Kafka概论
前言
任何消息中间件,除了基础组件架构外,核心特性无非三个,消息可靠性、消息模型、吞吐量,本文要聊的正是这些东西,其余诸如API、下载安装、集群搭建等都是死的,而且会随着版本的变动而改变,这类东西针对不同版本,查官方文档即可。
目录
前言
1.概述
1.1.特点
1.2.架构
2.消息模型
2.1.发布订阅模式
2.2.点对点
2.3.消息顺序
2.4.消息传递语义
2.6.事务
3.如何保证吞吐量
3.1.顺序写
3.2.序列化
3.3.零拷贝
1.概述
1.1.特点
Kafka,一款具有高吞吐量、高可靠性的分布式消息中间件。其采用分布式架构、顺序写、序列化、零拷贝等机制保证了高吞吐量,数据自动落磁盘完成持久化来保证消息不会丢失。
1.2.架构
topic:
主题,消息的分类
partition:
分区,Kafka是一个分布式的消息中间件,同一个topic可以被拆成多个partition,不同的partition存储在不同的服务器节点上。分区是Kafka里的最小并行单位,一个消费者可以消费多个分区,一个分区可以被多个消费者组里的消费者消费,但是一个分区不能同时被一个消费者组里的多个消费者消费,主要是为了避免重复消费。

offset:
偏移量,Kafka会为每条消息分配一个偏移量,偏移量就是该消息的index,Kafka通过offset来对消息进行提取,同一个分区中的offset是唯一的。
record:
消息记录,Kafka中的消息以KV键值对的方式记录,被称为消息记录。
replication:
Kafka通过副本机制,保证消息的可靠性,同编号的分区的个数和副本数是一致的,一份消息可以被复制为多个副本,分开存储在同编号的不同分区中。同编号的分区间有主从关系,读写都针对主分区,从分区只负责进行数据同步。Kafka会维护一个ISR,里面会记录处于同步的分区,不同步的会从ISR中剔除,直到同步后再重新纳入。

2.消息模型
2.1.发布订阅模式
一条消息可以被多个消费者消费。
消费者或者消费者组可以去订阅某一个topic,该topic中的每一条消息都会推送给订阅的消费者或者消费者组。
同一个消费者组的不同消费者回去消费同一个topic的不同分区,如果消费者数量大于分区数量时,同一个分区允许被同一个消费组多次消费,只要不是同时并行消费就行。

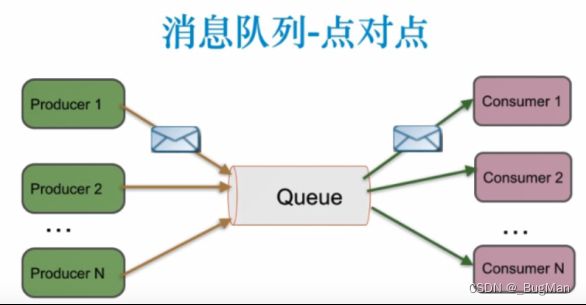
2.2.点对点
一条消息只能由一个消费者消费。
2.3.消息顺序
同一个topic下,单个分区中消息是有序的,和发送顺序一致。不同编号的分区间消息是无序的。
比如同一个topic的消息,A,B被存到了分区0中,C被存到了分区1中,那么消费者消费到的顺序可能是ABC,也可能是ACB,或者其它排列组合。
2.4.消息传递语义
Kafka支持多种消息传递语义:
-
最多一次,消息可能会丢失,永远不重复发送。
-
至少一次,消息不会丢失,但是可能会重复发送。
-
精确一次,保证消息被传递到服务端且在服务端不重复,精确一次需要生产者和消费者一起来保证。
精确一次:
生产方需要保证:
发送方需要保证:
2.6.事务
Kafka的消息生产支持事务,是标准的两阶段提交模型。
如果对两阶段的事务模型不熟悉的同学,可以移步博主的另一篇文章:
分布式事务__BugMan的博客-CSDN博客
kafka中的事务状态:
-
开启(Ongoing):事务已经开启,但尚未提交或回滚。
-
准备提交(PreparingCommit):事务已经发送了所有消息,并准备提交。
-
提交(Committing):事务正在提交,即将把消息持久化到Kafka的主题中。
-
回滚(Aborting):事务正在回滚,将丢弃该事务中所有尚未提交的消息。
Kafka事务的主要流程:
-
开启事务:生产者在发送消息前调用
beginTransaction()方法来开启一个事务。开启事务时,生产者会向事务协调器注册自己,并获取一个全局唯一的生产者ID和事务ID。 -
发送消息:生产者可以发送多个消息到不同的分区,这些消息将在同一个事务中。
-
准备提交:在所有消息都发送成功后,生产者调用
commitTransaction()方法来准备提交事务。在这个阶段,生产者会将事务状态更新为“准备提交”,并向事务协调器发送“预提交”请求。 -
事务协调器处理:事务协调器接收到“预提交”请求后,会将该事务的状态更新为“准备提交”,并记录下生产者ID和事务ID。然后,事务协调器将“预提交”请求发送给Kafka的其他Broker,并等待它们的响应。
-
提交或回滚:如果所有Broker都能成功接受事务的“预提交”请求,那么事务协调器会向生产者发送“正式提交”请求,表示可以提交事务。生产者收到“正式提交”请求后,将所有消息持久化到Kafka的主题中。如果在准备提交阶段或提交阶段出现错误,生产者可以调用
abortTransaction()方法来回滚事务。 -
结束事务:事务完成后,生产者可以调用
close()方法来关闭事务。这将会释放生产者的资源并终止与事务协调器的连接。
kafka的事务隔离级别:
默认为read_uncommitted,即脏读。实际使用时设置为read_committed,读已提交即可。
3.如何保证吞吐量
3.1.顺序写
Kafka为了保证消息不丢失,会将消息写入磁盘来存储,消费消息的时候再从磁盘中读出。众所周知,磁盘IO是很慢的动作,因为要寻道吗。所以对于磁盘IO来说比较好的一种优化方法就是将同类型的数据集中写在连续的存储空间上,减少寻道带来的时间开销。这种方式叫做顺序写,顾名思义将数据顺序写在连续的存储空间内。Kafka采用了这种方式来加快磁盘IO。总结起来就是一个partition就是一个文件,向partition追加写入,在消费的时候就能保证数据的连续性。
kafka将来自Producer的数据,顺序追加在partition,partition就是一个文件,以此实现顺序写入。Consumer从broker读取数据时,因为自带了偏移量,接着上次读取的位置继续读,以此实现顺序读。

3.2.序列化
序列化和反序列化其实一张图就能讲明白:

MQ在网络上传输message时,将携带的数据序列化后进行传输会加快传输速度,因为序列化后的数据在网络传输种会具有以下几个优点:
-
报文更加紧凑,序列化后的二进制数据会比json之类的文本格式体积要小很多,自然报文的大小就更小。
-
不用依赖第三方依赖,像json转对象之类的操作往往需要去依赖第三方的JSON框架,直接用序列化的话可以避免对第三方的依赖。
-
解析速度更快,序列化过程无需解析数据,而 JSON 转对象需要解析 JSON 文本。JSON 解析涉及字符到数字的转换、字符串到对象的映射等处理,相比直接转换二进制数据,解析过程较为复杂,因此在性能上较慢。
要注意的是以上优点是指多数情况下,序列化相较于JSON之类的文本解析存在的优势,少数极端的例子序列化不一定还存在以上优势。比如数据就传一个{"name":"zou"}之类的,序列化的报文由于某些描述性的字节位置是固定要有的,最终的报文大小不一定比JSON的报文大小要小,解析速度也不一定有JSON解析快。但是在实际应用种我们传输的数据一定是一个相对复杂的对象,所以在实际业务场景种序列化是会存在以上的优势的。
Kafka的序列化和反序列化是在SDK内实现的,Kafka在SDK内提供了一套默认的序列化机制,也支持自定义序列化机制。这里就不展开谈了,版本的更迭SDK种的API会有变化的,要用的时候查对应版本的官方手册更为稳妥。
3.3.零拷贝
零拷贝(Zero-Copy)是一种优化技术,旨在提高数据传输的效率和性能,特别是在文件传输和网络数据传输中。传统的数据传输方式涉及多次数据拷贝,而零拷贝通过避免不必要的数据拷贝操作,减少了数据传输的开销,从而提高系统的性能。
在传统的数据传输中,例如从磁盘读取文件并通过网络发送,通常涉及以下步骤:
- 将数据从磁盘读取到内核空间(Kernel Buffer)。
- 将数据从内核空间拷贝到用户空间(User Buffer)。
- 将数据从用户空间拷贝到网络缓冲区(Network Buffer)。
- 最终数据通过网络发送。
这种传统的数据传输方式涉及多次数据拷贝,每次拷贝都需要 CPU 参与,并且需要在内核空间和用户空间之间进行数据复制,导致了额外的开销和延迟。
零拷贝技术的主要思想是避免不必要的数据拷贝,通过直接在内核空间和用户空间之间传输数据,从而减少 CPU 和内存的使用。
关于0拷贝更详细的内容异步博主的另一篇文章:
全网最清晰的零拷贝详解,看一遍就会__BugMan的博客-CSDN博客