【python与数据分析】CH3 python序列结构补充——字符串
目录
前言
一、字符串简介
二、字符串编码
三、转义字符
1.表格
2.转义字符用法
四、字符串格式化
1.使用%运算符进行格式化
2.使用format方法进行格式化
3.格式化的字符串常量
五、字符串常用方法与操作
1.find()、rfind()、index()、rindex()、count()
2.split()、rsplit()、partition()、rpartition()
3.字符串连接符join()
4.lower()、upper()、capitalize()、title()、swapcase()
5.replace()、maketrans()、translate()
6.strip()、rstrip()、lstrip()
7.startswith()、endswith
8.isalnum()、isalpha()、isdigit()、isspace()、isupper()、islower()
9.center()、ljust()、rjust()
10.字符串对象支持的运算符
(1)+
(2)in
(3)*
(4)【例7-2】检测用户输入中是否有不允许的敏感字词,如果有就提示非法,否则提示正常
(5)【例7-3】测试用户输入中是否有敏感词,如果有的话就把敏感词替换成三个星号***
11.适用于字符串对象的内置函数
12.字符串切片
六、字符串常量
1.【例7-5】使用string模块提供的字符串常量,模拟生成指定长度的随机密码
七、中英文分词
八、汉字到拼音的转换
九、综合案例分析
1.【例7-6】编写函数实现字符串加密和解密,循环使用指定密钥,采用简单的异或算法
2.【例7-7】编写程序,统计一段文字中每个词出现的次数
3.【例7-8】检查并判断密码字符串的安全强度
前言
- 了解ASCII、UTF-8、GBK、CP936等常见字符编码格式
- 了解转义字符和原始字符的概念和用法
- 掌握字符串格式化方法format()的用法
- 熟练运用字符串常用方法
- 熟练运用运算符和内置函数对字符串的操作
一、字符串简介
- 在python中,字符串属于不可变有序序列,使用单引号、双引号、三单引号或三双引号作为定界符,并且不同的定界符之间可以互相嵌套。例如:'abc'、'123'、'中国';"python";'''Tom said,"Let's go." '''
- 除了支持序列通用方法(包括双向索引、比较大小、计算长度、元素访问、切片、成员测试等操作)以外,字符串类型还支持一些特有的操作方法,例如字符串格式化、查找、替换、排版等
- 字符串属于不可变序列,不能直接对字符串对象进行元素增加、修改和删除等操作,切片操作也只能访问其中的元素而无法使用切片来修改字符串中的字符
二、字符串编码
- 最早的字符串编码是美国标准信息交换码ASCII,仅对10个数字、26个大写英文字母、26个小写英文字母及一些其他字符进行了编码。ASCII码采用1个字节(用8位二进制数来表示一个字节)来对字符进行编码,最多只能表示256个符号
- Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案ASCII的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理要求。1990年开始研发,1994年正式公布
- GB2312是我国制定的中文编码,使用1个字节表示英语,2个字节表示中文;GBK是GB2312的扩充,而CP936是微软在GBK基础上开发的编码方式。GB2312、GBK和CP936都是使用2个字节表示中文
- UTF-8是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创键。UTF-8对全国所有国家需要用到的字符进行了编码,以1个字节表示英语字符(兼容ASCII),以3个字节表示中文,还有些语言的符号使用2个字节(例如俄语和希腊语符号)或4个字节
- 不同编码格式之间相差很大,采用不同的编码格式意味着不同的表示和存储形式,把同一字符存入文件时,写入的内容可能会不同,在试图理解其内容时必须了解编码规则并进行正确的解码。如果解码方法不正确就无法还原信息,从这个角度来讲,字符串编码也具有加密的效果
- python 3.x完全支持中文字符,默认使用UTF-8编码格式,无论是一个数字、英文字母,还是一个汉字,在统计字符串长度时都按一个字符对待和处理
>>> s='中国山东烟台' >>> len(s) 6 >>> s='山东烟台ABSIHU' >>> len(s) 10 >>> 姓名='张三' #使用中文作为变量名,一般不用 >>> print(姓名) 张三
三、转义字符
1.表格
| 转义字符 | 含义 |
| \b | 退格,把光标移动到前一列位置 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \\ | 一个斜线\ |
| \' | 单引号 |
| \\" | 双引号 |
| \ooo | 3位八进制数对应的字符 |
| \xhh | 2位十六进制数对应的字符 |
| \uhhhh | 4位十六进制数表示的Unicode字符 |
2.转义字符用法
- 为了避免对字符串中的转义字符进行转义,可以使用原始字符串,在字符串前面加上字母r或R表示原始字符,其中的所有字符都表示原始的含义而不会进行任何转义
>>> print('Hello\nworld') #包含转义字符的字符串
Hello
world
>>> print('\101') #三位八进制数对应的字符,相当于print(chr(65))
A
>>> print('\x41') #两位十六进制数对应的字符,相当于print(chr(65))
A
>>> hex(ord("胡"))
'0x80e1'
>>> hex(ord("歌"))
...
'0x6b4c'
>>> print('我是\u80e1\u6b4c') #四位十六进制数表示Unicode字符
...
我是胡歌
>>> path='C:\Windows\notepad.exe'
>>> print(path) #字符\n被转义位换行符
C:\Windows
otepad.exe
>>> path=r'C:\Windows\notepad.exe' #原始字符串,任何字符都不转义
>>> print(path)
C:\Windows\notepad.exe
>>> path=R'C:\Windows\notepad.exe'
>>> print(path)
C:\Windows\notepad.exe四、字符串格式化
1.使用%运算符进行格式化
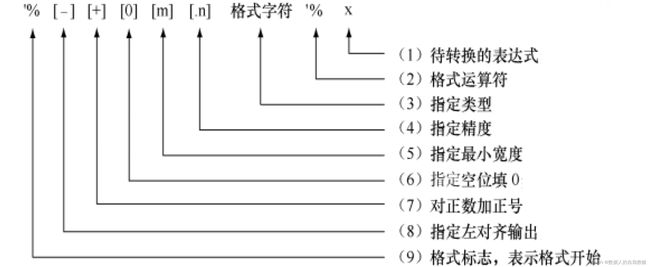
| 常用格式字符 | |
| 格式字符 | 说明 |
| %s | 字符串(采用str()的显示) |
| %r | 字符串(采用repr()的显示) |
| %c | 单个字符 |
| %d | 十进制整数 |
| %i | 十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数 |
| %e | 指数(基底写为e) |
| %E | 指数(基地写为E) |
| %f,%F | 浮点数 |
| %g | 指数(e)或浮点数(根据显示长度) |
| %G | 指数(E)或浮点数(根据显示长度) |
| %% | 一个字符"%" |
>>> x=12345
>>>so="%o"%x #将对象x格式化为八进制字符串
>>> so
'30071'
>>> sh="%x"%x #把对象格式化为十六进制字符串
>>> sh
'3039'
>>> se="%e"%x #把对象格式化为以e为底的指数字符串
>>> se
'1.234500e+04'
>>> chr(ord("3")+1) #讲字符串“3”转为Unicode码加1后再转回对应字符
'4'
>>> "%s"%65 #将整数65格式化为字符串‘65’
'65'
>>> ord('3')
51
>>> chr(52)
'4'
>>> type("%o"%x)
>>> "%d"%"555" #只有整数才能格式化为%d、%o、%x等形式
Traceback (most recent call last):
File "", line 1, in
"%d"%"555"
TypeError: %d format: a real number is required, not str
2.使用format方法进行格式化
基本使用格式:
<模板字符串>.format(<逗号分隔的参数>)
- 调用format()方法后会返回一个新的字符串,参数序号从0开始编号
- <模板字符串>中有槽{}及格式控制信息
- 槽的内部样式如下
{[name][:][fill][align][sign][#][0][width][,][.precision][type]}
- name:数字(占位),命名(传递参数名,不能以数字开头),以字典格式映射格式化,其为键名
- fill=
#fill是表示可以填写任何字符 - align="<"|">"|"="|"^" #align是对齐方式,分别对应左对齐,右对齐,居中对齐
- sign="+"|"-"|" " #符号,+表示正号,-表示负号
- width=integer #数字宽度,表示总共输出多少位数字
- precision=interger #小数保留位数
- type="b"|"c"|"d"|"e"|"E"|"f"|"F"|"g"|"G"|"n"|"o"|"s"|"x"|"X"|"%" #输出数字值的表示方式,比如b是二进制表示,E是指数表示,X是十六进制表示
>>> 1/3
0.3333333333333333
>>> print('{0:.3f}'.format(1/3))
0.333
>>> '{0:%}'.format(3.5)
'350.000000%'
>>> '{0:_}','{0:_x}'.format(1000000)
('{0:_}', 'f_4240')
>>> KeyboardInterrupt
>>> '{0:_},{0:_x}'.format(1000000)
'1_000_000,f_4240'
>>> print("The number{0:,}in hex is:{0:#x},the number {1} in oct is {1:}".format(5555,55))
The number5,555in hex is:0x15b3,the number 55 in oct is 55
>>> print("The number{1:,}in hex is:{1:#x},the number {0} in oct is {0:#o}".format(5555,55))
