Kubernetes(K8s) 基本概念
前言
随着容器以及微服务的普及,各个公司都在探索如何打造生产环境可用的、高效的容器调度平台,而 K8s 的出现使这种探索变得更简单。发展到如今,K8s 已经成为容器编排领域事实上的标准,并且大量的公司都已在生产中使用,比如谷歌、亚马逊、腾讯、京东和阿里等以及其他的中小公司都在进行大量的探索和实际,下面我们就来讲解 K8s,通过理论结合实践快速掌握 K8s 相关知识点。
什么是 K8s?
- K8s 是 Google 在 2014 年开源的一个容器集群管理系统,简称 K8S
- K8s 用于容器化应用程序的部署,扩展和管理,目标是让部署容器化应用简单高效
官方网站:http://www.kubernetes.io
官方文档:https://kubernetes.io/zh/docs/home
K8s 架构图
K8s 是一个完备的分布式系统支撑平台,具有完备的集群管理能力,K8s 将集群中的机器划分为一个 Master 节点和一群工作节点 Node,其中,在 Master 节点运行着集群管理相关的一组进程 kube-apiserver、kube-controller-manager 和 kube-scheduler,这些进程实现了整个集群的资源管理、Pod 调度、弹性伸缩、安全控制、系统监控和纠错等管理能力,并且都是全自动完成的。Node 作为集群中的工作节点,运行真正的应用程序,在 Node 上 K8s 管理的最小运行单元是 Pod。Node 上运行着 K8s 的 kubelet、kube-proxy 服务进程,这些服务进程负责 Pod 的创建、启动、监控、重启、销毁以及实现软件模式的负载均衡器。

Master 节点
- Etcd(数据库):是一个高可用的键值数据库,存储 K8s 的资源状态信息和网络信息,Etcd 中的数据变更是通过 API Server 进行的。
- API Server(资源操作入口):顾名思义是用来处理 API 操作的,是整个系统的对外接口,提供资源操作的唯一入口,供客户端和其他组件调用,提供了 K8s 各类资源对象(Pod、deployment、Service等)的增删改查,是整个系统的数据总线和数据中心,并提供认证、授权、访问控制、API 注册和发现等机制,并将操作对象持久化到 Etcd 中。
- API Server 工作原理图:

- API层:提供针对资源 CRUD 的和监控的接口和健康检查、日志、性能指标等运维相关接口;
- 访问控制层:当客户端访问 API 接口时,访问控制层负责对用户身份鉴权,验明用户身份,核准用户对 K8s 资源对象的访问权限,然后根据配置的各种资源访问许可逻辑(Admission Control),判断是否允许访问
- 注册表层:K8s 把所有资源对象都保存在注册表中,针对注册表中的各种资源对象定义了相关数据类型和创建、转换、编码的方法
- Etcd 数据库层:用于持久化存储 K8s 资源对象的 KV 数据库。Etcd 的 watch API 接口对于 API Server 来说至关重要,因为通过这个接口,API Server 创新性地设计了 List-Watch 这种高性能的资源对象实时同步机制,使 K8s 可以管理超大规模的集群,及时响应和快速处理集群中的各种事件
- Controller Manager(控制管理器):Controller Manager 在 pod 工作流中作用是管理和控制整个集群,主要对资源对象进行管理,当 Node 节点中运行的 Pod 对象或是 Node 自身发生故障时,Controller Manager 会及时发现并处理,以确保整个集群处于理想工作状态。
- Controller Manager 架构图

每个 Controller 通过 API Server 提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”,而 Controller Manager 是这些Controller 的核心管理者。
