卷积神经网络实现MNIST手写数字识别 - P1
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:365天深度学习训练营-第P1周:实现mnist手写数字识别
- 原作者:K同学啊 | 接辅导、项目定制
- 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
-
- 环境设置
-
- 引用需要的包
- 设置GPU
- 数据准备
-
- 下载数据集
- 数据集预览
- 数据集准备
- 模型设计
- 模型训练
-
- 超参数设置
- helper函数
- 正式训练
- 结果呈现
- 总结与心得体会
环境
- 系统:Linux
- 语言: Python 3.8.10
- 深度学习框架:PyTorch 2.0.0+cu118
步骤
环境设置
引用需要的包
Python写程序都需要做的事
import torch # 有些API直接在模块下
import torch.nn as nn # 大部分和模型相关的API
import torch.optim as optim # 优化器相关API
# 一些可以直接调用的函数封装(和nn下的很多方法是一样的效果不同的形式)
import torch.nn.functional as F
from torch.utils.data import DataLoader # 数据集做分批,随机排序
from torchvision import datasets, transforms # 预置数据集下载,数据增强
import matplotlib.pyplot as plt # 图表库
import numpy as np # 用来操作numpy数组,图像展示用
from torchinfo import summary # 打开模型结构
设置GPU
首先用一个全局的对象设置一下当前的设备,是使用CPU还是CPU
# 有显卡就用显卡,没有就用CPU
device = torch.device('cuda'if torch.cuda.is_available() else 'cpu')
数据准备
下载数据集
调用torchvision包预置的API可以一键下载MNIST数据集
train_dataset = datasets.MNIST(
root='data', # 数据存放位置
train=True, # 加载训练集还是验证集
download=True, # 本地没有是否从远程下载
transform=transforms.ToTensor()) # 载入后将图像转换成pytorch的tensor对象
test_dataset = datasets.MNIST(
root='data',
train=False, # False说明是验证集
download=True,
transform=transforms.ToTensor())
数据集预览
先看看数据集中图像的样子,比如是单通道还是三通道,长宽是多少,然后就可以设置缩放以及模型的一些参数
image, label = train_dataset[0]
image.shape
![]()
结果表明数据集中的图片应该是单通道的高28宽28的图像
打印里面20个图看看是什么样的
plt.figure(figsize=(20, 4)) # 设置一个plt图表画板的宽和高,单位是英寸。。
for i in range(20):
image, label = train_dataset[i]
plt.subplot(2, 10, i+1) # 以2行10列的形式展示图片
# 先把tensor转为了numpy数组,然后把(1, 28, 28)第0维用squeeze去掉
# cmap=plt.cm.binary说明是一个单通道的灰度图
plt.imshow(np.squeeze(image.numpy()), cmap=plt.cm.binary)
plt.title(label) # 打印一下对应的标签
plt.axis('off') # 不显示坐标轴
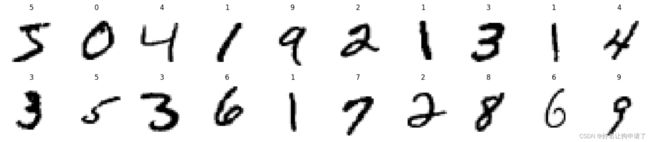
数据集准备
设置一下数据的批次大小
batch_size = 32
# 训练集上将数据的顺序打乱一下
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
test_loader= DataLoader(test_dataset, batch_size=batch_size)
模型设计
采用一个类似于LeNet的小型卷积网络
class Model(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 定义两个卷积层,核都是3x3的,通道数递增
self.conv1 = nn.Conv2d(1, 16, kernel_size=3)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3)
# 池化层没有参数需要学习,可以复用一个
self.maxpool = nn.MaxPool2d(2)
# 全连接层的输入维度要结果计算,可以在forward的时候算一下
self.fc1 = nn.Linear(5*5*32, 128)
# 最后一层的输出得是分类的数量
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
# 28x28 -> conv1 -> 26x26 -> maxpool -> 13x13
x = self.maxpool(F.relu(self.conv1(x)))
# 13x13 -> conv2 -> 11x11 -> maxpool -> 5x5
x = self.maxpool(F.relu(self.conv2(x)))
# 这里要进全连接层了,需要把数据压平,保留第0维,从第1维开始压
x = torch.Flatten(start_dim=1)
x = F.relu(self.fc1(1))
# 最后一层就不加激活函数了
x = self.fc2()