The number55in hex is:0x37,the number 5555 in oct is 0o12663
>>> print("my name is {name},my age is {age},and my qq is {qq}".format(name="haha",age=40,qq="123456789"))
my name is haha,my age is 40,and my qq is 123456789
>>> position=(5,8,13)
>>> print("x:{0[0]};y:{0[1]};z:{0[2]}".format(position))
x:5;y:8;z:13
3.格式化的字符串常量
- 从python 3.6.x开始支持一种新的字符串格式化方法,官方叫做Formatted String Literals,在字符串前加字母f,含义与字符串对象format()方法类似
>>> name='haha'
>>> age=39
>>> f'my name is {name},and i am {age} years old.'
'my name is haha,and i am 39 years old.'
>>> width=10
>>> precision=4
>>> value=11/3
>>> f'result:{value:{width}.{precision}}'
'result: 3.667'
五、字符串常用方法与操作
python字符串对象提供了大量方法用于字符串的切分、连接、替换和排版等操作,另外还有大量内置函数和运算符也支持对字符串的操作。
字符串对象是不可变的,所以字符串对象提供的设计到字符串“修改”的方法都是返回修改后的新字符串,并不对原始字符串做任何修改,无一例外。
1.find()、rfind()、index()、rindex()、count()
- find()、rfind()方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在返回-1
- index()、rindex()方法用来返回一个字符串在另一个字符串指定范围内首次和最后一次出现的位置,如果不存在则抛出异常
- cout()方法用来返回一个字符串在当前字符串中出现的次数
>>> s="apple,peach,bananam,peach,pear"
>>> s.find("peach")
6
>>> s.rfind("peach")
20
>>> s.find("peach",7) #指定从7开始查找
20
>>> s.find("peach",7,20)
-1
>>> s.index("peach")
6
>>> s.rindex("peah")
Traceback (most recent call last):
File "", line 1, in
s.rindex("peah")
ValueError: substring not found
>>> s.rindex("peach")
20
>>> s.count("peach")
2
>>> s.count("oooo")
0
2.split()、rsplit()、partition()、rpartition()
- split()和rsplit()方法分别用来以指定字符为分隔符,把当前字符串从左往右或从右往左分割成多个字符串,并返回包含分割结果的列表
- partition()和rpartition()用来以指定字符串为分隔符,将原字符串分隔为三部分,即分隔符前的字符,分隔符字符串,分隔符后的字符串。如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串
>>> s="apple,peach,bananam,peach,pear"
>>> s.split(",")
['apple', 'peach', 'bananam', 'peach', 'pear']
>>> s.partition(',')
('apple', ',', 'peach,bananam,peach,pear')
>>> s.partition(",")
('apple', ',', 'peach,bananam,peach,pear')
>>> s.rpartition(",")
('apple,peach,bananam,peach', ',', 'pear')
>>> s.rpartition("55")
('', '', 'apple,peach,bananam,peach,pear')
>>> s="1020-2-2"
>>> s.split("-")
['1020', '2', '2']
- split()和rsplit()方法还允许指定最大分割次数
>>> s='\n\nhello\t\tworld\n\n\nmy name is Dong'
>>> s