- Replication Controller:称为副本控制器,在 Pod 工作流中主要保证集群中 Replication Controller 所关联的 Pod 副本数始终保持在预期值,比如若发生节点故障的情况导致 Pod 被意外杀死,Replication Controller 会重新调度保证集群仍然运行指定副本数,另外还可通过调整 Replication Controller 中 spec.replicas 属性值来实现扩容或缩容
- Node Controller:kubelet 在启动时会通过 API Server 注册自身的节点信息,并定时向 API Server 汇报状态信息,API Server 接收到信息后将信息更新到 Etcd 中,包括节点健康状况、节点资源、节点名称、节点地址信息、操作版本、Docekr 版本、kubelet 版本等信,Node Controller 通过 API Server 实时获取 Node 的相关信息,实现管理和监控集群中的各个 Node 节点的相关控制功能
- Resource Quota Controller(资源配额管理):资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源,避免由于某些业务进程设计或实现上的缺陷导致整个系统运行紊乱甚至以为宕机,对整个集群平稳运行和稳定性都有非常重要的作用
- Namespace Controller:用户通过 API Server 可以创建新的 Namespace 并保存在 Etcd 中,Namespace Controller 定时通过 API Server 读取这些 Namespace 信息来操作 Namespace,比如 Namespace 被 API 标记为优雅删除,则将该 Namespace 状态设置为 Terminating 并保存到 Etcd 中。同时 Namespace Controller 删除该 Namespace 下的 ServiceAccount、RC、Pod 等资源对象
- Service Account Controller (服务账号控制器):主要在命名空间内管理 ServiceAccount,以保证名为 default 的 ServiceAccount 在每个命名空间中存在
- Token Controller(令牌控制器):作为 Controller Manager 的一部分,主要用作:监听 serviceAccount 的创建和删除动作以及监听 secret 的添加、删除动作
- Service Controller:Service Controller是属于 K8s 集群与外部的云平台之间的一个接口控制器。Service Controller 监听 Service 变化,如果是一个 LoadBalancer 类型的 Service,则确保外部的云平台上对该 Service 对应的 LoadBalancer 实例被相应地创建、删除及更新路由转发表
- Endpoints Controller:Endpoints 表示了一个 Service 对应的所有 Pod 副本的访问地址,而 endpoints controller 就是负责生成和维护所有 Endpoints 对象的控制器。负责监听 Service 和对应的 Pod 副本的变化,如果 Service 被删除,删除和该 Service 同名的 Endpoints 对象。如果新的 Service 被创建或者修改,根据该 Service 信息获得相关的 Pod 列表,然后创建或者更新 Service 对应的 Endpoints 对象。如果监测到 Pod 的事件,则更新它所对应的 Service 的 Endpoints 对象,每个 Node 上的 kube-proxy 进程获取每个 Service 的 Endpoints,实现 Service 的负载均衡。
