Python入门自学进阶-Web框架——35、网络爬虫使用
自动从网上抓取信息,就是获取相应的网页,对网页内容进行抽取整理,获取有用的信息,保存下来。
要实现网上爬取信息,关键是模拟浏览器动作,实现自动向网址发送请求,然后获取到相应的信息流,在对这个信息流进行统计查找,得到想要的信息。
Requests第三方库是基于Python开发的HTTP 库,其在Python内置模块(Python标准库中提供了:urllib、urllib2、httplib等模块以供Http请求,可用性不太好)的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
一、requests模块
安装 pip3 install requests
二、requests模块的方法
requests 方法如下表:
方法 |
描述 |
delete(url, args) |
发送 DELETE 请求到指定 url |
get(url, params, args) |
发送 GET 请求到指定 url |
head(url, args) |
发送 HEAD 请求到指定 url |
patch(url, data, args) |
发送 PATCH 请求到指定 url |
post(url, data, json, args) |
发送 POST 请求到指定 url |
put(url, data, args) |
发送 PUT 请求到指定 url |
request(method, url, args) |
向指定的 url 发送指定的请求方法 |
url 请求 url。
data 参数为post方法要发送到指定 url 的字典、元组列表、字节或文件对象。
json 参数为要发送到指定 url 的 JSON 对象。
args 为其他参数,比如 cookies、headers、verify等。
params参数为get方法要发送到指定 url 的参数键值对
对于GET方法,参数是params,最终会被组合到url中,以?key1=value1&key2=value2形式提交,对于POST方法,参数是data,不在url中体现,在请求体中保存。
三、GET请求
import requests
ret = requests.get('https://www.sina.com/') # 无参数
ret.encoding = 'utf-8' # 如果不写这一句,打印的中文乱码
print(ret.url) # 响应的地址
print(ret.text) # 返回的页面内容url是https://www.sina.com/
返回的是一个response对象,该对象包含了具体的响应信息。
属性或方法 |
说明 |
apparent_encoding |
编码方式 |
close() |
关闭与服务器的连接 |
content |
返回响应的内容,以字节为单位 |
cookies |
返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
elapsed |
返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
encoding |
解码 r.text 的编码方式 |
headers |
返回响应头,字典格式 |
history |
返回包含请求历史的响应对象列表(url) |
is_permanent_redirect |
如果响应是永久重定向的 url,则返回 True,否则返回 False |
is_redirect |
如果响应被重定向,则返回 True,否则返回 False |
iter_content() |
迭代响应 |
iter_lines() |
迭代响应的行 |
json() |
返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
links |
返回响应的解析头链接 |
next |
返回重定向链中下一个请求的 PreparedRequest 对象 |
ok |
检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
raise_for_status() |
如果发生错误,方法返回一个 HTTPError 对象 |
reason |
响应状态的描述,比如 "Not Found" 或 "OK" |
request |
返回请求此响应的请求对象 |
status_code |
返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
text |
返回响应的内容,unicode 类型数据 |
url |
返回响应的 URL |
import requests
payload = {'key1':'value1','key2':'value2'}
ret = requests.get('https://www.sina.com/',params=payload) # 带参数
ret.encoding='utf-8'
print(ret.url)
print(ret.text)url是https://www.sina.com/?key1=value1&key2=value2
四、POST请求
payload1 = {'key1':'value1','key2':'value2'}
ret = requests.post('http://www.sina.com',data=payload1) #基本POST
print(ret.text)
#发送请求头和数据
import json
url = "https://www.sina.com"
payload1 = {'key1':'value1','key2':'value2'}
headers = {'content-type':'application/json'}
ret = requests.post(url,data=json.dumps(payload1),headers=headers)
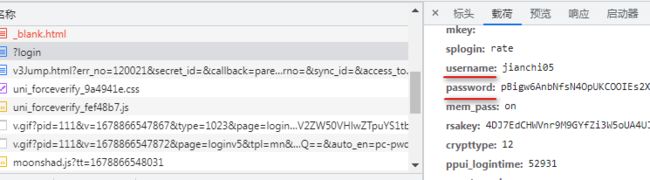
print(ret.text)使用post方法,需要会使用调试工具,使用网络来查看其传递的参数,如登录百度:在post提交的参数中有username和password参数。
五、request方法
payload = {'key1':'value1','key2':'value2'}
url = "https://www.sina.com"
ret = requests.request(method='get',url=url,params=payload)
print(ret.url)
print(ret.text)其他如get、post等方法,是对request方法的再包装。
六、关于request方法的参数——通过源代码查看
在查看request的源代码,提供了参数的解释:
"""Constructs and sends a :class:`Request
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How many seconds to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout)
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'https://httpbin.org/get')
>>> req
"""
request方法中关于post或get的参数传递
# filename:s1.py
import requests
requests.request(
method='get', # 或 'post'
url='http://127.0.0.1:8000/test/',
params={'key1':'value1','key2':'value2'},
# params最终拼接形成get的url参数部分,也可以是如下形式: “key1=value1&key2=value2”
data = {'user':'root','pwd':'123456'}, # 此格式默认发送content-type:application/X-WWW-form-urlencoding
# data是post方法提交时的参数,在请求体中传递;也可如下形式:"user=root;pwd=123456"
)view函数test:
def test(request):
print(request.GET)
print(request.POST)
print(request.body)
return HttpResponse("..........................")URLconf:path('test/',views.test,name='test'),
运行s1.py,结果,可以看出,POST中无内容,但是body中有内容,即data作为参数在请求体中保存传递,虽然是get请求,但是data内容也传递了。

将s1.py中的method改为post,结果

首先,post请求,params参数也传递了,而request.POST中的内容,是从body中内容解析出来的,只有当content-type是 'application/x-www-form-urlencoded',Django才会从body中将内容解析成字典给POST。当data是字典形式时,默认发送了content-type = 'application/x-www-form-urlencoded',在test.py中加上:print(request.headers):
运行的结果如下:
b'user=root&pwd=123456'
{'Content-Length': '20', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': '127.0.0.1:8000', 'User-Agent': 'python-requests/2.28.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 当使用data = 'user=root;pwd=123456'时,打印的POST是空的,如下图

此时的content-type默认是text/plain,设置headers:

此时运行POST有数据了。
传递数据还可以使用json:
requests.request(
method='post', # 或 'post'
url='http://127.0.0.1:8000/test/',
# params={'key1':'value1','key2':'value2'},
params = "key1=value1&key2=value2",
# params最终拼接形成get的url参数部分,也可以是如下形式: “key1=value1&key2=value2”
json = json.dumps({'user':'root','pwd':'123456'}), # 此时要使用application/json
)运行结果:

此时body中是json格式字符串,POST中无内容,content-type是application/json
参数:headers和cookies
有时会发生以下情形:在浏览器中可以访问页面,但是使用request方法却无法获取,原因一般如下:
一是headers中没有加User-Agent;二是没有Referer;三是对于需要登录的页面,需要设置cookie参数。
User-Agent,对于谷歌浏览器,一般是“Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36',”格式;
Referer指出是从哪一个页面过来的,即上一个访问的是哪个页面;
Cookies,通过浏览器的调试工具,获取cookie,将其中的重要内容作为cookies的内容
res = requests.get(
# url='https://i.csdn.net/#/user-center/profile?spm=1010.2135.3001.5111',
url = 'https://blog.csdn.net/kaoa000/',
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36',
# 'Referer':'https://www.zhihu.com/',
},
cookies ={'UserName':'kaoa000',
'UserInfo':'xxx获取的内容',
'UserToken':'调试工具获取的内容',
'UserNick':'调试工具获取的cookie的内容',
'UN':'调试工具获取的cookie的内容',
'p_uid':'调试工具获取的cookie的内容',
'csrfToken':'调试工具获取的cookie的内容',
'dc_sid':'调试工具获取的cookie的内容',
'SESSION':'调试工具获取的cookie的内容',
}
)
print(res.text)发送文件:
def param_files():
# 发送文件
file_dict = {
'f1': open('readme', 'rb')
}
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
files=file_dict)
# 发送文件,定制文件名
file_dict = {
'f1': ('test.txt', open('readme', 'rb'))
}
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
files=file_dict)
# 发送文件,定制文件名
file_dict = {
'f1': ('test.txt', "hahsfaksfa9kasdjflaksdjf")
}
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
files=file_dict)
# 发送文件,定制文件名
file_dict = {
'f1': ('test.txt', "hahsfaksfa9kasdjflaksdjf", 'application/text', {'k1': '0'})
}
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
files=file_dict)登录认证:只针对基本的登录认证
需要使用HTTPBasicAuth类
def param_auth():
from requests.auth import HTTPBasicAuth, HTTPDigestAuth
import requests
ret = requests.get('https://api.github.com/user', auth=HTTPBasicAuth('wupeiqi', 'sdfasdfasdf'))
print(ret.text)
# ret = requests.get('http://192.168.1.1',
# auth=HTTPBasicAuth('admin', 'admin'))
# ret.encoding = 'gbk'
# print(ret.text)
# ret = requests.get('http://httpbin.org/digest-auth/auth/user/pass', auth=HTTPDigestAuth('user', 'pass'))
# print(ret)关键是给HTTPBasicAuth()传递两个参数:用户名和密码,然后以auth变量名传递过去。
超时设置:
def param_timeout():
# ret = requests.get('http://google.com/', timeout=1)
# print(ret)
# ret = requests.get('http://google.com/', timeout=(5, 1))
# 第一个参数5是请求时的超时时间,即点击链接后的等待时间,第二个参数是读取数据的时间,即请求完成,开始读取数据的时间
# print(ret)重定向设置:
def param_allow_redirects():
ret = requests.get('http://127.0.0.1:8000/test/', allow_redirects=False)
print(ret.text)代理设置:
def param_proxies():
# proxies = {
# "http": "61.172.249.96:80",
# "https": "http://61.185.219.126:3128",
# “https://www.baidu.com”:"61.172.249.96:80" # 访问某个网站使用代理
# }
# proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}
# ret = requests.get("http://www.proxy360.cn/Proxy", proxies=proxies)
# print(ret.headers)
# 当代理需要登录验证时,如下
# from requests.auth import HTTPProxyAuth
#
# proxyDict = {
# 'http': '77.75.105.165',
# 'https': '77.75.105.165'
# }
# auth = HTTPProxyAuth('username', 'mypassword')
#
# r = requests.get("http://www.google.com", proxies=proxyDict, auth=auth)
# print(r.text)证书验证:
需要携带证书,使用cert,使用内置证书,使用verify