Python操作word基础

在办公自动化的操作,往往可能会存在Word的操作。因为在办公 时,对文档的操作是必不可少的。而在Python操作Word时,可以 使用一个三方的模块库 Python-docx
安装
pip install python-docx
常用方法与属性

from docx import Document
def create_word():
# 创建word文档
doc1 = Document()
# 增加标题
doc1.add_heading('欢迎使用Python创建Word',0)
doc1.add_heading('Python操作 增加1级标题',1)
doc1.add_heading('Python操作 增加2级标题',2)
# 保存文档
doc1.save('./create_data/01_创建word文档.docx')
if __name__ == '__main__':
create_word()
Word写入段落数据
常用方法与属性

from docx.enum.style import WD_BUILTIN_STYLE
def create_word():
from docx import Document
# 创建一个word文档
doc1 = Document()
# 增加段落信息
doc1.add_paragraph('Python第一阶段','Title')
# doc1.add_paragraph('Python第一阶段',style = 'Title')
par1 =doc1.add_paragraph('本阶段是进入“程序员”的门槛,需要学习编程基本的知识。本阶段会从0开始,循序渐进。让小伙伴们学完本阶段,可以掌握:变量、数据类型、控制语句、容器、函数和面向对象等。教程中会穿插一些有趣的案例,寓教于乐,引起大家的兴趣。 ')
# 给段落后面追加内容
par1.add_run('“兴趣永远是好的老师”。')
doc1.add_paragraph('本阶段是进入“程序员”的门槛,需要学习编程基本的知识。本阶段会从0开始,循序渐进。让小伙伴们学完本阶段,可以掌握:变量、数据类型、控制语句、容器、函数和面向对象等。教程中会穿插一些有趣的案例,寓教于乐,引起大家的兴趣。 “兴趣永远是好的老师”。')
# 增加列表-无序
doc1.add_paragraph('哪个不是动物:')
doc1.add_paragraph('喜洋洋',style='List Bullet')
doc1.add_paragraph('美羊羊',style='List Bullet')
doc1.add_paragraph('懒洋洋',style='List Bullet')
doc1.add_paragraph('苹果',style='List Bullet')
doc1.add_paragraph('灰太狼',style='List Bullet')
# 增加列表-有序
doc1.add_paragraph('今年的学习计划:')
doc1.add_paragraph('Python',style='List Number')
doc1.add_paragraph('HTML',style='List Number')
doc1.add_paragraph('JS',style='List Number')
doc1.add_paragraph('Flask',style='List Number')
# 增加引用
doc1.add_paragraph('这个是一个引用内容',style='Intense Quote')
# 保存word文档
doc1.save('./create_data/02_增加段落.docx')
if __name__ =='__main__':
create_word()
Word增加图片
常用方法与属性

def create_word():
from docx import Document
# 创建一个文档
doc1 = Document()
# 增加图片
pic = doc1.add_picture('./base_data/backg.jpg')
# 获取文档的宽度
page_width = doc1.sections[0].page_width
# 获取文档的左边距
page_left_width = doc1.sections[0].left_margin
print(page_width)
print(page_left_width)
# 获取中间内容的宽度
content_width = page_width-page_left_width*2
print(content_width)
# 获取图片应该缩小的比例
# 如果图片或者页面宽度值太高,有可能程序无法计算,可以考虑同时缩小几倍
sc =(content_width/100)/(pic.width/100)
# 修改图片的宽、高
pic.width = int(pic.width*sc)
pic.height = int(pic.height*sc)
# 保存文档
doc1.save('./create_data/03_增加图片.docx')
if __name__ == '__main__':
create_word() 
Word增加表格
常用方法与属性

def create_table():
from docx import Document
# 创建word文档
doc1 = Document()
# 增加表格
table = doc1.add_table(rows=1,cols=3)
# 设置表格的内容
cells = table.rows[0].cells
cells[0].text = '编号'
cells[1].text = '姓名'
cells[2].text = '职业'
data = (
(1,'吕小布','将军'),
(2,'诸葛亮','军事'),
(3,'刘备','主攻'),
)
for i,n,w in data:
# 增加一行数据
tmp_cell = table.add_row().cells
'''
问题1:
tmp_cell[0] = i
TypeError: 'tuple' object does not support item assignment
有可能是直接给单元格设置内容了!需要给text属性设置内容
'''
'''
问题2:
for char in text:
TypeError: 'int' object is not iterable
给单元格设置值,不能是数字,需要转成str
'''
tmp_cell[0].text = str(i)
tmp_cell[1].text = n
tmp_cell[2].text = w
# 保存文档
doc1.save('./create_data/04_增加表格.docx')
if __name__ =='__main__':
create_table()
Word设置文字样式
常用方法与属性

