一步步读懂Pytorch Chatbot Tutorial代码(四) - 为模型准备数据
文章目录
- 自述
- 有用的工具
- 代码出处
- 目录
- 头大
- 代码及说明 Prepare Data for Models
-
-
- 重点关注
- indexesFromSentence
- zeroPadding
- binaryMatrix
- inputVar
- outputVar
- batch2TrainData
-
- 最后得到结果
自述
我是编程小白,别看注册时间长,但从事的不是coding工作,为了学AI才开始自学Python。
平时就是照着书上敲敲代码,并没有深刻理解。现在想要研究chatbot了,才发现自己的coding水平急需加强,所以开这个系列记录自己一行行扣代码的过程。当然这不是从0开始的,只是把自己不理解的写出来,将来也可以作为资料备查。
最后还要重申一下,我没有系统学过编程,写这个系列就是想突破自己,各位大神请不吝赐教!
有用的工具
可以视觉化代码的网站https://pythontutor.com/visualize.html
代码出处
Pytorch的CHATBOT TUTORIAL
https://pytorch.org/tutorials/beginner/chatbot_tutorial.html?highlight=gpu%20training
目录
一步步读懂Pytorch Chatbot Tutorial代码(一) - 加载和预处理数据
一步步读懂Pytorch Chatbot Tutorial代码(二) - 数据处理
一步步读懂Pytorch Chatbot Tutorial代码(三) - 创建字典
一步步读懂Pytorch Chatbot Tutorial代码(四) - 为模型准备数据
一步步读懂Pytorch Chatbot Tutorial代码(五) - 定义模型
头大
写到这里,感慨一下。因为是悲催的社畜,平时本来就忙,再加上时不时捣乱的印度‘熊弟’,最近忙到飞起,这几篇写的就非常的慢,导致每次开始看代码都要不停的往回翻来回想代码逻辑。 效率实在提不起来。
代码及说明 Prepare Data for Models
尽管我们花了大量精力准备数据,并将其转换成一个漂亮的词汇表对象和句子对列表,但我们的模型最终将期望把Tensor作为输入。在seq2seq translation tutorial中可以找到为模型准备处理数据的一种方法。在该教程中,我们使用1的批量大小,这意味着我们所要做的就是将句子对中的单词从词汇表转换为相应的索引,并将其提供给模型。
但是,如果您对加快训练或希望利用GPU并行化功能感兴趣,则需要使用小批量进行训练。
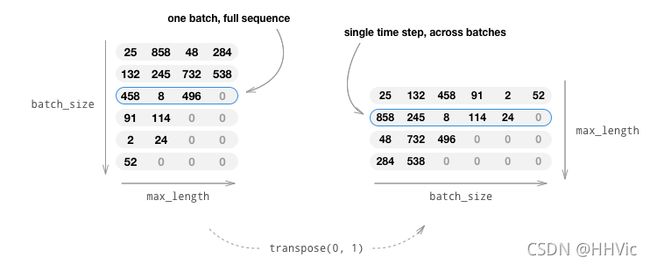
使用小批量也意味着我们必须注意批量中句子长度的变化。为了在同一批中容纳不同大小的句子,我们将创建批输入形状的张量(max_length , batch_size),其中小于max_length的句子在EOS_token后进行零填充。
如果我们简单地通过将单词转换为索引(IndexsFromSession)和零填充将英语句子转换为张量,我们的张量将具有形状(batch_size, max_length),对第一维度进行索引将返回所有时间步的完整序列。然而,我们需要能够在一段时间内以及在批次中的所有序列中对批次进行索引。因此,我们将输入批次形状转换为(max_length,batch_size),这样跨第一个维度的索引将跨批次中的所有句子返回一个时间步长。我们在zeroPadding函数中隐式地处理这个转置。
图片中的数字代表Word2index 中的值,也就是单词映射的index ID

inputVar函数处理将句子转换为张量的过程,最终创建形状正确的零填充张量。它还返回批次中每个序列的lengths张量,稍后将传递给我们的解码器。
outputVar函数执行与inputVar类似的函数,但它不返回lengths张量,而是返回二进制掩码张量和最大目标句子长度。二进制掩码张量的形状与输出目标张量的形状相同,但作为PAD_token的每个元素都是0,其他所有元素都是1。
batch2TrainData只需获取一组对,并使用上述函数返回输入和目标张量.
def indexesFromSentence(voc, sentence):
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
def zeroPadding(l, fillvalue=PAD_token):
return list(itertools.zip_longest(*l, fillvalue=fillvalue))
def binaryMatrix(l, value=PAD_token):
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
# Returns padded input sequence tensor and lengths
def inputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
padVar = torch.LongTensor(padList)
return padVar, lengths
# Returns padded target sequence tensor, padding mask, and max target length
def outputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
max_target_len = max([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
mask = binaryMatrix(padList)
mask = torch.BoolTensor(mask)
padVar = torch.LongTensor(padList)
return padVar, mask, max_target_len
# Returns all items for a given batch of pairs
def batch2TrainData(voc, pair_batch):
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
input_batch, output_batch = [], []
for pair in pair_batch:
input_batch.append(pair[0])
output_batch.append(pair[1])
inp, lengths = inputVar(input_batch, voc)
output, mask, max_target_len = outputVar(output_batch, voc)
return inp, lengths, output, mask, max_target_len
# Example for validation
small_batch_size = 5
batches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])
input_variable, lengths, target_variable, mask, max_target_len = batches
print("input_variable:", input_variable)
print("lengths:", lengths)
print("target_variable:", target_variable)
print("mask:", mask)
print("max_target_len:", max_target_len)
重点关注
下面先根据前面几章得到的结果来一层层推理本章的内容
先看voc.word2index
{'there': 3,
'.': 4,
'where': 5,
'?': 6,
'you': 7,
'have': 8,
'my': 9,
'word': 10,
'as': 11,
'a': 12,
'gentleman': 13,
're': 14,
'sweet': 15,
......
