大促之前全链路压测监控
1. skywalking服务监控
1.1 skywalking简介
Skywalking 是一个APM系统,即应用性能监控系统,为微服务架构和云原生架构系统设计
它通过探针自动收集所需的指标,并进行分布式追踪,通过这些调用链路以及指标,Skywalking APM会感知应用间关系和服务间关系,并进行相应的指标统计,目前支持链路追踪和监控应用组件如下,基本涵盖主流框架和容器,如国产PRC Dubbo和motan等,国际化的spring boot,spring cloud都支持了
SkyWalking是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8S、Mesos)架构而设计
SkyWalking是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案
1.1.1 SkyWalking组件
- Skywalking Agent: 采集
tracing(调用链数据)和metric(指标)信息并上报,上报通过HTTP或者gRPC方式发送数据到Skywalking Collector - Skywalking Collector : 链路数据收集器,对agent传过来的
tracing和metric数据进行整合分析通过Analysis Core模块处理并落入相关的数据存储中,同时会通过Query Core模块进行二次统计和监控告警 - Storage: Skywalking的存储,支持以
ElasticSearch、Mysql、TiDB、H2等作为存储介质进行数据存储 - UI: Web可视化平台,用来展示落地的数据,目前官方采纳了RocketBot作为SkyWalking的主UI
1.2 配置SkyWalking
1.2.1 下载SkyWalking
下载SkyWalking的压缩包,解压后将压缩包里面的agent文件夹放进本地磁盘,探针包含整个目录,请不要改变目录结构。
1.2.2 Agent配置
通过了解配置,可以对一个组件功能有一个大致的了解,解压开skywalking的压缩包,在agent/config文件夹中可以看到agent的配置文件,从skywalking支持环境变量配置加载,在启动的时候优先读取环境变量中的相关配置。
| skywalking配置名称 | 描述 |
|---|---|
| agent.namespace | 跨进程链路中的header,不同的namespace会导致跨进程的链路中断 |
| agent.service_name | 一个服务(项目)的唯一标识,这个字段决定了在sw的UI上的关于service的展示名称 |
| agent.sample_n_per_3_secs | 客户端采样率,每三秒中采样的条数,0或者负数标识禁用,默认-1 |
| agent.authentication | 与collector进行通信的安全认证,需要同collector中配置相同 |
| agent.ignore_suffix | 忽略特定请求后缀的trace |
| collecttor.backend_service | agent需要同collector进行数据传输的IP和端口 |
| logging.level | agent记录日志级别 |
skywalking agent使用javaagent无侵入式的配合collector实现对分布式系统的追踪和相关数据的上下文传递。
1.2.3 配置探针
配置SpringBoot启动参数,需要填写如下的运行参数,代码放在后面,需要的自己粘贴。
-javaagent:D:/data/skywalking/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=storage-server
-Dskywalking.collector.backend_service=172.18.0.50:11800

- javaagent:复制的agent目录下探针的jar包路径
- skywalking.agent.service_name:需要在skywalking显示的服务名称
- skywalking.collector.backend_service:skywalking服务端地址默认是11800
2. Arthas服务诊断

2.1 Arthas是什么
Arthas是Alibaba开源的Java诊断工具,深受开发者喜爱,在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态
Arthas 支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
2.2 Arthas能做什么
当你遇到以下类似问题而束手无策时,
Arthas可以帮助你解决:

Arthas采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
2.3 安装使用
2.3.1 快速安装
下载
arthas-boot.jar,然后用java -jar的方式启动
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar

2.4 启动arthas
在命令行下面执行(使用和目标进程一致的用户启动,否则可能attach失败):
java -jar arthas-boot.jar
- 执行该程序的用户需要和目标进程具有相同的权限。比如以
admin用户来执行:sudo su admin && java -jar arthas-boot.jar或sudo -u admin -EH java -jar arthas-boot.jar。 - 如果attach不上目标进程,可以查看
~/logs/arthas/目录下的日志。 - 如果下载速度比较慢,可以使用aliyun的镜像:
java -jar arthas-boot.jar --repo-mirror aliyun --use-http java -jar arthas-boot.jar -h打印更多参数信息。
2.5 选择java进程
在打印的java进程中选择一个需要
attach的进程, 这里选择4这个order-service的java进程

2.6 命令列表
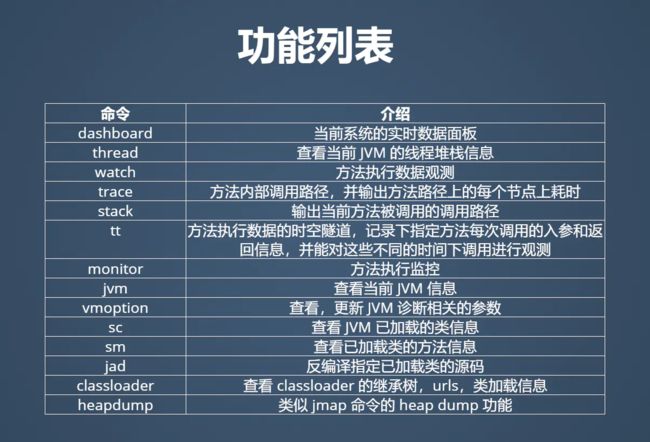
2.7 线程命令
2.7.1 dashboard指令
当前系统的实时数据面板,按 ctrl+c 退出。
当运行在服务时,会显示当前服务的实时信息,如HTTP请求的qps, rt, 错误数, 线程池信息等等。
2.7.1.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| [i:] | 刷新实时数据的时间间隔 (ms),默认5000ms |
| [n:] | 刷新实时数据的次数 |
2.7.1.2 使用
在Arthas中输入
dashboard命令会得到如下界面
dashboard

