Python入门自学进阶-Web框架——37、异步IO与scrapy
异步IO:
一个请求多个网址并获取返回值的程序:
import requests
url_list = [
'https://www.baidu.com',
'https://www.google.com',
'https://www.bing.com',
'https://www.sohu.com',
]
for url in url_list:
print('开始请求:',url)
response = requests.get(url=url,)
print('得到结果',response.url,response.content)运行结果:
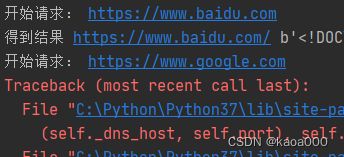
在请求google时,停顿很长时间后出错(国内google不可访问了),并且后面的请求也没有执行,这就是同步请求,请求,有结果后,再下一个,亦步亦趋。显然这种结果很不友好。一个是发送请求后,可能要很长时间返回结果,这时的等待,cpu空闲,显然是一种浪费;二是一个网址访问不到,不应该影响其他网址的访问。
使用多线程:
import requests
from concurrent.futures import ThreadPoolExecutor
url_list = [
'https://www.baidu.com',
'https://www.google.com',
'https://www.bing.com',
'https://www.sohu.com',
]
def async_url(url):
response = requests.get(url)
print('获取结果',response.url,response.content)
pool = ThreadPoolExecutor(5) # 创建含有5个线程的线程池
for url in url_list:
print('开始请求',url)
pool.submit(async_url,url)
pool.shutdown(wait=True)运行结果:

四个请求都发出,获得三个结果。这就是多线程,一个请求发出后,如果结果没有马上返回,就切换到其他线程,即执行其他请求,因为IO请求时间很长,所以,四个请求都进行了线程切换,都发送了请求。
使用多进程:
一开始,以为只要更改一下引入的类就行了:
import requests
from concurrent.futures import ProcessPoolExecutor
url_list = [
'https://www.baidu.com',
'https://www.google.com',
'https://www.bing.com',
'https://www.sohu.com',
]
def async_url(url):
response = requests.get(url)
print('获取结果',response.url,response.content)
pool = ProcessPoolExecutor(5) # 创建含有5个线程的线程池
for url in url_list:
print('开始请求',url)
pool.submit(async_url,url)
pool.shutdown(wait=True)将ThreadPoolExecutor改为ProcessPoolExecutor,结果运行出现错误:

使用 多进程,要有一个主进程,主进程调用其他进程,要判断是否为主进程:
import requests
from concurrent.futures import ProcessPoolExecutor
url_list = [
'https://www.baidu.com',
'https://www.google.com',
'https://www.bing.com',
'https://www.sohu.com',
]
def async_url(url):
try:
response = requests.get(url)
except Exception as e:
print("异常结果",response.url,response.content)
print('获取结果',response.url,response.content)
if __name__ == '__main__':
pool = ProcessPoolExecutor(max_workers=5) # 创建含有5个进程的进程池
for url in url_list:
print('开始请求',url)
pool.submit(async_url,url)
pool.shutdown(wait=True)运行结果:

对于IO请求,使用多线程更好,对于计算密集型,多进程更好。
多线程加回调函数:当线程执行完毕后,也就是async_url执行结束,可以接着再执行一个另外的函数,这个被执行的函数叫做回调函数。
import requests
from concurrent.futures import ThreadPoolExecutor
url_list = [
'https://www.baidu.com',
'https://www.google.com',
'https://www.bing.com',
'https://www.sohu.com',
]
def async_url(url):
response = requests.get(url)
print('线程内获取结果',response.url,response.content)
return response # 这里必须要有返回,供回调函数使用
def callback(future):
print("回调函数",future.result().content)
# 这里的future,就应该是下面v.add_done_callback(callback)的v,即self,
# 也就是add_done_callback这个函数将调用者自身作为回调函数的参数,即future
# future.result()得到response对象,然后打印的是response的content
pool = ThreadPoolExecutor(5) # 创建含有5个线程的线程池
for url in url_list:
print('开始请求',url)
v = pool.submit(async_url,url) # 这里,v是一个Future类,其包装了async_url这个线程函数的返回结果,即其中含有response,使用Future.result()可以获得response这个结果对象
print(v)
v.add_done_callback(callback)
pool.shutdown(wait=True)
线程池的使用
基类:Executor
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor
子类:ThreadPoolExecutor 和 ProcessPoolExecutor
ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
如果使用线程池/进程池来管理并发编程,那么只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。
Exectuor 提供了如下常用方法:
- submit(fn, *args, **kwargs):将 fn 函数提交给线程池。*args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
- map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
- shutdown(wait=True):关闭线程池。
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个“将来完成”的任务,所以 Python 使用 Future 来代表。
Future 提供了如下方法:
- cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。
- cancelled():返回 Future 代表的线程任务是否被成功取消。
- running():如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。
- done():如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。
- result(timeout=None):获取该 Future 代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒。
- exception(timeout=None):获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。
- add_done_callback(fn):为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数。
shutdown() 方法:
在用完一个线程池后,应该调用该线程池的 shutdown() 方法,该方法将启动线程池的关闭序列。调用 shutdown() 方法后的线程池不再接收新任务,但会将以前所有的已提交任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。其参数wait=True或wait=False,
使用线程池来执行线程任务的步骤如下:
- 调用 ThreadPoolExecutor 类的构造器创建一个线程池。
- 定义一个普通函数作为线程任务。
- 调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
为什么使用回调函数?
如果将上面程序中的v.add_done_callback(callback)换成直接打印结果:print(v.result())
则效果跟同步方式一样了,在第二步请求google时被阻塞。
调用 Future 的 result() 方法来获取线程任务的返回值,该方法会阻塞当前主线程,只有等到钱程任务完成后,result() 方法的阻塞才会被解除。
如果程序不希望直接调用 result() 方法阻塞线程,则可通过 Future 的 add_done_callback() 方法来添加回调函数,该回调函数形如 fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的 Future 对象作为参数传给该回调函数。
线程、进程、协程、GIL
异步IO
在Python3中,增加了asyncio模块,实现异步IO
import asyncio
@asyncio.coroutine
def func1():
print('before...func1.....')
yield from asyncio.sleep(5)
print('end...func1...')
tasks = [func1(),func1()] # 事件列表
loop = asyncio.get_event_loop() # 创建事件循环
loop.run_until_complete(asyncio.gather(*tasks)) #加入循环的事件,运行
loop.close()这是一个异步IO的使用框架,装饰器装饰的事件(含有IO操作,需要异步),事件列表,事件循环,关闭。
asyncio支持sleep,支持tcp,即支持这两种异步IO,但是不支持http。
为此,可以利用socket基于tcp来自己构建适用于http的异步IO:
import asyncio
@asyncio.coroutine
def fetch_async(host, url='/'):
print(host, url)
reader, writer = yield from asyncio.open_connection(host, 80) # tcp连接,属于IO操作,需要异步,使用了yield from
request_header_content = """GET %s HTTP/1.0\r\nHost: %s\r\n\r\n""" % (url, host,)
request_header_content = bytes(request_header_content, encoding='utf-8')
writer.write(request_header_content)
yield from writer.drain() # 写操作,即发送信息操作,属于IO,要异步
text = yield from reader.read() # 读操作,即接收信息操作,属于IO,要异步
print(host, url, text)
writer.close()
tasks = [
fetch_async('blog.csdn.net', '/kaoa000/'),
fetch_async('dig.chouti.com', '/pic/show?nid=4073644713430508&lid=10273091')
]
loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()上例使用了open_connection()方法,是基于tcp协议的,来完成http的异步IO。
asyncio与aiohttp组合:
Python提供另一个扩展的模块aiohttp,来完成http的异步IO。
import aiohttp
import asyncio
@asyncio.coroutine
def fetch_async(url):
print(url)
response = yield from aiohttp.request('GET', url)
# data = yield from response.read()
# print(url, data)
print(url, response)
response.close()
tasks = [fetch_async('http://www.google.com/'), fetch_async('http://www.chouti.com/')]
event_loop = asyncio.get_event_loop()
results = event_loop.run_until_complete(asyncio.gather(*tasks))
event_loop.close()但是上述代码在测试时出现错误,经过查询,这个是Python3.4的语法,现在已经改成async/await语法了。
import aiohttp
import asyncio
async def fetch_async(session,url):
print(url)
async with session.get(url) as response:
return await response.text()
async def main(url):
async with aiohttp.ClientSession() as session:
html = await fetch_async(session,url)
print(html)
tasks = [main('http://www.google.com/'), main('http://www.chouti.com/')]
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(asyncio.wait(tasks))
event_loop.close()异步与多线程并不是同一个概念,多线程编程是实现异步的一种手段
同步异步更强调的是消息反馈机制,即调用后是否需要等待返回结果。
什么是多线程
多线程,是指从软件或者硬件上实现多个线程并发执行或并行执行的技术(单核CPU只可并发,多核CPU取决系统调度)。其依赖的是并发执行机制原理。
并发执行机制原理:简单地说就是把一个处理器划分为若干个短的时间片,每个时间片依次轮流地执行处理各个应用程序,由于一个时间片很短,相对于一个应用程序来说,就好像是处理器在为自己单独服务一样,从而达到多个应用程序在同时进行的效果 。
多线程就是把操作系统中的这种并发执行机制原理运用在一个程序中,把一个程序划分为若干个子任务,多个子任务并发执行,每一个任务就是一个线程。这就是多线程程序 。
利用CPU在处理其他任务时产生的空余、等待时间、压榨CPU劳动力就是多线程
异步与多线程异同点
异步和多线程都可以达到避免调用线程阻塞的目的
异步操作在完成await操作后,会发出完成通知,并释放占用的线程,之后系统调用线程池中空余的线程来进行await之后的操作,减少了线程负担。
而多线程编程会在整个任务中一直占用线程造成资源浪费。比如DMA(直接存储器访问)操作,允许硬件可以不通过CPU而直接与内存数据进行交互,在这时闲置的线程无法被释放,造成了资源浪费。(使用异步可以避免)
异步与多线程适用场景
异步:I/O密集操作
多线程:CPU密集操作
asyncio与requests结合:
import asyncio
import requests
async def fetch_async(func,*args):
loop = asyncio.get_event_loop()
future = await loop.run_in_executor(None,func,*args)
print (future.url,future.content)
tasks = [fetch_async(requests.get,'http://www.cnblogs.com/wupeiqi/'),
fetch_async(requests.get, 'http://www.baidu.com/')]
loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()gevent使用:也是异步IO
from gevent import monkey
monkey.patch_all() # 将socket替换为gevent
import requests
import gevent
def fetch_async(method,url,req_kwargs):
print(method,url,req_kwargs)
response = requests.request(method=method,url=url,**req_kwargs)
print(response.url,response.content)
gevent.joinall([
gevent.spawn(fetch_async,method='get',url='https://www.python.org/',req_kwargs={}),
gevent.spawn(fetch_async,method='get',url='https://www.yahoo.com/',req_kwargs={}),
gevent.spawn(fetch_async,method='get',url='https://www.baidu.com/',req_kwargs={})
])
grequests模块,对上面程序的再封装,应用更简单:
import grequests
request_list = [
grequests.get('https://www.python.org/',timeout=1),
grequests.get('http://fakedomain/'),
grequests.get('http://www.baidu.com')
]
response_list = grequests.map(request_list)
print(response_list)Twisted:Twisted是用Pyhton实现的基于事件驱动的网络引擎框架
from twisted.web.client import getPage, defer
from twisted.internet import reactor
def all_done(arg):
reactor.stop()
def callback(contents):
print(contents)
deferred_list = []
url_list = ['http://www.bing.com', 'http://www.baidu.com', ]
for url in url_list:
deferred = getPage(bytes(url, encoding='utf8'))
deferred.addCallback(callback)
deferred_list.append(deferred)
dlist = defer.DeferredList(deferred_list)
dlist.addBoth(all_done)
reactor.run()上述代码是老版本,现在已经没有getPage方法。
tornado,Tornado 是使用 Python 开发的全栈式(full-stack)Web 框架和异步网络库,通过使用非阻塞 IO,Tornado 可以处理数以万计的开放连接。
Tornado 主要分成四个部分:
- Web 框架(包括 RequestHandler,用于创建 Web 程序的基类,以及各种支持类)
- 实现 HTTP 的客户端和服务器端 (HTTPServer 和 AsyncHTTPClient).
- 一个异步网络库 (IOLoop 和 IOStream)
- 一个协程库 (tornado.gen) ,使得异步调用代码能够以更直接的方式书写,取代回调链接
from tornado.httpclient import AsyncHTTPClient
from tornado.httpclient import HTTPRequest
from tornado import ioloop
def handle_response(response):
"""
处理返回值内容(需要维护计数器,来停止IO循环),调用 ioloop.IOLoop.current().stop()
:param response:
:return:
"""
if response.error:
print("Error:", response.error)
else:
print(response.body)
def func():
url_list = [
'http://www.baidu.com',
'http://www.bing.com',
]
for url in url_list:
print(url)
http_client = AsyncHTTPClient()
http_client.fetch(HTTPRequest(url), handle_response)
ioloop.IOLoop.current().add_callback(func)
ioloop.IOLoop.current().start()上面的代码现在运行有问题。
scrapy框架:
安装:pip install scrapy
安装成功后,可以在终端使用scrapy命令:
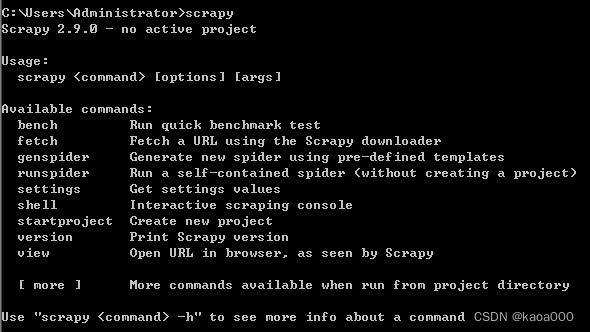
创建scrapy项目:使用scrapy startproject name,如
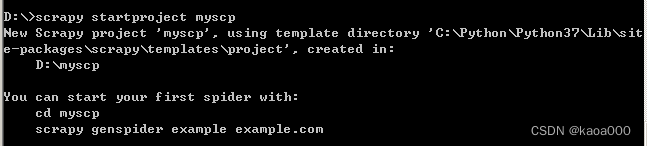
此时,在D盘下会创建目录myscp,如下:

这就类似django创建的项目,然后创建爬虫,类似Django创建app
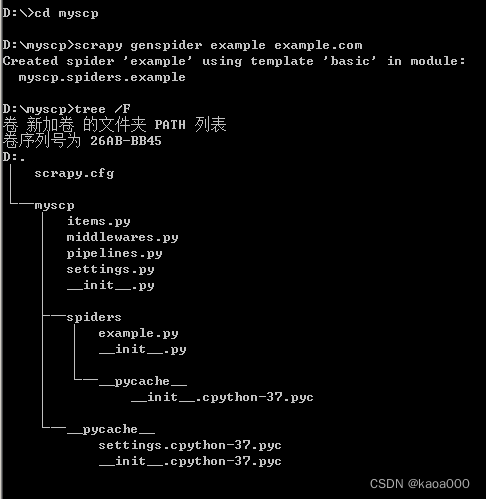
在spiders子目录下多了example.py文件,就是一个爬虫。example.py:
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example" # 爬虫的名字,在运行时使用,作为区别其他爬虫的标志
allowed_domains = ["example.com"] # 允许爬取的域,只爬取此域的网页
start_urls = ["https://example.com"] # 爬虫的起始点
def parse(self, response): # 对爬取结果进行解析的工作放在这个函数中
pass
做一个爬自己博客的爬虫:

import scrapy
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["blog.csdn.net"]
start_urls = ["https://blog.csdn.net/kaoa000"]
def parse(self, response):
print(response.text)执行:scrapy crawl csdn --nolog
--nolog表示
可以产生的爬虫模板:

爬一个文秘网的例子:
import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
class WenmiSpider(scrapy.Spider):
name = "wenmi"
allowed_domains = ["laojinfw.cn"]
start_urls = ["https://www.laojinfw.cn/list/150?page=1"]
def parse(self, response): # response的类型:scrapy.http.response.html.HtmlResponse
item_list =response.xpath('//div[@class="post grid"]')
for item in item_list:
v = item.xpath('./h3/a/text()').get()
print(v)
运行:scrapy crawl wenmi --nolog
结果如下:

再往深层爬取,就是点击对应的文章,获取文章的内容:
import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse,Request
class WenmiSpider(scrapy.Spider):
name = "wenmi"
allowed_domains = ["laojinfw.cn"]
start_urls = ["https://www.laojinfw.cn/list/150?page=1"]
def parse(self, response): # response的类型:scrapy.http.response.html.HtmlResponse
item_list =response.xpath('//div[@class="post grid"]')
url_list = []
for item in item_list:
url_t = item.xpath('./h3/a/@href').get()
v = item.xpath('./h3/a/text()').get()
print('https://www.laojinfw.cn' + url_t)
page = 'https://www.laojinfw.cn' + url_t
url_list.append(page)
for url in url_list:
obj = Request(url=url,method='GET',callback=self.parse_page)
yield obj
def parse_page(self,response):
print('============================')
item_list = response.xpath('//div[@class="container"]/p/span/text()')
for item in item_list:
print(item.get())结果:

此篇只是一个对异步IO和scrapy的起步认识,通知这次学习,感觉异步IO是很复杂的,需要一个知识点一个知识点的仔细学,关键是弄懂原理。
再就是很多相关的模块都升级了,尤其是异步IO的模块,升级后有些方法要么被新方法取代,要么用法改变很大,所以要自己找最新的资料去一点点学习。