'\n\nhello\t\tworld\n\n\nmy name is Dong'
>>> s.split (None,1)
['hello', 'world\n\n\nmy name is Dong']
>>> s.rsplit(None,2)
['\n\nhello\t\tworld\n\n\nmy name', 'is', 'Dong']
>>> s.split(maxsplit=6)
['hello', 'world', 'my', 'name', 'is', 'Dong']
>>> s.split (maxsplit=100) #最大分割次数大于可分割次数时无效(不报错,忽略其余次数)
['hello', 'world', 'my', 'name', 'is', 'Dong']
- 对于split()和rsplit()方法,如果不指定分隔符,则字符串中的任何空白字符(空格、换行符、制表符等)都将被认定为分隔符,把连续多个空白字符看作一个分隔符
>>> s='hello\t\tworld\n\n\nmy name is Dong'
>>> s.split()
['hello', 'world', 'my', 'name', 'is', 'Dong']
>>> s='\n\nhello\t\tworld\n\n\nmy name is Dong'
>>> s.split()
['hello', 'world', 'my', 'name', 'is', 'Dong']
- 然而,明确传递参数指定split()使用的分隔符时,情况是不一样的
>>> 'a,,,bb,,ccc'.split(',')
['a', '', '', 'bb', '', 'ccc']
>>> 'a,\t\tbb,,\t\tccc'.split('\t')
['a,', '', 'bb,,', '', 'ccc']
3.字符串连接符join()
>>> li=["apple",'banana','pear','peach']
>>> ','.join(li)
'apple,banana,pear,peach'
>>> '.'.join(li)
'apple.banana.pear.peach'
4.lower()、upper()、capitalize()、title()、swapcase()
>>> s="What's your name?"
>>> s.lower() #返回小写字符串
"what's your name?"
>>> s.upper() #返回大写字符串
"WHAT'S YOUR NAME?"
>>> s.capitalize() #字符串首字符大写
"What's your name?"
>>> s.title
>>> s.title() #每个单词的首字母大写
"What'S Your Name?"
>>> s.swapcase() #大小写互换
"wHAT'S YOUR NAME?"
5.replace()、maketrans()、translate()
- 查找替换repalce(),相当于word中的“全部替换”功能
>>> s='中国,中国'
>>> print(s)
中国,中国
>>> s.replace('中国','中华人民共和国')
'中华人民共和国,中华人民共和国'
- 字符串对象的maketrans()方法用来生成字符映射表,而translate()方法用来根据映射表中定义的对应关系转换字符串并替换其中的字符,使用这两个方法的组合可以同时处理多个字符
>>> #创建映射表,将字符“abcdef123”一一地转换为“uvwxyz#$%”
>>> table=''.maketrans("abcdef123","uvwxyz#$%")
>>> s="abcdef123123fedcba"
>>> s.translate(table)
'uvwxyz#$%#$%zyxwvu'
>>> _.translate(table)
'uvwxyz#$%#$%zyxwvu'
- 【例7-1】使用maketrans()和translate()方法实现了凯撒加密算法,其中k表示算法密钥,也就是把每个英文字母变为其后面的第k个字母

>>> import string
>>> def kaisa(s,k):
... lower=string.ascii_lowercase #大写字母
... upper=string.ascii_uppercase #小写字母
... before=string.ascii_letters
... after=lower[k:]+lower[:k]+upper[k:]+upper[:k]
... table=''.maketrans (before,after) #创建映射表
... return s.translate(table)
...
>>> s="Python is a greate programming language,I like it!"
