HTTP协议
HTTP协议
- 应用层
-
- 再谈 "协议"
-
- 网络版计算器
- HTTP协议
-
- 认识URL
- urlencode和urldecode
- HTTP协议格式
- HTTP的方法
- HTTP的状态码
- HTTP常见Header
- HTTPS协议
- HTTPS 是什么
-
- 什么是"加密"
- 为什么要加密
- 常⻅的加密⽅式
- HTTPS 的⼯作过程探究
-
- ⽅案 1 - 只使⽤对称加密
- ⽅案 2 - 只使⽤⾮对称加密
- ⽅案 3 - 双⽅都使⽤⾮对称加密
- ⽅案 4 - ⾮对称加密 + 对称加密
- 中间⼈攻击
- 引⼊证书
- ⽅案 5 - ⾮对称加密 + 对称加密 + 证书认证
- 完整流程
- 总结
应用层
再谈 “协议”
协议是一种 “约定”. socket api的接口, 在读写数据时, 都是按 “字符串” 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?
网络版计算器
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端
约定方案:
- 定义结构体来表示我们需要交互的信息
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体
- 这个过程叫做 “序列化” 和 “反序列化”
“protocol.hpp”
enum
{
OK = 0,
DIV_ZERO,
MOD_ZERO,
OP_ERROR
};
std::string enLength(const std::string &text)
{
std::string send_string = std::to_string(text.size());
send_string += LINE_SEP;
send_string += text;
send_string += LINE_SEP;
return send_string;
}
bool deLength(const std::string &package, std::string *text)
{
auto pos = package.find(LINE_SEP);
if (pos == std::string::npos)
return false;
std::string text_len_string = package.substr(0, pos);
int text_len = std::stoi(text_len_string);
*text = package.substr(pos + LINE_SEP_LEN, text_len);
return true;
}
class Request
{
public:
Request()
: x(0), y(0), op(0)
{
}
Request(int _x, int _y, char _op)
: x(_x), y(_y), op(_op)
{
}
bool serialize(std::string *out)
{
*out = "";
std::string x_string = std::to_string(x);
std::string y_string = std::to_string(y);
*out = x_string;
*out += SEP;
*out += op;
*out += SEP;
*out += y_string;
return true;
}
bool deserialize(const std::string &in)
{
auto left = in.find(SEP);
auto right = in.rfind(SEP);
if (left == std::string::npos || right == std::string::npos)
return false;
if (left == right)
return false;
if (right - (left + SEP_LEN) != 1)
return false;
std::string x_string = in.substr(0, left);
std::string y_string = in.substr(right + SEP_LEN);
if (x_string.empty())
return false;
if (y_string.empty())
return false;
x = std::stoi(x_string);
y = std::stoi(y_string);
op = in[left + SEP_LEN];
return true;
}
public:
int x;
int y;
char op;
};
class Response
{
public:
Response()
: exitcode(0), result(0)
{
}
bool serialize(std::string *out)
{
*out = "";
std::string ec_string = std::to_string(exitcode);
std::string res_string = std::to_string(result);
*out = ec_string;
*out += SEP;
*out += res_string;
return true;
}
bool deserialize(std::string &in)
{
auto mid = in.find(SEP);
if (mid == std::string::npos)
return false;
std::string ec_string = in.substr(0, mid);
std::string res_string = in.substr(mid + SEP_LEN);
if (ec_string.empty() || res_string.empty())
return false;
exitcode = std::stoi(ec_string);
result = std::stoi(res_string);
return true;
}
public:
int exitcode; // 0:表示计算成功,!0表示计算失败
int result; // 计算结果
};
bool RecvPackage(int sock, std::string &inbuffer, std::string *text)
{
char buffer[1024];
while (true)
{
ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0);
if(n>0)
{
buffer[n]=0;
inbuffer+=buffer;
//分析处理
auto pos=inbuffer.find(LINE_SEP);
if(pos==std::string::npos)
continue;
std::string text_len_string=inbuffer.substr(0,pos);
int text_len=std::stoi(text_len_string);
int total_len=text_len_string.size()+2*LINE_SEP_LEN+text_len;
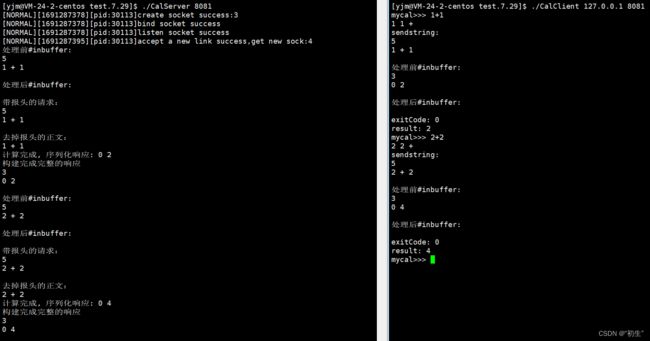
std::cout<<"处理前#inbuffer:\n"<<inbuffer<<std::endl;
if(inbuffer.size()<total_len)
{
std::cout<<"你输入的消息,没有严格遵守协议,正在等待后续的内容,continue"<<std::endl;
continue;
}
*text=inbuffer.substr(0,total_len);
inbuffer.erase(0,total_len);
std::cout<<"处理后#inbuffer:\n"<<inbuffer<<std::endl;
break;
}
else
return false;
}
return true;
}
“CalServer.hpp”
namespace Server
{
static const uint16_t gport = 8080;
static const int gbacklog = 5;
typedef std::function<bool(const Request &req, Response &resp)> func_t;
// 保证解耦
void HandlerEntery(int sock, func_t func)
{
std::string inbuffer;
while (true)
{
// 1. 读取:"content_len"\r\n"x op y"\r\n
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
std::string req_text, req_str;
// 1.2 我们保证,我们req_text里面一定是一个完整的请求:"content_len"\r\n"x op y"\r\n
if (!RecvPackage(sock, inbuffer, &req_text))
return;
std::cout << "带报头的请求:\n"
<< req_text << std::endl;
if (!deLength(req_text, &req_str))
return;
std::cout << "去掉报头的正文:\n"
