MySQL多表查询(联合查询、连接查询、子查询)
目录
多表联合查询
联合查询类型
多表连接查询
多表查询的分类
交叉查询(笛卡尔积)
内连接查询
外连接查询
自连接查询
子查询规则
子查询的分类
子查询的不同结果
EXISTS和NOT EXISTS
子查询应用的不同位置
不同外部语句的子查询应用情况
多表联合查询
1、通过联合查询,可以得到两张表中记录的集合或者公共记录的集合,或者其中某张表中的记录的集合
2、联合查询以行为单位对表进行操作,主要是进行行数的增减
3、作为联合查询的多表之间的列数、以及列数的类型必须相同(例如:表1查询哪些列,表2就查询哪些列)
4、联合查询默认会去除重复的记录
5、联合查询可以使用任何SELECT语句,但是ORDER BY子句只能在最后一次使用
联合查询类型
UNION 将两张表的某些字段的记录相加(并集)
ALL 作为关键字,表示集合运算的结果保留重复行(一般为UNION ALL)
INTERSECT 将两张表的某些字段的公共记录提取出来(交集)(MySQL不存在,可以使用下述的连接查询代替)
EXCEPT 将两张表的某些字段的公共记录减去,然后返回一张表的剩余记录(差集)(MySQL不存在,使用NOT IN字段实现)
联合查询格式
Union格式
SELECT 字段列表 FROM 表A …… UNION SELECT 字段列表 FROM 表B ……;
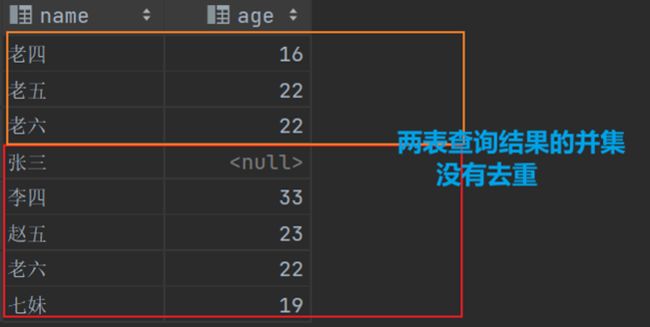
返回表A查询和表B查询的并集(并进行去重处理)
Union all格式
相比于Union查询,此查询可以对合并的数据不进行去重
联合查询演示
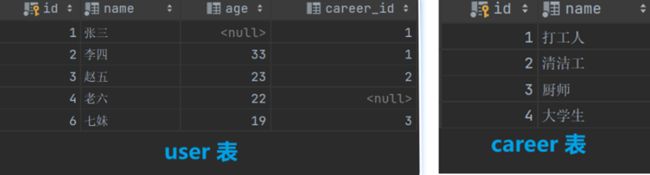
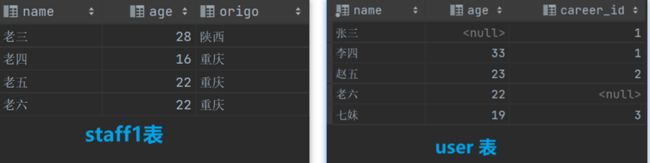
我们使用以下两表进行演示
select name,age from staff1 where origo='重庆' union select name,age from user; #查询表1 origo为重庆的name,age字段的结果 加上表2查询name,age的结果,并进行去重处理(要求两表的name和age数据类型一致)
select name,age from staff1 where origo='重庆' union all select name,age from user; #没有进行去重处理
select name,age from staff1 where (name,age) not in (select name,age from user); #查询表1 与 表2 的差集(将表1的查询结果减去表1与表2的交集)


多表连接查询
多表查询是以横向列为单位,主要是将其他表的某些列添加过来
在进行多表查询时,SELECT子句中的列一般按照 表名的别名.列名 的格式书写
我们使用两张表来做演示讲解

多表查询的分类
交叉查询
将两张表的全部记录交叉组合,所得的记录数是两张表行数的乘积
内连接查询
查询A、B两表交集部分的数据
外连接查询
左外连接:查询左表所有数据,以及两张表交集部分的数据
右外连接:查询右表所有数据,以及两张表交集部分的数据
自连接查询
只有一张表,当前表与自身进行连接查询(子连接必须使用表的别名)
交叉查询(笛卡尔积)
交叉连接通过使用集合运算符GROSS JOIN(笛卡尔积)来完成
将两张表的全部记录交叉组合,在添加了其他表字段的同时,所得的记录数是两张表行数的乘积
格式
SELECT 字段列表 FROM 表1,表2; 显示出来的数据量为表1的数据量*表2的数据量
注意事项
我们通过现象可以看到,其结果太多并且存在错误,没有太多实用价值,并且需要花费大量的运算时间;因此此查询在实际业务中并不会使用
不过此查询是所有表查询的基础
