ARM JDK上CMS一个极小概率发生的bug
编者按:笔者遇到一个非常典型 JVM 架构相关问题,在 x86 正常运行的应用,在 aarch64 环境上低概率偶现 JVM 崩溃。这是一个典型的 JVM 内部 bug 引发的问题。通过分析最终定位到 CMS 代码存在 bug,导致 JVM 在弱内存模型的平台上 Crash。在分析过程中,涉及到 CMS 垃圾回收原理、内存屏障、对象头、以及ParNew并行回收算法中多个线程竞争处理的相关技术。笔者发现并修复了该问题,并推送到上游社区中。毕昇 JDK 发布的所有版本均解决了该问题,其他 JDK 在 jdk8u292、jdk11.0.9、jdk13 以后的版本修复该问题。
bug 描述
目标进程在 aarch64 平台上运行,使用的 GC 算法为 CMS(-XX:+UseConcMarkSweepGC),会概率性地发生 JVM crash,且问题发生的概率极低。我们在 aarch64 平台上使用 fuzz 测试,运行目标进程 50w 次只出现过一次 crash(连续运行了 3 天)。
JBS issue:https://bugs.openjdk.java.net/browse/JDK-8248851
约束
- 我们对比了 x86 和 aarch64 架构,发现问题仅在 aarch64 环境下会出现。
- 文中引用的代码段取自 openjdk-8u262:http://hg.openjdk.java.net/jdk8u/jdk8u-dev/。
- 读者需要对 JVM 有基本的认知,如垃圾回收,对象布局,GC 线程等,且有一定的 C++ 基础。
背景知识
GC
GC(Garbage Collection)是 JVM 中必不可少的部分,用于回收不再会被使用到的对象,同时释放对象占用的内存空间。
垃圾回收对于释放的剩余空间有两种处理方式:
1. 一种是存活对象不移动,垃圾对象释放的空间用空闲链表(free_list)来管理,通常叫做标记-清除(Mark-Sweep)。创建新对象时根据对象大小从空闲链表中选取合适的内存块存放新对象,但这种方式有两个问题,一个是空间局部性不太好,还有一个是容易产生内存碎片化的问题。

2. 另一种对剩余空间的处理方式是 Copy GC,通过移动存活对象的方式,重新得到一个连续的空闲空间,创建新对象时总在这个连续的内存空间分配,直接使用碰撞指针方式分配(Bump-Pointer)。这里又分两种情况:
1)将存活对象复制到另一块内存(to-space,也叫 survival space),原内存块全部回收,这种方式叫撤离(Evacuation)。
2)将存活对象推向内存块的一侧,另一侧全部回收,这种方式也被称为标记-整理(Mark-Compact)。
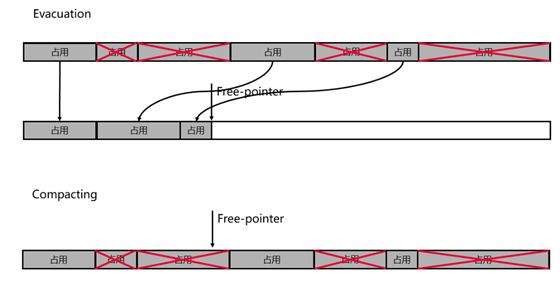
现代的垃圾回收算法基本都是分代回收的,因为大部分对象都是朝生夕死的,因此将新创建的对象放到一块内存区域,称为年轻代;将存活时间长的对象(由年轻代晋升)放入另一块内存区域,称为老年代。根据不同代,采用不同回收算法。
- 年轻代,一般采用 Evacuation 方式的回收算法,没有内存碎片问题,但会造成部分空间浪费。
- 老年代,采用 Mark-Sweep 或者 Mark-Compact 算法,节省空间,但效率低。
GC 算法是一个较大的课题,上述介绍只是给读者留下一个初步的印象,实际应用中会稍微复杂一些,本文不再展开。
CMS
CMS(Concurrent Mark Sweep)是一个以低时延为目标设计的 GC 算法,特点是 GC 的部分步骤可以和 mutator 线程(可理解为 Java 线程)同时进行,减少 STW(Stop-The-World)时间。年轻代使用 ParNewGC,是一种 Evacuation。老年代则采用 ConcMarkSweepGC,如同它的名字一样,采用 Mark-Sweep(默认行为)和 Mark-Compact(定期整理碎片)方式回收,它的具体行为可以通过参数控制,这里就不展开了,不是本文的重点研究对象。
CMS 是 openjdk 中实现较为复杂的 GC 算法,条件分支很多,阅读起来也比较困难。在高版本 JDK 中已经被更优秀和高效的 G1 和 ZGC 替代(CMS 在 JDK 13 之后版本中被移除)。
本文讨论的重点主要是年轻代的回收,也就是 ParNewGC 。
对象布局
在 Java 的世界中,万物皆对象。对象存储在内存中的方式,称为对象布局。

