阿里用户序列建模ETA
End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model
摘要
现实很少有工作可以处理长序列用户建模的问题,SIM提出了两阶段方法。第一阶段,辅助任务旨在从长序列用户行为检索最相关的用户行为序列。第二阶段,经典的注意力机制用来处理目标物料和第一阶段选出来的用户子序列的关系,进行CTR预估。
这种方式存在两个问题,首先是目标不一致,第一阶段目的是找到和目标物料相似的用户序列行为,第二阶段是尽可能的准确建模点击率;其次,第一阶段和第二阶段的更新频率不同,第一阶段是离线构建索引,然后导入到线上,第二阶段是参与在线训练。
受Reformer的启发,我们提出了一种称为 ETA(End-to-end Target Attention)可以大大降低训练和推理成本,并端到端训练长期用户行为序列。
1. 简介
如何有效地利用大量的信息型,主动的用户行为变得越来越重要,这也是本文的目标。提出了各种方法来建模顺序用户行为,数据早期的方法,如sum/avg池化方法,基于RNN的方法,基于cnn的方法和,基于自注意的方法编码不同长度的用户行为序列到固定维的向量。
然而,它们总是无法抓住用户的动态兴趣。这些方法还介绍了噪声通过编码所有用户的历史行为。要克服针对全局池化方法的缺点,提出了DIN方法,通过目标注意机制,其中目标候选作为查询和序列中的每个项作为键和值。然而,由于昂贵的计算和存储资源,DIN使用了最近的50个行为目标注意力,它忽略了资源丰富用户长序列的信息,明显是次优的效果。
最近,诸如SIM和UBR4CTR等方法都是可以从较长的用户行为中捕捉用户的动态兴趣。这些方法以两阶段的方式起作用。在第一阶段,是一个辅助任务旨在从长期用户检索topk和目标物料的行为序列,以便准备好top-k相关物料,第二阶段是目标注意机制,是在第一个项目中选择的子序列和目标项目之间进行建,然而,用于检索阶段的目标和主CTR任务目标是不同的。例如,UBR4CTR和SIM使用与目标物料的类别等属性相同的用户行为序列,这与CTR模型的目标有所不同。SIM还试图建立一个基于预先训练的向量,在训练和推理过程中,该模型可以搜索top-“相似”的无量。但CTR模型都是在线学习中更新向量embedding.因此,预先训练的embedding在离线索引中与在线CTR模型中的embedding相比,已经过时了。无论是发散的目标还是过时的检索向量,它都会是的长期用户行为序列无法被充分利用。
在本文中,我们提出了一种称为ETA的方法,可以实现端到端的长期用户行为建模,以减轻上述信息缺失(即目标发散和更新频率不一致)。我们使用SimHash来生成用户行为序列中每个行为的指纹。然后用汉明距离是用来帮助选择top-k物料。我们的方法把检索复杂性从O(LBd)降低到O(L*B),其中L为行为序列的长度,B是候选物料的数量,d为embedding的尺寸。降低复杂性是有帮助我们删除了离线辅助模型,并实时进行训练和服务过程中进行检索。
总结:
提出端到端的用户长序列建模。
2. 相关工作
特征交互:
特征交互的直观来看是为了记忆特征空间中的共现模式。例如,一个特征AND(user_install_app=netflix,impression_app=pandora)可以更好地捕获用户点击或未点击某个推荐的应用程序的规律。有代表性的文章有FM,FFM,GBDT+LR, Wide&Deep, FNN, AFM, DeepCross,DeepFM,PNN和xDeepFM。各种差异可以可以在任何两个模型之间找到,例如,是否有用到深度学习技术,embedding的权重和特征是共享,是否需要特性工程。
用户行为序列:
用户行为序列对每个用户是高度个性化的,引入按用户序列行为到CTR模型是一个显著的里程碑。Youtube使用观看视频序列和搜索词条建模用户兴趣,为了更好地从用户行为中提取用户的兴趣序列中,提出了各种模型,包括CNN、RNN,注意力机制和胶囊网络。然而从上述模型中学习到的用户兴趣向量是全局的,对于某个用户。DIN提出了一种基于注意力的方法,来捕获目标物料相关的用户局部兴趣。
长期的用户行为序列:
尽管功能强大,序列模型能够捕获用户多样化的兴趣,但是计算目标注意力(target attention)是昂贵的。线推理时间的严格限制使得类似于DIN的模型无法应用更长的用户序列。用户兴趣向量是离线更新,MIMN理论上可以处理任意长期用户行为序列,但当序列过长时,离线的用户兴趣向量包含了很多的噪声,影响到模型的精度。用户感兴趣地对CTR任务的其余部分进行建模。SIM和UBR4CTR在CTR中击败了MIMN任务,并成为SOTA模型。SIM和UBR4CTR均采用两阶段架构用来建模长期用户行为序列。在第一阶段,设计了一个辅助任务来检索top-k和目标物料相关的用户序列。在第二阶段,使用注意力机制建模目标物料和第一阶段选出的用户子序列。
除了上述关于CTR预测任务的相关工作外,还有很多的研究旨在提高transformer的效率和有效性。Reformer和Informer是最近的工作。然而他们只关注经典transformer的优化,由于大规模推荐系统在线推断的耗时限制,它们不能直接用于CTR预测任务。
3. SimHash简介
SimHash是局部敏感哈希(Local Sensitive Hash)的一种实现。LSH的思想是,在保留数据相对位置的条件下,将原始数据映射到一个碰撞率较高的低维的新空间里,从而降低下游任务的计算量。利用局部敏感哈希编码的高碰撞率,我们可以设计出更加稀疏的倒查索引键值,从而得到非常高效的文本去重方案,大量文本去重就是使用SimHash的方法。
SimHash算法