>>> kaisa(s,3)
'Sbwkrq lv d juhdwh surjudpplqj odqjxdjh,L olnh lw!'
6.strip()、rstrip()、lstrip()
>>> s='abc '
>>> s.strip() #删除空白字符
'abc'
>>> s='\nhello world \n \n' #删除空白字符(含各种转义字符)
>>> s
'\nhello world \n \n'
>>> s.strip()
'hello world'
>>> 'aaaaabbeessq'.strip('a') #删除指定字符
'bbeessq'
>>> 'sdefreqgsqy6'.strip('sf') #从左右两边逐一删除‘s’‘f’(不当整体)
'defreqgsqy6'
>>> 'aaaabbbbssaa'.rstrip('a') #删除字符串右端指定字符
'aaaabbbbss'
>>> 'aaaabbbbaaaa'.lstrip('ab')
''
>>> 'aaaabbbbaaaa'.lstrip('a') #删除字符串左端指定字符
'bbbbaaaa'
7.startswith()、endswith
- s.startswith()、s.endswith判断字符串是否以指定字符串开始或结束
>>> s='Beautiful is better than ugly.'
>>> s.startswith('Be') #检查整个字符串
True
>>> s.startswith('Be',5) #指定检测范围
False
>>> s.startswith('Be',0,5)
True
>>> import os
>>> [filename for filename in os.listdir(r'c:\Python37\\') if filename.endswith('.py','.jpg','.gif')]
8.isalnum()、isalpha()、isdigit()、isspace()、isupper()、islower()
- 用来检测字符是否为数字或字母,是否为字母,是否为数字,是否为空白字符,是否为大写字母,是否为小写字母
>>> '123'.isalnum()
True
>>> '123sjid'.isalnum()
True
>>> '123sjid'.isalpha()
False
>>> '123sjid'.isdigit()
False
>>> '123.12'.isdigit() #整数时返回True
Flase
9.center()、ljust()、rjust()
- 返回指定宽度的新字符串,原字符串居中,左对齐或右对齐出现在新字符串中,如果指定宽度大于字符串宽度,则使用指定的字符(默认为空格)进行填充
>>> 'hello world'.center(20)
' hello world '
>>> 'hello world'.center(20,'=')
'====hello world====='
>>> 'hello world'.ljust(20,'=')
'hello world========='
>>> 'hello world'.rjust(20,'=')
'=========hello world'
10.字符串对象支持的运算符
(1)+
- +:表示两个字符串的连接,生成新字符串(比join()慢很多)
>>> 'hello '+'world'
'hello world'
(2)in
- 成员判断关键字
>>> 'a' in "abe"
True
>>> 'ab ' in 'abc'
False
>>> 'ab' in 'abc'
True
>>> 'ac' in 'abc' #作为整体看待
False
(3)*
- 与整数的乘法运算,表示序列重复
>>> 'abc'*3
'abcabcabc'
(4)【例7-2】检测用户输入中是否有不允许的敏感字词,如果有就提示非法,否则提示正常
>>> words=('测试','暴力','非法')
>>> text='这句话里有非法内容'
>>> for word in words:
... if word in text:
... print('非法')
... break
... else:
... print('正常')
...
...
正常
正常
非法
(5)【例7-3】测试用户输入中是否有敏感词,如果有的话就把敏感词替换成三个星号***
>>> words=('测试','暴力','非法')
>>> text='这句话里有非法内容'
>>> for word in words:
... if word in text:
... text=text.replace(word,'***')
...
...
>>> text
'这句话里有***内容'
11.适用于字符串对象的内置函数
>>> x='hello world.'
>>> len(x)
12
>>> max(x)
'w'
>>> min(x)
' '
>>> list(zip(x,x))
[('h', 'h'), ('e', 'e'), ('l', 'l'), ('l', 'l'), ('o', 'o'), (' ', ' '), ('w', 'w'), ('o', 'o'), ('r', 'r'), ('l', 'l'), ('d', 'd'), ('.', '.')]
