python/gurobi计算二人零和博弈纳什均衡精确解(可求解大规划策略空间)
python/gurobi计算二人零和博弈纳什均衡精确解(可求解大规划策略空间)
文章目录
- python/gurobi计算二人零和博弈纳什均衡精确解(可求解大规划策略空间)
-
- 1 二人零和博弈的纯策略NE——鞍点
- 2. 二人零和博弈的混合策略NE——对偶的线性规划
- 3.python+gurobi程序实现
- 4.实现效果
二人零和博弈描述了涉及两名参与人的严格竞争情况(每一组动作对应的效用和为0), 矩阵博弈是具有有限策略集的两人零和博弈(如下图)。

矩阵博弈在很多方面都很有趣,并且由于其简单性和特殊结构,它们的分析很容易处理。 冯·诺依曼和摩根斯坦表明,线性规划可以用来解决这些博弈。 在二人零和博弈中有以下重要性质:
- 二人零和博弈的纯策略纳什均衡(如果存在)恰恰是鞍点。
- 两个参与人的最佳策略可以用彼此对偶的线性规划来描述。
- 极小极大定理:在二人零和博弈中minmax=maxmin。
- 极大极小定理表明每个矩阵博弈都保证有一个混合策略纳什均衡。通过求解两个互为对偶的线性规划问题可以求解其混合策略NE。
下面分别介绍求解二人零和博弈的纯策略NE的方法及相关定义和定理,并在最后赋上了用python求解的代码。
1 二人零和博弈的纯策略NE——鞍点
定义1:最大最小值
给定一个矩阵博弈A,其最大最小值定义为:
v ‾ = max i ∈ S 1 min j ∈ S 2 a i j \underline{v}=\max _{i \in S_1} \min _{j \in S_2} a_{i j} v=i∈S1maxj∈S2minaij
最大最小值maxmin是当列玩家可以自由使用任何策略时,对行玩家的最小保证回报(因为当前考虑的以及是列玩家采取动作使行玩家获得奖赏最少的情况了,列玩家已经没办法使得行玩家获得比maxmin更少的回报)。行玩家获得回报maxmin的策略称为玩家的最大最小策略。
定义2:最小最大值
给定一个矩阵博弈A,其最小最大值定义为:
v ‾ = min j ∈ S 2 max i ∈ S 1 a i j \overline{v}=\min _{j \in S_2} \max _{i \in S_1} a_{i j} v=j∈S2mini∈S1maxaij
最小最大值minmax是当行玩家可以自由使用任何策略时,对列玩家的最小保证损失(因为当前考虑的以及是行玩家采取动作使列玩家损失最大的情况了,行玩家已经没办法使得列玩家获得比minmax更大的损失)。列玩家获得损失minmax的策略称为玩家的最小最大策略。
定义3:矩阵的鞍点
给定一个矩阵博弈A,一个点为鞍点的充分必要条件为:该点在所在行中为最小值,在所在列中为最大值。
定理1
一个矩阵A有一个鞍点当且仅当 v ‾ = v ‾ \underline{v} =\overline{v} v=v。
命题1:纯策略NE的充要条件
对于具有收益矩阵A的矩阵博弈, a i j a_{ij} aij是鞍点当且仅当策略(i,j)为纯策略纳什均衡。
综上可知,要求二人零和博弈的纯策略均衡,只需要找到收益矩阵的鞍点。但并不是每个二人零和博弈都有纯策略纳什均衡,接下来介绍混合策略纳什均衡。
2. 二人零和博弈的混合策略NE——对偶的线性规划
我们已经看到矩阵游戏中可能不存在鞍点或纯策略纳什均衡。 然而,当允许混合策略时,均衡肯定存在。 令 x = ( x 1 , … , x m ) x=\left(x_1, \ldots, x_m\right) x=(x1,…,xm)和 y = ( y 1 , … , y n ) y=\left(y_1, \ldots, y_n\right) y=(y1,…,yn)分别为行玩家和列玩家的混合策略。 注意 a i j a_{ij} aij是当行玩家选择行 i i i而列玩家选择列 j j j的概率为1时行玩家的收益。列玩家对应的收益为$-a_{ij} $。 使用上述混合策略 x x x 和 y y y 的行玩家的预期收益可以计算为:
= u 1 ( x , y ) = ∑ i = 1 m ∑ j = 1 n x i y j a i j = x A y where x = ( x 1 , … , x m ) ; y = ( y 1 , … , y n ) ; A = [ a i j ] \begin{aligned} & =u_1(x, y) \\ & =\sum_{i=1}^m \sum_{j=1}^n x_i y_j a_{i j} \\ & =x A y \quad \text { where } \quad x=\left(x_1, \ldots, x_m\right) ; y=\left(y_1, \ldots, y_n\right) ; A=\left[a_{i j}\right] \end{aligned} =u1(x,y)=i=1∑mj=1∑nxiyjaij=xAy where x=(x1,…,xm);y=(y1,…,yn);A=[aij]
列玩家的预期收益为 − x A y -x A y −xAy。使用前面分析纯策略时的方法可知:
-
行玩家的安全策略
当行玩家使用混合策略 x x x 时,它可以保证预期的收益为:
min y ∈ Δ ( S 2 ) x A y \min _{y \in \Delta\left(S_2\right)} x A y y∈Δ(S2)minxAy
因此,行玩家应该寻找一种混合策略 x x x 来最大化上述收齐。 也就是:
max x ∈ Δ ( S 1 ) min y ∈ Δ ( S 2 ) x A y \max _{x \in \Delta\left(S_1\right)} \min _{y \in \Delta\left(S_2\right)} x A y x∈Δ(S1)maxy∈Δ(S2)minxAy
