基于text2vec和faiss开发实现文档查询系统初体验
最近接触到了一些文本向量化的预训练模型,感觉相比较自己去基于gensim去训练词向量来说,使用预训练模型可能是更高效的方式了,正好有一个想法一直在想能够以什么样的形式间接的实现问答,说白了这里的问答跟我们理解的chatGPT类型的问答是不一样的,这里的考虑是想有一堆知识语料或者是文本文档数据,对于专业人士来说查询使用起来肯定是很简单的,但是对于一些刚从业或者是缺乏专业培训的人员来说是比较困难的,如何能高效地利用本地的知识语料数据来为我们产生对应的问答回答结果呢?或者说是让对应的问题产出更聚焦更准确呢?
这两天在查阅资料的时候结合自己最近两天的亲身实践有一个粗糙的方案,整体流程如下所示:
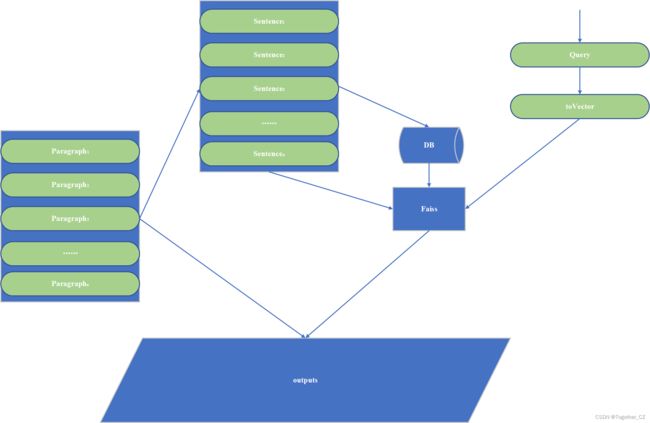
核心的思想就是想要基于text2vec模型提供文本句级或者是段落级别的向量化计算,之后将问答生成的任务转化为了文本相似度匹配任务,而原始的文本已经转化为了标准的向量,那么相似度匹配的任务又变成了向量查询检测任务,这个任务场景下faiss是比较好用的工具了。
faiss官方项目在这里,如下所示:
Faiss是一个用于高效相似性搜索和密集向量聚类的库。它包含在任何大小的向量集中搜索的算法,最多可以搜索可能不适合RAM的向量集。它还包含用于评估和参数调整的支持代码。Faiss是用C++编写的,带有完整的Python/numpy包装器。一些最有用的算法是在GPU上实现的。它主要由Meta的基础人工智能研究小组开发。
Faiss包含几种相似性搜索方法。它假设实例被表示为向量,并由整数标识,并且向量可以与L2(欧几里得)距离或点积进行比较。类似于查询向量的向量是与查询向量具有最低L2距离或最高点积的向量。它还支持余弦相似性,因为这是归一化向量上的点积。
一些方法,如基于二进制矢量和紧凑量化码的方法,仅使用矢量的压缩表示,不需要保留原始矢量。这通常是以不太精确的搜索为代价的,但这些方法可以在单个服务器的主存中扩展到数十亿个向量。其他方法,如HNSW和NSG,在原始向量上添加索引结构,以提高搜索效率。
GPU实现可以接受来自CPU或GPU存储器的输入。在具有GPU的服务器上,GPU索引可以用于替换CPU索引(例如,用GpuIndexFlatL2替换IndexFlatL2),并且自动处理到GPU存储器的拷贝/从GPU存储器的复制。然而,如果输入和输出都保持在GPU上,结果将更快。支持单GPU和多GPU使用。
想要进一步了解faiss详情的可以自行移步官方项目即可。
这里因为目前只是一个初步的粗糙想法,本文的主要目的就是想要去基于真实的实践去尝试这个流程的可行性,这里从网上找了一个文本对相似度计算的数据集,实例如下所示:
{"text1":"一个女人在跳舞。","text2":"这个男人在跳舞。","label":2}
{"text1":"你好,请问你这个借款有免息期吗","text2":"一次七天免息机会领取","label":1}
{"text1":"明年他成为左后卫和右截锋的先发球员。","text2":"第二年,他成为左后卫和右截锋的先发球员。","label":4}
{"text1":"同年,他被任命为密西西比州和伊利诺伊州教区魁北克地区的牧师将军。","text2":"同年,他被任命为密西西比州和伊利诺伊州教区魁北克地区的牧师。","label":4}
label":5}
{"text1": "埃摩森丨职场遇难题?找不到对象?做好这3步,人生就会像开了挂一样", "text2": "春节后开工已经一个星期了 各位小伙伴们还适应吗? 上班的时候,是不是一边摸鱼 一边还在回味放假的快乐? 再过几天又到周末了 如果一周能多休息半天,该有多好 近年来,多地区开始试行 4.5天弹性工作制 今后会在东莞推广吗? 人社部答复来了 ↓↓↓ 人社部明确回复:“四天半工作制” 不宜在企业中广泛推行 近日,人社部在回复全国人大代表的建议中 明确指出“4.5天弹性工作制” 不宜在企业中广泛推行 图源:人社局 进一步缩短工时标准尚不具备现实基础 不宜在企业中广泛推行 进一步缩短我国的法定工作时间标准 需要以经济发展、科技进步 和生产力水平的提高为基础 充分考虑我国社会经济发展水平和企业承受能力 图源:摄图网 在当前经济形势下 缩短工时会加大企业生产经营压力 带来较高的用人成本 和负担影响经济发展 图源:摄图网 人社部:现行工时制度符合现实 劳动者每年有120-130天休息休假 人社部指出,现行工时制度和标准 是综合考虑我国人口、就业、经济发展水平 和人民生活习惯等因素制定的 有利于实现劳动者身体健康权 休息权以及就业权之间的平衡 图源:摄图网 同时该标准符合国际劳工组织 1935年通过的《40小时工作周公约》 和1962年《缩短工时建议书》提出的 逐步缩短工作时间至每周40小时的要求 与多数经济发达国家或地区的工时水平基本一致 是一种比较先进和科学的劳动标准 图源:摄图网 此外,劳动者每年可依法享受: ▷11天法定节假日 ▷最长15天的带薪年休假 ▷每周2天休息日 图源:摄图网 每年固定的休息休假在120-130天 约占全年时间1/3 现行休息休假制度 已为职工探亲访友、消费休闲等 创造了较好的前提条件 图源:摄图网 弹性休假落地难,或成为特有福利 此前对于弹性休假 大家争议最多的是 “2.5天弹性休假” 究竟是福利,还是口号? 