- Scheduler(集群分发调度器):Scheduler 调度器是 K8s 的核心组件;用户或者控制器创建 Pod 之后,调度器通过 K8s 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。整个调度流程分为两个阶段:预选策略(Predicates)和优选策略(Priorities):
- 预选(Predicates):输入是所有节点,输出是满足预选条件的节点。Scheduler 根据预选策略过滤掉不满足策略的 Node。例如,如果某节点的资源不足或者不满足预选策略的条件如 “Node 的 label 必须与 Pod 的 Selector 一致”时则无法通过预选。
- 优选(Priorities):输入是预选阶段筛选出的节点,优选会根据优先策略为通过预选的 Nodes 进行打分排名,选择得分最高的 Node,最后 Scheduler 会将 Pod 调度到得分最高的 Node 上,例如,资源越富裕、负载越小的 Node 可能具有越高的排名。
- 通过一幅图简单介绍一下 Scheduler 的工作流程
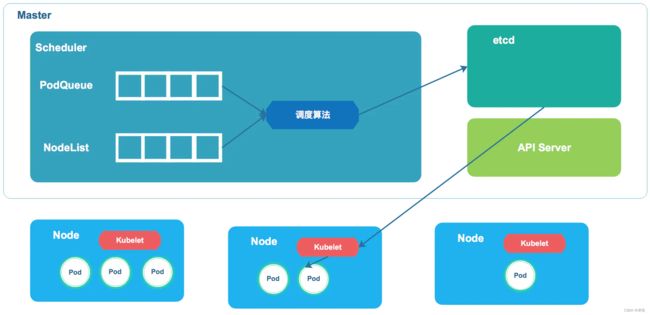
- Scheduler 监听到 Pod Queue 有新的 Pod 需要创建
- 通过检测 NodeList 以及相应的调度算法和策略绑定到集群中某个合适 Node 上,并将绑定信息保存到 Etcd 中
- Node 上的 kubelet 通过 API Server 监听到 K8s Scheduler 产生的 Pod 绑定事件,获取到对应的 Pod 清单,下载 image 镜像,启动容器
Node 节点
- kubelet(集群管理命令行工具集):每个 Node 节点上的 kubelet 定期就会调用 API Server 的 REST 接口报告自身状态,API Server 接收这些信息后,将节点状态信息更新到 Etcd 中,kubelet 也通过 API Server 监听 Pod 信息,从而对 Node 机器上的 Pod 进行管理,如创建、删除、更新 Pod。
- Proxy(负载均衡、路由转发):Proxy 提供网络代理和负载均衡,是实现 service 的通信与负载均衡机制的重要组件,kube-proxy 负责为 Pod 创建代理服务,从 API Server 获取所有 service 信息,并根据 service 信息创建代理服务,实现 service 到 Pod 的请求路由和转发,从而实现 K8s 层级的虚拟转发网络,将到 service 的请求转发到后端的 Pod 上。
Pod
1、上面的组件中一直在说 Pod,那么 Pod 到底是什么呢?
Pod 是 K8s 中能够创建和部署的最小单元,当指派容器时,容器实际上并不会指派到物理硬件上,容器会被分配到一个 Pod 里面。一个 Pod 代表着集群中运行的一 个进程,一个 Pod 封装一个容器(可以封装多个容器),Pod 里的容器共享存储、网络等。也就是说,应该把整个 Pod 看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
2、Pod 里面到底装的是什么?
在一些小公司里面,一个 Pod 就是一个完整的应用,里面安装着各种容器,一个 Pod 里面可能包含 Redis、MySQL、Tomcat 等等,当把这一个 Pod 部署以后就相当于部署了一个完整的应用,多个 Pod 部署完以后就形成了一个集群,这是 Pod 的第一种应用方式,还有一种使用方式就是在 Pod 里面只服务一种容器,比如在一个 Pod 里面我只部署 Redis,具体怎么部署 Pod 里面的容器,是按照我们项目的特性和资源的分配进行合理选择的Pod 结构图:
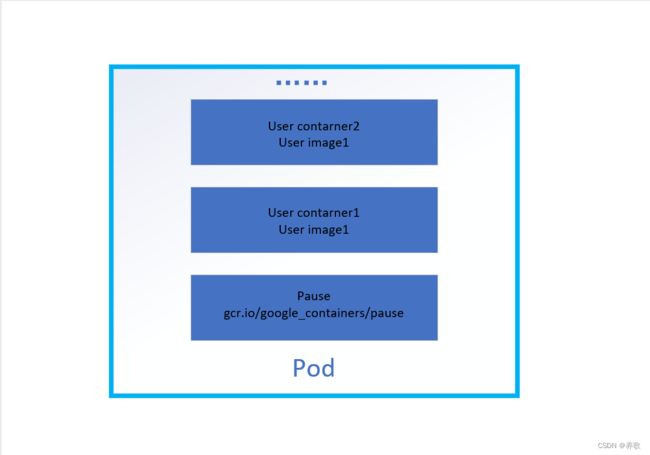