2.7.1.3 线程参数解释
- ID: Java级别的线程ID,注意这个ID不能跟jstack中的nativeID一一对应。
- NAME: 线程名
- GROUP: 线程组名
- PRIORITY: 线程优先级, 1~10之间的数字,越大表示优先级越高
- STATE: 线程的状态
- CPU%: 线程的cpu使用率。比如采样间隔1000ms,某个线程的增量cpu时间为100ms,则cpu使用率=100/1000=10%
- DELTA_TIME: 上次采样之后线程运行增量CPU时间,数据格式为
秒 - TIME: 线程运行总CPU时间,数据格式为
分:秒 - INTERRUPTED: 线程当前的中断位状态
- DAEMON: 是否是daemon线程
2.7.2 thread相关指令
查看当前线程信息,查看线程的堆栈
2.7.2.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| id | 线程id |
| [n:] | 指定最忙的前N个线程并打印堆栈 |
| [b] | 找出当前阻塞其他线程的线程 |
[i |
指定cpu使用率统计的采样间隔,单位为毫秒,默认值为200 |
| [–all] | 显示所有匹配的线程 |
2.7.2.2 cpu使用率如何统计
这里的cpu使用率与linux 命令
top -H -p的线程%CPU类似,一段采样间隔时间内,当前JVM里各个线程的增量cpu时间与采样间隔时间的比例。
2.7.2.3 工作原理
-
首先第一次采样,获取所有线程的CPU时间(调用的是
java.lang.management.ThreadMXBean#getThreadCpuTime()及sun.management.HotspotThreadMBean.getInternalThreadCpuTimes()接口) -
然后睡眠等待一个间隔时间(默认为200ms,可以通过
-i指定间隔时间) -
再次第二次采样,获取所有线程的CPU时间,对比两次采样数据,计算出每个线程的增量CPU时间
-
线程CPU使用率 = 线程增量CPU时间 / 采样间隔时间 * 100%
注意: 这个统计也会产生一定的开销(JDK这个接口本身开销比较大),因此会看到as的线程占用一定的百分比,为了降低统计自身的开销带来的影响,可以把采样间隔拉长一些,比如5000毫秒。
2.7.2.4 JVM内部线程
Java 8之后支持获取JVM内部线程CPU时间,这些线程只有名称和CPU时间,没有ID及状态等信息(显示ID为-1), 通过内部线程可以观测到JVM活动,如GC、JIT编译等占用CPU情况,方便了解JVM整体运行状况。
- 当JVM 堆(heap)/元数据(metaspace)空间不足或OOM时,可以看到GC线程的CPU占用率明显高于其他的线程
- 当执行
trace/watch/tt/redefine等命令后,可以看到JIT线程活动变得更频繁,因为JVM热更新class字节码时清除了此class相关的JIT编译结果,需要重新编译。
JVM内部线程包括下面几种:
- JIT编译线程: 如
C1 CompilerThread0,C2 CompilerThread0 - GC线程: 如
GC Thread0,G1 Young RemSet Sampling - 其它内部线程: 如
VM Periodic Task Thread,VM Thread,Service Thread
2.7.2.5 显示线程列表
输入thread 列出来线程列表,默认按照CPU增量时间降序排列,只显示第一页数据。
thread
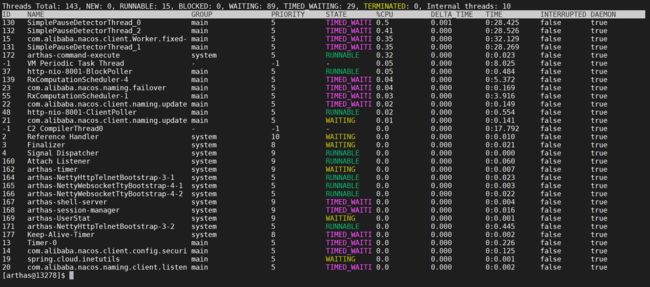
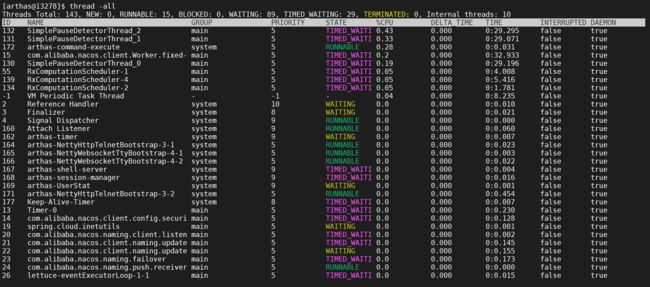
2.7.2.6 显示所有线程
显示所有匹配线程信息,有时需要获取全部JVM的线程数据进行分析。
thread -all
2.7.2.7 打印线程堆栈
通过
thread id命令, 显示指定线程的运行堆栈, 看下139这个线程的堆栈信息
thread 139
这样可以打印出来线程139的堆栈以及调用关系

