一步步读懂Pytorch Chatbot Tutorial代码(三) - 创建字典
文章目录
- 自述
- 有用的工具
- 代码出处
- 目录
- 代码 Load and trim data
-
-
- 类 class
- _ _ init _ _ 初始化实例变量
- for word in sentence.split(' ')
- addWord
- trim
- unicodetoAscii
- normalizeString
- readVocs
- filterPair & filterPairs
- trimRareWords
-
自述
我是编程小白,别看注册时间长,但从事的不是coding工作,为了学AI才开始自学Python。
平时就是照着书上敲敲代码,并没有深刻理解。现在想要研究chatbot了,才发现自己的coding水平急需加强,所以开这个系列记录自己一行行扣代码的过程。当然这不是从0开始的,只是把自己不理解的写出来,将来也可以作为资料备查。
最后还要重申一下,我没有系统学过编程,写这个系列就是想突破自己,各位大神请不吝赐教!
有用的工具
可以视觉化代码的网站https://pythontutor.com/visualize.html
代码出处
Pytorch的CHATBOT TUTORIAL
https://pytorch.org/tutorials/beginner/chatbot_tutorial.html?highlight=gpu%20training
目录
一步步读懂Pytorch Chatbot Tutorial代码(一) - 加载和预处理数据
一步步读懂Pytorch Chatbot Tutorial代码(二) - 数据处理
一步步读懂Pytorch Chatbot Tutorial代码(三) - 创建字典
一步步读懂Pytorch Chatbot Tutorial代码(四) - 为模型准备数据
一步步读懂Pytorch Chatbot Tutorial代码(五) - 定义模型
代码 Load and trim data
我们的下一个任务是创建词汇表并将查询/响应句子对加载到内存中。
注意,我们处理的是单词的序列,它们没有隐式映射到离散的数值空间。 因此,我们必须通过将数据集中遇到的每个唯一单词映射到一个索引值来创建一个索引。
为此,我们定义了一个Voc类,它保存从单词到索引的映射、索引到单词的反向映射、每个单词的计数和总单词计数。 该类提供了向词汇表中添加单词(addWord)、在句子中添加所有单词(addSentence)和trimming不常见单词(trim)的方法。 稍后会有更多关于trimming的内容。
# Default word tokens
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
class Voc:
def __init__(self, name):
self.name = name
self.trimmed = False
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count SOS, EOS, PAD
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1
# Remove words below a certain count threshold
def trim(self, min_count):
if self.trimmed:
return
self.trimmed = True
keep_words = []
for k, v in self.word2count.items():
if v >= min_count:
keep_words.append(k)
print('keep_words {} / {} = {:.4f}'.format(
len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)
))
# Reinitialize dictionaries
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count default tokens
for word in keep_words:
self.addWord(word)
现在我们可以组合我们的词汇和查询/回答句子对。 在准备使用这些数据之前,我们必须执行一些预处理。
首先,我们必须使用unicodeToAscii将Unicode字符串转换为ASCII。 接下来,我们应该将所有字母转换为小写字母,并修剪除基本标点符号(normalizeString)之外的所有非字母字符。 最后,为了帮助训练收敛,我们将过滤掉长度大于MAX_LENGTH阈值的句子(filterPairs)。
MAX_LENGTH = 10 # Maximum sentence length to consider
# Turn a Unicode string to plain ASCII, thanks to
# https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
s = re.sub(r"\s+", r" ", s).strip()
return s
# Read query/response pairs and return a voc object
def readVocs(datafile, corpus_name):
print("Reading lines...")
# Read the file and split into lines
lines = open(datafile, encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
voc = Voc(corpus_name)
return voc, pairs
# Returns True iff both sentences in a pair 'p' are under the MAX_LENGTH threshold
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH
# Filter pairs using filterPair condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
# Using the functions defined above, return a populated voc object and pairs list
def loadPrepareData(corpus, corpus_name, datafile, save_dir):
print("Start preparing training data ...")
voc, pairs = readVocs(datafile, corpus_name)
print("Read {!s} sentence pairs".format(len(pairs)))
pairs = filterPairs(pairs)
print("Trimmed to {!s} sentence pairs".format(len(pairs)))
print("Counting words...")