从上面的结构图可知,在每一个 Pod 中都有一个特殊的 Pause 容器和一个或多个业务容器,Pause 来源于 pause-amd64 镜像,Pause 容器在 Pod 中具有非常重要的作用:- Pause 容器作为 Pod 容器的根容器,其本地于业务容器无关,它的状态代表了整个 Pod 的状态。
- Pod 里的多个业务容器共享 Pause 容器的 IP,每个 Pod 被分配一个独立的 IP 地址,Pod 中的每个容器共享网络命名空间,包括 IP 地址和网络端口。Pod 内的容器可以使用 localhost 相互通信。K8s 支持底层网络集群内任意两个 Pod 之间进行通信。
- Pod 中的所有容器都可以访问共享 Volume,允许这些容器共享数据。Volume 也可以用来持久化 Pod 中的存储资源,以防容器重启后文件丢失。。
ReplicaSet
ReplicaSet 是 K8s 中的一种副本控制器,简称 RS,是新一代的 ReplicationController,K8s 中的 ReplicaSet 主要的作用是维持一组 Pod 副本的运行,它的主要作用就是保证一定数量的 Pod 能够在集群中正常运行,它会持续监听这些 Pod 的运行状态,在 Pod 发生故障重启数量减少时重新运行新的 Pod 副本。
官方推荐不要直接使用 ReplicaSet,用 Deployment 取而代之,Deployment 是比 ReplicaSet 更高级的概念,它会管理 ReplicaSet 并提供很多其它有用的特性,最重要的是 Deployment 支持声明式更新,声明式更新的好处是不会丢失历史变更。所以 Deployment 控制器不直接管理 Pod 对象,而是由 Deployment 管理 ReplicaSet,再由 ReplicaSet 负责管理 Pod 对象,如下图所示:

ReplicaSet 控制器主要由三个部分组成1、replicas(用户期望的 Pod 副本数):期望的 Pod 副本数,指定该 ReplicaSet 应该维持多少个 Pod 副本,默认为1
2、selector(标签选择器):选定哪些 Pod 是自己管理的,如果通过标签选择器选到的 Pod 副本数量少于我们指定的数量,需要用到下面的组件
3、template(Pod 资源模板):如果集群中现存的 Pod 数量不够我们定义的副本中期望的数量怎么办,需要新建 Pod ,这就需要 Pod 模板,新建的 Pod 是基于模板来创建的
Deployment
为了更好地解决服务编排的问题,K8s在V1.2版本开始,引入了 Deployment 控制器,值得一提的是,这种控制器并不直接管理 Pod,而是通过管理 ReplicaSet 来间接管理 Pod,即:Deployment 管理 ReplicaSet,ReplicaSet 管理 Pod。所以 Deployment 比 ReplicaSet 的功能更强大,可实现滚动升级和回滚应用、扩容和缩容和提供声明式配置。

那么举个例子,以升级版本为例:
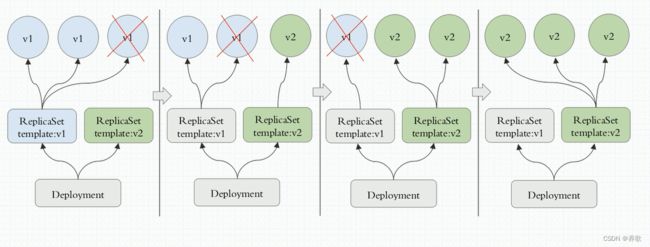
通过 Deployment 控制器来动态更新 Pod 版本,Deployment 下有众多 ReplicaSet ,但更改配置文件中的镜像版本,就会一个一个的删除 ReplicaSet v1 版本中的 Pod,自动新创建的 Pod 就会变成 v2 版本,当 Pod 全部变成 v2 版本后,ReplicaSet v1不会被删除,因为一旦发现 v2 版本有问题,还可以回退到 v1 版本,通常 Deployment 默认保留 10 个版本的 ReplicaSet 。Service
有这么一个问题,Pod 是应用程序的载体,我们可以通过 Pod 的 IP 来访问应用程序,ReplicaSet 定义了 Pod 的数量是 2,当一个 Pod 由于某种原因停止了,ReplicaSet 会新建一个 Pod,以确保运行中的 Pod 数量始终是 2。但每个 Pod 都有自己的 IP,前端请求不知道这个新 Pod 的 IP 是什么,那前端的请求如何发送到新的 Pod 中呢?