2.7.2.8 排查死锁
找出当前阻塞其他线程的线程
有时候会发现应用卡住了, 通常是由于某个线程拿住了某个锁, 并且其他线程都在等待这把锁造成的。 为了排查这类问题, arthas提供了thread -b, 一键找出那个罪魁祸首。
thread -b
发现当前没有发现阻塞其他线程的线程
![]()
2.8 虚拟机命令
2.8.1 jvm相关指令
查看当前JVM信息
2.8.1.1 查看JVM信息
jvm 命令可以打印出当前微服务jvm相关的参数
jvm

Thread相关

参数解释
- COUNT: JVM当前活跃的线程数
- DAEMON-COUNT: JVM当前活跃的守护线程数
- PEAK-COUNT: 从JVM启动开始曾经活着的最大线程数
- STARTED-COUNT: 从JVM启动开始总共启动过的线程次数
- DEADLOCK-COUNT: JVM当前死锁的线程数
2.8.2 JVM选项指令
查看,更新VM诊断相关的参数
2.8.2.1 查看相关选项
通过该命令可以看到当前jvm的一些参数选项
vmoption

2.8.2.2 查看指定选项
这里查看是否打开了
PrintGCDetails
vmoption PrintGCDetails
![]()
2.8.2.3 更新选项
可以使用arthas对jvm的选项进行更新,这里开启
PrintGCDetails
vmoption PrintGCDetails true