for pair in pairs:
voc.addSentence(pair[0])
voc.addSentence(pair[1])
print("Counted words:", voc.num_words)
return voc, pairs
# Load/Assemble voc and pairs
save_dir = os.path.join("data", "save")
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# Print some pairs to validate
print("\npairs:")
for pair in pairs[:10]:
print(pair)
类 class
类是抽象的模板, 详细内容可以看廖雪峰的介绍 https://www.liaoxuefeng.com/wiki/1016959663602400/1017496031185408
也可以参考这个视频 https://www.bilibili.com/video/BV1N5411t7EH?from=search&seid=3094138607375985455&spm_id_from=333.337.0.0
第一段代码Visualize:
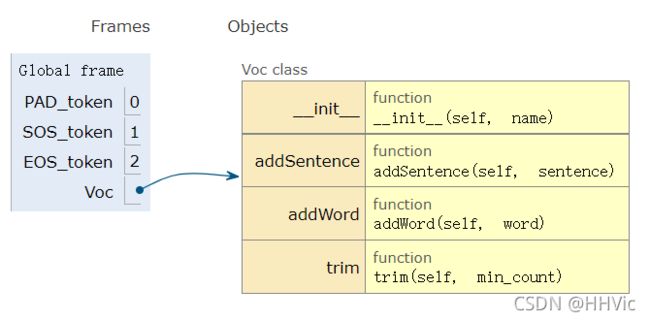
第二段代码Visualize:

_ _ init _ _ 初始化实例变量
__init__()的作用是初始化某个类的一个实例
self.name = name
self.trimmed = False
self.word2index = {} #单词到索引的映射
self.word2count = {} #单词出现的次数
#索引到单词的映射 index2word
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"} # 索引到单词映射
self.num_words = 3 # Count SOS, EOS, PAD 计算token字符的数量,起始为3
for word in sentence.split(’ ')
根据空格来提取每个单词, 举个栗子:
a='Good morning everyone!'
b=a.split(' ')
b
['Good', 'morning', 'everyone!']
self.addWord(word) 原来还可以这样调用类中的其他函数!!
addWord
伪代码如下:
假如上面sentence中第一个单词(Good)不在word2index 字典中:
字典word2index = {Good : 3}
字典word2count= {Good: 1} #代表Good单词出现了1次
字典index2word = {3 : Good}
num_words 自+1 # 总共出现词的个数
或者: #单词出现在word2index字典中,
字典word2count 自+1
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1
trim
这段函数目的是删除低频词,即低于min_count的token。由于低频词删除后,单词和索引的映射还是旧的,所以后半段代码重新初始化字典,生成新的单词和索引的映射以及其他字典。
没搞懂这里为什么会出现这段代码。
if self.trimmed:
return
self.trimmed = True
self.word2count.items() : 调用字典中的键值对, 举个栗子:
a={'one':1,'two':2}
a.items()
dict_items([('one', 1), ('two', 2)])
{:.4f} 取小数点后四位
a=3
b=4
print('a/b等于{:.4f}'.format(a/b))
a/b等于0.7500
unicodetoAscii
unicodedata函数更多介绍参考https://blog.csdn.net/weixin_43866211/article/details/98384017
使用unicodeToAscii将Unicode字符串转换为ASCII. 举个栗子:(中文字符一般不需要进行这个操作)
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
unicodeToAscii('Bonjour, ma chère.')
'Bonjour, ma chere.'
normalizeString
所有大写字母改小写,删减空白以及非字母的字符
s.lower().strip() 大写字母改小写并按空格分隔
s.re.sub() 详细介绍参考 https://blog.csdn.net/jackandsnow/article/details/103885422
- re.sub的函数原型为:re.sub(pattern, repl, string, count) 其中第二个函数是替换后的字符串;
第四个参数指替换个数。默认为0,表示每个匹配项都替换
其中的 r 是告诉编译器这是string,不要转译backslash
举个栗子:
其中 is 和 a 前面放了两个空格
s="This is a good question. I ##will $$$find [a] soluation for you ASAP!!! Do you have any more questions? "
s = unicodeToAscii(s.lower().strip())
s
Ouput:
'this is a good question. i ##will $$$find [a] soluation for you asap!!! do you have any more questions?'
在 . ! ? 三个符号前面加空格,后面的 \1 代表第一个加括号(bracketed)的group
s = re.sub(r"([.!?])", r" \1", s)
s
Output:
'this is a good question . i ##will $$$find [a] soluation for you asap ! ! ! do you have any more questions ?'
^ 代表取非a-zA-z.!?字符 + 代表多连续字符 ,将多余字符用空格代替
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
s
'this is a good question . i will find a soluation for you asap ! ! ! do you have any more questions ?'
将多余空格 详细\s介绍参考 https://blog.csdn.net/weixin_40426830/article/details/108743258
s = re.sub(r"\s+", r" ", s).strip()
s
'this is a good question . i will find a soluation for you asap ! ! ! do you have any more questions ?'
readVocs
\ 反斜杠后直接回车即可实现续行
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
lines = open(datafile, encoding='utf-8').\
read().strip().split('\n')
print(lines)
Output:
["Can we make this quick? Roxanne Korrine and Andrew Barrett are having an incredibly horrendous public break- up on the quad. Again.\tWell, I thought we'd start with pronunciation, if that's okay with you.",
"Well, I thought we'd start with pronunciation, if that's okay with you.\tNot the hacking and gagging and spitting part. Please.",
"Not the hacking and gagging and spitting part. Please.\tOkay... then how 'bout we try out some French cuisine. Saturday? Night?",
"You're asking me out. That's so cute. What's your name again?\tForget it.",
"No, no, it's my fault -- we didn't have a proper introduction ---\tCameron.",
"Cameron.\tThe thing is, Cameron -- I'm at the mercy of a particularly hideous breed of loser. My sister. I can't date until she does.",
normalizeString(s) for s in l.split('\t')] for l in lines 列表推导式层层分析如下:
可以看出这里将lines中的每段对白循环迭代给 l (由此我才发现,由于是电影台词的关系,问答对的句子并不是简单的一问一答。)
for l in lines:
print l
print('\n')
Output:
Can we make this quick? Roxanne Korrine and Andrew Barrett are having an incredibly horrendous public break- up on the quad. Again. Well, I thought we'd start with pronunciation, if that's okay with you.