# 将模型创建后,设备设置为上面定义的设备对象
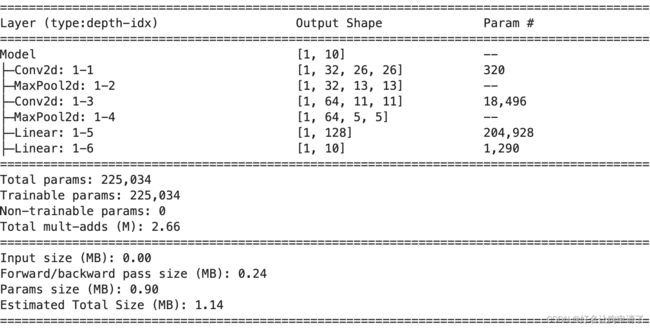
model = Model(10).to(device)
# 一定要加input_size,不然打印的就不是实际执行的样子,而是按self中定义的顺序,复用的组件也展示不出来
summary(model, input_size(1, 1, 28, 28))
模型训练
接下来就到了训练模型的环节了
超参数设置
需要设置的超参数有训练的轮次epoch和学习率learning_rate
# 轮次
epochs = 10
# 学习率
larning_rate = 0.001
# 创建优化器,将模型参数进去,并设置学习率
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 分类问题,无脑使用交叉熵损失
loss_fn = nn.CrossEntropyLoss()
helper函数
编写两个函数用来封装模型训练和模型验证的过程
- 模型训练
def train(train_loader, model, loss_fn, optimizer):
size = len(train_loader.dataset) # 训练总数据量
num_batches = len(train_loader) # 批次数量
train_loss, train_acc = 0, 0 # 记录并返回本次训练过程的状态数据
for x, y in train_loader:
x, y = x.to(device), y.to(device) # 将数据加载到和模型相同的设备中,不然取不到值
preds = model(x) # 这样模型会自动调用forward并进行一些参数的跟踪操作等
loss = loss_fn(preds, y) # 计算当前批次的损失
optimizer.zero_grad() # 清空之前训练时产生的梯度
loss.backward() # 在损失函数上对参数执行反向传播计算梯度
optimizer.step() # 执行参数更新操作
# 累加当前数据
train_loss += loss.item()
# 计算正确数需要使用argmax求概率最大的一个分类然后和ground truth比较
train_acc += (preds.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches # 因为一个批次只计算一次损失,求平均值
train_acc /= size # 正确率是在总数上计算的
return train_loss, train_loss # 返回数据
- 模型验证
# 基本上就是train函数的简化
def test(test_loader, model, loss_fn):
size = len(test_loader.dataset)
num_batches = len(test_loader)
test_loss, test_acc = 0, 0
for x, y in test_loader:
x, y = x.to(device), y.to(device)
preds = model(x)
loss = loss_fn(preds, y)
test_loss += loss.item()
test_acc += (preds.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss, test_acc
正式训练
开始正式训练,其实也可以封装成一个helper
# 记录训练过程的数据
train_loss, train_acc = [],[]
test_loss, test_acc = [],[]
for epoch in range(epochs):
model.train() # 切换模型为训练模式
epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)
model.eval() # 切换模型为评估模式
epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)
# 记录本轮次数据
train_loss.append(epoch_train_loss)
train_acc.append(epoch_train_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
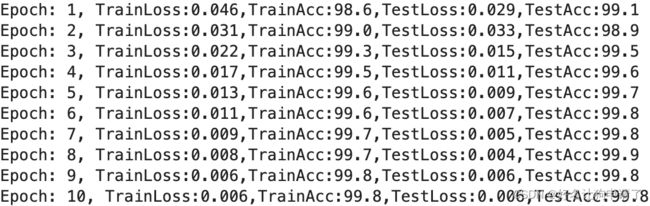
# 打印本轮次的数据信息
print(f"Epoch:{epoch+1}, Train loss: {epoch_train_loss:.3f}, Train accuracy: {epoch_train_loss*100:.1f}, Validation loss: {epoch_test_loss:.3f}, Validation accuracy: {epoch_test_acc*100:.1f}")
结果呈现
上面打印的结果不够直观我们可以用折线图打印一下
plt.figure(figsize=(16, 4))
series = range(epochs)
plt.subplot(1, 2, 1) # 一排两个图表
plt.plot(series, train_loss, label='train loss')
plt.plot(series, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(1, 2, 2)
plt.plot(series, train_acc, label='train accuracy')
plt.plot(series, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')

总结与心得体会
通过整个过程可以发现,手写数字的识别还是非常简单的,训练的效率比较快,结果也不错。非常适合拿来练手,学习一些基本概念、深度学习框架和分类任务实践过程等。