2.9 类相关命令
2.9.1 搜索相关类
查看JVM已加载的类信息,SC是“Search-Class” 的简写,这个命令能搜索出所有已经加载到 JVM 中的 Class 信息
2.9.1.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-pattern | 方法名表达式匹配 |
| [d] | 输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的ClassLoader等详细信息。 如果一个类被多个ClassLoader所加载,则会出现多次 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
| [f] | 输出当前类的成员变量信息(需要配合参数-d一起使用) |
| [x:] | 指定输出静态变量时属性的遍历深度,默认为 0,即直接使用 toString 输出 |
[c:] |
指定class的 ClassLoader 的 hashcode |
[classLoaderClass:] |
指定执行表达式的 ClassLoader 的 class name |
[n:] |
具有详细信息的匹配类的最大数量(默认为100) |
class-pattern支持全限定名,如com.黑马.test.AAA,也支持com/黑马/test/AAA这样的格式,这样,从异常堆栈里面把类名拷贝过来的时候,不需要在手动把
/替换为.啦。
sc 默认开启了子类匹配功能,也就是说所有当前类的子类也会被搜索出来,想要精确的匹配,请打开
options disable-sub-class true开关
2.9.2.2 模糊搜索
该命令可以搜索
com.demo.fulllink下面的包以及子包的类
sc com.demo.fulllink.*
2.9.2.3 打印类的详细信息
可以使用 -d 参数打印 类的详细信息
sc -d com.demo.fulllink.module.po.OrderPO
2.9.2.4 打印出类的Field信息
该命令可以打印类中字段信息,可以看到各种字段的介绍
sc -d -f com.demo.fulllink.module.po.OrderPO
2.9.2 搜索相关方法
sm是“Search-Method” 的简写,这个命令能搜索出所有已经加载了 Class 信息的方法信息。
sm命令只能看到由当前类所声明 (declaring) 的方法,父类则无法看到。
2.9.2.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-pattern | 方法名表达式匹配 |
| [d] | 展示每个方法的详细信息 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
[c:] |
指定class的 ClassLoader 的 hashcode |
[classLoaderClass:] |
指定执行表达式的 ClassLoader 的 class name |
[n:] |
具有详细信息的匹配类的最大数量(默认为100) |
2.9.2.2 查看类的方法
查看
com.demo.fullink.service.impl.AsyncOrderServiceImpl类的相关方法
sm com.demo.fullink.service.impl.AsyncOrderServiceImpl
可以看到该方法有两个方法actualPlaceOrder以及processOrder
2.9.2.3 查看方法信息信息
通过
-d可以看到方法的详细信息
sm -d com.demo.fullink.service.impl.AsyncOrderServiceImpl
通过-d参数可以看到方法的详细信息
2.9.2.4 查看具体方法信息
可以在类名后面加入加入方法名称就可以查看具体的方法详情
sm -d com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder
2.9.3 反编译
jad命令将 JVM 中实际运行的 class 的 byte code 反编译成 java 代码,便于你理解业务逻辑;
- 在 Arthas Console 上,反编译出来的源码是带语法高亮的,阅读更方便
- 当然,反编译出来的 java 代码可能会存在语法错误,但不影响你进行阅读理解
2.9.3.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
[c:] |
类所属 ClassLoader 的 hashcode |
[classLoaderClass:] |
指定执行表达式的 ClassLoader 的 class name |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
2.9.3.2 反编译类
可以将jvm内存中的类进行反编译
jad com.demo.fullink.service.impl.AsyncOrderServiceImpl
反编译后信息比较全面,有类加载等信息
2.9.3.3 只显示源代码
默认情况下,反编译结果里会带有
ClassLoader信息,通过--source-only选项,可以只打印源代码。
jad --source-only com.demo.fullink.service.impl.AsyncOrderServiceImpl
通过
--source-only后就没有了类加载等信息
2.9.3.4 反编译指定的方法
有时候可以反编译类中的指定方法
jad --source-only com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder
这样只会反编译对应的方法的代码
2.9.3.5 不显示行号
有时候不需要打印行号,可以使用
--lineNumber参数来设置是否显示行号,默认值为true,显示指定为false则不打印行号
jad --source-only com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder --lineNumber false
通过这种方式可以不显示具体行号
2.10 监控相关命令
2.10.1 方法执行监控
monitor命令是一个非实时返回命令,对匹配class-pattern/method-pattern/condition-express的类、方法的调用进行监控。
实时返回命令是输入之后立即返回,而非实时返回的命令,则是不断的等待目标 Java 进程返回信息,直到用户输入 Ctrl+C 为止。
服务端是以任务的形式在后台跑任务,植入的代码随着任务的中止而不会被执行,所以任务关闭后,不会对原有性能产生太大影响,而且原则上,任何Arthas命令不会引起原有业务逻辑的改变。
2.10.1.1 监控的维度说明
| 监控项 | 说明 |
|---|---|
| timestamp | 时间戳 |
| class | Java类 |
| method | 方法(构造方法、普通方法) |
| total | 调用次数 |
| success | 成功次数 |
| fail | 失败次数 |
| rt | 平均RT |
| fail-rate | 失败率 |
2.10.1.2 参数说明
方法拥有一个命名参数
[c:],意思是统计周期(cycle of output),拥有一个整型的参数值
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-pattern | 方法名表达式匹配 |
| condition-express | 条件表达式 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
[c:] |
统计周期,默认值为120秒 |
| [b] | 在方法调用之前计算condition-express |
2.10.1.3 打印方法调用
monitor -c 20 com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder
这样每隔20秒打印一次
actualPlaceOrder方法的调用信息
2.10.2 查看方法参数
watch让你能方便的观察到指定方法的调用情况。能观察到的范围为:返回值、抛出异常、入参,通过编写 OGNL 表达式进行对应变量的查看。
2.10.2.1 参数说明
watch 的参数比较多,主要是因为它能在 4 个不同的场景观察对象
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-pattern | 方法名表达式匹配 |
| express | 观察表达式 |
| condition-express | 条件表达式 |
| [b] | 在方法调用之前观察 |
| [e] | 在方法异常之后观察 |
| [s] | 在方法返回之后观察 |
| [f] | 在方法结束之后(正常返回和异常返回)观察 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
| [x:] | 指定输出结果的属性遍历深度,默认为 1 |
2.10.2.2 观察表达式
这里重点要说明的是观察表达式,观察表达式的构成主要由 ognl 表达式组成,所以你可以这样写"{params,returnObj}",只要是一个合法的 ognl 表达式,都能被正常支持。
2.10.2.3 使用说明
- watch 命令定义了4个观察事件点,即
-b方法调用前,-e方法异常后,-s方法返回后,-f方法结束后 - 4个观察事件点
-b、-e、-s默认关闭,-f默认打开,当指定观察点被打开后,在相应事件点会对观察表达式进行求值并输出 - 这里要注意
方法入参和方法出参的区别,有可能在中间被修改导致前后不一致,除了-b事件点params代表方法入参外,其余事件都代表方法出参 - 当使用
-b时,由于观察事件点是在方法调用前,此时返回值或异常均不存在
2.10.2.4 方法调用前
通过该命令可以查看到方法调用前的
actualPlaceOrder方法第一个参数的入参信息
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0],returnObj}" -b

看到入参是对象,但是看不到对象的具体数据,可以使用
-x表示遍历深度,可以调整来打印具体的参数和结果内容,默认值是1
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0],returnObj}" -x 2 -b
遍历的深度设置为两层,这样就可以看到对象里面的属性
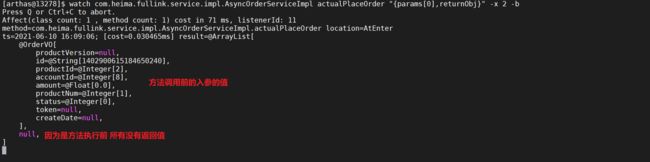
2.10.2.5 方法调用后
通过该命令可以查看到方法调用后的
actualPlaceOrder方法第一个参数的入参信息和返回值
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0],returnObj}" -x 2
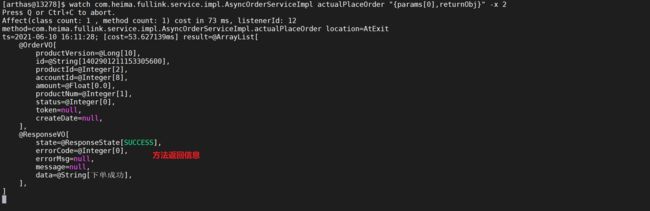
在方法返回调用后监控参数获取到了方法的返回结果
2.10.2.6 方法调用前后
有时候需要查看方法执行前后的结果信息,可以使用如下的形式查看
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0].amount,returnObj}" -x 2 -b -s -n 2
这样可以查看方法的执行前后的参数信息
- 参数里
-n 2,表示只执行两次 - 这里输出结果中,第一次输出的是方法调用前的观察表达式的结果,第二次输出的是方法返回后的表达式的结果
- 结果的输出顺序和事件发生的先后顺序一致,和命令中
-s -b的顺序无关
2.10.2.7 条件表达式
查看参数还支持查看满足特定条件后才会打印参数
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0],returnObj}" "params[0].amount>100" -x 2
只有满足
amount参数大于100的数据才会打印参数信息
2.10.2.8 查看耗时慢的参数
有时候需要查看因为那些参数导致服务速度慢,可以使用如下的形式
watch com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "{params[0],returnObj}" "#cost>50" -x 2
这样只有方法调用耗时大于50ms的方法才会打印参数信息
2.10.3 链路追踪
方法内部调用路径,并输出方法路径上的每个节点上耗时
trace 命令能主动搜索 class-pattern/method-pattern 对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
2.10.3.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-pattern | 方法名表达式匹配 |
| condition-express | 条件表达式 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
[n:] |
命令执行次数 |
#cost |
方法执行耗时 |
2.10.3.2 跟踪方法
能够跟踪方法的调用链信息,并且可以打印方法调用耗时
trace com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder
2.10.3.3 限制次数
如果方法调用的次数很多,那么可以用
-n参数指定捕捉结果的次数。比如下面的例子里,捕捉到一次调用就退出命令。
trace com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder -n 1
2.10.3.4 根据耗时过滤
有时候只要查看耗时时间长的调用的方法,可以使用如下方式
trace com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder '#cost > 80' -n 1
只会展示耗时大于80ms的调用路径,有助于在排查问题的时候,只关注异常情况
2.10.4 调用路径
输出当前方法被调用的调用路径
很多时候都知道一个方法被执行,但这个方法被执行的路径非常多,或者你根本就不知道这个方法是从那里被执行了,此时你需要的是 stack 命令。
2.10.4.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| class-pattern | 类名表达式匹配 |
| method-patter | 方法名表达式匹配 |
| condition-express | 条件表达式 |
| [E] | 开启正则表达式匹配,默认为通配符匹配 |
[n:] |
执行次数限制 |
2.10.4.2 查看方法调用
stack com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder
这样就可以看到
actualPlaceOrder是从什么地方调用过来的
2.10.4.3 根据条件过滤
有时候只需要看特定条件的的调用路径,可以使用如下形式
stack com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder "params[0].amount>100" -n 1
只需要打印金额大于100的调用链,并且只需要打印一次
2.10.4.4 根据耗时过滤
有时候只需要过滤耗时长的调用路径,可以使用如下的形式
stack com.demo.fullink.service.impl.AsyncOrderServiceImpl actualPlaceOrder '#cost > 80' -n 1
只打印耗时大于80ms的方法调用路径
2.10.5 生成火焰图
profiler命令支持生成应用热点的火焰图。本质上是通过不断的采样,然后把收集到的采样结果生成火焰图。
2.10.5.1 参数说明
| 参数名称 | 参数说明 |
|---|---|
| action | 要执行的操作 |
| actionArg | 属性名模式 |
| [i:] | 采样间隔(单位:ns)(默认值:10’000’000,即10 ms) |
| [f:] | 将输出转储到指定路径 |
| [d:] | 运行评测指定秒 |
| [e:] | 要跟踪哪个事件(cpu, alloc, lock, cache-misses等),默认是cpu |
2.10.5.2 启动profile
默认情况下,生成的是cpu的火焰图,即event为
cpu。可以用--event参数来指定
profiler start
![]()
进行服务压测
2.10.5.3 查看profiler状态
可以查看当前profiler在采样哪种
event和采样时间。
profiler status
![]()
2.10.5.4 停止profiler
profiler stop
停止后会自动生成svg格式的文件
![]()
默认情况下,生成的结果保存到应用的工作目录下的arthas-output目录。可以通过 --file参数来指定输出结果路径。比如:
profiler stop --file /tmp/output.svg
![]()
2.10.5.5 生成html格式结果
默认情况下,结果文件是
svg格式,如果想生成html格式,可以用--format参数指定:
profiler stop --format html
![]()
或者在
--file参数里用文件名指名格式。比如--file /tmp/result.html
2.10.5.6 查看结果
通过浏览器查看arthas-output下面的profiler结果,默认情况下,arthas使用3658端口,但是一般不允许外部IP访问,可以下载到本地查看

