【linux--->网络层协议】
文章目录
-
- @[TOC](文章目录)
- 一、概念
-
- 1.网络层概念
- 2.IP地址概念
- 二、IP协议报文结构
-
- 1.首部长度
- 2.总长度(total length)
- 3.协议
- 4.版本号(version)
- 5.服务类型(Type Of Service)
- 6.生存时间间(Time To Live, TTL)
- 三、网段划分
-
- 1.5类IP划分法.
- 2.CIDR(Classless Interdomain Routing)划分方案
- 3.NAT技术
- 四、路由转发
- 五、报文分片
-
- 1.分片的由来
- 2.IP报文分片管理字段
- 3.接收端分片报文管理原理
- 4.tcp数据分包
- 六、相关命令
-
- 1.ifconfig查看主机IP地址,子网掩码,Mac地址,mtu最大传输单元
文章目录
-
- @[TOC](文章目录)
- 一、概念
-
- 1.网络层概念
- 2.IP地址概念
- 二、IP协议报文结构
-
- 1.首部长度
- 2.总长度(total length)
- 3.协议
- 4.版本号(version)
- 5.服务类型(Type Of Service)
- 6.生存时间间(Time To Live, TTL)
- 三、网段划分
-
- 1.5类IP划分法.
- 2.CIDR(Classless Interdomain Routing)划分方案
- 3.NAT技术
- 四、路由转发
- 五、报文分片
-
- 1.分片的由来
- 2.IP报文分片管理字段
- 3.接收端分片报文管理原理
- 4.tcp数据分包
- 六、相关命令
-
- 1.ifconfig查看主机IP地址,子网掩码,Mac地址,mtu最大传输单元
一、概念
1.网络层概念
网络层主要是负责执行,传输层策略的.传输层的发送不是真正意义上的发送数据,而是将封装好的协议向下交付给了网络层,有网络层执行传输层的传输策略.
2.IP地址概念
IP地址包含两个信息,一个是目标网络地址,一个是目标主机地址.目标网络用于找到目标主机所在的子网(局域网),主机地址用来定位主机.
主机和路由器都有路由控制功能,主机一般设置一个IP地址,路由器一般设置多个IP地址.主机和路由器都是网络中的节点.
二、IP协议报文结构

1.首部长度
首部长度占4个比特位,最大是16,首部内容包含可选字段,首部长度16*4字节-20字节是可选字段的长度.
2.总长度(total length)
总长度是真个IP协议报文的长度,占16个比特位,2^16-首部长度=数据部分.
3.协议
占8位比特位,这个字段定义了IP数据报的数据部分使用的协议类型。 常用的协议及其十进制数值包括ICMP (1)、TCP (6)、UDP (17)
4.版本号(version)
由于IPv6还没有公认化使用,所以版本号一般是表示为IPv4版本.
5.服务类型(Type Of Service)
占8位比特位,3位优先权字段(已经弃用), 4位TOS字段, 和1位保留字段(必须置为0). 4位TOS分别表示: 最小延时, 最大吞吐量, 最高可靠性, 最小成本. 这四者相互冲突, 只能选择一个. 对于ssh/telnet这样的应用程序, 最小延时比较重要; 对于ftp这样的程序, 最大吞吐量比较重要
6.生存时间间(Time To Live, TTL)
数据报到达目的地的最大报文跳数. 一般是64. 每次经过一个路由, TTL -= 1, 一直减到0还没到达, 那么就丢弃了. 这个字段主要是用来防止出现路由循环
三、网段划分
IP地址分为网络号和主机号,网络号和主机号组成一个唯一的IP地址,IP地址是一个32位的整数.也就是说IP地址有42亿多个,全球有60亿人,而且一个人手上可能有多个联网设备,所以IP地址需要合理的分配使用.
1.5类IP划分法.