<< req_str << std::endl;
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
func(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
std::string resp_str;
resp.serialize(&resp_str);
std::cout << "计算完成, 序列化响应: " << resp_str << std::endl;
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
std::string send_string = enLength(resp_str);
std::cout << "构建完成完整的响应\n"
<< send_string << std::endl;
send(sock, send_string.c_str(), send_string.size(), 0); // 其实这里的发送也是有问题的,不过后面再说
}
}
class CalServer
{
public:
CalServer(const uint16_t &port = gport)
: _listensock(-1), _port(port)
{
}
void InitServer()
{
// 1.创建socket套接字对象
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock < 0)
{
LogMeassage(FATAL, "create socket error");
exit(1);
}
LogMeassage(NORMAL, "create socket success:%d", _listensock);
// 2.bind绑定对应的网络信息
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0)
{
LogMeassage(FATAL, "bind socket error");
exit(2);
}
LogMeassage(NORMAL, "bind socket success");
// 3.设置socket为监听状态
if (listen(_listensock, gbacklog) < 0)
{
LogMeassage(FATAL, "listen socket error");
exit(3);
}
LogMeassage(NORMAL, "listen socket success");
}
void start(func_t func)
{
for (;;)
{
// 4.server 获取新链接
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int sock = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sock < 0)
{
LogMeassage(ERROR, "accept error,continue");
continue;
}
LogMeassage(NORMAL, "accept a new link success,get new sock:%d", sock);
pid_t id = fork();
if (id == 0)
{
close(_listensock);
HandlerEntery(sock, func);
close(sock);
exit(0);
}
close(sock);
pid_t ret = waitpid(id, nullptr, 0);
if (ret > 0)
{
LogMeassage(NORMAL, "wait child success");
}
}
}
~CalServer()
{
}
private:
int _listensock;
uint16_t _port;
};
}
“CalClient.hpp”
class CalClient
{
public:
CalClient(const std::string &serverip, const uint16_t &serverport)
: _sock(-1), _serverip(serverip), _serverport(serverport)
{
}
void initClient()
{
// 1. 创建socket
_sock = socket(AF_INET, SOCK_STREAM, 0);
if (_sock < 0)
{
std::cerr << "socket create error" << std::endl;
exit(2);
}
// 2. tcp的客户端要不要bind?要的! 要不要显示的bind?不要!这里尤其是client port要让OS自定随机指定!
// 3. 要不要listen?不要!
// 4. 要不要accept? 不要!
// 5. 要什么呢??要发起链接!
}
void start()
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(_serverport);
server.sin_addr.s_addr = inet_addr(_serverip.c_str());
if (connect(_sock, (struct sockaddr *)&server, sizeof(server)) != 0)
{
std::cerr << "socket connect error" << std::endl;
}
else
{
std::string line;
std::string inbuffer;
while (true)
{
std::cout << "mycal>>> ";
std::getline(std::cin, line); // 1+1
Request req = ParseLine(line); // "1+1"
std::string content;
req.serialize(&content);
std::string send_string = enLength(content);
std::cout << "sendstring:\n" << send_string << std::endl;
send(_sock, send_string.c_str(), send_string.size(), 0); // bug?? 不管
std::string package, text;
// "content_len"\r\n"exitcode result"\r\n
if (!RecvPackage(_sock, inbuffer, &package))
continue;
if (!deLength(package, &text))
continue;
// "exitcode result"
Response resp;
resp.deserialize(text);
std::cout << "exitCode: " << resp.exitcode << std::endl;
std::cout << "result: " << resp.result << std::endl;
}
}
}
Request ParseLine(const std::string &line)
{
// 建议版本的状态机!
//"1+1" "123*456" "12/0"
int status = 0; // 0:操作符之前,1:碰到了操作符 2:操作符之后
int i = 0;
int cnt = line.size();
std::string left, right;
char op;
while (i < cnt)
{
switch (status)
{
case 0:
{
if(!isdigit(line[i]))
{
op = line[i];
status = 1;
}
else left.push_back(line[i++]);
}
break;
case 1:
i++;
status = 2;
break;
case 2:
right.push_back(line[i++]);
break;
}
}
std::cout << std::stoi(left)<<" " << std::stoi(right) << " " << op << std::endl;
return Request(std::stoi(left), std::stoi(right), op);
}
~CalClient()
{
if (_sock >= 0)
close(_sock);
}
private:
int _sock;
std::string _serverip;
uint16_t _serverport;
};
无论我们采用什么方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的. 这种约定, 就是 应用层协议
HTTP协议
认识URL
平时我们俗称的 “网址” 其实就是说的 URL
通过HTTP协议通过此电脑,将远端的服务器这个路径下的资源拿到,放在此电脑中
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现. 比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
HTTP协议格式
HTTP请求

HTTP响应


细节
请求和响应如何保证应用层读取完毕?