列表推导式(for表达式)
可以参考这里 http://c.biancheng.net/view/2231.html
indexesFromSentence
将句子中的单词转化成index ID, 举个栗子:
pairs[2][1]
Output:
'looks like things worked out tonight huh ?'
def indexesFromSentence(voc, sentence):
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
indexesFromSentence(voc,pairs[2][0])
indexesFromSentence(voc,pairs[2][1])
Output:
[16, 4, 2]
[17, 18, 19, 20, 21, 22, 23, 6, 2]
zeroPadding
将上面不定长的句子填充0到定长10
PAD_token = 0
itertools模块包含创建高效迭代器的函数,这些函数的返回值不是list,而是iterator(可迭代对象),可以用各种方式对数据执行循环操作.
zip_longest(it_obj1, …, it_objN, fillvalue=None) 其函数实现的功能和内置zip函数大致相同(实现一一对应),不过内置的zip函数是已元素最少对象为基准,而zip_longest函数是已元素最多对象为基准,使用fillvalue的值来填充
思路大致如此: 找出元素个数最多->算出元素个数差值->填充差值个元素到各个对象
举个栗子:
a=[16, 4, 2]
b=[17, 18, 19, 20, 21, 22, 23, 6, 2]
c=list(zip(a,b))
c
Output:
[(16, 17), (4, 18), (2, 19)]
c=list(itertools.zip_longest(a,b))
c
[(16, 17),
(4, 18),
(2, 19),
(None, 20),
(None, 21),
(None, 22),
(None, 23),
(None, 6),
(None, 2)]
* 在这里代表所有列表,再举个栗子
a=[[16, 4, 2],[17, 18, 19, 20, 21, 22, 23, 6, 2]]
list(itertools.zip_longest(*a))
Output:
[(16, 17),
(4, 18),
(2, 19),
(None, 20),
(None, 21),
(None, 22),
(None, 23),
(None, 6),
(None, 2)]
binaryMatrix
将上面的矩阵转换成由0和1组成的矩阵
这里的 l 已经根据之前的函数变成了由index 和 0 组成的矩阵 比如这样
a=[[16, 4, 2],[17, 18, 19, 20, 21, 22, 23, 6, 2]]
d=list(itertools.zip_longest(*a,fillvalue=0))
d
Output:
[(16, 17),
(4, 18),
(2, 19),
(0, 20),
(0, 21),
(0, 22),
(0, 23),
(0, 6),
(0, 2)]
# 带入函数之后得到结果:
ef binaryMatrix(l, value=PAD_token):
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
binary_d=binaryMatrix(d)
binary_d
Output:
[[1, 1], [1, 1], [1, 1], [0, 1], [0, 1], [0, 1], [0, 1], [0, 1], [0, 1]]
inputVar
torch.Tensor和torch.tensor区别如下
https://blog.csdn.net/weixin_42018112/article/details/91383574
def inputVar(l, voc):这里的l代表你输入的需要提问的句子
indexes_batch 代表输入句子中每个单词的index ID
lengths 是list,代表每个句子的实际长度,长度为(batch, )
padList 补齐index ID
padVar 是一个LongTensor,shape是(batch, max_length)
outputVar
max()函数
https://www.runoob.com/python3/python3-func-number-max.html
max_target_len 这里只取了最大长度的indexes
padList 返回最大最长句子的长度(也就是padding后的长度)
padVar是LongTensor,shape是 batch, max_target_length)
mask是ByteTensor,shape也是 (batch, max_target_length)
原文中的错误: 这里应该是ByteTensor mask = torch.ByteTensor(mask)
batch2TrainData
这里处理一个batch的pair句对 ,这里的pair来自上一章最后的一句
pairs = trimRareWords(voc, pairs, MIN_COUNT)
lamda表达式
https://blog.csdn.net/qq_39226755/article/details/86773171
按照句子的长度排序 pair_batch.sort
随机选择句子 random.choice(pairs)
_本身无意义,用i也可以 for _ in range(small_batch_size)
这里可以再回到本文开头,看下文字说明
最后得到结果
input_variable: tensor([[ 307, 334, 25, 16, 142],
[ 492, 101, 356, 4, 6],
[2613, 24, 7, 2, 2],
[ 344, 36, 349, 0, 0],
[ 4, 6, 4, 0, 0],
[ 2, 2, 2, 0, 0]])
lengths: tensor([6, 6, 6, 3, 3])
target_variable: tensor([[ 50, 124, 141, 25, 53],
[ 6, 318, 83, 94, 403],
[ 2, 4, 558, 117, 122],
[ 0, 2, 4, 359, 53],
[ 0, 0, 2, 7, 108],
[ 0, 0, 0, 22, 4],
[ 0, 0, 0, 4, 2],
[ 0, 0, 0, 2, 0]])
mask: tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 1, 0]], dtype=torch.uint8)
max_target_len: 8