kafka+zookeeper群集
目录
部署jdk
一、zookeeper简介
二、部署zookeeper
Ⅰ、zookeeper下载安装
Ⅱ、zookeeper配置文件
Ⅲ、zookeeper的开启
三、kafka简介
Ⅰ、为什么需要消息队列
Ⅱ、kafka特性
四、部署kafka
Ⅰ、kafka的下载安装
Ⅱ、kafka配置文件
Ⅲ、kafka_HOME环境
Ⅳ、启动kafka
五、Kafka的命令行操作
Ⅰ、创建topic
Ⅱ、查看topic列表、信息
Ⅲ、删除topic
Ⅳ、修改分区数
Ⅴ、发布、消费消息
部署jdk
rpm -qa | grep java
#查看系统自带的openjdk
rpm -evh --nodeps ***
#进行删除
rpm -ivh jdk-8u201-linux-x64.rpm
#安装jdk1.8.0_201的rpm包
vim /etc/profile.d/java.sh
#配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
#1.输出定义java的工作目录
#2.输出指定java所需的类文件
#3.输出重新定义环境变量,$PATH一定要放在$JAVA_HOME的后面,让系统先读取到工作目录中的版本信息
source /etc/profile.d/java.sh
#读取profile
java -version
#查看jdk版本
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)一、zookeeper简介
ZooKeeper 是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务, 它提供了一项基本服务:分布式锁服务。分布式应用可以基于它实现更高级的服 务,实现诸如同步服务、配置维护和集群管理或者命名的服务。 Zookeeper 服务自身组成一个集群,2n+1 个(奇数)服务允许 n 个失效,当集群内 一半以上机器可用,Zookeeper 就可用。
二、部署zookeeper
群集:
zk22:192.168.116.22
zk25:192.168.116.25
zk120:192.168.116.120
Ⅰ、zookeeper下载安装
Zookeeper下载地址:
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.1/apache-zookeep er-3.7.1-bin.tar.gz
zookeeper解压安装(所有节点)
tar zxvf apache-zookeeper-3.5.7-bin.tar.gz -C/opt
mv /opt/apache-zookeeper-3.5.7-bin.tar.gz /opt/zookeeper
cd /opt/zookeeper
cp ./conf/zoo_sample.cfg ./conf/zoo.cfgⅡ、zookeeper配置文件
修改部分如下
#------省略部分内容------
#创建一个数据目录,在zoo.cfg中修改数据目录为创建的数据目录
dataDir=/opt/zookeeper/zkdata
clientPort=2181
#------省略部分内容------
#指定群集节点
server.1=zk22:2888:3888
server.2=zk25:2888:3888
server.3=zk120:2888:3888
将配置文件分发给另两个节点
vim /etc/hosts
192.168.116.22 zk22 manager
192.168.116.25 zk25
192.168.116.120 zk120 slave2
scp /opt/zookeeper root@zk25:/opt/
scp /opt/zookeeper root@zk120:/opt/根据conf/zoo.cfg的配置分配对应的节点号,dataDir和节点号要与zoo.cfg文件中一致
#192.168.116.22
mkdir /opt/zookeeper/zkdata
touch /opt/zookeeper/zkdata/myid
echo "1" >/opt/zookeeper/zkdata/myid
#192.168.116.25
mkdir /opt/zookeeper/zkdata
touch /opt/zookeeper/zkdata/myid
echo "2" >/opt/zookeeper/zkdata/myid
#192.168.116.120
mkdir /opt/zookeeper/zkdata
touch /opt/zookeeper/zkdata/myid
echo "3" >/opt/zookeeper/zkdata/myid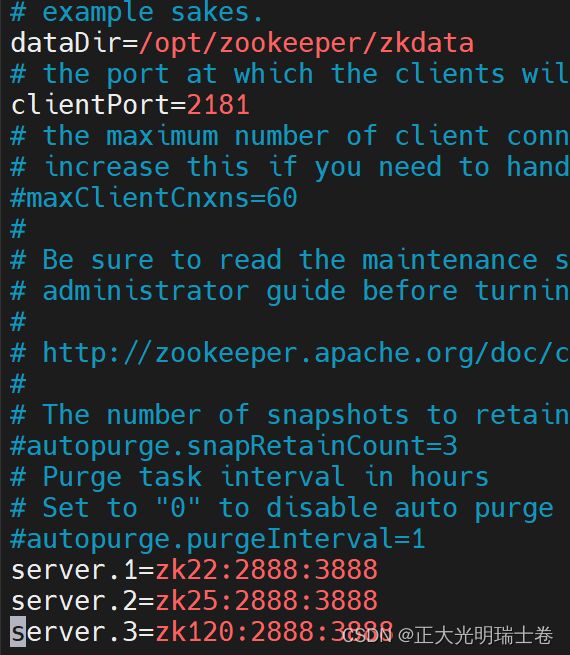
Ⅲ、zookeeper的开启
#启动zookeeper
/opt/zookeeper/bin/zkServer.sh start
#查看zookeeper状态
/opt/zookeeper/bin/zkServer.sh status节点间创建、分发ssh密钥
ssh-keygen -t rsa
#创建公钥私钥
ssh-copy-id [IP]
#分发密钥这里写一个脚本来对zookeeper群集进行管理
#!/bin/bash
#开启zookeeper
case $1 in
"start"){
for i in zk22 zk25 zk120
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/zookeeper/bin/zkServer.sh start"
done
};;
#关闭zookeeper
"stop"){
for i in zk22 zk25 zk120
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/zookeeper/bin/zkServer.sh stop"
done
};;
#查看zookeeper状态
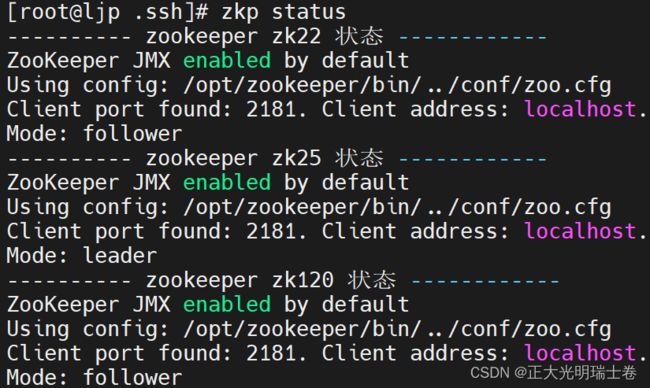
"status"){
for i in zk22 zk25 zk120
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/zookeeper/bin/zkServer.sh status"
done
};;
esac
启动成功, 第二台zookeeper为leader
三、kafka简介
Kafka 是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做 日志的处理。既然是消息队列,那么 Kafka 也就拥有消息队列的相应的特性了。 可以在系统中起到“削峰填谷”的作用,也可以用于异构、分布式系统中海量数 据的异步化处理
Ⅰ、为什么需要消息队列
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。 比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从 而触发 too many connection 错误,引发雪崩效应。 我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用 于异步处理,流量削峰,应用解耦,消息通讯等场景。
Ⅱ、kafka特性
高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫 秒
可扩展性:kafka 集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)
高并发:支持数千个客户端同时读写
四、部署kafka
Ⅰ、kafka的下载安装
kafka官网:
https://kafka.apache.org/downloads
kafka解压安装
tar zxvf kafka_2.12-3.0.0.tgz -C/opt
mv /opt/kafka_2.12-3.0.0 /opt/kafkaⅡ、kafka配置文件
vim /opt/kafka/config/server.properties
#-----省略部分内容-----
#注意三台节点服务器不能相同
broker.id=0
#-----省略部分内容-----
#日志文件目录,配置后需要自己创建
log.dirs=/opt/kafka/kafka_logs
#-----省略部分内容-----
#添加连接zookeeper群集的IP,在zookeeper下有一个根目录,在这里群集IP后加上/kafka
#来让kafka的数据存储在/kafka的节点位置,否则会与跟目录里的其他数据混乱在一起
zookeeper.connect=zk22:2181,zk25:2181,zk120:2181/kafka
#-----省略部分内容-----
----wq
#创建日志文件目录
mkdir /opt/kafka/kafka_logsⅢ、kafka_HOME环境
echo "#kafka_HOME
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin" >> /etc/profile.d/java.sh
source /etc/profileⅣ、启动kafka
/usr/local/kafka/config/kafka-server-start.sh -daemon server.properties脚本管理群集Kafka
#!/bin/bash
case $1 in
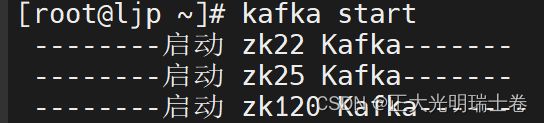
"start"){
for i in zk22 zk25 zk120
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config
/server.properties"
done
};;
"stop"){
for i in zk22 zk25 zk120
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/kafka/bin/kafka-server-stop.sh "
done
};;
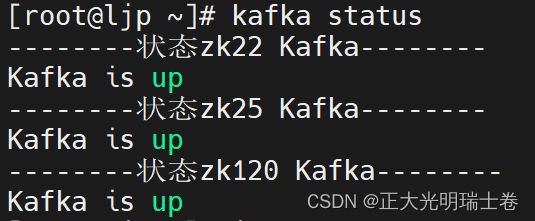
"status"){
for i in zk22 zk25 zk120
do
echo "--------状态 $i Kafka--------"
ssh $i "[ $(pgrep -f kafka | wc -l) -ne 0 ] && echo Kafka is down || echo Kafka is up"
done
};;
esac
启动
关闭