- 读取完整的一行
- 循环语句(while),请求行+请求报头全部读完直至空行
- 报头中有一个属性,Content-Length:正文长度
- 解析正文长度,读取正文即可
请求和响应如何做到序列化和反序列化?
http自己实现,第一行+请求/响应报头,连成一个字符串
上面只是理论,下面通过代码来验证
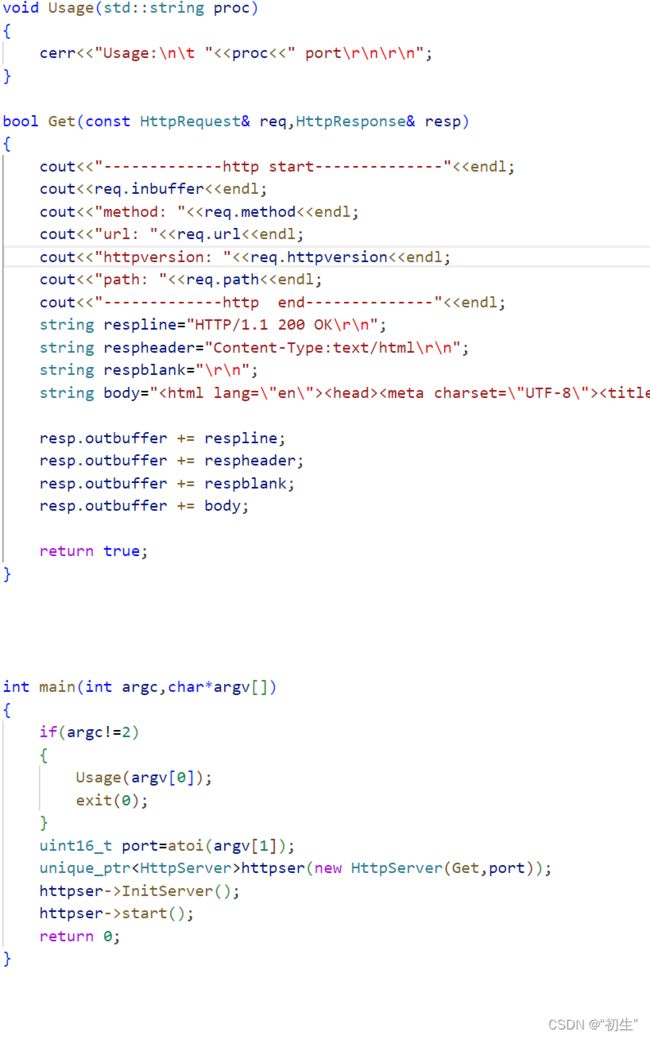
HttpServer.hpp
namespace Server
{
static const uint16_t gport=8080;
static const int gbacklog=5;
using func_t =std::function<bool(const HttpRequest& req,HttpResponse& resp)>;
class HttpServer
{
public:
HttpServer(func_t func,const uint16_t& port=gport)
:_func(func)
,_listensock(-1)
,_port(port)
{
}
void InitServer()
{
//1.创建socket文件套接字对象
_listensock=socket(AF_INET,SOCK_STREAM,0);
if(_listensock<0)
{
exit(1);
}
//2.bind绑定自己的网络信息
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family=AF_INET;
local.sin_port=htons(_port);
local.sin_addr.s_addr=INADDR_ANY;
if(bind(_listensock,(struct sockaddr*)&local,sizeof(local))<0)
{
exit(2);
}
//3.设置socket为监听状态
if(listen(_listensock,gbacklog)<0)
{
exit(3);
}
}
void HandlerHttp(int sock)
{
//1.读取完整的HTTP请求,read
//2.反序列化
//3.httprequest->httpresponse
//4.resp序列化
//5.send
char buffer[1024];
HttpRequest req;
HttpResponse resp;
size_t n=recv(sock,buffer,sizeof(buffer)-1,0);
if(n>0)
{
buffer[n]=0;
req.inbuffer=buffer;
req.parse();
_func(req,resp);
send(sock,resp.outbuffer.c_str(),resp.outbuffer.size(),0);
}
}
void start()
{
for(;;)
{
//4.server获取新链接
struct sockaddr_in peer;
socklen_t len=sizeof(peer);
int sock=accept(_listensock,(struct sockaddr*)&peer,&len);
if(sock<0)
{
continue;
}
//多进程
pid_t id=fork();
if(id==0)
{
close(_listensock);
if(fork()>0) exit(0);
HandlerHttp(sock);
close(sock);
exit(0);
}
close(sock);
waitpid(id,nullptr,0);
}
}
~HttpServer() {};
private:
int _listensock;
uint16_t _port;
func_t _func;
};
}
protocol.hpp
const std::string sep="\r\n";
const std::string defualt_root="./wwwroot";
const std::string home_page="index.html";
class HttpRequest
{
public:
HttpRequest(){};
~HttpRequest(){};
void parse()
{
//1.从inbuffer中读取第一行
std::string line=Util::getOneline(inbuffer,sep);
if(line.empty()) return ;
//2.从请求行中提取三个字段
std::stringstream ss(line);
ss>>method>>url>>httpversion;
//3.添加web默认路径
path=defualt_root;
path+=url;
if(path[path.size()-1]=='/')
path+=home_page;
}
public:
std::string inbuffer;
std::string method;
std::string url;
std::string httpversion;
std::string path;
};
class HttpResponse
{
public:
std::string outbuffer;
};
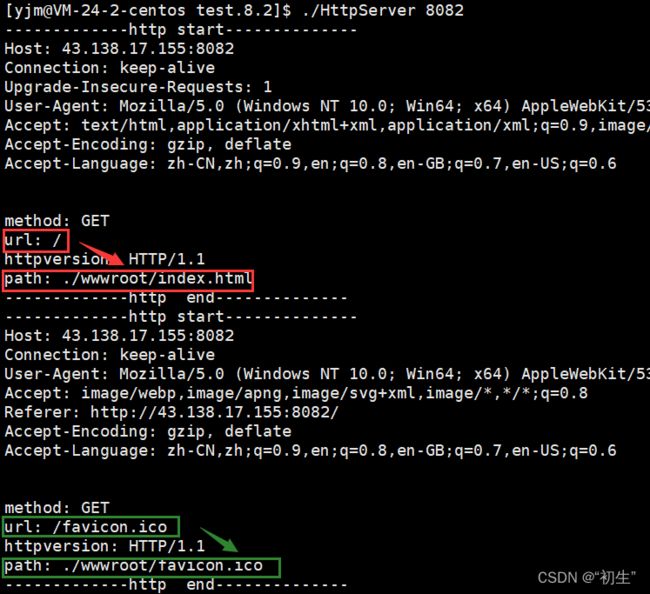
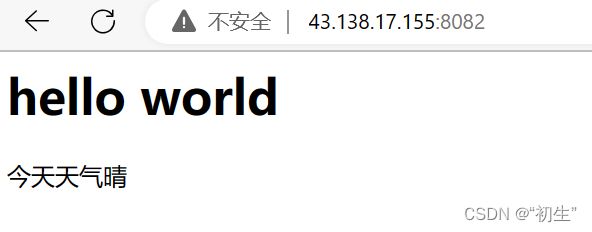
/是web根目录,对应的服务器根据输入的网址,找到对应路径下的资源;http请求如果没有请求指定的资源,服务器会有默认首页, index.html是对应服务器的默认首页
对于上面的运行结果可能会有些疑问:客服端请求一次,服务端却接受两次请求?这合理吗?
其实,第一个请求的资源是网页,第二个请求的是网页上面的小图标(favicon .ico);所以用户看到的网页结果,可能是多个资源组合而成的,想要获取一张完整的网页效果,浏览器会发起多次HTTP请求
HTTP的方法
HTTP请求方法:获取资源,上传资源
我们在进行数据提交时,本质是前端要通过form表单提交的,浏览器会自动将form表单中的内容转换成GET/POST方法请求
举个栗子

QQ登录时,用户填入数据进行提交;浏览器根据数据的内容转换请求方法(GET/POST)
接下来,代码验证两者区别
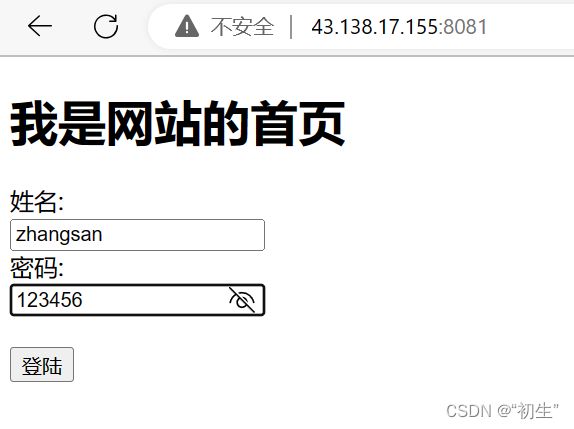
GET
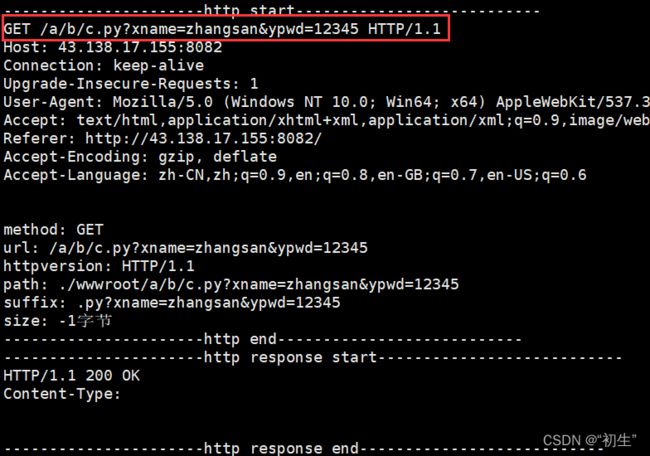
GET通过url传递参数,具体:http://ip:port/XXX/YYY?name1=value1&name2=value2
不私秘
POST
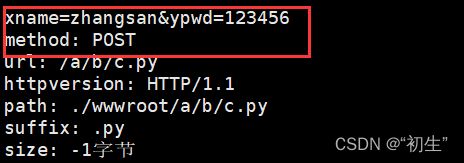
POST通过HTTP请求的正文提交参数
在上面我们向服务器提交了指定的路径,其作用在于;服务器会根据指定的路径分配指定的资源
除了上面的GET/POST方法,其实还有其他的方法,比如重定向:永久重定向,临时重定向
这其实很好理解,比如当你进入某个页面突然就跳转到广告,这就是临时重定向
HTTP的状态码
- 信息响应(100-199)
- 成功响应(200-299)
- 重定向消息(300-399)
- 客户端错误响应(400-499)
- 服务端错误响应(500-599)
HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Content-Length: 正文的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- User-Agent: 声明用户的操作系统和浏览器版本信息
- referer: 当前页面是从哪个页面跳转过来的
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能