为了解决这个问题,K8s 提供了 Service,Service是 K8s 最重要的资源对象,Service 定义了一个服务的访问入口地址,前端的应用通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例,来自外部的访问请求被负载均衡到后端的各个容器应用上。Service 与其后端 Pod 副本集群之间则是通过 Label Selector 实现关联。简单来说前端请求不是直接发送给 Pod,而是发送到 Service,Service 再将请求转发给 Pod。
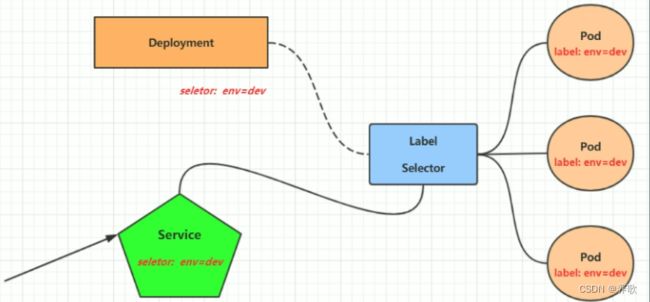
Service 在很多情况下只是一个概念,而真正将 Service 的作用实现的是 Kube-proxy 服务进程。Kube-proxy
在 K8s 集群中的每个 Node 上都会运行一个 Kube-proxy 服务进程,每个 Kube-proxy 都充当一个负载均衡器,这是一个分布式的负载均衡器,我们可以把这个进程看作是透明代理兼负载均衡器,核心功能就是将访问到某个 Service 的请求转发到该 Service 对应的真实后端 Pod 上。
目前 Kube-proxy 有三种工作模式:
1、userspace 模式
userspace 模式下,Kube-proxy 会为每一个 Service 创建一个监听端口,发向 Cluster IP 的请求被 Iptables 规则重定向到 Kube-proxy 监听的端口上,Kube-proxy 根据 LB 算法选择一个提供服务的 Pod 并和其建立连接,以将请求转发到 Pod 上。
该模式下,Kube-proxy 充当了一个四层负责均衡器的角色。由于 Kube-proxy 运行在 userspace 中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率比较低。
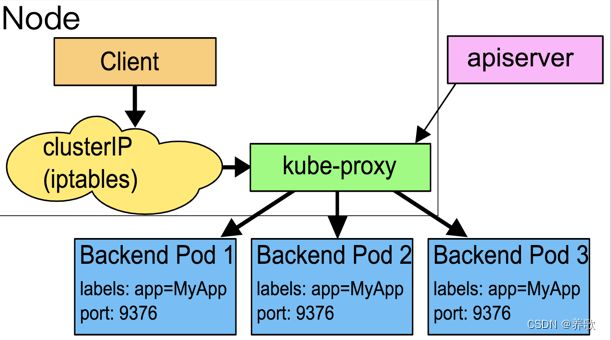
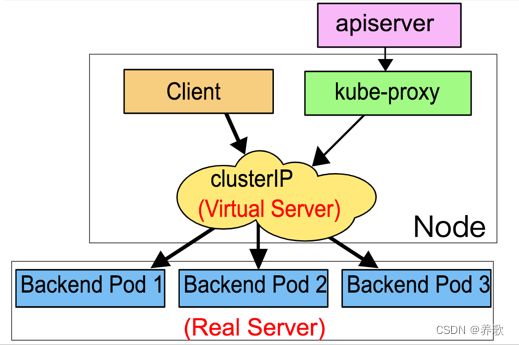
2、iptables 模式
