Flink 使用 SQL 读取 Kafka 写入到Doris表中
Apache Doris 代码仓库地址:apache/incubator-doris 欢迎大家关注加星
这次我们演示的是整合Flink Doris Connector 到 Flink 里使用,通过Flink Kafka Connector,通过SQL的方式流式实时消费Kafka数据,利用Doris Flink Connector将数据插入到Doris表中。
这里的演示我们是用过Flink SQL Client来进行的,
1. 准备条件
这里我们使用的环境是
- Doris-0.14.7
- doris-flink-1.0-SNAPSHOT.jar,这个可以自己去编译
- Flink-1.12.5
- flink-connector-kafka_2.11-1.12.1.jar
- kafka-clients-2.2.2.jar
- kafka-2.2.2
2. Kafka数据准备
- 首先我们在kafka下创建一个topic:
bin/kafka-topics.sh --create --topic user_behavior --replication-factor 1 --partitions 1 --zookeeper 10.220.147.155:2181,10.220.147.156:2181,10.220.147.157:2181
-
向user_behavior topic队列中添加数据
bin/kafka-console-producer.sh --broker-list 10.220.147.155:9092,10.220.147.156:9092,10.220.147.157:9092 --topic user_behavior示例数据如下:
{"user_id": "54346222", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"} {"user_id": "662863337", "item_id":"2244074", "category_id": "1575622", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}这里是演示,你可以将这个示例数据中的数据进行复制修改
3. doris 数据库建表
这里我们采用的是唯一主键模型
CREATE TABLE user_log (
user_id VARCHAR(20),
item_id VARCHAR(30),
category_id VARCHAR(30),
behavior VARCHAR(30),
ts varchar(20)
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "V2"
);
4.实战演示
4.1 Flink 安装部署
这里我们使用的是单机模式
因为Doris Flink Connector 要求Scala 2.12.x版本,这里我们下载是Flink 适配 scala 2.12的版本
下载Flink : https://dlcdn.apache.org/flink/flink-1.12.5/flink-1.12.5-bin-scala_2.12.tgz
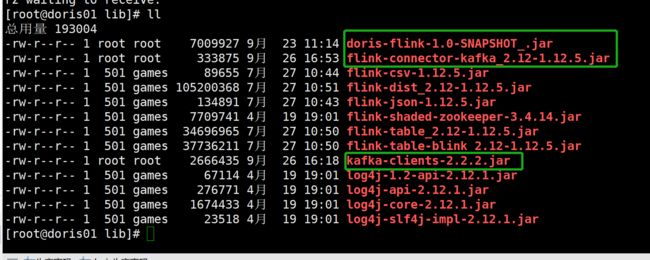
解压Flink到指定目录,然后将下面依赖的 JAR 包拷贝到 Flink lib 目录下:
- doris-flink-1.0-SNAPSHOT.jar
- flink-connector-kafka_2.12-1.12.1.jar
- kafka-clients-2.2.2.jar
4.2 启动Flink
bin/start-cluster.sh
启动以后我们在浏览器里访问:http://IP:8081 可以看到Flink的界面
4.3 启动 Flink SQL Client
./bin/sql-client.sh embedded
-
首先我们通过Flink SQL 创建Kafka表
CREATE TABLE user_log ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts varchar ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.startup-mode' = 'earliest-offset', 'connector.properties.0.key' = 'zookeeper.connect', 'connector.properties.0.value' = '10.220.147.155:2181,10.220.147.156:2181,10.220.147.157:2181', 'connector.properties.1.key' = 'bootstrap.servers', 'connector.properties.1.value' = '10.220.147.155:9092,10.220.147.156:9092,10.220.147.157:9092', 'update-mode' = 'append', 'format.type' = 'json', 'format.derive-schema' = 'true' );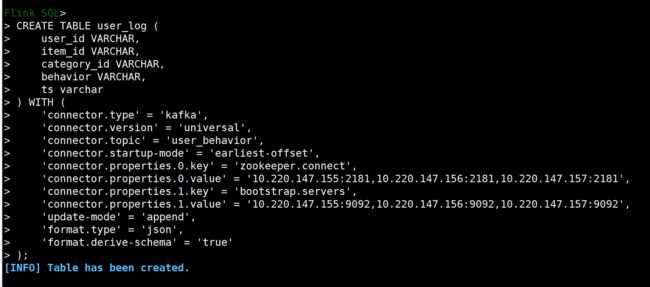
执行查询验证是否正常
select * from user_log;执行以后我们可以看到下面的界面,显示正常
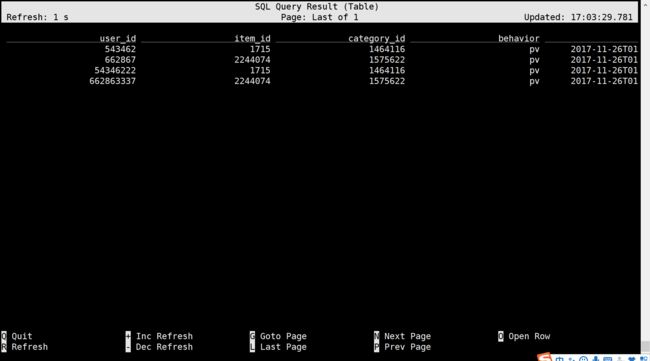
-
利用 Doris Flink Connector 创建 Doris 映射表
CREATE TABLE doris_test_sink_1 ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts varchar ) WITH ( 'connector' = 'doris', 'fenodes' = '10.220.146.10:8030', 'table.identifier' = 'test_2.user_log', 'sink.batch.size' = '2', 'username' = 'root', 'password' = '' )执行下面SQL 查询Doris数据库表里的数据,验证是否正常
select * from doris_test_sink_1;执行以后可以看到下面的界面,显示有四条数据,是正常的
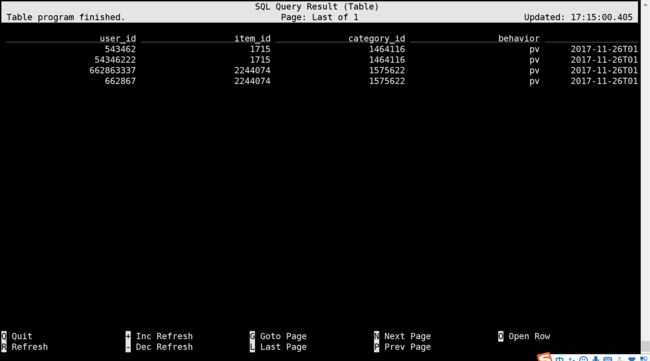
- 提交 插入语句,从Kafka表中读取数据插入到Doris中
insert into doris_test_sink_1 select * from user_log;显示任务已经提交到FLink 集群上运行