在详细介绍Header之前,先介绍几个概念
长链接
我们知道,一张网页实际上是包含多种元素,所以需要进行多次HTTP请求;HTTP又是基于TCP实现的,TCP是面向链接的,便会频繁创建链接
为了解决这个问题,需要客户端和服务端都支持长链接,建立一条链接,获取所需的资源;Connection: keep-alive
HTTP周边会话保持
会话保持并不是HTTP天然具备的,在使用中发现需要,才加入的
HTTP协议是无状态的,但是用户需要;例如,当我们在B站中观看视频,一个视频结束进行跳转到另一个视频时,新的页面无法识别用户的身份,需要再次登录;所以为了用户一经登录,便可以在整个网站,按照自己的身份进行随意访问,HTTP便引入周边会话保持的概念
会话保持的实现
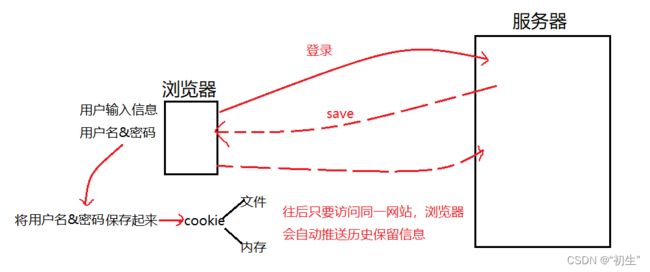
在会话保持中使用了Header中的cookie,这里开始详细介绍cookie
cookie
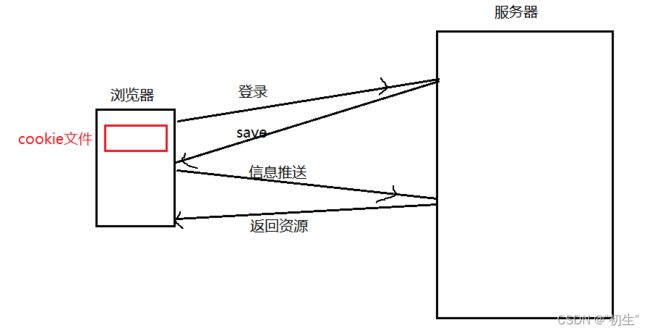
在浏览器中进行登陆时,服务器会将用户输入的信息保存并返回,用户的信息保存在浏览器中的cookie文件中,当再次进行登陆时,浏览器会自动推送保存的信息,不需要再次输入信息
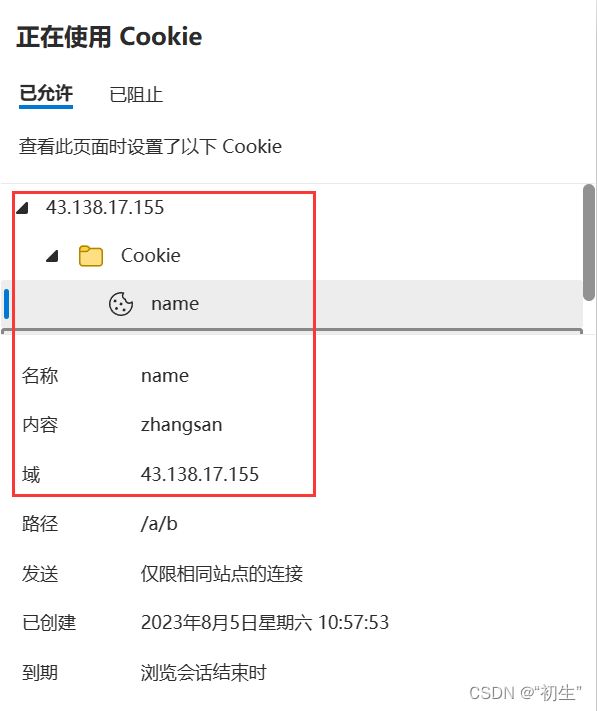
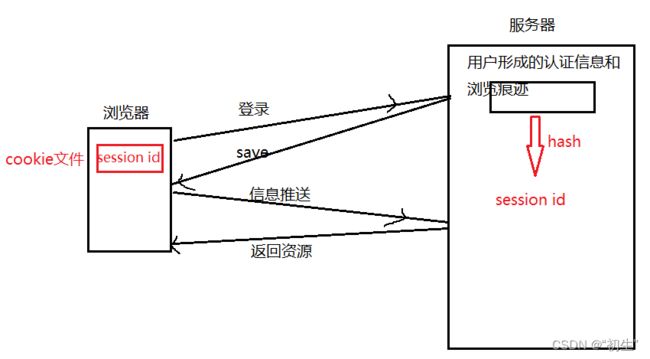
后来,为了防止在客户端中病毒的情况下泄漏个人信息,客户端的浏览器中的cookie文件不在保存用户信息和密码,而是替换成由哈希函数生成的数据摘要
HTTPS协议
HTTPS 是什么
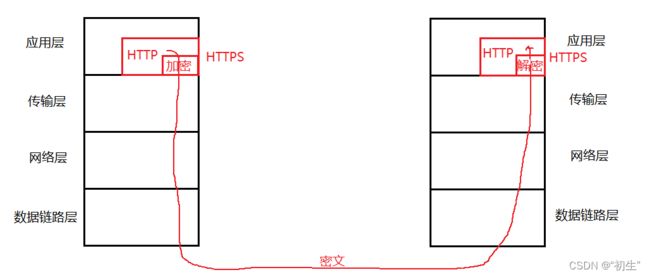
HTTPS 也是⼀个应⽤层协议. 是在 HTTP 协议的基础上引⼊了⼀个加密层.
HTTP 协议内容都是按照⽂本的⽅式明⽂传输的. 这就导致在传输过程中出现⼀些被篡改的情况.
什么是"加密"
加密就是把 明⽂ (要传输的信息)进⾏⼀系列变换, ⽣成 密⽂
解密就是把 密⽂ 再进⾏⼀系列变换, 还原成 明⽂ .