select user.name,career.name from user , career ; #没有使用别名 select u.name,c.name from user u , career c; #使用别名的方式进行交叉查询

内连接查询
可以选取出同时存在于两张表中的数据,即两张表的交集数据
分为隐式内连接和显示内连接,两者只是书写方式不同,得到的结果是完全相同的
隐式内连接
SELECT 字段列表 FROM 表1,表2 WHERE 条件列表;
显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件列表 [WHERE 判断语句] ;
INNER可以省略
如果要在此语句后续加入Where,则需要注意ON语句必须是在FROM和WHERE之间
执行顺序为:先进行显示内连接,再对连接的结果进行Where
注意事项
使用内连接可能会有漏掉的数据,会漏掉NULL值
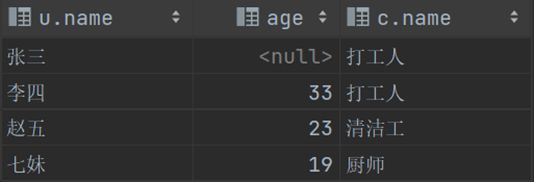
select u.name,u.age,c.name from user u , career c where u.career_id = c.id; #隐式查询;选出user.career_id和career.id相同的记录,并显示这些记录对应的user.name、user,age、career.name字段;此时如果user.career_id有空值或者career.id有空值,就会漏掉空值所对应的数据(此时就漏掉了老六的数据)select u.name,u.age,c.name from user u join career c on u.career_id = c.id; #显式查询; 两次查询的结果都是下图
select u.name,u.age,c.name from user u join career c on u.career_id = c.id where u.age > 20; #显式查询 对以上结果进行筛选,选择年龄大于20的数据据

外连接查询
选取出单张表(主表)的全部信息,然后再加上两张表交集的信息
左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件列表;
[OUTER] 可以省略
查询表1的所有数据,其中包含表1和表2交集部分的数据
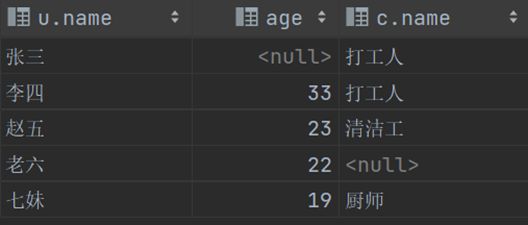
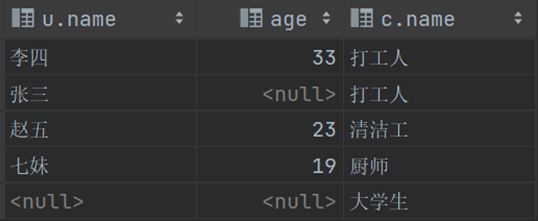
select u.name,u.age,c.name from user u left join career c on u.career_id = c.id; #左外连接 显示user表对应name和age字段的全部信息,然后再加上user.career_id和career.id的交集部分
右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件列表;
[OUTER] 可以省略
查询表2的所有数据包含表1和表2交集部分的数据
select u.name,u.age,c.name from user u right join career c on u.career_id = c.id; #右外连接 显示career表对应name段的全部信息,然后再加上user.career_id和career.id的交集部分
自连接查询
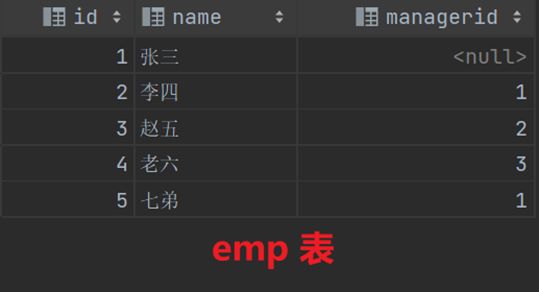
使用此表来做自连接查询的演示(此表记录的是员工与其对应的上司id表—即managerid对应的id的name就是上司名称)
自己连接自己进行查询,可以是内连接方式,也可以是外连接方式
格式
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件列表;