在Flink 集群的web界面我们也可以看到这个Job
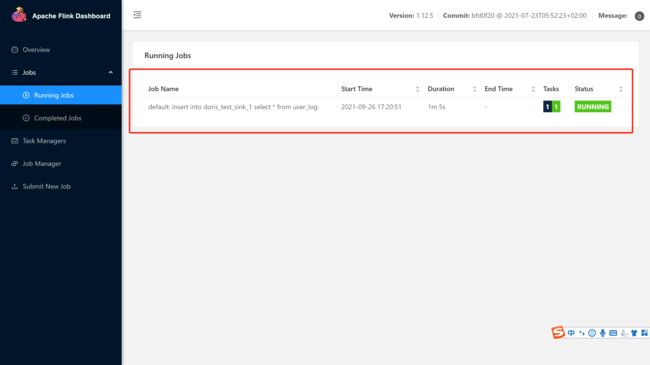
- 然后我们朝Kafka topic中推送两条数据,看看是否在Doris表中能查询到
{"user_id": "123456", "item_id":"123", "category_id": "1464116", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
{"user_id": "1765543", "item_id":"456", "category_id": "1575622", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}

-
验证结果
我们在Flink SQL Client界面查询可以看到红色标识出来额的两条数据已经插入进去,说明是正常的。

5.总结
我们到这里整个的演示就结束了,使用Doris flink connector可以很容易的通过Flink SQL方式整合各种异构数据源,导入到Doris数仓中,非常的方便