为了避免增加内核和用户空间的数据拷贝操作,提高转发效率,Kube-proxy 提供了 iptables 模式。在该模式下,Kube-proxy 为 Service 后端的每个 Pod 创建对应的 iptables 规则,直接将发向 Cluster IP 的请求重定向到一个 Pod IP。该模式下 Kube-proxy 不承担四层代理的角色,只负责创建 iptables 规则。该模式的优点是较 userspace 模式效率更高,但不能提供灵活的 LB 策略,当后端 Pod 不可用时也无法进行重试。

3、ipvs 模式
该模式和 iptables 类似,Kube-proxy 监控 Pod 的变化并创建相应的 ipvs rules。ipvs 也是在 kernel 模式下通过 netfilter 实现的,但采用了 hash table 来存储规则,因此在规则较多的情况下,ipvs 相对 iptables 转发效率更高。除此以外,ipvs 支持更多的 LB 算法。如果要设置 Kube-proxy 为 ipvs 模式,必须在操作系统中安装 IPVS 内核模块。
那么 Service 和 Kube-Proxy 在 K8s 集群中的工作原理到底是怎么样的呢,以 iptables 模式为例:
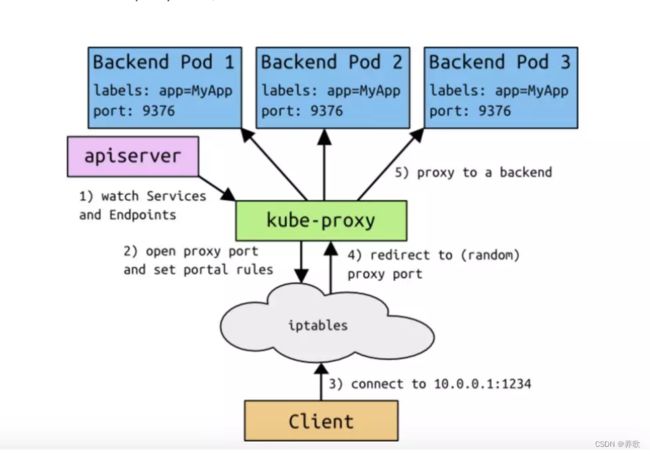
1、运行在每个 Node 节点的 Kube-Proxy 会实时的 watch Service 和 Endpoints 对象2、当用户在 K8s 集群中创建了含有 label 的 Service 之后,同时会在集群中创建出一个同名的 Endpoints 对象,用于存储该 Service 下的 Pod IP
3、每个运行在 Node 节点的 Kube-Proxy 感知到 Service 和 Endpoints 的变化之后,会在各自的 Node 节点设置相关的 iptables 转发规则,用于之后用户通过 Service 的 Cluster IP 去访问该 Service 下的服务
4、当 Kube-Proxy 把需要的规则设置完成后,用户就可以在集群内的 Node 或客户端 Pod 上通过 Cluster IP 经过该节点下的 iptales 设置的规则进行路由和转发后,直接将请求发送到真实的后端 Pod 中。
Service 类型暴露服务
在 K8s 中 Service 主要有 4 种不同的类型:
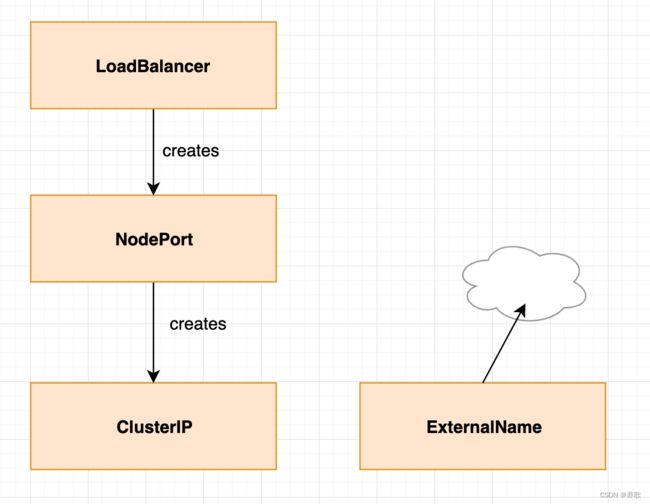
1、 Cluster IP