注意
我们在写word的时候,一般英文采用Arial和新罗马字体,中文 是宋体和黑体 w:eastAsia是东亚的意思。应该是规定使用中文字体时确认“微 软雅黑”是哪个地方的微软雅黑 记住即可
def use_style():
from docx import Document
from docx.shared import Pt,Inches,RGBColor
# 创建文档
doc1 = Document()
# 设置加粗
p1 = doc1.add_paragraph('这是段落1:\n')
p1.runs[0].font.bold=True
# 加粗
p1.add_run('这是内容1.1_加粗\n').font.bold=True
# 斜体
p1.add_run('这是内容1.2_斜体\n').font.italic = True
# 删除线
p1.add_run('这是内容1.3_删除线\n').font.strike = True
# 阴影
p1.add_run('这是内容1.4_阴影\n').font.shadow = True
# 字体大小
p1.add_run('这是内容1.5_字体大小\n').font.size = Pt(30)
# 颜色 rgb三原色 0-255
p1.add_run('这是内容1.6_颜色\n').font.color.rgb = RGBColor(255,100,76)
# 字体
# p1.add_run('这是内容1.7_字体\n').font.name='微软雅黑' # 只写这个设置不成功的
run = p1.add_run('这是内容1.7_字体\n')
from docx.oxml.ns import qn
'''
AttributeError: 'NoneType' object has no attribute 'rFonts'
直接设置字体,会报错,需要先声明字体名称
'''
run.font.name=''
run._element.rPr.rFonts.set(qn('w:eastAsia'),'微软雅黑')
doc1.save('./create_data/05_设置字体样式.docx')
if __name__ == "__main__":
use_style() 
Word设置段落样式
常用方法与属性

def use_style():
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
# 创建文档
doc1 = Document()
# 段落居中
doc1.add_paragraph('这是段落1:').paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 设置整段离左侧距离
doc1.add_paragraph('Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是...').paragraph_format.left_indent = Pt(50)
# 设置首行左侧距离
doc1.add_paragraph('Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是...').paragraph_format.first_line_indent = Pt(50)
# 段落离上面的距离
doc1.add_paragraph('这是段落2:').paragraph_format.space_before=Pt(30)
# 段落离下面的距离
doc1.add_paragraph('这是段落3:').paragraph_format.space_after=Pt(30)
# 设置行间距
doc1.add_paragraph('这是段落4:')
doc1.add_paragraph('Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是...').paragraph_format.line_spacing = Pt(50)
doc1.save('./create_data/06_设置段落样式.docx')
if __name__ =='__main__':
use_style() 
Word生成通知书

from docx import Document
from docx.shared import Pt,RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
def create_book():
# 生成一个文档
doc1 = Document()
# 增加标题
title = doc1.add_paragraph()
run = title.add_run('录取通知书')
# 设置标题的样式
run.font.size = Pt(30)
run.font.color.rgb = RGBColor(255,0,0)
run.font.name = ''
run._element.rPr.rFonts.set(qn('w:eastAsia'),'黑体')
title.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 增加内容
doc1.add_paragraph('张三 同学:')
content1 = doc1.add_paragraph('兹录取你入我校 人工智能技术 专业类学习。请凭本通知书来报道。具体时间、地点见《新生入学须知》。')
# 设置内容样式
content1.paragraph_format.first_line_indent = Pt(30)
# 落款
footer = doc1.add_paragraph('清华大学\n')
footer.add_run('二0三0年八月十号')
footer.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 保存文档
doc1.save('./create_data/07_录取通知书.docx')
def create_book2(name,major,school,_time):
# 生成一个文档
doc1 = Document()
# 增加标题
title = doc1.add_paragraph()
run = title.add_run('录取通知书')
# 设置标题的样式
run.font.size = Pt(30)
run.font.color.rgb = RGBColor(255,0,0)
run.font.name = ''
run._element.rPr.rFonts.set(qn('w:eastAsia'),'黑体')
title.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 增加内容
doc1.add_paragraph(f'__{name}__ 同学:')
content1 = doc1.add_paragraph(f'兹录取你入我校 __{major}__ 专业类学习。请凭本通知书来报道。具体时间、地点见《新生入学须知》。')
# 设置内容样式
content1.paragraph_format.first_line_indent = Pt(30)
# 落款
footer = doc1.add_paragraph(f'{school}\n')
footer.add_run(f'{_time}')
footer.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 保存文档
doc1.save(f'./create_data/07_录取通知书_{name}.docx')
if __name__ == '__main__':
# create_book()
create_book2('吕布','人工智能技术','清华大学','二0三0年八月十号')其中有两个版本,第一个是写死的,第二个是根据不同的信息进行修改