>>> sorted(x)
[' ', '.', 'd', 'e', 'h', 'l', 'l', 'l', 'o', 'o', 'r', 'w']
>>> list(reversed(x))
['.', 'd', 'l', 'r', 'o', 'w', ' ', 'o', 'l', 'l', 'e', 'h']
>>> list(enumerate(x))
[(0, 'h'), (1, 'e'), (2, 'l'), (3, 'l'), (4, 'o'), (5, ' '), (6, 'w'), (7, 'o'), (8, 'r'), (9, 'l'), (10, 'd'), (11, '.')]
>>> from operator import add
>>> list(map(add,x,x))
['hh', 'ee', 'll', 'll', 'oo', ' ', 'ww', 'oo', 'rr', 'll', 'dd', '..']
- 内置函数eval()用来把任意字符串转化为python表达式并进行求值
>>> eval("3+4")
7
>>> import math
>>> eval('math.sqrt(3)')
1.7320508075688772
12.字符串切片
- 切片也适用于字符串,但仅限于读取其中的元素,不支持字符串的修改
>>> 'Explicit is better than explicit.'[:8]
'Explicit'
>>> 'Explicit is better than explicit.'[9:23]
'is better than'
>>> path='C:\\python35\\test.bmp'
>>> path[:-4]+'_new'+path[-4:]
'C:\\python35\\test_new.bmp'
六、字符串常量
1.【例7-5】使用string模块提供的字符串常量,模拟生成指定长度的随机密码
>>> from random import choice
>>> from string import ascii_letters,digits
>>> characters=digits+ascii_letters
>>> def generatePassword(n):
... return ''.join((choice(characters) for _ in range(n)))
...
>>> print(generatePassword(8))
7RmAXQNF
>>> print(generatePassword(19))
Wwrf3unJrGiYIHUGh0T
七、中英文分词
>>> import jieba #导入jieba模块(中文分词扩展库,用于自然语言处理)
>>> x='分词的准确度直接影响了后续文本处理和挖掘算法的最终效果'
>>> jieba.cut(x) #使用默认词库进行分词
>>> list(_)
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\Lenovo\AppData\Local\Temp\jieba.cache
Loading model cost 1.070 seconds.
Prefix dict has been built successfully.
['分词', '的', '准确度', '直接', '影响', '了', '后续', '文本处理', '和', '挖掘', '算法', '的', '最终', '效果']
>>> list(jieba.cut('纸杯'))
['纸杯']
>>> list(jieba.cut('花纸杯'))
['花', '纸杯']
>>> jieba.add_word('花纸杯') #增加词条
>>> list(jieba.cut('花纸杯')) #使用新词库进行分词
['花纸杯']
>>> import snownlp #导入snownlp模块(中文分词扩展库,用于自然语言处理)
>>> snownlp.SnowNLP('学而时习之,不亦说乎').words
['学而', '时习', '之', ',', '不亦', '说乎']
>>> snownlp.SnowNLP(x).words
['分词', '的', '准确度', '直接', '影响', '了', '后续', '文本', '处理', '和', '挖掘', '算法', '的', '最终', '效果']
八、汉字到拼音的转换
>>> from pypinyin import lazy_pinyin,pinyin
>>> lazy_pinyin('胡歌') #返回拼音
['hu', 'ge']
>>> lazy_pinyin('胡歌',1) #带声调的拼音
['hú', 'gē']
>>> lazy_pinyin('胡歌',2) #另一种拼音形式,数字表示前面字母的声调
['hu2', 'ge1']
>>> lazy_pinyin('胡歌',3) #只返回拼音首字母
['h', 'g']
>>> pinyin('重阳') #能够根据词组智能识别多音字
[['chóng'], ['yáng']]
>>> pinyin('重阳节',heteronym=True) #返回多音字的所有读音
[['chóng'], ['yáng'], ['jié', 'jiē']]
>>> import jieba #其实不需要导入jieba,这里只是说明已安装
>>> x='中英文混合test124'
>>> lazy_pinyin(x) #自动调用已安装的jieba扩展库分词功能
['zhong', 'ying', 'wen', 'hun', 'he', 'test124']
>>> lazy_pinyin(jieba.cut(x))
['zhong', 'ying', 'wen', 'hun', 'he', 'test124']
>>> x='山东烟台的大樱桃真好吃啊'
>>> sorted(x,key=lambda ch:lazy_pinyin(ch)) #按拼音对汉字进行排序
['啊', '吃', '大', '的', '东', '好', '山', '台', '桃', '烟', '樱', '真']
九、综合案例分析
1.【例7-6】编写函数实现字符串加密和解密,循环使用指定密钥,采用简单的异或算法
>>> def crypt(source,key):
... from itertools import cycle
... result=''
... temp=cycle(key)
... #取出原文souce的每一个字符ch与密钥(循环用)进行异或^(需要转成Unicode码后运算)再转回字符
... for ch in source:
... result=result+chr(ord(ch)^ord(next(temp)))
... return result
...