为什么要加密
臭名昭著的 “运营商劫持”
下载某app时,点击 “下载按钮”, 就会给服务器发送了⼀个 HTTP 请求, 获取到的 HTTP 响应其实就包含了该APP 的下载链接. 运营商劫持之后, 就发现这个请求是要下载某app, 那么就⾃动的把交给⽤⼾的响应给篡改成 “QQ浏览器” 的下载地址了
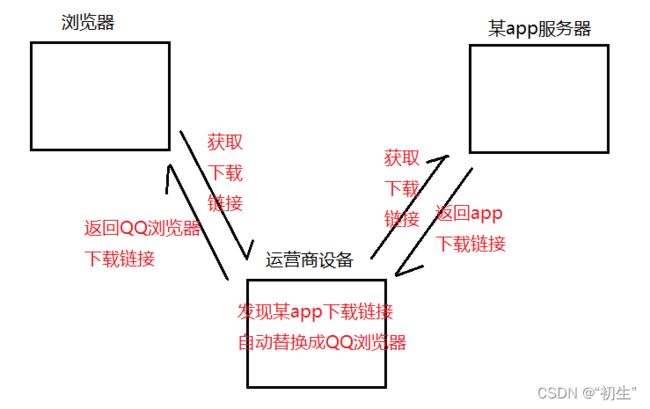
不⽌运营商可以劫持, 其他的 ⿊客 也可以⽤类似的⼿段进⾏劫持, 来窃取⽤⼾隐私信息, 或者篡改内容
在互联⽹上, 明⽂传输是⽐较危险的事情!!!
HTTPS 就是在 HTTP 的基础上进⾏了加密, 进⼀步的来保证⽤⼾的信息安全
常⻅的加密⽅式
对称加密
- 采⽤单钥密码系统的加密⽅法,同⼀个密钥可以同时⽤作信息的加密和解密,这种加密⽅法称为对称加密,也称为单密钥加密,特征:加密和解密所⽤的密钥是相同的
- 特点:算法公开、计算量⼩、加密速度快、加密效率⾼
对称加密其实就是通过同⼀个 “密钥” , 把明⽂加密成密⽂, 并且也能把密⽂解密成明⽂.
例如⼀个简单的对称加密, 按位异或
⾮对称加密
- 需要两个密钥来进⾏加密和解密,这两个密钥是公开密钥(public key,简称公钥)和私有密钥(private key,简称私钥)
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,⽽使得加密解密速度没有对称加密解密的速度快
⾮对称加密要⽤到两个密钥, ⼀个叫做 “公钥”, ⼀个叫做 “私钥”
公钥和私钥是配对的. 最⼤的缺点就是运算速度⾮常慢,⽐对称加密要慢很多.
- 通过公钥对明⽂加密, 变成密⽂
- 通过私钥对密⽂解密, 变成明⽂
当然也可以反着⽤
数据摘要 && 数据指纹
- 数字指纹(数据摘要),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,⽣成⼀串固定⻓度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常⽤来进⾏数据对⽐
HTTPS 的⼯作过程探究
既然要保证数据安全, 就需要进⾏ “加密”.
⽹络传输中不再直接传输明⽂了, ⽽是加密之后的 “密⽂”.
加密的⽅式有很多, 但是整体可以分成两⼤类: 对称加密 和 ⾮对称加密
⽅案 1 - 只使⽤对称加密
如果通信双⽅都各⾃持有同⼀个密钥X,且没有别⼈知道,这两⽅的通信安全当然是可以被保证的(除⾮密钥被破解)
引⼊对称加密之后, 即使数据被截获, 由于⿊客不知道密钥是啥, 因此就⽆法进⾏解密, 也就不知道请求的真实内容是啥了
但是呢在客⼾端和服务器建⽴连接的时候, 双⽅协商确定这次的密钥
但是如果直接把密钥明⽂传输, 那么⿊客也就能获得密钥此时后续的加密操作就形同虚设了
因此密钥的传输也必须加密传输!
但是要想对密钥进⾏对称加密, 就仍然需要先协商确定⼀个 “密钥的密钥”. 这就成了 “先有鸡还是先有蛋” 的问题了. 此时密钥的传输再⽤对称加密就⾏不通了.
⽅案 2 - 只使⽤⾮对称加密
鉴于⾮对称加密的机制,如果服务器先把公钥以明⽂⽅式传输给浏览器,之后浏览器向服务器传数据前都先⽤这个公钥加密好再传,从客⼾端到服务器信道似乎是安全的(有安全问题),因为只有服务器有相应的私钥能解开公钥加密的数据。