对象由对象头加字段组成,我们这里主要关注对象头。对象头包括markOop和_matadata。前者存放对象的标志信息,后者存放 Klass 指针。所谓 Klass,可以简单理解为这个对象属于哪个 Java 类,例如:String str = new String(); 对象 str 的 Klass 指针对应的 Java 类就是 Ljava/lang/String。
- markOop 的信息很关键,它的定义如下[1]:
1. // 32 bits:
2. // --------
3. // hash:25 ------------》| age:4 biased_lock:1 lock:2 (normal object)
4. // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
5. // size:32 ------------------------------------------》| (CMS free block)
6. // PromotedObject*:29 ----------》| promo_bits:3 -----》| (CMS promoted object)
7. //
8. // 64 bits:
9. // --------
10. // unused:25 hash:31 --》| unused:1 age:4 biased_lock:1 lock:2 (normal object)
11. // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
12. // PromotedObject*:61 ---------------------》| promo_bits:3 -----》| (CMS promoted object)
13. // size:64 -----------------------------------------------------》| (CMS free block)
14. //
15. // unused:25 hash:31 --》| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
16. // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
17. // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 -----》| (COOPs && CMS promoted object)
18. // unused:21 size:35 --》| cms_free:1 unused:7 ------------------》| (COOPs && CMS free block)
对于一般的 Java 对象来说,markOop 的定义如下(以 64 位举例):
- 低两位表示对象的锁标志:00-轻量锁,10-重量锁,11-可回收对象, 01-表示无锁。
- 第三位表示偏向锁标志:0-表示无锁,1-表示偏向锁,注意当偏向锁标志生效时,低两位是 01-无锁。即 ----》|101 表示这个对象存在偏向锁,高 54 位存放偏向的 Java 线程。
- 第 4-7 位表示对象年龄:一共 4 位,所以对象的年龄最大是 15。
CMS 算法还会用到 markOop,用来判断一个内存块是否为 freeChunk,详细的用法见下文分析。
_metadata 的定义如下:
1. class oopDesc {
2. friend class VMStructs;
3. private:
4. volatile markOop _mark;
5. union _metadata {
6. Klass* _klass;
7. narrowKlass _compressed_klass;
8. } _metadata;
9. _// 。.._10. }_metadata 是一个 union,不启用压缩指针时直接存放 Klass 指针,启用压缩指针后,将 Klass 指针压缩后存入低 32 位。高 32 位留作它用。至于为什么要启用压缩指针,理由也很简单,因为每个引用类型的对象都要有 Klass 指针,启用压缩指针的话,每个对象都可以节省 4 个 byte,虽然看起来很小,但实际上却可以减少 GC 发生的频率。而压缩的算法也很简单,base + _narrow_klass 《《 offset 。base 和 offset 在 JVM 启动时会根据运行环境初始化好。offset 常见的取值为 0 或者 3(8 字节对齐)。
memory barrier