Word读取内容

常用方法与属性
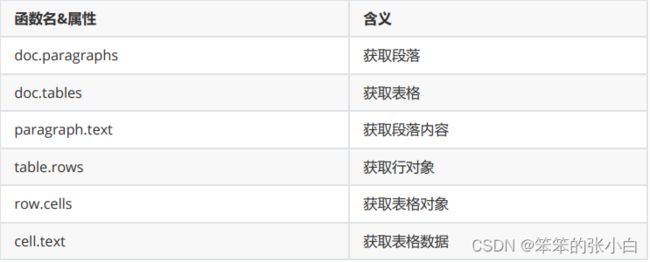
from docx import Document
def read_word():
# 打开文档
doc1 = Document('./base_data/原数据.docx')
# 读取数据-段落
for p in doc1.paragraphs:
print(p.text)
# 读取表格
for t in doc1.tables:
for row in t.rows:
for c in row.cells:
print(c.text,end=' ')
print()
if __name__ == '__main__':
read_word()Word通过模板生成文档
from docx import Document
def create_word(_data):
# 打开文档
doc1 = Document('./base_data/word_模板.docx')
# 读取里面的数据
for p in doc1.paragraphs:
# 替换新数据 如果直接级paragraph的text替换内容,会丢失样式
# p.text = p.text.replace('{0}','000001')
# p.text = p.text.replace('{1}','2030')
# p.text = p.text.replace('{2}','01')
# p.text = p.text.replace('{3}','01')
# p.text = p.text.replace('{4}','01')
# p.text = p.text.replace('{5}','01')
# p.text = p.text.replace('{6}','闯红灯')
# p.text = p.text.replace('{7}','600')
for run in p.runs:
run.text = run.text.replace('{0}',_data[0])
run.text = run.text.replace('{1}',_data[1])
run.text = run.text.replace('{2}',_data[2])
run.text = run.text.replace('{3}',_data[3])
run.text = run.text.replace('{4}',_data[4])
run.text = run.text.replace('{5}',_data[5])
run.text = run.text.replace('{6}',_data[6])
run.text = run.text.replace('{7}',_data[7])
# 保存新文件
doc1.save(f'./create_data/09_模板生成文档_{_data[0]}.docx')
if __name__ == '__main__':
data = [
('00001','2030','01','01','01','01','闯红灯','600'),
('00002','2030','02','01','01','01','违反禁令','300'),
('00003','2030','03','01','01','01','违章停车','300'),
('00004','2030','04','01','01','01','挑线','100'),
('00005','2030','05','01','01','01','没礼让行人','300'),
]
for d in data:
create_word(d)
# print(d)
Word转换PDF

使用office组件将word转换成PDF文件(缺点:只支持windows平 台) 原理:使用python win32 库 调用word底层vba,将word转成pdf
安装
pip install pywin32
本地选装 office 套件,可以安装比较稳定的版本

from win32com.client import gencache
from win32com.client import constants, gencache
def createPdf(wordPath, pdfPath):
"""
word转pdf
:param wordPath: word文件路径
:param pdfPath: 生成pdf文件路径
"""
word = gencache.EnsureDispatch('Word.Application')
doc = word.Documents.Open(wordPath, ReadOnly=1)
doc.ExportAsFixedFormat(pdfPath,
constants.wdExportFormatPDF,
Item=constants.wdExportDocumentWithMarkup,
CreateBookmarks=constants.wdExportCreateHeadingBookmarks)
word.Quit(constants.wdDoNotSaveChanges)
if __name__ == "__main__":
# 路径填写绝对路径
createPdf(
r'D:\code\python\auto_code_word\base_data\原数据.docx',
r'D:\code\python\auto_code_word\create_data\10_word转换成pdf.pdf'
)
# 命令要安装pywin32模块,命令:pip install pywin32Python操作Word模块库文档