3. 生产环境部署服务
3.1 环境服务列表
需要在虚拟机或者linux服务器启动运行环境
| 服务 | ip | 端口 | 备注 |
|---|---|---|---|
| mysql | 172.18.0.10 | 3306 | 数据库服务 |
| rabbitMQ | 172.18.0.20 | 5672,5672 | RabbitMQ消息服务 |
| redis | 172.18.0.30 | 6379 | Redis缓存服务 |
| nacos | 172.18.0.40 | 8848 | 微服务注册中心 |
| skywalking | 172.18.0.50 | 1234,11800,12800 | 链路追踪APM服务端 |
| skywalking-ui | 172.18.0.60 | 8080 | 链路追踪APM服务UI端 |
3.2 应用服务列表
应用服务可以单独部署或者在idea中启动
| 服务 | ip | 端口 | 备注 |
|---|---|---|---|
| order-service | 192.168.64.177 | 8001 | 订单服务 |
| account-service | 192.168.64.177 | 8002 | 账户服务 |
| storage-service | 192.168.64.177 | 8003 | 数据存储服务 |
| notice-service | 192.168.64.177 | 8004 | 通知服务 |
3.3 docker-compose 编排环境
docker-compose只对环境进行了搭建,具体微服务在本地运行或者在容器运行都可以。
version: '2'
services:
mysql:
image: mysql:5.7
hostname: mysql
container_name: mysql
networks:
docker-network:
ipv4_address: 172.18.0.10
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: root
volumes:
- "/tmp/etc/mysql:/etc/mysql/conf.d"
- "/tmp/data/mysql:/var/lib/mysql"
rabbitMQ:
image: rabbitmq:management
hostname: rabbitMQ
container_name: rabbitMQ
networks:
docker-network:
ipv4_address: 172.18.0.20
ports:
- "5672:5672"
- "15672:15672"
redis:
image: redis
hostname: redis
container_name: redis
networks:
docker-network:
ipv4_address: 172.18.0.30
ports:
- "6379:6379"
volumes:
- "/tmp/etc/redis/redis.conf:/etc/redis/redis.conf"
- "/tmp/data/redis:/data"
command:
redis-server /etc/redis/redis.conf
nacos:
image: nacos/nacos-server
hostname: nacos
container_name: nacos
depends_on:
- mysql
networks:
docker-network:
ipv4_address: 172.18.0.40
ports:
- "8848:8848"
environment:
MODE: standalone
volumes:
- "/tmp/etc/nacos/application.properties:/home/nacos/conf/application.properties"
skywalking:
image: apache/skywalking-oap-server
hostname: skywalking
container_name: skywalking
networks:
docker-network:
ipv4_address: 172.18.0.50
ports:
- "1234:1234"
- "11800:11800"
- "12800:12800"
skywalkingui:
image: apache/skywalking-ui
hostname: skywalkingui
container_name: skywalkingui
depends_on:
- skywalking
networks:
docker-network:
ipv4_address: 172.18.0.60
environment:
SW_OAP_ADDRESS: 172.18.0.50:12800
ports:
- "8080:8080"
networks:
docker-network:
ipam:
config:
- subnet: 172.18.0.0/16
gateway: 172.18.0.1
3.4 初始化数据
3.4.1 MySQL环境初始化
3.4.1.1 配置MySQL忽略大小写
创建MySQL挂载目录,等会会解释什么是挂载路径
# 创建MySQL配置的文件夹
mkdir -p /tmp/etc/mysql
# 编辑my.cnf配置文件
vi /tmp/etc/mysql/my.cnf
配置MySQL忽略大小写,在创建的MySQL配置文件挂载点的目录的my.cnf文件加入如下内容
[mysqld]
lower_case_table_names=1
3.4.1.2 创建MySQL数据目录
因为默认MySQL启动后他的文件是在容器中的,如果删除容器,数据也将会消失,需要将数据挂载出来。
#创建mysql存储的目录
mkdir -p /tmp/data/mysql
3.4.2 Redis环境初始化
3.4.2.1 创建Redis配置文件
创建Redis配置文件
mkdir -p /tmp/etc/redis/redis.conf
vi /tmp/etc/redis/redis.conf
可以到这个地址下载配置Reids配置
https://redis.io/docs/manual/config/
3.4.2.2 创建Redis数据目录
mkdir -p /tmp/data/mysql
3.4.3 nacos环境配置
3.4.3.1 创建配置文件目录
创建Nacos配置目录
mkdir -p /tmp/etc/nacos/
3.4.3.2 创建Nacos配置文件
在nacos新增
Data ID为full-link-pressure-common类型位yaml的配置,将feign,hystrix,ribbon等统一配置配置到nacos
# 配置超时时间
feign:
hystrix:
enabled: true #开启熔断
httpclient:
enabled: true
hystrix:
threadpool:
default:
coreSize: 50
maxQueueSize: 1500
queueSizeRejectionThreshold: 1000
command:
default:
execution:
timeout:
enabled: true
isolation:
thread:
timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 10000
ReadTimeout: 50000
3.5 准备工作
3.5.1 安装Agent
将部署在本地的agent复制到
centos主机中的/usr/local/agent目录下