内存屏障(Memory barrier)是多核计算机为了提高性能,同时又要保证程序正确性,必不可少的一个设计。简单来说是为了防止因为系统优化,或者指令调度等因素导致的指令乱序。
所以多核处理器大都提供了内存屏障指令,C++ 也提供了关于内存屏障的标准接口,参考 memory order 。
总的来说分为 full-barrier 和 one-way-barrier。
full barrier 保证在内存屏障之前的读写操作的真正完成之后,才能执行屏障之后的读写指令。
one-way-barrier 分为 read-barrier 和 write-barrier。以 read-barrier 为例,表示屏障之后的读写操作不能乱序到屏障之前,但是屏障指令之前的读写可以乱序到屏障之后。
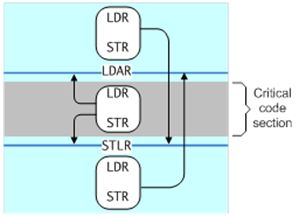
openjdk 中的 barrier 定义[3]
1. class OrderAccess : AllStatic {
2. public:
3. static void loadload();
4. static void storestore();
5. static void loadstore();
6. static void storeload();
8. static void acquire();
9. static void release();
10. static void fence();
11. _// 。.._12. static jbyte load_acquire(volatile jbyte* p);
13. _// 。.._14. static void release_store(volatile jint* p, jint v);
15. _// 。.._16. private:
17. _// This is a helper that invokes the StubRoutines::fence_entry()_18. _// routine if it exists, It should only be used by platforms that_19. _// don‘t another way to do the inline eassembly._20. static void StubRoutines_fence();
21. };其中 acquire()和 release() 是 one-way-barrier, fence() 是 full-barrier。不同架构依照这个接口,实现对应架构的 barrier 指令。
问题分析
在问题没有复现之前,我们能拿到的信息只有一个名为 hs_err_$pid.log 的文件,JVM 在发生 crash 时,会自动生成这个文件,里面包含 crash 时刻 JVM 的详细信息。但即便如此,分析这个问题还是有相当大的困难。因为没有 core 文件,无法查看内存中的信息。好在我们在一台测试环境上成功复现了问题,为最终解决这个问题奠定了基础。
第一现场
首先我们来看下 crash 的第一现场。
- backtrace

通过调用栈我们可以看出发生 core 的位置是在 CompactibleFreeListSpace::block_size 这个函数,至于这个函数具体是干什么的,我们待会再分析。从调用栈中我们还可以看到,这是一个 ParNew 的 GC 线程。上文提到 CMS 年轻代使用 ParNewGC 作为垃圾回收器。这里 Par 指的是 Parallel(并行)的意思,即多个线程进行回收。
- pc

pc 值是 0x0000ffffb2f320e8,相对这段 Instruction 开始位置 0x0000ffffb2f320c8 偏移为 0x20,将这段 Instructions 用反汇编工具得到如下指令:

根据相对偏移,我们可以计算出发生 core 的指令为 02 08 40 B9 ldr w2, [x0, #8],然后从寄存器列表,可以看出 x0(上图中的 R0)寄存器的值为 0x54b7af4c0,这个值看起来不像是一个合法的地址。所以我们接下来看看堆的地址范围。
- heap
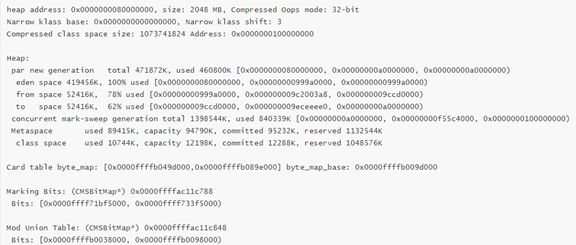
从堆的分布可以看出 0x54b7af4c0 肯定不在堆空间内,到这里可以怀疑大概率是访问了非法地址导致 crash,为了更进一步确认这个猜想,我们要结合源码和汇编,来确认这条指令的目的。
首先我们看看汇编
下图这段汇编是由 objdump 导出 libjvm.so 得到,对应 block_size 函数一小部分:
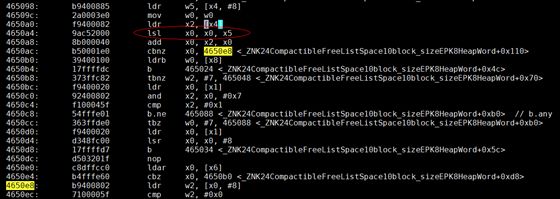
图中标黄的部分就是 crash 发生的地址,这个地址在 hs_err_pid.log 文件中也有体现,程序运行时应该是由 0x4650ac 这个位置经过 cbnz 指令跳转过来的。而图中标红的这条指令是一条逻辑左移指令,结合 x5 寄存器的值是 3,我首先联想到 x0 寄存器的值应当是一个 Klass 指针。因为在 64 位机器上,默认会开启压缩指针,而 hs_err_$pid.log 文件中的 narrowklass 偏移刚好是 3(heap 中的 Narrow klass shift: 3)。到这里,如果不熟悉 Klass 指针是什么,可以回顾下背景知识中的对象布局。
如果 x0 寄存器存放的是 Klass 指针,那么 ldr w2, [x0, #8] 目的就是获取对象的大小,至于为什么,我们结合源码来分析。
源码分析
CompactibleFreeListSpace::block_size 源码[4]:
1.size_t CompactibleFreeListSpace::block_size(const HeapWord* p) const {
2.NOT_PRODUCT(verify_objects_initialized());
3.// This must be volatile, or else there is a danger that the compiler_4.// will compile the code below into a sometimes-infinite loop, by keeping_5. // the value read the first time in a register._6. while (true) {
7.// We must do this until we get a consistent view of the object._8. if (FreeChunk::indicatesFreeChunk(p)) {
9. volatile FreeChunk* fc = (volatile FreeChunk*)p;
10.size_t res = fc-》size();
11.
12.// Bugfix for systems with weak memory model (PPC64/IA64)。 The_13.// block’s free bit was set and we have read the size of the_14.// block. Acquire and check the free bit again. If the block is_15.// still free, the read size is correct._16.OrderAccess::acquire();
17.
18.// If the object is still a free chunk, return the size, else it_19.// has been allocated so try again._20.if (FreeChunk::indicatesFreeChunk(p)) {
21.assert(res != 0, “Block size should not be 0”);
22.return res;
23.}
24.} else {
25.// must read from what ‘p’ points to in each loop._26.Klass* k = ((volatile oopDesc*)p)-》klass_or_null();
27.if (k != NULL) {
28.assert(k-》is_klass(), “Should really be klass oop.”);
29.oop o = (oop)p;
30.assert(o-》is_oop(true _/* ignore mark word */_), “Should be an oop.”);
31.
32.// Bugfix for systems with weak memory model (PPC64/IA64)._33.// The object o may be an array. Acquire to make sure that the array_34.// size (third word) is consistent._35.OrderAccess::acquire();
36.