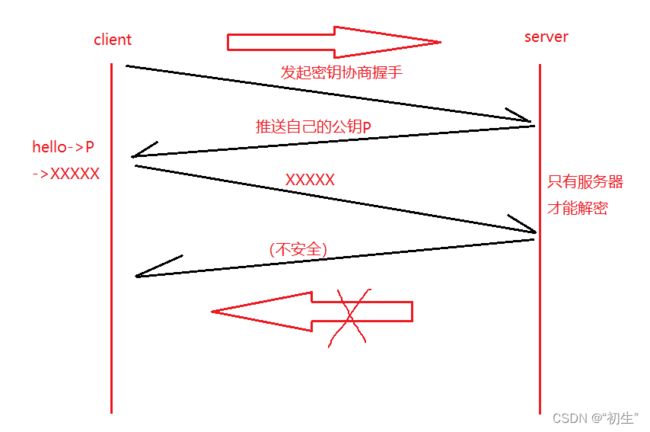
如果服务器⽤它的私钥加密数据传给浏览器,那么浏览器⽤公钥可以解密它,⽽这个公钥是⼀开始通过明⽂传输给浏览器的,若这个公钥被中间⼈劫持到了,那他也能⽤该公钥解密服务器传来的信息
了,因此也行不通
⽅案 3 - 双⽅都使⽤⾮对称加密
- 服务端拥有公钥S与对应的私钥S’,客⼾端拥有公钥C与对应的私钥C’
- 客⼾和服务端交换公钥
- 客⼾端给服务端发信息:先⽤S对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥S’
- 服务端给客⼾端发信息:先⽤C对数据加密,在发送,只能由客⼾端解密,因为只有客⼾端有私钥C’
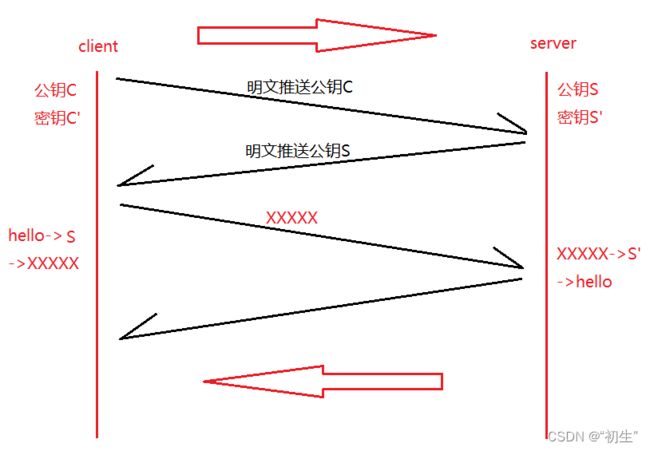
这样貌似也⾏啊,但是存在两个问题:效率太低,依旧有安全问题
⽅案 4 - ⾮对称加密 + 对称加密
先解决效率问题
- 服务端具有⾮对称公钥S和私钥S’
- 客⼾端发起https请求,获取服务端公钥S
- 客⼾端在本地⽣成对称密钥C, 通过公钥S加密, 发送给服务器
- 由于中间的⽹络设备没有私钥, 即使截获了数据, 也⽆法还原出内部的原⽂, 也就⽆法获取到对称密钥
- 服务器通过私钥S’解密, 还原出客⼾端发送的对称密钥C. 并且使⽤这个对称密钥加密给客⼾端返回的响应数据
- 后续客⼾端和服务器的通信都只⽤对称加密即可. 由于该密钥只有客⼾端和服务器两个主机知道, 其他主机/设备不知道密钥即使截获数据也没有意义
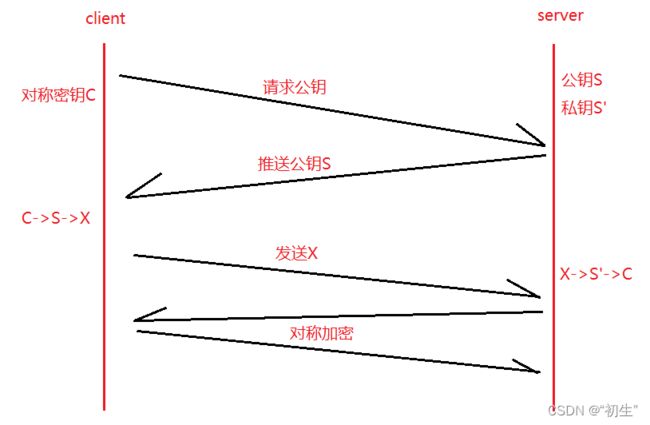
虽然很接近答案,但是依旧有安全问题,如果最开始,中间⼈就已经开始攻击了呢?
中间⼈攻击
确实,在⽅案2/3/4中,客⼾端获取到公钥S之后,对客⼾端形成的对称秘钥X⽤服务端给客⼾端的公钥S进⾏加密,中间⼈即使窃取到了数据,此时中间⼈确实⽆法解出客⼾端形成的密钥X,因为只有服务器有私钥S’
但是中间⼈的攻击,如果在最开始握⼿协商的时候就进⾏了,那就不⼀定了,假设hacker已经成功成为中间⼈
- 服务器具有⾮对称加密算法的公钥S,私钥S’
- 中间⼈具有⾮对称加密算法的公钥M,私钥M’
- 客⼾端向服务器发起请求,服务器明⽂传送公钥S给客⼾端
- 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥M,并将伪造报⽂发给客⼾端
- 客⼾端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加密X,形成报⽂发送给服务器
- 中间⼈劫持后,直接⽤⾃⼰的私钥M’进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加密后,将报⽂推送给服务器
- 服务器拿到报⽂,⽤⾃⼰的私钥S’解密,得到通信秘钥X
- 双⽅开始采⽤X进⾏对称加密,进⾏通信。但是⼀切都在中间⼈的掌握中,劫持数据,进⾏窃听甚⾄修改,都是可以的
问题本质出在:客⼾端⽆法确定收到的含有公钥的数据报⽂,就是⽬标服务器发送过来的!