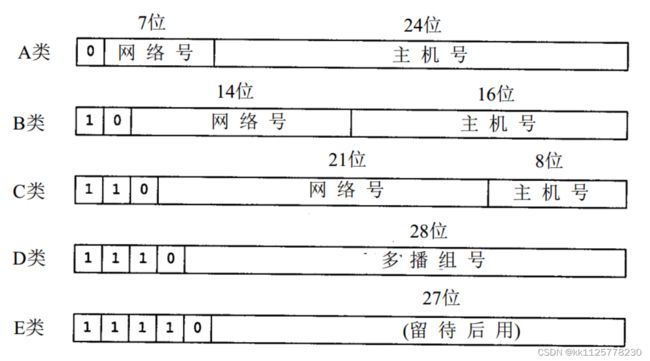
IP地址根据网络号和主机号来分,分为A、B、C三类及特殊地址D、E。 全0和全1的都保留不用。
A类:(1.0.0.0-126.0.0.0)(默认子网掩码:255.0.0.0或 0xFF000000)第一个字节为网络号,后三个字节为主机号。该类IP地址的最前面为“0”,所以地址的网络号取值于1~126之间。一般用于大型网络。
B类:(128.0.0.0-191.255.0.0)(默认子网掩码:255.255.0.0或0xFFFF0000)前两个字节为网络号,后两个字节为主机号。该类IP地址的最前面为“10”,所以地址的网络号取值于128~191之间。一般用于中等规模网络。
C类:(192.0.0.0-223.255.255.0)(子网掩码:255.255.255.0或 0xFFFFFF00)前三个字节为网络号,最后一个字节为主机号。该类IP地址的最前面为“110”,所以地址的网络号取值于192~223之间。一般用于小型网络。
D类:是多播地址。该类IP地址的最前面为“1110”,所以地址的网络号取值于224~239之间。一般用于多路广播用户[1] 。
E类:是保留地址。该类IP地址的最前面为“1111”,所以地址的网络号取值于240~255之间。
2.CIDR(Classless Interdomain Routing)划分方案
A、B、C、D类地址划分子网的概念导致网络号是固定的,可能会发生B类地址早就用完了,A类IP地址用不完,而又因为将一个网络号划分给了一个地区,其他地区无法使用这个网段的IP地址.浪费了IP地址.所以后来又提出了新的划分方案,CIDR
CIDR引入一个额外的子网掩码(subnet mask)来区分网络号和主机号;子网掩码也是一个32位的正整数,子网掩码不能单独使用,要与IP地址配合使用,唯一作用就是区分网络号和主机号;将IP地址和子网掩码进行 “按位与” 操作, 得到的结果就是网络号,IP地址与子网掩码的简洁表示方法:IP地址/子网掩码所占二进制位的个数.
CIDR技术可以根据实际情况,确定网络号所占的比特位,或者主机号所占的比特位,这样就不会造成IP地址的浪费;例如子网中有2000台主机,就需要2^11个IP地址,也就是说主机号要占用11个比特位,那么子网掩码就是255.255.248.0;
网络被分为一个一个的子网,子网又可以再往下继续分为多个子网,每个子网都有一个网络地址,网络地址主机号为全0的IP地址,用来标记子网在网络中的地址.一个网段的第一个可用IP地址是网络地址+1,最后一个IP地址是广播地址,可以将数据包通过这个地址转发给子网内多有主机,最后一个可用IP地址是广播地址-1.
网络中用IP标识一个主机,A主机与B主机通信,它们要互相能在网络中查找到对方IP地址,查找的本质就是排除,一次查找排除更多的IP地址才能使查找更加高效,一个好的数据结构和相应的查找算法决定了查找的高效.所有才有了现在的网络拓扑结构.IP地址的查找通过路由器的路由表中的网络号和子网掩码,一次可以排除一个子网.很快就能定位到目标主机所在子网.
3.NAT技术
全球有60亿人口,而IP地址是有限的,随着网民的增加,IP地址可定有不够用的一天,路由器的动态IP分配技术,有效的缓解了这个问题,就是IP地址与网络设备的关系不是固定的,每次链接都随机分配地址,解决了IP地址不适用时还被占用的问题.IPv6如果发展成熟,是能够彻底解决问题的,之所以到现在都没有普及,是因为有NAT(网络地址转换)技术,
网络拓扑结构中有公网和私网.IP也分为公网IP和私网IP.C1918规定用于组件局域网的私有IP,包含10.*前8位为网络号,172.16*—172.31*前12位为网络号,192.168.*前16位是网络号,出了这些其他的都是公网IP,私网IP是可以重复出现在不同的局域网中的,所以这也大大解决了IP数量不够的问题.
不同的局域网有相同的IP地址,在数据包转发的过程中就需要用到NAT技术了,每个路由器都有一个WAN口IP(外网IP),和LAN口IP(内网IP),.LAN口连接的是主机,WAN网连接上级子网.子网内的IP地址不能重复,但是子网之间的IP地址可以相同.内网的IP地址都是私网IP,像着样的内外网可能有好几层,最外层的运营商路由器是公网IP.跨网络通信时,首先要将LAN口IP转换为WAN口IP,一层一层的转换成公网IP就可以将数据包转发到公网中去了.