Well, I thought we'd start with pronunciation, if that's okay with you. Not the hacking and gagging and spitting part. Please.
Not the hacking and gagging and spitting part. Please. Okay... then how 'bout we try out some French cuisine. Saturday? Night?
You're asking me out. That's so cute. What's your name again? Forget it.
for s in l.split('\t') 结果出乎我的意料,竟然只有一对对话内容,而且重新运行后内容不一样。
下面我会。
\t 代表4个空格 即TAB
for s in l.split('\t'):
print(s)
Output:
Most people can't hear me with the whole orchestra playing. You're good.
I don't have to take abuse from you. I have other people dying to give it to me.
换个方式来解释上面这句:这里就符合我们的预期
lines[0]
"Can we make this quick? Roxanne Korrine and Andrew Barrett are having an incredibly horrendous public break- up on the quad. Again.\tWell, I thought we'd start with pronunciation, if that's okay with you."
lines[0].split('\t')
['Can we make this quick? Roxanne Korrine and Andrew Barrett are having an incredibly horrendous public break- up on the quad. Again.',
"Well, I thought we'd start with pronunciation, if that's okay with you."]
voc = Voc(corpus_name)中 corpus_name 即 Voc类中的self.name
filterPair & filterPairs
filterPairs : 判断问答对单词是否低于MAX_LENGTH的阈值
MAX_LENGTH = 10 # Maximum sentence length to consider
# Returns True if both sentences in a pair 'p' are under the MAX_LENGTH threshold
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH
直观一点:
pairs[0][0]
Output:
'can we make this quick ? roxanne korrine and andrew barrett are having an incredibly horrendous public break up on the quad . again .'
pairs[0][0].split()
Output:
['can',
'we',
'make',
'this',
'quick',
'?',
'roxanne',
'korrine',
'and',
'andrew',
'barrett',
'are',
'having',
'an',
'incredibly',
'horrendous',
'public',
'break',
'up',
'on',
'the',
'quad',
'.',
'again',
'.']
len(pairs[0][0].split())<10
Output:
False
filterPairs : 利用filterPair函数来筛选pairs里面的句子, 将所有长度低于10 的句子放入pair
# Filter pairs using filterPair condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
之后根据上面两个函数,获得新的句子对Pairs , 总数64271。
pairs = filterPairs(pairs)
print("Read {!s} sentence pairs".format(len(pairs)))
Output:
Read 64271 sentence pairs
其余函数和上面写的有重复,可自行理解。
最终得到结果与网页一致:
Start preparing training data ...
Reading lines...
Read 221282 sentence pairs
Trimmed to 64271 sentence pairs
Counting words...
Counted words: 18008
pairs:
['there .', 'where ?']
['you have my word . as a gentleman', 'you re sweet .']
['hi .', 'looks like things worked out tonight huh ?']
['you know chastity ?', 'i believe we share an art instructor']
['have fun tonight ?', 'tons']
['well no . . .', 'then that s all you had to say .']
['then that s all you had to say .', 'but']
['but', 'you always been this selfish ?']
['do you listen to this crap ?', 'what crap ?']
['what good stuff ?', 'the real you .']
trimRareWords
另一个有助于在训练期间更快地实现衔接的策略是从我们的词汇表中删去很少使用的单词。减少特征空间也将降低模型必须学习近似的函数的难度。我们将分两步进行:
- 使用voc.trim函数修剪单词,使其低于
MIN_COUNT阈值。 - 用修剪过的单词过滤掉对。
voc.trim 根据上面写的函数介绍,删掉低频词,即出现次数低于3次的词。
MIN_COUNT = 3 # Minimum word count threshold for trimming
def trimRareWords(voc, pairs, MIN_COUNT):
# Trim words used under the MIN_COUNT from the voc
voc.trim(MIN_COUNT)
# Filter out pairs with trimmed words
keep_pairs = []
for pair in pairs:
input_sentence = pair[0]
output_sentence = pair[1]
keep_input = True
keep_output = True
# Check input sentence
for word in input_sentence.split(' '):
if word not in voc.word2index:
keep_input = False
break
# Check output sentence
for word in output_sentence.split(' '):
if word not in voc.word2index:
keep_output = False
break
# Only keep pairs that do not contain trimmed word(s) in their input or output sentence
if keep_input and keep_output:
keep_pairs.append(pair)
print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))
return keep_pairs
# Trim voc and pairs
pairs = trimRareWords(voc, pairs, MIN_COUNT)
结果与网页一致
keep_words 7823 / 18005 = 0.4345
Trimmed from 64271 pairs to 53165, 0.8272 of total