SimHash满足局部敏感特性:如果输入向量是相似的,输出的SimHash也是相似的。SimHash将向量从D维通过随机旋转投影到K维,降低维度,同时K维向量的值要么是0要么是1,这样可以使用汉明距离来计算两个向量的距离。这个旋转是通过输入向量和随机投影向量相乘实现的,随机投影向量就是hash函数。SimHash在旋转是相当于将D维超平面的一个个点映射到K维超平面的坐标轴上面,保持向量的相对距离。同时SimHash计算汉明距离时还可以通过位操作来加速计算过程。换句话说,以前判断两个向量相似性使用内积,现在只需要计算SimHash后的汉明距离,大大减少了计算量。值得注意的是,SimHash算法对选择的hash函数并不敏感。
以下是举例说明,在超平面上相近的两个原始点,经过SimHash投影映射后的签名0-1向量,保持着原本的距离性质。

4. 模型
4.1 概述
如下图,输入是用户长期序列、用户短期序列、用户画像、物料特征。分别使用长期用户兴趣抽取单元、多头注意力和Embedding层去处理长期用户序列、短期用户序列、用户和无量特征输入。然后concat到一起,送入MLP网络,最后经过sigmoid,得到用户点击的概率。
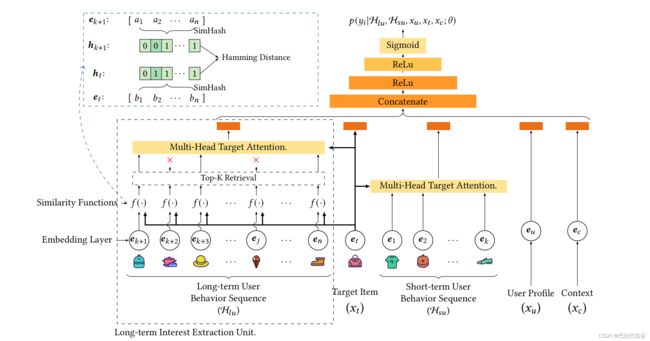
4.2 长期用户兴趣抽取单元
1)检索部分的目标应与整体CTR预测保持不变。只有这样,top-k才能检索到对CTR预测贡献最大的物料。
2)检索的时间应该是满足严格的推理时间限制,以保证算法的可以应用于现实系统中,满足每秒数百万的请求。
ETA将两个向量的内积计算转化为SimHash的汉明距离的计算,同时SimHash的局部敏感特性保证了两个原始相似的向量映射投影后还是相似的。SimHash将一个D维的向量映射成m位的0-1串,然后用汉明距离来衡量相似性。
top-k检索:汉明距离定义为两个hash串对应位置上字符不同的个数,使用异或(XOR)即可得到结果,相同则为0,不同则为1。计算汉明距离的时间复杂度为O(1),总的时间复杂度为O(LB1),相比于用内积计算的时间复杂度O(LBD),大大降低。
4.3 部署
在训练前初始化一个随机矩阵,用来作为SimHash的随机旋转投影。
选择和Reformer一样的hash函数。
对于SimHash后的签名向量(长度为m),计算汉明距离时,用log(m)个位的整数来表示这个签名向量,然后可以使用异或操作加速检索过程。
5. 实验
实验数据
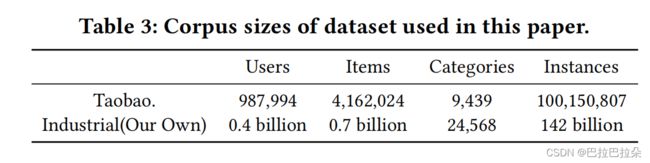
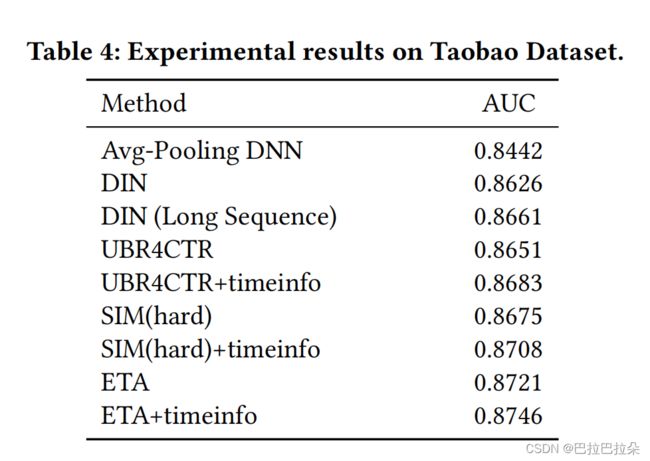
在taobao数据集上面的效果
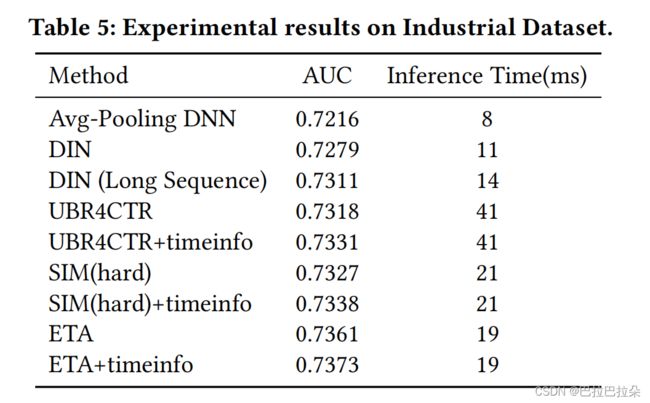
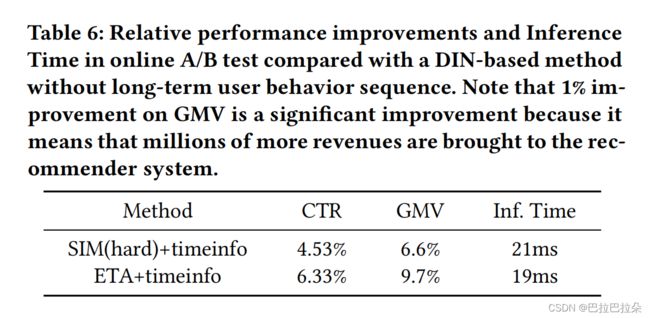
在工业数据集上面的效果
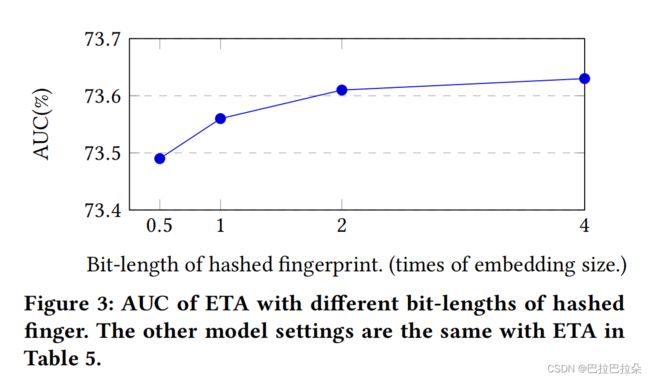
SimHash之后签名指纹向量长度和AUC的关系,当长度是2倍Embedding size的时候,auc最高,再往后增长很小了。