在路由器中维护着一个NATP(转换表),每当内网IP向外网通信时,需要将LAN口IP转换为WAN口IP,转换关系会存储在NATP表中,每条存储信息不仅仅有LANIP和WAN口IP还有目的IP以及网络进程端口号.有端口号是因为在内网,一个客户端主机上可能有多个网络进程,所以要用端口区分,确保这条报文在内网是唯一的.但是在外网来看可能不同主机的网络进程使用同一个端口号,所以为了区分在外网可能还会更改端口号,确保在外网这个是唯一网络进程的标识.维护目的IP的意义在于,不让外网的设备任意访问内网主机,当有目的IP地址时,外网发送报文的主机不是目的主机IP时,报文是不会被转发到内网中去的.因为在转换表中找不到对的映射关系.这种关联关系也是由NAT路由器自动维护的. 例如在TCP的情况下, 建立连接时, 就会生成这个表项; 在断开连接后, 就会删除这个表项
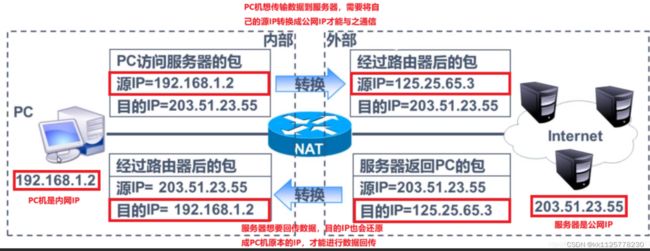
缺点:由于NAT依赖这个转换表, 所以有诸多限制:无法从NAT外部向内部服务器建立连接;装换表的生成和销毁都需要额外开销;通信过程中一旦NAT设备异常, 即使存在热备, 所有TCP连接也都会断开
四、路由转发
使用route命令可查看主机路由表

destination网络地址和genmask子网掩码,相与用来确认下一个目标网络区域,这个目标网络区域包含,目标主机地址,或者网络地址,或者子网地址,或者默认网关地址.
gateway网关 ,网络通信关口,路由器,网关IP就是路由器IP.
metric(跃点数),就是到达目标网络区域要经过的路由器的个数,当同一个目标网络区域有多条路由,tcp/ip会选择跃点数最小的一个.
iface:网络接口.
Flags中的U标志表示此条目有效(可以禁用某些 条目),G标志表示此条目的下一跳地址是某个路由器的地址,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发;
IP数据包每到达一个路由器,路由器就会查一次路由表,将网络地址按位与子网掩码后的结果与目的IP地址比较,如果目的IP地址就在局域网中,就直接转发给目标主机,如果不在本地网中,需要经过路由器就是,将数据包转发给下一跳路由器.如果没有就直接走缺省地址,直接转发给网关地址.每一个网络地址都对应一个iface发送接口.
五、报文分片
1.分片的由来
数据链路层有MTU的概念,MTU是最大传输单元的意思,它限制了最大传输帧长度,超过了这个长度数据包就要被分片.以太网的传输帧长是1500,所以MTU的长度一般是1500.
2.IP报文分片管理字段
IP报文中有与分片相关的三个字段16位标识(id): 唯一的标识主机发送的报文. 如果IP报文在数据链路层被分片了, 那么每一个片里面的这个id都是相同的.
3位标志字段: 第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要用到). 第二位置为1表示禁止分片, 这时候如果报文长度超过MTU, IP模块就会丢弃报文. 第三位表示"更多分片", 如果分片了的话, 最后一个分片置为0, 其他是1. 类似于一个结束标记.
13位分片偏移(framegament offset): 是分片相对于原始IP报文开始处的偏移. 其实就是在表示当前分片在原报文中处在哪个位置. 实际偏移的字节数是这个值 * 8 得到的. 因此, 除了最后一个报文之外, 其他报文的长度必须是8的整数倍(否则报文就不连续了).
3.接收端分片报文管理原理
1.接收端用源IP地址来区分是那个主机发来的分片报文.
2.用第3位标志位是否是1或者偏移是否大于0,来确认报文是否被分片.
3.用第三个标志位是否为1,偏移是否为0,来确认是否为第一个报文;用第三个标志位是否为1,偏移是否大于0,来确认是否是中间的报文;用第三个标志位是否为0,偏移是否大于0,来确认是否是最后一个报文;将收到的报文按照偏移排序就还原了报文.
4.收到的分片报文可以根据偏移字段和第三个标志位确定的第一个和最后一个报文是否丢包,可以根据偏移量+报文总长度确定下一个分片报文的首部偏移,从而确定下一个报文是否丢包.
5.传输层协议有16位校验和用来检查整个报文的正确性,IP协议有16位首部校验和,传输层协议相当于IP协议的有效载荷,所以传输层与IP协议相互配合可以检查收到报文的正确性.
4.tcp数据分包
如果分片报文丢失了,tcp会认为整个报文丢失,重发整个报文,分片会增加丢包率,所以分片是网络中的少数情况,最好的解决方案就是控制tcp封装的报文大小,数据链路层数据包最大不超过1500,数据链路层数据包就是IP报文,IP有固定大小的报头20个字节,所以数据包的大小就不能超过1480,IP数据包就是tcp报文,tcp报文固定报头20个字节,那么数据包大小就需要不超过1460.
六、相关命令
1.ifconfig查看主机IP地址,子网掩码,Mac地址,mtu最大传输单元