3.5.2 打包微服务
将微服务打包并上传到centos中

打包后并上传到centos中去

3.5.3 配置启动脚本
3.5.3.1 编写启动脚本
在启动脚本中加入对于jvm内存的限制以及对
skywalking的配置
vi start.sh
#!/bin/bash
# 启动account-service
nohup java -jar account-service-1.0-SNAPSHOT.jar -Xms128m -Xmx128m -javaagent:/usr/local/agent/skywalking-agent.jar -Dskywalking.agent.service_name=Account-server > logs/account-service.out 2>&1 &
# 启动storage-service
nohup java -jar storage-service-1.0-SNAPSHOT.jar -Xms128m -Xmx128m -javaagent:/usr/local/agent/skywalking-agent.jar -javaagent:/usr/local/agent/skywalking-agent.jar -Dskywalking.agent.service_name=storage-service > logs/storage-service.out 2>&1 &
# 启动order-service
nohup java -jar order-service-1.0-SNAPSHOT.jar -Xms128m -Xmx128m -javaagent:/usr/local/agent/skywalking-agent.jar -Dskywalking.agent.service_name=order-service > logs/order-service.out 2>&1 &
# 启动notice-service
nohup java -jar notice-service-1.0-SNAPSHOT.jar -Xms128m -Xmx128m -javaagent:/usr/local/agent/skywalking-agent.jar -Dskywalking.agent.service_name=notice-service > logs/notice-service.out 2>&1 &
# 启动gateway-server
nohup java -jar gateway-server-1.0-SNAPSHOT.jar -Xms128m -Xmx128m -javaagent:/usr/local/agent/skywalking-agent.jar -Dskywalking.agent.service_name=gateway-server > logs/gateway-server.out 2>&1 &

3.5.3.2 创建一个log目录
mkdir logs
3.5.3.3 配置sh权限
chmod 755 start.sh
3.5.3.4 完整结构如下

3.5.4 配置数据库访问权限
需要配置数据库的外网访问权限
GRANT ALL PRIVILEGES ON fulllink.* TO 'root'@'%' IDENTIFIED BY 'root';
GRANT ALL PRIVILEGES ON `fulllink-shadow`.* TO 'root'@'%' IDENTIFIED BY 'root';
FLUSH PRIVILEGES;
3.6 启动微服务
3.6.1 执行启动脚本
# 启动微服务集群
./start.sh
# 查看java进程
ps -ef|grep java

3.6.2 nacos查看注册列表
访问
http://116.62.213.90:9105/nacos进入nacos注册列表

服务都已经注册了
3.6.3 测试接口
使用postman测试服务接口是否正常,访问发现是是可以正常访问的

3.6.4 查看skyworking
4. 压测调优
4.1 jmeter配置
配置好压测数据,并且配置压测线程数1000 进行10轮压测
4.2 第一轮压测
4.2.1 链路分析优化
找到一个调用时长1S左右的链路,分析发现在存储服务调用时,耗时较长,但是数据库调用耗时并不长,基本说明是存储服务的连接池耗尽导致调用过长。

4.2.1.1 数据库连接池优化
调整存储服务的连接池,由原来的最大10 改为100
initialSize: 10
minIdle: 20
maxActive: 100
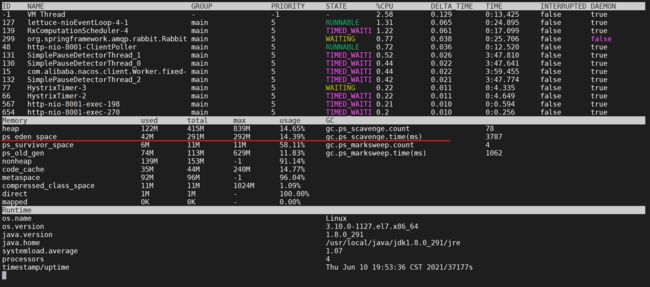
4.2.2 查看JVM内存
jvm的中的老年代并没有太大的变化,说明JVM不需要怎么优化

并且发现eden区每隔一段时间就会垃圾回收一次,并且很少有晋升到老年代的情况
4.3 第二轮压测
结果已经由原来的服务内部的耗时 变为了fegin的耗时,这种情况下可以考虑使用fegin的连接池优化或者新增节点

4.3.1 观察消费节点
发现消费速度很慢,产生了大量消息堆积

检查
storage-service的actualPlaceOrder端点信息
发现平均响应时间在200ms左右
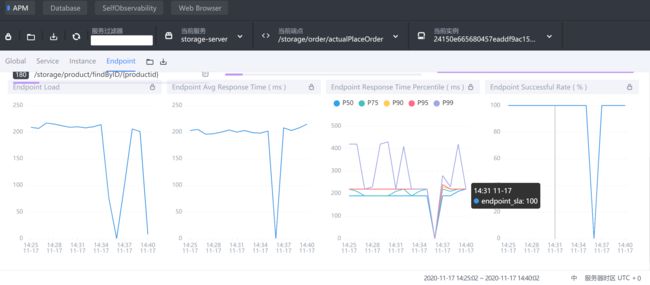
检查断点链路/storage/order/actualPlaceOrder
发现是事务提交慢造成的,这个时候就需要优化mysql服务器了

5. Skywalking 使用(自学)
5.1 Skywalking 模块栏目
![]()
Skywalking web UI 主要包括如下几个大的功能模块:
- 仪表盘:查看被监控服务的运行状态
- 拓扑图:以拓扑图的方式展现服务直接的关系,并以此为入口查看相关信息
- 追踪:以接口列表的方式展现,追踪接口内部调用过程
- 性能剖析:单独端点进行采样分析,并可查看堆栈信息
- 告警:触发告警的告警列表,包括实例,请求超时等。
- 自动刷新:刷新当前数据内容。
5.2 仪表盘

- 第一栏:不同内容主题的监控面板,应用/数据库/容器等
- 第二栏:操作,包括编辑/导出当前数据/倒入展示数据/不同服务端点筛选展示
- 第三栏:不同纬度展示,服务/实例/端点
9.3 展示栏
9.3.1 Global全局维度

- 第一栏:Global、Server、Instance、Endpoint不同展示面板,可以调整内部内容
- Services load:服务每分钟请求数
- Slow Services:慢响应服务,单位ms
- Un-Health services(Apdex):Apdex性能指标,1为满分。
- Global Response Latency:百分比响应延时,不同百分比的延时时间,单位ms
- Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度
- 底部栏:展示数据的时间区间,点击可以调整。
5.3.2 Service服务维度

- Service Apdex(数字):当前服务的评分
- Service Apdex(折线图):不同时间的Apdex评分
- Successful Rate(数字):请求成功率
- Successful Rate(折线图):不同时间的请求成功率
- Servce Load(数字):每分钟请求数
- Servce Load(折线图):不同时间的每分钟请求数
- Service Avg Response Times:平均响应延时,单位ms
- Global Response Time Percentile:百分比响应延时
- Servce Instances Load:每个服务实例的每分钟请求数
- Show Service Instance:每个服务实例的最大延时
- Service Instance Successful Rate:每个服务实例的请求成功率
5.3.3 Instance实例维度
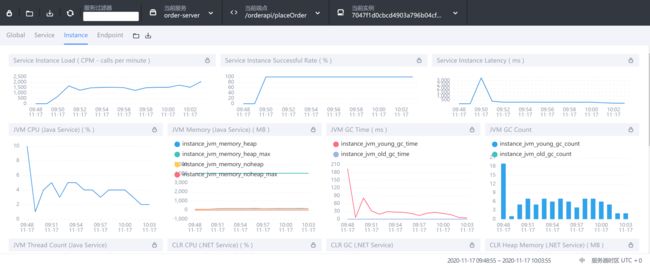
- Service Instance Load:当前实例的每分钟请求数
- Service Instance Successful Rate:当前实例的请求成功率
- Service Instance Latency:当前实例的响应延时
- JVM CPU:jvm占用CPU的百分比
- JVM Memory:JVM内存占用大小,单位m
- JVM GC Time:JVM垃圾回收时间,包含YGC和OGC
- JVM GC Count:JVM垃圾回收次数,包含YGC和OGC
- CLR XX:类似JVM虚拟机,这里用不上就不做解释了
5.3.4 Endpoint端点(API)维度

- Endpoint Load in Current Service:每个端点的每分钟请求数
- Slow Endpoints in Current Service:每个端点的最慢请求时间,单位ms
- Successful Rate in Current Service:每个端点的请求成功率
- Endpoint Load:当前端点每个时间段的请求数据
- Endpoint Avg Response Time:当前端点每个时间段的请求行响应时间
- Endpoint Response Time Percentile:当前端点每个时间段的响应时间占比
- Endpoint Successful Rate:当前端点每个时间段的请求成功率
5.4 拓扑图

- 1:选择不同的服务关联拓扑
- 2:查看单个服务相关内容
- 3:服务间连接情况
- 4:分组展示服务拓扑
5.5 追踪

- 左侧:api接口列表,红色-异常请求,蓝色-正常请求
- 右侧:api追踪列表,api请求连接各端点的先后顺序和时间
5.6 性能剖析
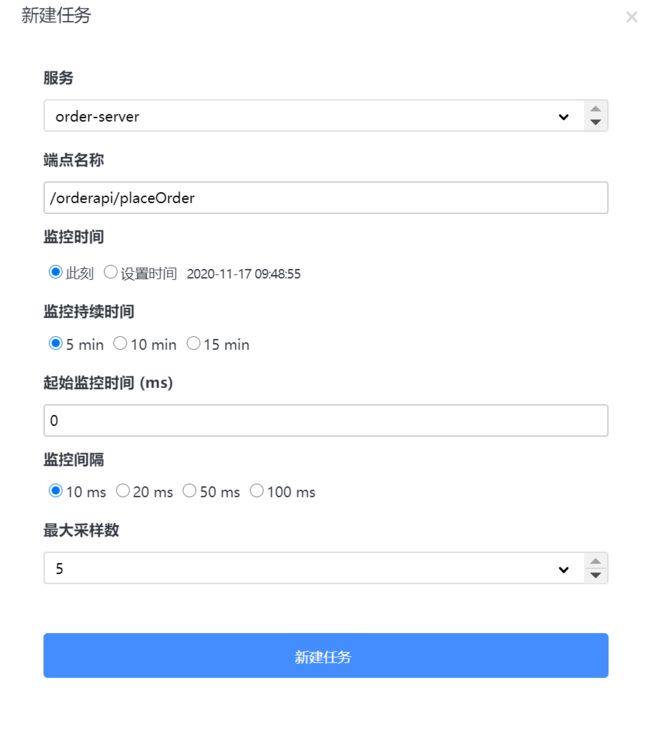
- 服务:需要分析的服务
- 端点:链路监控中端点的名称,可以再链路追踪中查看端点名称
- 监控时间:采集数据的开始时间
- 监控持续时间:监控采集多长时间
- 起始监控时间:多少秒后进行采集
- 监控间隔:多少秒采集一次
- 最大采集数:最大采集多少样本
查看监控结果
