Python脚本工具,PyMuPDF批量提取PDF文件中的图片
如何批量快速提取出PDF中的图片文件,你是否遇到这样的一个问题,尤其是PPT文件转换为PDF文件,需要快速提取其中的图片文件,如果你恰好会那么一点py,同时复制粘贴没问题的话,那么相信你也能够很轻松的解决这个问题。
提取PDF文件中的图片无疑是需要读取PDF文件,Python作为胶水语言,有着丰富第三方库,只要你想基本上都能找到你想要的轮子,而这里本渣渣应用的第三方库就是PyMuPDF,度娘搜的!!!
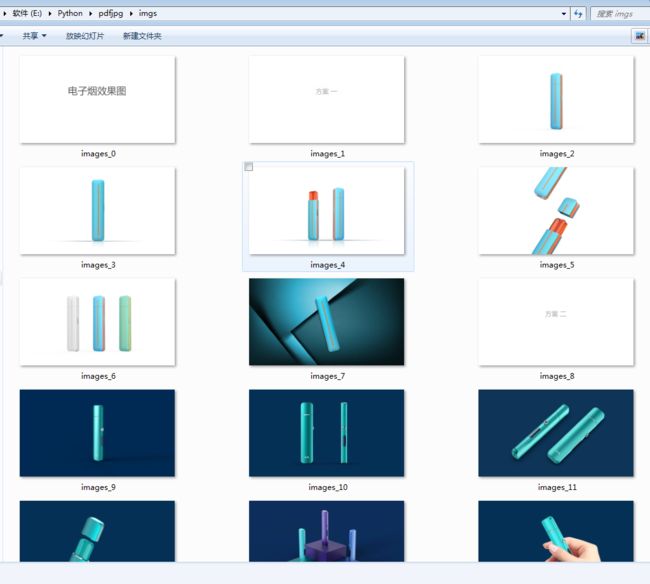
PyMuPDF(又称“ fitz”):MuPDF的Python绑定,这是一种轻量级的PDF和XPS查看器。该库可以访问PDF,XPS,OpenXPS,epub,漫画和小说书格式的文件,并且以其最佳性能和高渲染质量而闻名。
PyMuPDF库安装方法:
pip install PyMuPDF
PyMuPDF库使用方法:
#打开pdf读取页码数
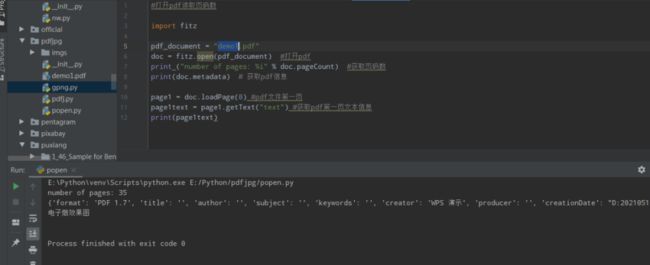
import fitz
pdf_document = "demo1.pdf"
doc = fitz.open(pdf_document) #打开pdf
print ("number of pages: %i" % doc.pageCount) #获取页码数
print(doc.metadata) # 获取pdf信息
page1 = doc.loadPage(0) #pdf文件第一页
page1text = page1.getText("text") #获取pdf第一页文本信息
print(page1text)
PyMuPDF的优点是可以保持原始文档结构完整-带有换行符的整个段落都保留在PDF文档中!
使用PyMuPDF从PDF提取图像
PyMuPDF使用该方法简化了从PDF文档提取图像的过程getPageImageList()。
#提取图像
import fitz
pdf_document = fitz.open("demo1.pdf")
for current_page in range(len(pdf_document)):
for image in pdf_document.getPageImageList(current_page):
xref = image[0]
pix = fitz.Pixmap(pdf_document, xref)
if pix.n < 5: # this is GRAY or RGB
pix.writePNG("page%s-%s.png" % (current_page, xref))
else: # CMYK: convert to RGB first
pix1 = fitz.Pixmap(fitz.csRGB, pix)
pix1.writePNG("page%s-%s.png" % (current_page, xref))
pix1 = None
pix = None
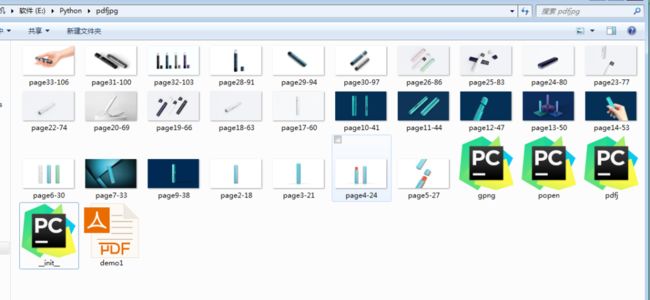
第二种方法:
import datetime
import os
import fitz # fitz就是pip install PyMuPDF
def pyMuPDF_fitz(pdfPath, imagePath):
startTime_pdf2img = datetime.datetime.now() # 开始时间
print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
for pg in range(pdfDoc.pageCount):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
# zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)
# zoom_y = 1.33333333
zoom_x=zoom_y=10
mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pix = page.getPixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
pix.writePNG(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)
if __name__ == "__main__":
# 1、PDF地址
pdfPath = 'demo1.pdf'
# 2、需要储存图片的目录
imagePath = './imgs'
pyMuPDF_fitz(pdfPath, imagePath)
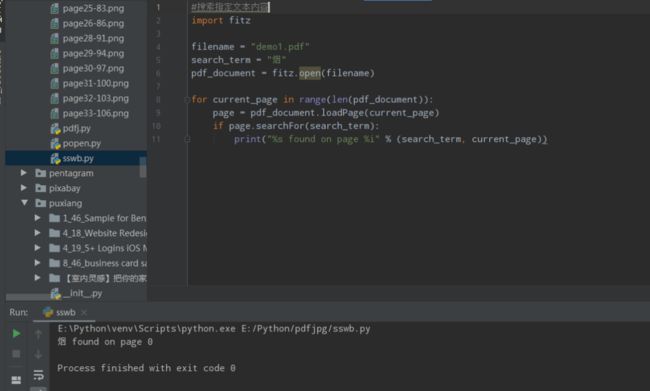
搜索指定文本
#搜索指定文本内容
import fitz
filename = "demo1.pdf"
search_term = "烟"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
来源:
1.Python操作PDF-文本和图片提取(使用PyPDF2和PyMuPDF)
https://www.jianshu.com/p/8fbb662bd6f7
2.python 将PDF 转成 图片的几种方法
https://blog.csdn.net/weixin_42081389/article/details/103712181
注:以上代码都是本渣渣抄袭的,如有不理解,可咨询度娘获取解决方案
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

![]()
关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji