Excel 单表单列、单表多列、多表单列数据的条件去重罗列
文章目录
- 前言
- 一、应用场景
- 二、核心内容
-
- 2.1.if()
- 2.2.countif()
- 2.3.row(),column()
- 2.4.text()
- 2.5.主函数
- 三、使用步骤
-
- 3.1.单表单列、单表多列条件去重罗列
- 3.2.多表单列条件去重罗列
- 四、效果验证
-
- 1.单表单列、单表多列去重罗列
- 2.多表单列去重罗列
- 总结
前言
日常工作中需要度娘很多知识点或者方法,但每次用了就忘,下次遇到就需要继续度娘,故在此记录能解决相关问题的文章并做简单的个人理解,以此达到加深印象,分享知识的目的。
一、应用场景
工作中有时需要将某些条件下的数据去重罗列出来,而需要去重罗列的区域可能是一列,也可能是多列,也可能是多个表的一列数据,也可能是多个表的多列数据,而使用手动去重的方式,需要每次都进行筛选,然后手动复制粘贴出来,再进行去重后合并,太过于繁琐,不够高效。
因此考虑使用公式来制作一个模板,根据不同的需求使用不同的模板,以此来实现快速去重的目的。
读者可自行创建相应数据来匹配公式的使用,依次理解和应用本文内容,使用数据如下:
1.单表去重罗列数据

2.多表去重罗列数据

二、核心内容
2.1.if()
if()函数是通过某些条件得到一个数组的常用的一种函数,博主在之前的一片博文中有大概讲了下个人的一些理解,它其实跟高数里学的矩阵很像,将矩阵的思维代入数组函数中就很好理解了。
链接:https://blog.csdn.net/xiao_chuai/article/details/121922944
在其中的“一、EXCEL 公式实现多个条件值匹配”,有介绍
2.2.countif()
众所周知,countif()是一个条件统计函数,返回区域内符合条件的值的个数的和,因此大多数使用形式都是例如countif(A1:A10,B1),也就是统计A1:A10这个区域里,等于B1的值的个数。
这是较为普遍的一个应用,那有没有一种可能:把值填入区域,把区域填入值,那会是什么效果呢?
我对于countif()的运算原理的推断是:将条件和区域都看成一个矩阵,然后按照先左后右,先上后下的顺序,将条件矩阵中的值一个个拎出来,去统计在区域矩阵中的个数,然后令其对应位置等于其统计的结果。既然是矩阵,那就可能存在条件矩阵大于区域矩阵的情况和条件矩阵小于区域矩阵的情况。
这里以两个数据为例:
 结论:由上图可见,countif()的运算原理,从结果出发,跟我的推断是一致的,即“若条件矩阵中的值存在于区域矩阵,则统计其数量并代替对应其对应位置,否则为0”,那么就会返回一个跟条件矩阵相同大小的结果矩阵。
结论:由上图可见,countif()的运算原理,从结果出发,跟我的推断是一致的,即“若条件矩阵中的值存在于区域矩阵,则统计其数量并代替对应其对应位置,否则为0”,那么就会返回一个跟条件矩阵相同大小的结果矩阵。
注:
1.concat()合并矩阵内元素的原理是先左后右,先上后下,且要使用数组三键。
2.若条件是个区域,也就是条件不是一个单元格,好像结果都是0,所以countif()的实际的运算原理肯定不是我推断的那样,我只是以矩阵的形式,将“当区域和条件都是一个矩阵时,countif()的运算原理”展示出来,方便读者理解。
2.3.row(),column()
row(),column()的作用是返回目标单元格的行序号和列序号。
这里讲下这两个函数在if()型数组公式的作用:返回if()第一步“测试条件”得到的逻辑矩阵中每个元素对应的行序号和列序号。
测试数据如下:

如图所示,
IF(E3:G9=I3,ROW(E3:G9),0)返回的都是E3:G9区域内所有等于1的单元格的行序号;
IF(E3:G9=J3,COLUMN(E:G),0)返回的都是E3:G9区域内所有等于2的单元格的列序号。
其原理如下:
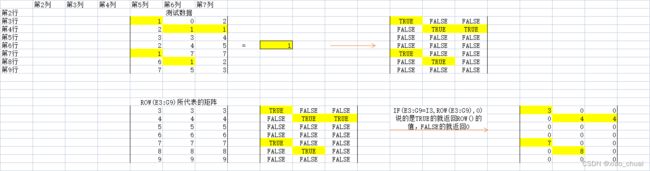 IF(E3:G9=J3,COLUMN(E:G),0)原理也是如上类似的。
IF(E3:G9=J3,COLUMN(E:G),0)原理也是如上类似的。
2.4.text()
TEXT函数的主要功能是按照指定的格式将数字转换为文本,其语法结构为:TEXT(value,format_text)。这是他的基本功能。
这边讲下它与row()、colunmn()在数组公式中的应用:通过
text(row([目标区域])*100+colunmn([目标区域]),“R0C00”)
可以将原本都是数字的行列坐标转化为"R0C00"这样的可引用的单元格地址。
但需要注意:
1.需配合indirect()使用,即indirect(text(row([目标区域])*100+colunmn([目标区域]),“R0C00”))。
2.注意目标区域的列数大小,“R0C00”,是指在右边数起第二个数字和第三个数字之间插入"C",在第一个数字前面插入"R"。例如:TEXT(14*100+2,“R0C00”)=TEXT(1402,“R0C00”)=R14C02,这时*100的作用就出来了:令行坐标始终保持在右边数起第二个位置之前,这样就能通过TEXT([数据],“R0C00”)这样的形式将数据转化为准确的、需求的单元格地址。但如果目标区域的列数大于100呢?例如:第14行,第102列的数据
=TEXT(14*100+102,“R0C00”)=TEXT(1502,“R0C00”)=R15C02,由R15C02可以看出,结果是第15行第2列,跟我们想要的数据不符合。
因此,当你的目标区域的列数大于100时,就要注意把*100变成*1000,且"R0C00"也要写成"R0C000"的形式。而当你这样写"R0C0"时,说明你的目标区域是小于10列的,此时*100要改成*10,当目标区域变化成大于10列时,对应的数据也要更改。
**
其实,可以把1402理解成行坐标和列坐标组成的字符串,然后通过"R0C00"去将它们划分开。
**,测试数据如下:
TEXT(14*1000+2,“R0C000”)=TEXT(14002,“R0C000”)=R14C002,正确。
TEXT(14*1000+102,“R0C000”)=TEXT(14102,“R0C000”)=R14C102,正确。
注:R和C之间一定要有至少1个0,C才是把数值划分开的重点位置,而R是始终在第一个数字之前。
2.5.主函数
=INDIRECT(TEXT(MIN(IF((COUNTIF(D$1:D1,[目标区域])=0)*([目标区域]<>“”),ROW([目标区域])*100+COLUMN([目标区域]),4^8)),“R0C00”),)&“”
这是实现功能的主函数,前面已经对公式内各个函数的作用做了分析,这里讲下每个函数在这个主函数中的作用:
1.INDIRECT():将内层函数得到的形如"R0C00"这样的单元格地址,返回其对应的单元格数据。
2.TEXT():将内层得到的数据转化为"R0C00"的形式,使其能成为被INDIRECT()引用的数据。
3.MIN():这个函数主要是做“去重”的作用的,当目标区域中有很多个符合条件的,那就会返回多个“1402”这样的行列坐标数据组成的数组,那么就取最小的那个,最小那就代表唯一,唯一就代表去重了。
4.IF():将目标区域的数据按条件区分开来,实现数组化,然后再通过合适的函数找到目标数据,数组公式最重要的思想就是想办法把目标区域数组化,才方便使用其他函数逐渐得到目标数据。
5.COUNTIF(D$1:D1,[目标区域])=0):这里之前已经讲过COUNTIF()的作用了,现在讲讲"D$1:D1"这个设定,这个是实现将数据唯一地罗列出来的设定,以下图为例:

D2处输入公式,那由图可知,D$1:D1可以看成一个1 X 1的矩阵,矩阵内数据只有“去重罗列”这个,它不存在于目标区域中,此时的COUNTIF(D$1:D1,[目标区域])=0)会得到一个全是TRUE的矩阵。通过min(row()*100+column())的作用,会得到201是最小的,也就是R2C1,也就是A2的数据,也就是1,那此时1就从目标区域中被罗列出来了。
然后下拉公式后,由于D$1:D1只有前半部分是被固定了,后半部分的D1没有被固定,到了D3时,公式变为COUNTIF(D$1:D2,[目标区域])=0),此时D$1:D2是一个2行1列的2 X 1的矩阵,矩阵内数据有{“去重罗列”,“1”}这两个,而1存在于目标区域了,根据前面关于countif()的介绍,1在目标区域中的位置所返回的就是一个FALSE,也就不会对应返回对应的行列坐标数据。那么2所在的202就是最小的了,也就是R2C2,也就是B2,也就是2,就会被罗列出来。
6.[目标区域]<>“”: 为了去除空白单元格。
7.ROW([目标区域])*100+COLUMN([目标区域]) :前面讲过了,是为了返回一个能被行列坐标组成的数据。
8.4^8 :这是if()的假值的返回,是必须的,因为要返回一个实际的数值型数据,才能使得min()不出错。而4^8 = 65536,这是xls的最大行数,xlsx的最大行数会是百万行的,设置成这个主要是大多数数据都不会超过65536行,若是超过了,读者可设置更大的数据,当然,更大的数据,用这个函数计算起来就会特别卡,还不如用python。
三、使用步骤
3.1.单表单列、单表多列条件去重罗列
以如下数据为例,读者自己数据需要自己做调整。

1.在目标单元格中输入如下公式:
=INDIRECT(TEXT(MIN(IF((COUNTIF(D$1:D1,$A$2:$B$44)=0)*($A$2:$B$44<>“”),ROW($2:$44)*100+COLUMN(A:B),4^8)),“R0C00”),)&“”
然后ctrl + shift + enter 数组三键
2.手动调整公式覆盖区域的大小,确保覆盖所有数据;手动调整公式中一些参数的值。例如*100和"R0C00"。
3.公式下拉到目标区域的行数乘列数的积的行数(确保能把所有值罗列出来)。
3.2.多表单列条件去重罗列
以如下数据为例,读者自己数据需要自己做调整。
主表数据:

表1数据:
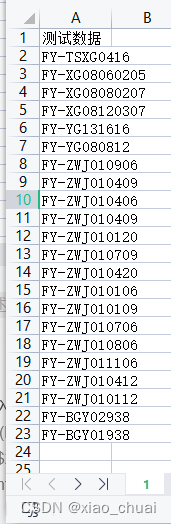
表2数据:

表3数据:

1.在目标单元格中输入如下公式:
=INDIRECT(TEXT(MIN(IF(COUNTIF(A$1:A1,T(INDIRECT({1,2,3}&“!A”&ROW($2:$44)))),4^8,{1,2,3}*1000+ROW($2:$44))),“0\!A000”))&“”
然后ctrl + shift + enter 数组三键
多表去重罗列公式与单表去重罗列有一些区别:
(1)countif()内的“条件”写成了T(INDIRECT({1,2,3}&“!A”&ROW($2:$44))),{1,2,3}代表的是sheet名,把自己要引用的表格的sheet名,手动填进去。
(2){1,2,3}*1000+ROW($2:$44))),“0!A000”,这里的原理跟前面的是一样的,只是同样是通过把坐标通过四则运算转为数值,然后再通过TEXT([数据],“0\!A000”),转为指定格式。
(3)图中公式得出的结果中,有个空白单元格,这是公式本身的“不全面”引起的,细心的读者可以发现,多表单列去重罗列公式比单表的少了个($A$2:$B$44<>“”),这个公式是用于去除空白单元格的。但博主没本事,不知道怎么在这个公式中去添加这个条件,一添加就报错,望厉害的读者能帮忙改进下,谢谢。
(4)下面的报错(#REF!)是正常的,因为已经把所有唯一值罗列出来了,之后的返回值都是4^8,这个结果本身就是错误的。可以做个iferror或者把报错部分的数据删掉即可。
这个公式的原理跟单表单列的公式原理是一样的,只是对应的区域的引用和转换是个问题。而且没能实现多表多列的去重罗列,这个也是个难点,博主暂时研究不出。
四、效果验证
1.单表单列、单表多列去重罗列
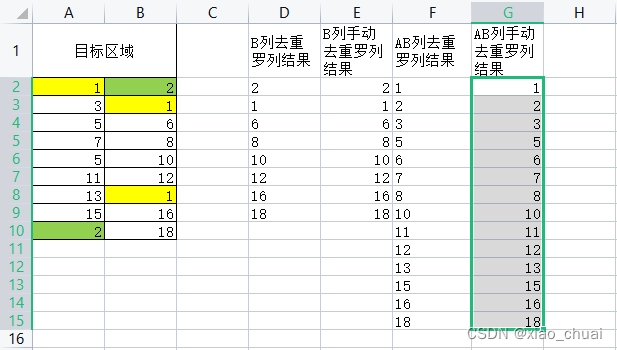
注:在手动去重罗列多列的数据时,需按照先左后右,先上后下的原则,把数据合并到一列,然后点击[数据]–>[重复项]–>删除重复项,这个功能。否则直接把两列数据合并到一起,得到的只会是一个数据对得上,但位置对不上的结果。
2.多表单列去重罗列

总结
通过验证,本文能实现“单表单列、单表多列的去重罗列”和“多表单列的去重罗列”这两个需求,希望能通过本文解决读者的需求,具体应用中,还需读者去灵活地更改公式引用的区域和*100、“R0C00”等参数的设置。