五、Kafka的命令行操作
开启Kafka+Zookeep集群
Ⅰ、创建topic
kafka-topic.sh --create --boostrap-server ljp26:9092,ljp111:9092,ljp120:9092 --partitions 3 --replication-factor 3 --topic [topicname]
*:partitions:分区数
*:replication-factor:分区副本数
*:topic:定义topic名称
Ⅱ、查看topic列表、信息
kafka-topic.sh --list --bootstrap-server ljp26:9092

kafka-topic.sh --describe --bootstrap-server ljp26:9092 --topic [topicname]

Ⅲ、删除topic
kafka-topic.sh --delete --bootstrap-server ljp26:9092 --topic [topicname]
Ⅳ、修改分区数
只可以增加
kafka-topic.sh --alter --bootstrap-server ljp26:9092 --topic [topicname] --partitions [numbers]
Ⅴ、发布、消费消息
kafka-console-producer.sh --bootstrap-server ljp26:9092 --topic [topicname]
![]()
| 参数 | 描述 |
| --bootstrap-server | 连接的 Kafka Broker 主机名称和端口号 |
| --topic | 操作的 topic 名称 |
| --from-beginning | 从头开始消费 |
| --group | 指定消费者组名称 |
kafka-console-consumer.sh --bootstrap-server ljp26:9092 --topic [topicname]
![]()
如果需要查看完整的消息,加上--from-beginning即可