Cluster IP 是 Service 默认类型,每个 Node 分配一个集群内部的 IP,IP私有的 ,内部可以互相访问,外部无法访问集群内部。2、 Node Port
基于 Cluster IP,另外在每个 Node 上开放一个端口,将 Service 的 Port 映射到每个 Node 的一个指定内部 Port 上,映射的每个 Node 的内部 Port 都一样。将向该端口的流量导入到 Kube-proxy,然后由 Kube-proxy 进一步导给对应的 Pod。可以从所有的位置访问这个地址。
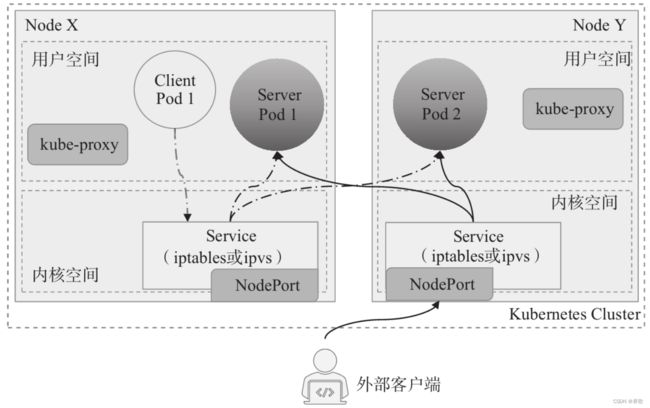
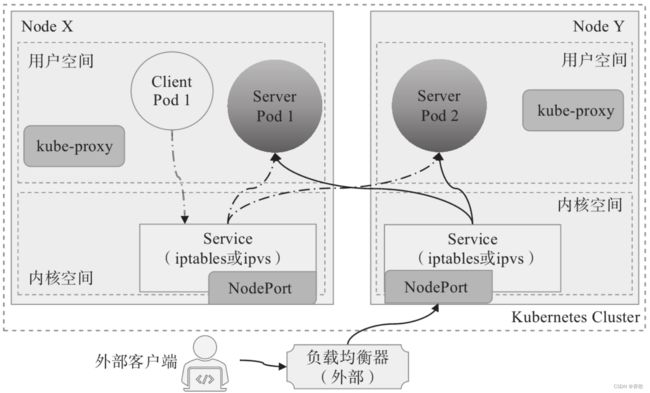
3、Load Balance
基于 Node Port,云服务商在外部创建了一个负载均衡层,会向 cloud provider 申请映射到 Service 本身的负载均衡,将流量导入到对应 Port,但是要收费。
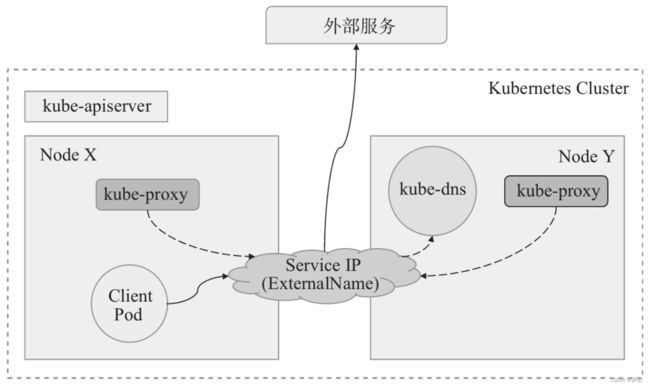
4、External Name
ExternalName 通过将 Service 映射至由 externalName 字段的内容指定的主机名来暴露服务,此主机名需要被 DNS 服务解析至 CNAME 类型的记录中。换言之,这种类型不是定义由 K8s 集群提供的服务,而是把集群外部的某服务以 DNS CNAME 记录的方式映射到集群内,从而让集群内的 Pod 资源能够访问外部服务的一种实现方式,如图所示。因此,这种类型的 Service 没有 Cluster IP 和 Node Port,没有标签选择器用于选择 Pod 资源,也不会有 Endpoints 存在。
例如你们公司的镜像仓库,最开始是用 IP 访问,等到后面域名下来了再使用域名访问。你不可能去修改每处的引用。但是可以创建一个 External Name,首先指向到 IP,等后面再指向到域名。所有需要访问仓库的地方,统一访问这个服务即可。最后
关于 K8s 相关组件的知识到此已讲解完,这只是根据我个人的理解所写,更加深入的大家可以自行去了解,基本上了解了个大概,下面我会根据所了解的搭建一个 K8s 集群环境 ,下一篇文章将会实现这个,大家可以参考操作一遍,加深对上面所说的理解。