模式的处理对象功能一般相似,另外责任链模式也关注请求是否正确被处理。
另外,定义里说”直到有一个对象处理它“也不太准确,有多少对象可以处理请求看具体需求,极端情况下每一个对象都可以处理请求。
责任链模式的核心在于将处理对象整理成链路。
应用场景
如果请求被多个对象进行处理,就可以用职责链模式。具体业务的像敏感词脱敏,框架中的过滤器、拦截器等。
总体感觉框架中使用的比较多一些,研发人员能够快速扩展出自己的过滤器和拦截器。
优点
- 降低了对象之间的耦合度。该模式使得一个对象无须知道到底是哪一个对象处理其请求以及链的结构,发送者和接收者也无须拥有对方的明确信息。
- 增强了系统的可扩展性。可以根据需要增加新的请求处理类,满足开闭原则。
- 增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态地改变链内的成员或者调动它们的次序,也可动态地新增或者删除责任。
- 责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
- 责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
缺点
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 责任链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
实例演示
我们仿照Gin,实现Gin的全局中间件功能。
代码实现:
package main
import "fmt"
var status int8 = 0
type HandlerFunc func()
type HandlersChain []HandlerFunc
/**
* @Description:
*/
type RouterGroup struct {
Handlers HandlersChain
index int8
}
/**
* @Description: 添加中间件,将其组成链式
* @receiver group
* @param middleware
*/
func (group *RouterGroup) Use(middleware ...HandlerFunc) {
group.Handlers = append(group.Handlers, middleware...)
}
/**
* @Description: 链顺序执行
* @receiver group
*/
func (group *RouterGroup) Next() {
for group.index < int8(len(group.Handlers)) {
group.Handlers[group.index]()
group.index++
}
}
/**
* @Description: 中间件
*/
func middleware1() {
fmt.Println("全局中间件1执行完毕")
}
/**
* @Description: 中间件
*/
func middleware2() {
fmt.Println("全局中间件2执行失败")
status = 1
}
func main() {
r := &RouterGroup{}
//添加中间件
r.Use(middleware1, middleware2)
//运行中间件
r.Next()
//状态检查
if status == 1 {
fmt.Println("中间件检查失败,请重试")
return
}
//执行后续流程
}
运行结果:
➜go run main.go
全局中间件1执行完毕
全局中间件2执行失败
中间件检查失败,请重试
这是一个简版的中间件执行过程,我将Gin中的Context和RouterGroup合并了。虽然比起真正的执行流程缺乏很多内容,但是核心操作是一致的。
总结
通过Gin中间件的例子,可以很好证明责任链的扩展性。简单使用Use增加自己创建的中间件,每一个请求都会被新增的中间件所处理。所以开发者可以方便的增加鉴权、限流、脱敏、拦截等操作。
访问者模式
通俗解释
情人节到了,要给每个 MM 送一束鲜花和一张卡片,可是每个 MM 送的花都要针对她个人的特点,每张卡片也要根据个人的特点来挑,我一个人哪搞得清楚,还是找花店老板和礼品店老板做一下 Visitor,让花店老板根据 MM 的特点选一束花,让礼品店老板也根据每个人特点选一张卡,这样就轻松多了
概念
访问者模式:访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。访问者模式适用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由的演化。访问者模式使得增加新的操作变的很容易,就是增加一个新的访问者类。
访问者模式将有关的行为集中到一个访问者对象中,而不是分散到一个个的节点类中。当使用访问者模式时,要将尽可能多的对象浏览逻辑放在访问者类中,而不是放到它的子类中。访问者模式可以跨过几个类的等级结构访问属于不同的等级结构的成员类。

分析
看完访问者模式定义和示意图,可能大家会想,这说的是人话吗?一开始我也是这么想的。但是把定义和示意图拆分后,就容易理解了。
定义分析
先看定义:表示一个作用于某对象结构中的各元素的操作。
对象结构中的各元素:就是指一个类和类里的各种成员变量,对应UML中的Element。
操作:就是指访问者,访问者有操作元素的能力。
所以这句话可以解释为:访问者模式,就是访问者可以操作类里的元素。
再看定义:它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
这句话主要讲访问者模式的优点:类在不做任何改动的情况下,能够增加新的操作/解析方式。如元素类是pdf资源文件类,以前只支持抽取文本内容操作,现在增加压缩、提取文件元信息操作,元素类无需感知。
示意图分析
定义没有解释访问者模式是如何实现的,这时候我们可以看示意图。
首先我们看Element,这个是元素类,属于被操作的对象。元素类有成员函数Accept,用于接收访问者。关于Element想提两点:
- 成员函数Accept中的入参vistor是接口或者是父类,不是子类
- Element可以有一个operator函数,ConcreteElementA和ConcreteElementB可实现该函数。
再来看Vistor,有两个成员函数,入参分别对应ConcreteElementA、ConcreteElementB,即Vistor提供了同一种功能,能够操作不同的Element。
通过UML分析,我们可以看出,Element和Vistor是你中有我,我中有你的关系。
应用场景
-
访问者模式把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由地演化,所以适用于数据结构相对稳定的操作。
-
对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作。
-
需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作”污染”这些对象的类,也不希望在增加新操作时修改这些类。
优点
访问者模式的优点是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。访问者模式将有关的行为集中到一个访问者对象中。(element尽量不改变,visitor容易增加)
缺点
使增加新的数据结构变得困难
实例演示
假设有三种文件类型,pdf、word、txt,需要对这三种文件做内容提取、压缩、获取文件元信息操作,我们应该如何设计。
我们肯定需要创建pdf、word、txt三个类,实现文件的读取。
然后我们实现内容提取、压缩、获取文件元信息三个类,每个类有三个函数,用来处理不同类型的文件。
现在已经将所有文件读取完毕,需要对文件分别进行内容提取、压缩、获取文件元信息。
我们可以这么实现:
func test() {
fileList := make([]int, 10)
fmt.Println("------提取文件")
for _, f := range fileList {
if "f是pdf" == "true" {
fmt.Println("调用pdf提取接口")
}else "f是txt" == "true" {
fmt.Println("调用txt提取接口")
}
}
fmt.Println("------压缩文件")
for _, f := range fileList {
if "f是pdf" == "true" {
fmt.Println("调用pdf压缩接口")
}else "f是txt" == "true" {
fmt.Println("调用txt压缩接口")
}
}
}
如果这样实现,当增加新文件类型或者新功能时,都要修改一堆if-else,不但不优雅,而且极易出问题。这时候就可以使用访问者模式:
package main
import "fmt"
/**
* @Description: 读文件接口,用于获取到文件
*/
type ReadFile interface {
Read(fileName string)
Accept(v VistorReadFile)
}
/**
* @Description: 读pdf文件类
*/
type ReadPdfFile struct {
}
/**
* @Description: 读取文件
* @receiver p
* @param fileName
*/
func (p *ReadPdfFile) Read(fileName string) {
fmt.Println("读取pdf文件" + fileName)
}
/**
* @Description: 接受访问者类
* @receiver p
* @param v
*/
func (p *ReadPdfFile) Accept(v VistorReadFile) {
v.VistorPdfFile(p)
}
/**
* @Description: 读取txt文件类
*/
type ReadTxtFile struct {
}
/**
* @Description: 读取文件
* @receiver t
* @param fileName
*/
func (t *ReadTxtFile) Read(fileName string) {
fmt.Println("读取txt文件" + fileName)
}
/**
* @Description: 接受访问者类
* @receiver p
* @param v
*/
func (t *ReadTxtFile) Accept(v VistorReadFile) {
v.VistorTxtFile(t)
}
/**
* @Description: 访问者,包含对pdf和txt的操作
*/
type VistorReadFile interface {
VistorPdfFile(p *ReadPdfFile)
VistorTxtFile(t *ReadTxtFile)
}
/**
* @Description: 提取文件类
*/
type ExactFile struct {
}
/**
* @Description: 提取pdf文件
* @receiver e
* @param p
*/
func (e *ExactFile) VistorPdfFile(p *ReadPdfFile) {
fmt.Println("提取pdf文件内容")
}
/**
* @Description: 提取txt文件
* @receiver e
* @param p
*/
func (e *ExactFile) VistorTxtFile(p *ReadTxtFile) {
fmt.Println("提取txt文件内容")
}
/**
* @Description: 压缩文件类
*/
type CompressionFile struct {
}
/**
* @Description: 压缩pdf文件
* @receiver c
* @param p
*/
func (c *CompressionFile) VistorPdfFile(p *ReadPdfFile) {
fmt.Println("压缩pdf文件内容")
}
/**
* @Description: 压缩txt文件
* @receiver c
* @param p
*/
func (c *CompressionFile) VistorTxtFile(p *ReadTxtFile) {
fmt.Println("压缩txt文件内容")
}
func main() {
filesList := []ReadFile{
&ReadPdfFile{},
&ReadTxtFile{},
&ReadPdfFile{},
&ReadTxtFile{},
}
//提取文件
fmt.Println("--------------------------提取文件")
extract := ExactFile{}
for _, f := range filesList {
f.Accept(&extract)
}
//压缩文件
fmt.Println("--------------------------压缩文件")
compress := CompressionFile{}
for _, f := range filesList {
f.Accept(&compress)
}
}
运行结果:
➜go run main.go
————————–提取文件
提取pdf文件内容
提取txt文件内容
提取pdf文件内容
提取txt文件内容
————————–压缩文件
压缩pdf文件内容
压缩txt文件内容
压缩pdf文件内容
压缩txt文件内容
这种写法,如果增加新的文件类型,main中代码无需改动,只需要vistor添加新的实现即可。如果增加新的功能,文件类也无需感知。
总结
访问者模式实现了对象和操作的解耦。可以认为访问者模式有两个维度,一是对象和操作解耦,这个比较容易理解,也符合单一职责原则。二是对象给操作开个大门,这个是否需要主要看业务的复杂度。