>>> source='Shandong Institute of Business and Technology'
>>> key='Dong Fuguo'
>>> print('Before Encrypted:'+source) #显示原文
Before Encrypted:Shandong Institute of Business and Technology
>>> encrypted=crypt(source,key) #加密(将原文用密钥异或)
>>> print('After Encrypted:'+encrypted) #显示密文
After Encrypted: D)
>>> decrypted=crypt(encrypted,key) #解密
>>> print('After Decrypted:'+decrypted) #显示解密文(即原文)
After Decrypted:Shandong Institute of Business and Technology
2.【例7-7】编写程序,统计一段文字中每个词出现的次数
>>> from collections import Counter
>>> from jieba import cut
>>> def frequency(text):
... return Counter(cut(text))
...
>>> text='''寻寻觅觅,冷冷清清,凄凄惨惨戚戚。乍暖还寒时候,最难将息。三杯两盏淡酒,怎敌他、晚来风急!雁过也,正伤心,却是旧时相识。满地黄花堆积,憔悴损,如今有谁堪摘?守着窗儿,独自怎生得黑!梧桐更兼细雨,到黄昏、点点滴滴。这次第,怎一个愁字了得!'''
>>> print(frequency(text))
Counter({',': 11, '。': 4, '!': 3, '、': 2, '得': 2, '寻寻觅觅': 1, '冷冷清清': 1, '凄凄惨惨': 1, '戚戚': 1, '乍暖还寒': 1, '时候': 1, '最': 1, '难': 1, '将息': 1, '三杯': 1, '两盏': 1, '淡酒': 1, '怎敌': 1, '他': 1, '晚': 1, '来风': 1, '急': 1, '雁过': 1, '也': 1, '正': 1, '伤心': 1, '却是': 1, '旧时': 1, '相识': 1, '满地': 1, '黄花': 1, '堆积': 1, '憔悴': 1, '损': 1, '如今': 1, '有': 1, '谁': 1, '堪': 1, '摘': 1, '?': 1, '守着': 1, '窗儿': 1, '独自': 1, '怎生': 1, '黑': 1, '梧桐': 1, '更': 1, '兼': 1, '细雨': 1, '到': 1, '黄昏': 1, '点点滴滴': 1, '这次': 1, '第': 1, '怎': 1, '一个': 1, '愁字': 1, '了': 1})
3.【例7-8】检查并判断密码字符串的安全强度
import string
>>> def check(pwd):
... if not isinstance(pwd,str) or len(pwd)<6:
... return 'not suitable for password'
... #密码强度等级与包含字符种类的对应关系
... d={1:'week',2:'below middle',3:'above middle',4:'strong'}
... r=[False]*4
... for ch in pwd:
... if not r[0] and ch in string.digits:
... r[0]=True
... elif not r[1] and ch in string.ascii_lowercase:
... r[1]=True
... elif not r[2] and ch in string.ascii_uppercase:
... r[2]=True
... elif not r[3] and ch in ',.?!<>':
... r[3]=True
... return d.get(r.count(True),'error')
...
>>> print(check('aSsiw,. w12'))
strong