多出半天假,是否意味着延长法定工作时间? 能否落实、如何落实…… 图源:摄图网 此次,人社部尤其强调: 近年的相关调查显示 我国能够严格执行目前 工时标准的企业比例不高,加班情况较多 目前有的地方推行的2.5天假期 也可能成为行政机关、事业单位 工作人员的特有福利,社会影响也不好 图源:摄图网 消息一出,网友们纷纷表示 先把我们的双休落实好吧 ▽ 图源:微博 图源:南方都市报 还有脑洞大开的网友表示 各种办事处周六日应该上班 ▽ 图源:微博 一看就是我们东莞搞钱人 ▽ 图源:微博 凡尔赛大师也出现了 ▽ 图源:微博 网友:说多了都是泪 ▽ 图源:微博 实际上,“4.5天弹性工作制”并非新规 早在2015年8月,国务院办公厅就曾印发 《关于进一步促进旅游投资和消费的若干意见》 鼓励弹性作息 图源:摄图网 有条件的地方和单位可根据实际情况 依法优化调整夏季作息安排 为职工周五下午与周末结合 外出休闲度假创造有利条件 图源:摄图网 目前已有河北、江西、重庆、甘肃 辽宁、安徽、陕西、贵州、福建等 10多个省份出台了鼓励2.5天休假的意见 图源:人民日报 不管是过去还是现在 各地关于弹性休假的政策多为鼓励性文件 并非强制措施 因此此前2.5天为代表的弹性休假政策 是否能够真正落实颇受关注 如今人社部正式回复也算是尘埃落地了 图源:摄图网 各位搬砖人们还是安心打工吧 信息:摄图网、微博、人社局、人民日报、深圳全接触 编辑:全妹 如有侵权请联系删除", "label": 0}一共包含三个字段text1、text2和label,这个不同字段的含义猜一下就知道是什么意思了。
首先来加载本地的数据集,如下所示:
def loadData():
"""
加载数据集
"""
with open("data.jsonl",encoding="utf-8") as f:
data_list=[eval(one.strip()) for one in f.readlines() if one.strip()]
print("data_list_length: ", len(data_list))
return data_list接下来需要对原始的数据集进行解析计算,提取所需要的字段数据,如下所示:
def parseData(data_list):
"""
解析数据集
"""
result=[]
data_list=data_list[:1000]
for one_dict in data_list:
try:
text1=one_dict["text1"]
text2=one_dict["text2"]
label=one_dict["label"]
result+=[text1,text2]
except Exception as e:
print("Exception: ", e)
return result接下来是需要对整个语料数据集进行向量化计算处理,如下所示:
def toVector(sentences):
"""
向量化
"""
embeddings = model.encode(sentences)
print("embeddings_shape: ", embeddings.shape)
vector={}
embeddings=embeddings.tolist()
for i in range(len(sentences)):
one_sen=sentences[i]
one_vec=embeddings[i]
vector[one_sen]=one_vec
with open("vector.json","w",encoding="utf-8") as f:
f.write(json.dumps(vector))整体pipeline实现如下所示:
def main():
"""
主函数
"""
data_list=loadData()
sentences=parseData(data_list)
toVector(sentences)
到这里我们就得到了上图DB数据库的向量数据了。
接下来就可以基于faiss来实现向量的查询检索计算了,核心实现如下所示:
index = faiss.IndexFlatL2(dimision)
print("index.is_trained: ", index.is_trained)
index.add(vectors)
print("index.ntotal: ", index.ntotal)
query = np.array([vector[ind]])
distances, indexs = index.search(query, topK)
print("distances_shape: ", distances.shape)
print("indexs_shape: ", indexs.shape)
print("原始文本: ", text[ind])
print("indexs: ", indexs)
for one_ind in indexs.tolist():
for one in one_ind:
print(text[one])结果输出如下所示:




初步实践感觉结果还是可以的,另外检索计算的速度也是挺快的。
后续就考虑基于上述的流程来开发第一个demo项目。