也就是说行玩家的最优策略是进行最大最小化,这种行玩家的策略也被称为行玩家的安全策略。 -
列玩家的安全策略
类似地,当列玩家玩 y y y 时,她要确保自己的收益为:
= min x ∈ Δ ( S 1 ) − x A y = − max x ∈ Δ ( S 1 ) x A y \begin{aligned} & =\min _{x \in \Delta\left(S_1\right)}-x A y \\ & =-\max _{x \in \Delta\left(S_1\right)} x A y \end{aligned} =x∈Δ(S1)min−xAy=−x∈Δ(S1)maxxAy
也就是说,她保证自己的损失不会超过
max x ∈ Δ ( S 1 ) x A y \max _{x \in \Delta\left(S_1\right)} x A y x∈Δ(S1)maxxAy
列玩家的最优策略应该是最小化这种损失:
min y ∈ Δ ( S 2 ) max x ∈ Δ ( S 1 ) x A y \min _{y \in \Delta\left(S_2\right)} \max _{x \in \Delta\left(S_1\right)} x A y y∈Δ(S2)minx∈Δ(S1)maxxAy
这称为最小化最大化。 列玩家的这种策略也被恰当地称为列玩家的安全策略。
将上面两个策略的形式改写,可以得到:
-
行玩家的优化问题
maximize min j ∑ i = 1 m a i j x i subject to ∑ i = 1 m x i = 1 x i ≥ 0 i = 1 , … , m \begin{aligned} & \operatorname{maximize} \min _j \sum_{i=1}^m a_{i j} x_i \\ & \text { subject to } \\ & \qquad \sum_{i=1}^m x_i=1 \\ & \quad x_i \geq 0 \quad i=1, \ldots, m \end{aligned} maximizejmini=1∑maijxi subject to i=1∑mxi=1xi≥0i=1,…,m -
列玩家的优化问题
minimize max i ∑ j = 1 n a i j y j subject to ∑ j = 1 n y j = 1 y j ≥ 0 j = 1 , … , n \begin{aligned} & \quad \operatorname{minimize} \max _i \sum_{j=1}^n a_{i j} y_j \\ & \text { subject to } \\ & \qquad \sum_{j=1}^n y_j=1 \\ & y_j \geq 0 \quad j=1, \ldots, n \end{aligned} minimizeimaxj=1∑naijyj subject to j=1∑nyj=1yj≥0j=1,…,n
定理:最大最小值定理
对于每一个 A m × n A_{m \times n} Am×n 的矩阵博弈,都有一个行玩家的混合策略 x ∗ = ( x 1 ∗ , … , x m ∗ ) x^*=\left(x_1^*, \ldots, x_m^*\right) x∗=(x1∗,…,xm∗) 和一个列玩家的混合策略 y ∗ = ( y 1 ∗ , … , y n ∗ ) y^*=\left(y_1^*, \ldots, y_n^*\right) y∗=(y1∗,…,yn∗) ,使得:
max x ∈ Δ ( S 1 ) x A y ∗ = min y ∈ Δ ( S 2 ) x ∗ A y \max _{x \in \Delta\left(S_1\right)} x A y^*=\min _{y \in \Delta\left(S_2\right)} x^* A y x∈Δ(S1)maxxAy∗=y∈Δ(S2)minx∗Ay
也即:
max x ∈ Δ ( S 1 ) min y ∈ Δ ( S 2 ) x A y = min y ∈ Δ ( S 2 ) max x ∈ Δ ( S 1 ) x A y \max _{x \in \Delta\left(S_1\right)} \min _{y \in \Delta\left(S_2\right)} x A y=\min _{y \in \Delta\left(S_2\right)} \max _{x \in \Delta\left(S_1\right)} x A y x∈Δ(S1)maxy∈Δ(S2)minxAy=y∈Δ(S2)minx∈Δ(S1)maxxAy
同时, ( x ∗ , y ∗ ) \left(x^*, y^*\right) (x∗,y∗) 是一个混合策略纳什均衡。
通过将上述两个优化问题进行改写,可以得到一组对偶线性规划问题,用于求解二人零和博弈的混合策略纳什均衡:
(1)LP1
maximize z subject to z − ∑ i = 1 m a i j x i ≤ 0 j = 1 , … , n ∑ i = 1 m x i = 1 x i ≥ 0 ∀ i = 1 , … , m \begin{aligned} & \text { maximize } \quad z \\ & \text { subject to } \\ & z-\sum_{i=1}^m a_{i j} x_i \leq 0 \quad j=1, \ldots, n \\ & \sum_{i=1}^m x_i=1 \\ & x_i \geq 0 \quad \forall i=1, \ldots, m \\ & \end{aligned} maximize z subject to z−i=1∑maijxi≤0j=1,…,ni=1∑mxi=1xi≥0∀i=1,…,m