select e1.name,e2.name '上司' from emp e1 join emp e2 on e1.managerid = e2.id; # 显示查询,查询每个员工对应的上司是谁;可以理解为将emp复制为表e1和表e2两张表,将e1表的managerid作为外键与e2的id关联起来,然后显示e1表的name和e2表的name(此处是使用显式内连接方式 会有遗漏)select e1.name,e2.name '上司' from emp e1 left join emp e2 on e1.managerid = e2.id; #左外连接,员工没有领导也显示出来


子查询规则
子查询(Sub Query)也可以称为嵌套查询,是一种嵌套在其它SQL查询的Where子句中的查询;包含子查询的语句称为外部语句
- 子查询必须包含在()内
- 一般子查询的SELECT语句只有一个字段,除非外部语句中有多个列需要与子查询的列进行比较
- 子查询不可以直接应用在聚合函数中,子查询也无法使用ORDER BY
- Ntext、text、image数据类型不可以在子查询的选择列表中使用
- 关键字DISTINCT不能与包含GROUP BY的子查询一起使用
子查询的分类
根据子查询的结果不同,可以分为4类
标量子查询 子查询结果为单个值
列子查询 子查询结果为一列多行
行子查询 子查询结果为一行多列
表子查询 子查询结果为多行多列
根据子查询的不同位置,大致可以分为3类
子查询应用的位置主要有三种情况:
分别是WHERE之后、FROM之后、SELECCT之后
根据子查询的不同外部语句可以分为大致4类
子查询外部的语句可以是
INSERT / UPDATE / DELETE / SELECT的任何一个
子查询的不同结果
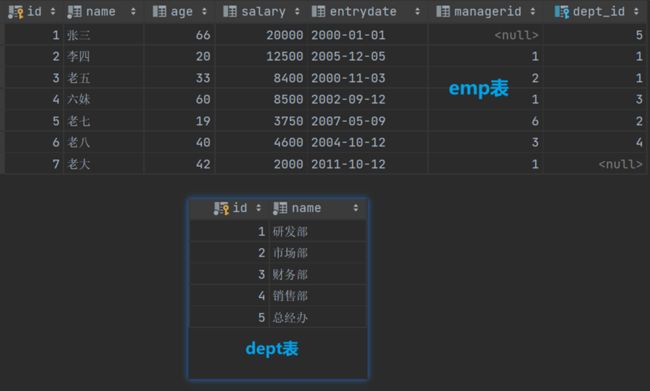
通过以下两表来进行查询
标量子查询——查询结果必须只能返回一行一列的结果,也就是某个值
由于其子查询的结果是单个值,所以可以用来进行算术运算
常用操作符: = 、 <> 、 > 、>= 、< 、 <=
select * from emp where dept_id=(select id from dept where name='销售部'); #查询销部对应的所有员工(先查询销售部对应的id,然后根据id查询员工) select * from emp where entrydate >= (select entrydate from emp where name='张三'); #查询张三入职之后的所有员工信息(先查询张三的入职信息,再查询此时间之后的员工信息
列子查询——返回结果是一列多行
常用操作符:
IN 指定的集合范围内多选一
NOT IN 不在指定的集合范围之内
ANY 子查询返回列表中,有任意一个满足即可
SOME 等同于ANY
ALL 子查询返回列表的所有值都必须满足
select * from emp where salary > all(select salary from emp where dept_id=(select id from dept where name='研发部')); #查询比所有财务员工工资都高的员工信息(先查询财务部对应的id,通过此id查询财务部员工薪资,然后再找出大于此薪资的员工信息)
行子查询——返回结果是一行多列
常用操作符:=、<>、IN、NOT IN
select * from emp where (salary,managerid) = (select salary,managerid from emp where name='李四'); #查询与李四相同薪资与领导的其它员工信息
表子查询——返回结果是多行多列
常用的操作符:IN
经常出现在from之后