引⼊证书
CA认证
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性
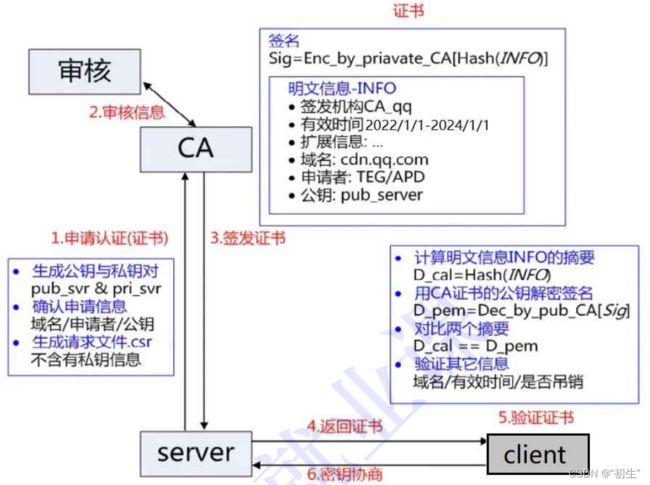
这个 证书 可以理解成是⼀个结构化的字符串, ⾥⾯包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- …
申请证书的时候,需要在特定平台⽣成查,会同时⽣成⼀对⼉密钥对⼉,即公钥和私钥。这对密钥对⼉就是⽤来在⽹络通信中进⾏明⽂加密以及数字签名的。
理解数据签名
签名的形成是基于⾮对称加密算法
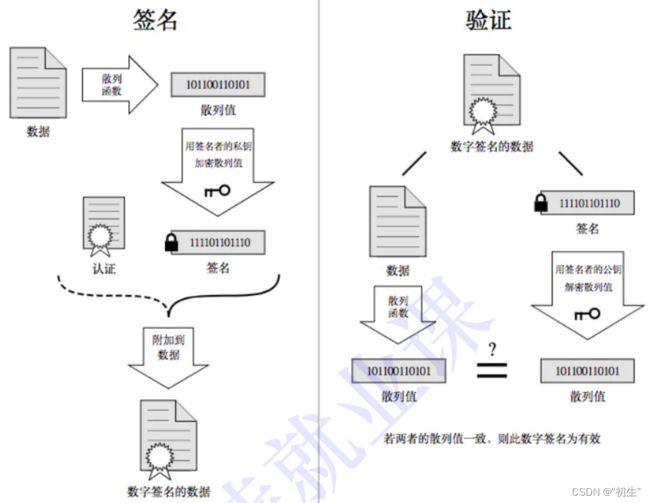
当服务端申请CA证书的时候,CA机构会对该服务端进⾏审核,并专⻔为该⽹站形成数字签名,过程如下:
- CA机构拥有⾮对称加密的私钥A和公钥A’
- CA机构对服务端申请的证书明⽂数据进⾏hash,形成数据摘要
- 然后对数据摘要⽤CA私钥A’加密,得到数字签名S
服务端申请的证书明⽂和数字签名S 共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端
因为我们使用CA私钥形成数据签名,所以,只有CA能形成可信任的证书
⽅案 5 - ⾮对称加密 + 对称加密 + 证书认证
在客⼾端和服务器刚⼀建⽴连接的时候, 服务器给客⼾端返回⼀个 证书,证书包含了之前服务端的公钥, 也包含了⽹站的⾝份信息
客⼾端进⾏认证
当客⼾端获取到这个证书之后, 会对证书进⾏校验(防⽌证书是伪造的).
- 判定证书的有效期是否过期
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)
- 验证证书是否被篡改: 从系统中拿到该证书发布机构的公钥, 对签名解密, 得到⼀个 hash 值(称为数据摘要), 设为 hash1. 然后计算整个证书的 hash 值, 设为 hash2. 对⽐ hash1 和 hash2 是否相等. 如果相等, 则说明证书是没有被篡改过的
中间⼈有没有可能篡改该证书?
- 中间⼈篡改了证书的明⽂
- 由于他没有CA机构的私钥,所以⽆法hash之后⽤私钥加密形成签名,那么也就没法办法对篡改后的证书形成匹配的签名
- 如果强⾏篡改,客⼾端收到该证书后会发现明⽂和签名解密后的值不⼀致,则说明证书已被篡改,证书不可信,从⽽终⽌向服务器传输信息,防⽌信息泄露给中间人
中间⼈整个掉包证书?
- 因为中间⼈没有CA私钥,所以⽆法制作假的证书
- 所以中间⼈只能向CA申请真证书,然后⽤⾃⼰申请的证书进⾏掉包
- 这个确实能做到证书的整体掉包,但是别忘记,证书明⽂中包含了域名等服务端认证信息,如果整体掉包,客⼾端依旧能够识别出来
- 永远记住:中间⼈没有CA私钥,所以对任何证书都⽆法进⾏合法修改,包括⾃⼰的
完整流程
左侧都是客⼾端做的事情, 右侧都是服务器做的事情
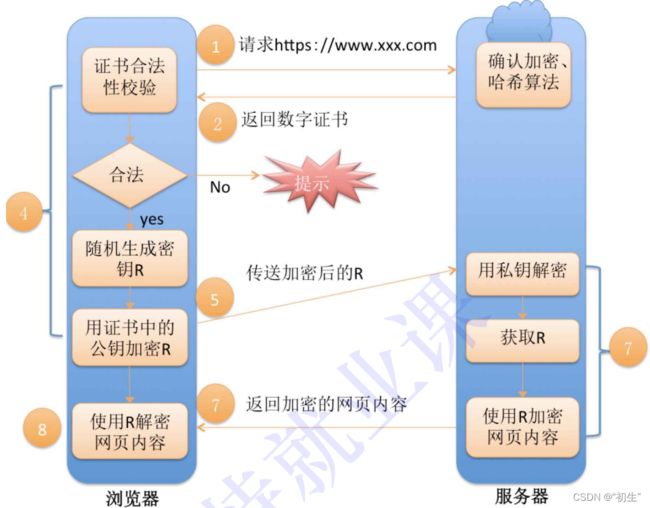
总结
HTTPS ⼯作过程中涉及到的密钥有三组
第⼀组(⾮对称加密): ⽤于校验证书是否被篡改. 服务器持有私钥(私钥在形成CSR⽂件与申请证书时获得), 客⼾端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器在客⼾端请求是,返回携带签名的证书. 客⼾端通过这个公钥进⾏证书验证, 保证证书的合法性,进⼀步保证证书中携带的服务端公钥权威性
第⼆组(⾮对称加密): ⽤于协商⽣成对称加密的密钥. 客⼾端⽤收到的CA证书中的公钥(是可被信任的)给随机⽣成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解密获取到对称加密密钥
第三组(对称加密): 客⼾端和服务器后续传输的数据都通过这个对称密钥加密解密
其实⼀切的关键都是围绕这个对称加密的密钥. 其他的机制都是辅助这个密钥⼯作的