37.size_t res = o-》size_given_klass(k);
38.res = adjustObjectSize(res);
39.assert(res != 0, “Block size should not be 0”);
40.return res;
41.}
42.}
43.}
44.}
这个函数的功能我们先放到一边,首先发现 else 分支中有关于 Klass 的判空操作,且仅有这一处,这和反汇编之后的 cbnz 指令对应。如果 k 不等于 NULL,则会马上调用 size_given_klass(k) 这个函数[5],而这个函数第一步就是取 klass 偏移 8 个字节的内容。和 ldr w2, [x0, #8]对应。
1. inline int oopDesc::size_given_klass(Klass* klass) {
2. int lh = klass-》layout_helper();
3. int s;
4. _// 。.._5. }
通过 gdb 查看 Klass 的 fields offset,_layout_helper 的偏移刚好是 8 。
klass-》layout_helper();这个函数就是取 Klass 的 _layout_helper 字段,这个字段在解析 class 文件时,会自动计算,如果为正,其值为对象的大小。如果为负,表示这个对象是数组,通过设置 bit 的方式来描述这个数组的信息。但无论怎样,这个进程都是在获取 layouthelper 时发生了 crash。
到这里,程序 core 在这个位置应该是显而易见的了,但是为什么 klass 会读到一个非法值呢?仅凭现有的信息,实在难以继续分析。幸运的是,我们通过 fuzz 测试,成功复现了这个问题,虽然复现概率极低,但是拿到了 coredump 文件。
debug
问题复现后,第一步要做的就是验证之前的分析结论:

上述标号对应指令含义如下:
- narrow_klass 的值最初放在 x6 寄存器中,通过 load 指令加载到 x0 寄存器
- 压缩指针解压缩
- 判断解压缩后的 klass 指针是否为 NULL
- 获取 Klass 的 layouthelper
查看上述指令相关的寄存器:

- 寄存器 x0 的值为 0x5b79f1c80
- 寄存器 x0 的值是一个非法地址
- 查看 narrow_klass 的 offset
- 查看 narrow_klass 的 base
- narrow_klass 解压缩,得到的结果是 0x100000200 和 x0 的值对应不上???
- 查看这个对象是什么类型,发现是一个 char 类型的数组。
通过以上调试基本信息,可以确认我们的猜想正确 ,但是问题是我们解压缩后得到的 Klass 指针是正确的,也能解析出 C,这是一个有效的 Klass。
但是 x0 中的值确实一个非法值。也就是说,内存中存放的 Klass 指针是正确的,但是 CPU 看见的 x0,也就是存放 Klass 指针的寄存器值是错误的。为什么会造成这种不一致呢,可能的原因是,这个地址刚被其他线程改写,而当前线程获取到的是写入之前的值,这在多线程环境下是非常有可能发生的,但是如果程序写的正确,且加入了正确的 memory barrier,也是不会有问题的,但现在出了问题,只能说明是程序没有插入适当的 memory barrier,或者插入得不正确。到这里,我们可以知道这个问题和内存序有关,但具体是什么原因导致这个地方读取错误,还要结合 GC 算法的逻辑进行分析。
ParNewTask
结合上文的调用栈,这个线程是在做根扫描,根扫描的意思是查找活跃对象的根,然后根据这个根集合,查找出根引用的对象的集合,进而找到所有活跃对象。因为 ParNew 是年轻代的垃圾回收器,要识别出整个年轻代的所有活跃对象。有一种可能的情况是根引用一个老年代对象 ,同时这个老年代对象又引用了年轻代的对象,那么这个年轻代的对象也应该被识别为活对象。
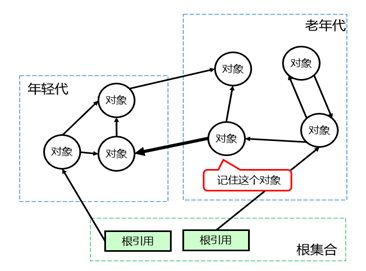
所以我们需要考虑上述情况,但是没有必要扫描整个老年代的对象,这样太影响效率了,所以会有一个表记录老年代的哪些对象有引用到年轻代的对象。在 JVM 中有一个叫 Card Table的数据结构,专门干这个事情。
Card table
关于 Card table 的实现细节,本文不做展开,只是简单介绍下实现思路。有兴趣的读者可以参考网上其他关于 Card table 的文章。也可以根据本文的调用栈,去跟一下源码中的实现细节。
简单来说就是使用 1 byte 的空间记录一段连续的 512 byte 内存空间中老年代的对象引用关系是否发生变化。如果有,则将这个 card 标记置为 dirty,这样做根扫描的时候,只关注这些 dirty card 即可。当找到一个 dirty card 之后,需要对整个 card 做扫描,这个时候,就需要计算 dirty card 中的一块内存的大小。回忆下 CMS 老年代分配算法,是采用的 freelist。也就是说,一块连续的 dirty card,并不都是一个对象一个对象排布好的。中间有可能会产生缝隙,这些缝隙也需要计算大小。调用栈中的 process_stride 函数就是用来扫描一个 dirtyCard 的,而最顶层的 block_size 就是计算这个 dirtyCard 中某个内存块大小的。
FreeChunk::indicatesFreeChunk(p) 是用来判断块 p 是不是一个 freeChunk,就是这块内存是空的,加在 free_list 里的。如果不是一个 freeChunk,那么继续判断是不是一个对象,如果是一个对象,计算对象的大小,直到整个 card 遍历完。
晋升
从上文中 gdb 的调试信息不难看出这个对象的地址为 0xc93e2a18(klass 地址 0xc93e2a20 -8),结合 heap 信息,这个对象位于老年代。如果是一个正常的老年代对象,在上一次 GC 完成之后,对象是不会移动的,那么作为对象头的 markOop 和 Klass 是大概率不会出现寄存器和内存值不一致的情况,因为这离现场太远了。那么更加可能的情况是什么呢?答案就是晋升。
熟悉 GC 的朋友们肯定知道这个概念,这里我再简单介绍下。所谓晋升就是发生 Evacuation 时,如果对象的年龄超过了阈值,那么认为这个对象是一个长期存活的对象,将它 copy 到老年代,而不是 survival space。还有一种情况是 survival space 空间已经不足了,这时如果还有活的对象没有 copy,那么也需要晋升到老年代。不管是那种情况,发生晋升和做根扫描这两个线程是可以同时发生的,因为都是 ParNewTask。
到这里,问题的重点怀疑对象,放在了对象晋升和根扫描两个线程之间没有做好同步,从而导致根扫描时读到错误的 Klass 指针。
所以简单看下晋升实现[6]。
1. ConcurrentMarkSweepGeneration::par_promote {
2. HeapWord* obj_ptr = ps-》lab.alloc(alloc_sz);
3. |---》 CFLS_LAB::alloc
4. |---》FreeChunk::markNotFree
5. oop obj = oop(obj_ptr);
6. OrderAccess::storestore();
7. obj-》set_mark(m);
8. OrderAccess::storestore();
9. _// Finally, install the klass pointer (this should be volatile)._10. OrderAccess::storestore();
11. obj-》set_klass(old-》klass());
12. 。..。..
13. void markNotFree() {
14. _// Set _prev (klass) to null before (if) clearing the mark word below_15. _prev = NULL;
16. _#ifdef _LP64_
17. if (UseCompressedOops) {
18. OrderAccess::storestore();
19. set_mark(markOopDesc::prototype());
20. }
21. _#endif_
22. assert(!is_free(), “Error”);
23. }看到这个地方,隔三岔五的一个 OrderAccess::storestore(); 我感觉到我离真相不远了,这里已经插了这么多 memory barrier 了,难道之前经常出过问题吗?但是已经插了这么多了,难道还有问题吗?哈哈哈…