(2)LP2
minimize w subject to w − ∑ j = 1 n a i j y j ≥ 0 i = 1 , … , m ∑ j = 1 n y j = 1 y j ≥ 0 ∀ j = 1 , … , n \begin{aligned} & \operatorname{minimize} w \\ & \text { subject to } \\ & w-\sum_{j=1}^n a_{i j} y_j \geq 0 \quad i=1, \ldots, m \\ & \sum_{j=1}^n y_j=1 \\ & y_j \geq 0 \quad \forall j=1, \ldots, n \end{aligned} minimizew subject to w−j=1∑naijyj≥0i=1,…,mj=1∑nyj=1yj≥0∀j=1,…,n
基于上面的定理,只需要求解出上面两个互为对偶的规划问题LP1、LP2,并且保证求出的最优目标函数值相同,此时对应的解x和y,即为混合策略纳什均衡。
3.python+gurobi程序实现
-
纯策略纳什均衡——鞍点
Tag =False Mat=np.array(Mat) [m,n]=Mat.shape SP_List=[]#鞍点的集合 for i in range(m): for j in range(n): if Mat[i,j]==min(Mat[i,:]) and Mat[i,j]==max(Mat[:,j]): SP_List.append((i,j)) if len(SP_List): Tag=True r=choice(SP_List)2.借助python+gurobi求解混合策略均衡
model = Model('LP1')
# 变量
z = model.addVar(lb = -np.inf,vtype = GRB.CONTINUOUS, name = 'z') # 注意gurobi里默认变量大于等于0,对于可取负数的变量,要格外设定
x = model.addVars([i for i in range(m)],lb = 0,vtype = GRB.CONTINUOUS, name = 'x') #[0,1]之间的连续变量
model.update()
# 目标函数
model.setObjective(z, GRB.MAXIMIZE)
# 约束
model.addConstr(quicksum(x)==1, name = 'c1')
for j in range(n):
model.addConstr((np.mat(z)-np.mat(Mat[:,j])@(x.select())).tolist()[0][0]<=0, name = 'c%d'%(j+2))
# 求解
model.setParam('outPutFlag', 0) # 0表示不输出求解日志
model.setParam('DualReductions', 0)
model.optimize()
# 输出
print('LP1求解状态:', model.Status) # 显示当前求解状态
model.write('lp1.lp')
if model.Status==3:
print('LP1 is infeasible')
p1 = None
else:
print('obj1=', model.objVal)
p1 = [(model.getVars()[i]).x for i in range(1, m + 1)]
# LP2
model = Model('LP2')
# 变量
w = model.addVar(lb=-np.inf,vtype = GRB.CONTINUOUS, name = 'w') # 注意gurobi里默认变量大于等于0,对于可取负数的变量,要格外设定
y = model.addVars([i for i in range(n)],lb = 0,vtype = GRB.CONTINUOUS, name = 'y') #[0,1]之间的连续变量
model.update()
# 目标函数
model.setObjective(w, GRB.MINIMIZE)
# 约束
model.addConstr(quicksum(y)==1, name = 'c1')
for i in range(m):
model.addConstr((np.mat(w)-np.mat(Mat[i,:])@(y.select())).tolist()[0][0]>=0, name = 'c%d'%(i+2))
# 求解
model.setParam('outPutFlag', 0) # 不输出求解日志
model.optimize()
# 输出
print('LP2求解状态:',model.Status) # 显示当前求解状态
model.write('lp2.lp')
if model.Status == 3:
print('LP2 is infeasible')
p2 = None
else:
print('obj2=', model.objVal)
p2 = [(model.getVars()[i]).x for i in range(1, m + 1)]
4.实现效果
针对剪刀石头布博弈,该算法的求解结果为:

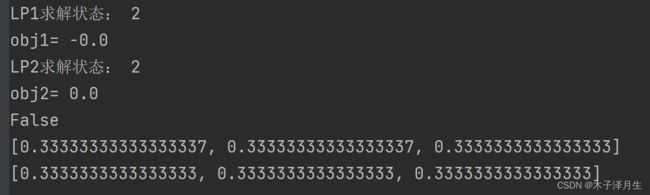
其中,求解状态为2表示已经找到最优解,而两个优化问题的目标函数值相同,说明找到的就是混合策略纳什均衡,即以均匀概率随机出剪刀/石头/布。经测试,目前该算法可适用于大规模策略空间下的二人零和博弈。