select * from emp where (dept_id,salary) in (select dept_id,salary from emp where name='老五' or name='李四'); #查询与老五或李四 的部门相同、工资相同的其它员工信息 select e.*,dept.name from (select * from emp where entrydate > '2001-01-01') e left join dept on e.dept_id = dept.id ; #查询入职时间大于2001-01-01之后的员工信息及其对应的部门信息


EXISTS和NOT EXISTS
格式为:EXISTS(子查询)
EXISTS用于检查子查询是否至少会返回一行数据;如果该子查询至少返回了一行数据,则为True;如果子查询没有返回数据,则为False
某些情况下,也可以使用IN或者ANY字段来代替
NOT EXISTS与EXIST相反
select * from emp where exists(select * from emp where id = 10); #只要有id=10的值,就查询emp表 结果为没有数据 select * from emp where exists(select * from emp where id = 1); #只要有id=1的值,就查询emp表 结果为emp表数据
子查询应用的不同位置
子查询应用的位置主要有三种情况,分别是WHERE之后、FROM之后、SELECCT之后
Where子句中——一般子查询都应用在where之后
我们上述所演示的都是where之后的子查询
大概格式:SELECT * FROM t1 WHERE column1= (SELECT column1 FROM t2);
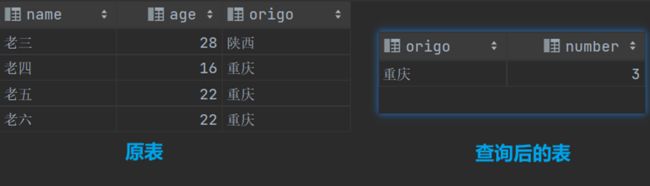
From子句中——此时子查询返回的结果集将作为临时表,该表又称为派生表
派生表必须要配置别名,并且派生表的列名必须是唯一的
select * from (select origo,count(*) as number from staff1 group by origo) as emp where emp.number > 2; #根据居住地分组,并查询居住地人数大于2的(派生表的别名为emp)
Select之后——仅支持标量子查询,子查询返回的是单个值
SELECT (子查询) FROM 表1;
子查询返回的单个值是表1中的某个字段;此查询一般很少用到
不同外部语句的子查询应用情况
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT的任何一个
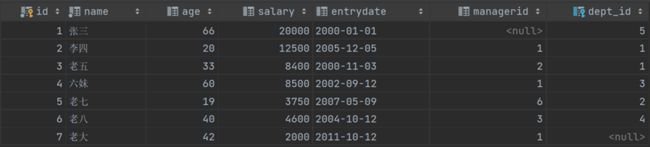
根据以下两个表做的实验
SELECT语句中的子查询
select * from user where career_id =(select id from career where name='厨师'); #查询user中有哪些人是厨师(子查询查询厨师id,然后外部语句再查询此id对应的人员)
INSERT语句中的子查询
insert into user1 (name,age,career_id) select * from user where career_id in (select id from career); #向user1表添加数据,添加的数据为user表中有职位的人
UPDATE语句中的子查询
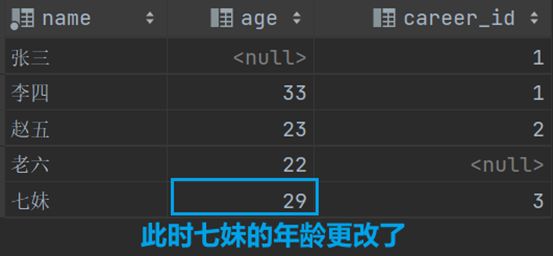
update user set age = age * 1.5 where career_id = (select id from career where name ='厨师'); #将厨师的年龄乘1.5
DELETE语句中的子查询
delete from user where career_id =(select id from career where name='厨师'); #阐述user表中职业是厨师的信息