看下代码逻辑,首先从 freelist 中分配一块内存,并将其初始化为一个新的对象 oop,这里需要注意的一个地方是 markNotFree 这个函数,将 prev(转换成 oop 是对象的 Klass)设置为 NULL,然后将需要 copy 的对象的 markOop赋值给这个新对象,再然后 copy 对象体,最后再将需要 copy 对象的 Klass 赋值给新对象。这中间的几次赋值都插入了 OrderAccess::storestore()。回忆下背景知识中的 memory barrier ,OrderAccess::storestore() 的含义是,storestore 之前的写操作,一定比 storestore 之后的写操作先完成。换句话说,其他线程当看到 storestore 之后写操作时,那么它观察到的 storestore 之前的写操作必定能完成。
根因
通过上面的介绍,相信大家理解了 block_size 的功能,以及 par_promote 的写入顺序。那么这两个函数,或者说执行这两个函数的线程是如何造成 block_size 函数看见的 klass 不一致(CPU 和内存不一致)的呢?请看下面的伪代码:
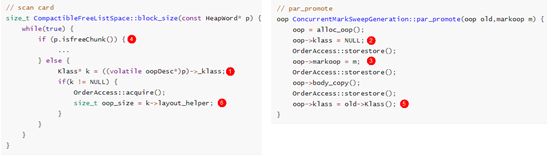
- scan card 线程先读 klass,此时读到取到的 klass 是一个非法地址;
- par_promote 线程设置 klass 为 NULL;
- par_promote 设置 markoop,判断一块内存是不是一个 freeChunk,就是 markoop 的第 8 位判断的(回忆背景知识);
- scan card 线程根据 markoop 判断该内存块是一个对象,进入 else 分支;
- par_promote 线程此时将正确的 klass 值写入内存;
- scan card 线程发现 klass 不是 NULL,访问 klass 的 _layout_helper,出现非法地址访问,发生 coredump。
到这里,所有的现象都可以解释通了,但是线程真正执行的时候,会发生上述情况吗?答案是会发生的。
- 我们先看 scan card 线程
① 中 isfreeChunk 会读 p(对应 par_promote 的 oop)的 markoop,④ 会读 p 的 klass,这两者的读写顺序,按照程序员的正常思维,一定是先读 markoop,再读 klass,但是 CPU 运行时,为了提高效率,会一次性取多条指令,还可能进行指令重排,使流水线吞吐量更高。所以 klass 是完全有可能在 markoop 之前就被读取。那么我们实际的期望是先读 markoop,再读 klass。那么怎样确保呢?
- 接下来看下 par_promote 线程
根据之前堆 storestore 的解释,③ 写入 markoop 之后,scan_card 线程必定能观察到 klass 赋值为 NULL,但也有可能直接观察到 ⑤ klass 设置了正确的值。
- 我们再看下 scan card 线程
试想以下,如果 markoop 比 klass 先读,那么在 ① 读到的 klass,要么是 NULL,要么是正确的 Klass,如果读到是 NULL,则会在 while(true)内循环,再次读取,直到读到正确的 klass。那么如果反过来 klass 比 markoop 先读,就有可能产生上述标号顺序的逻辑,造成错误。
综上,我们只要确保 scan_card 线程中 markoop 比 klass 先读,就能确保这段代码逻辑无懈可击。所以修复方案也自然而然想到,在 ① 和 ④ 之间插入 load 的 memory barrier,即加入一条 OrderAccess::loadload()。
详细的修复 patch 见 https://hg.openjdk.java.net/jdk-updates/jdk11u/rev/ae52898b6f0d 。目前已经 backport 到 jdk8u292,以及 JDK 13。
x86 ?
至于这个问题为什么在 x86 上不会出现,这是因为 x86 的内存模型是 TSO(Total Store Ordering)的,他不允许读读乱序,从架构层面避免了这个问题。而 aarch64 内存模型是松散模型(Relaxed),读和写可以任意乱序,这个问题也随之暴露。关于这两种内存模型,Relaxed 的模型理论上肯定是更有性能优势的,但是对程序员的要求也更大。TSO 模型虽然只允许写后读提前,但是在大多数情况下,能够确保程序顺序和执行顺序保持一致。
总结
这是一个极小概率发生的 bug,因此隐藏的很深。解这个 bug 也耗费了很长时间,虽然最后修复方案就是一行代码,但涉及的知识面还是比较广的。其中 memory barrier 是一个有点绕的概念,GC 算法的细节也需要理解到位。如果读者第一次接触 JVM,希望有耐心看下去,反复推敲,相信你一定会有所收获。