排序素来美如玉,层进理解获芳心
注:本篇博客排序算法的实现默认都以升序为例
目录
一、(直接)插入排序
第一层境界:一组有序数据 插入 数tmp 使其有序(预备工作)
第二层境界:一组数据从乱序到升序(真正的插入排序)(第一层境界的变形~)
二、希尔排序
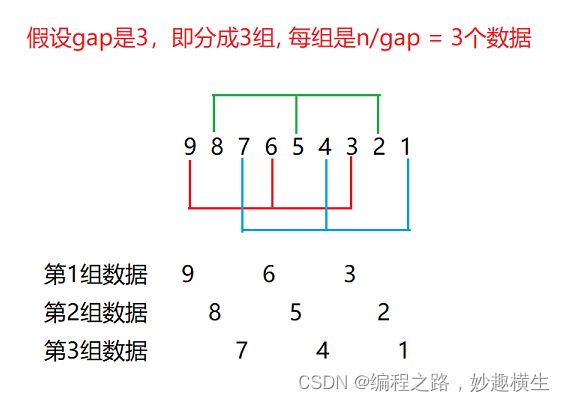
第一层境界:gap组数据之每组数据的排序
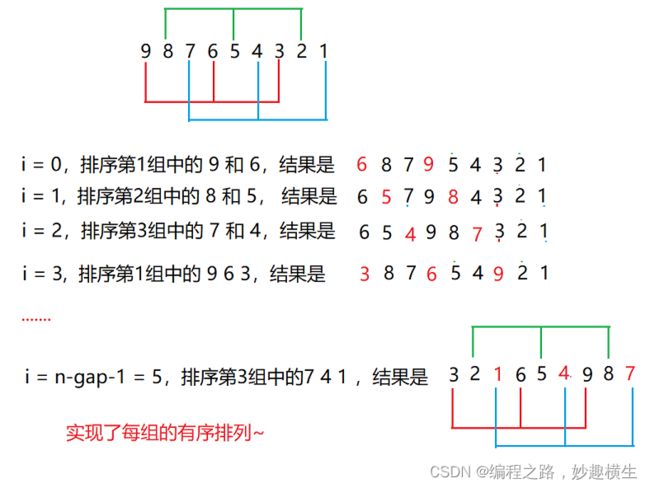
第二层境界:循环实现gap组数据的各组排序
第三层境界:gap组数据的最终排序算法
三、冒泡排序
第一层境界:傻傻比较走全程
第二层境界:边走边看中途停(第一层境界的优化)
四、堆排序
五、选择排序
六、快速排序
第一层境界:递归实现(三大版本)
避坑:
以上三个版本代码缺陷:
快速排序递归版本选key优化
第二层境界:非递归实现(借助栈)
快速排序复杂度分析
七、归并排序
第一层境界:递归实现
思想:数组一分为二,整体有序则需左右有序,左右有序则递归即可~
代码要点:
第二层境界:非递归实现(循环实现)
八、计数排序
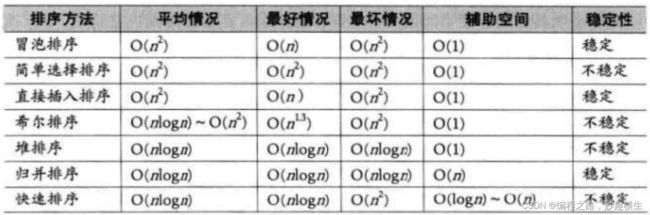
九、八大排序总结
一、(直接)插入排序
第一层境界:一组有序数据 插入 数tmp 使其有序(预备工作)
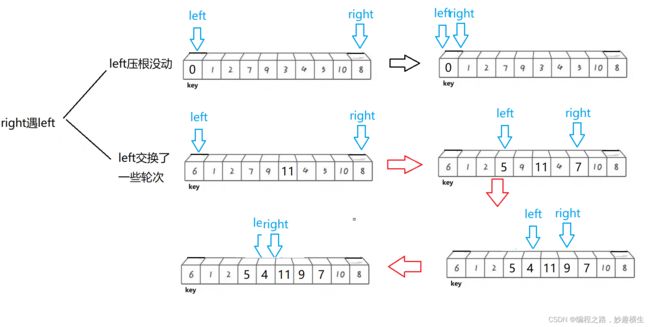
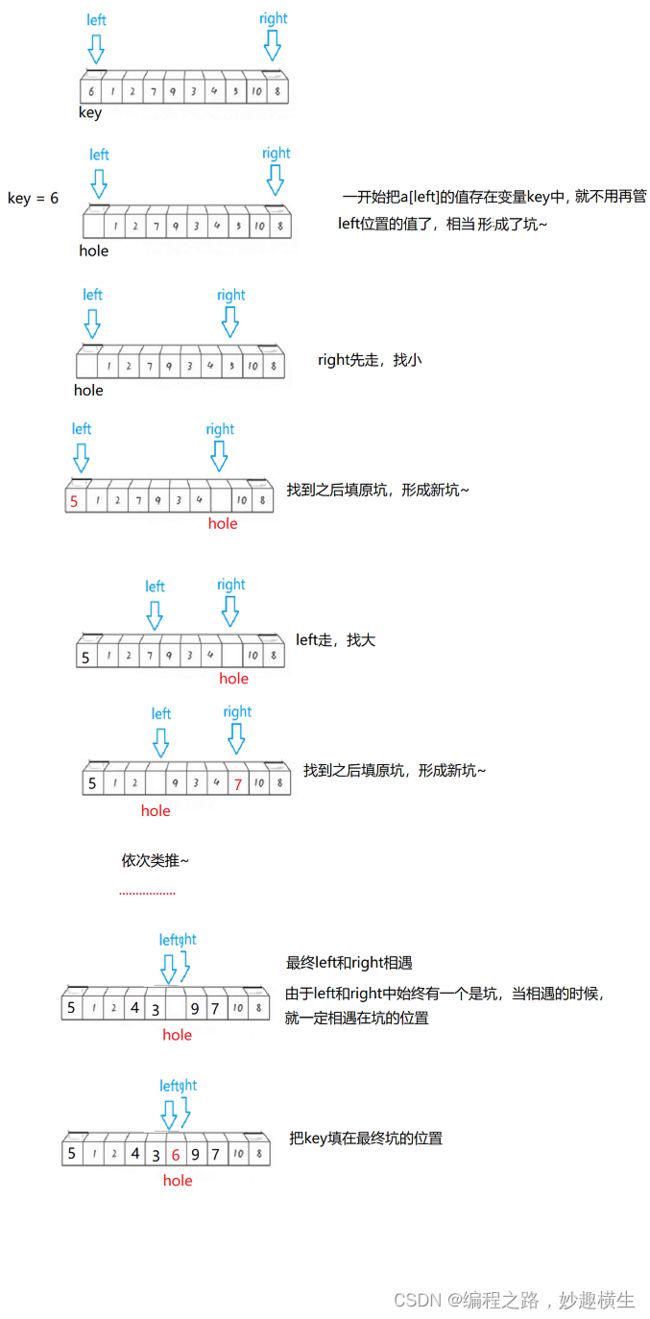
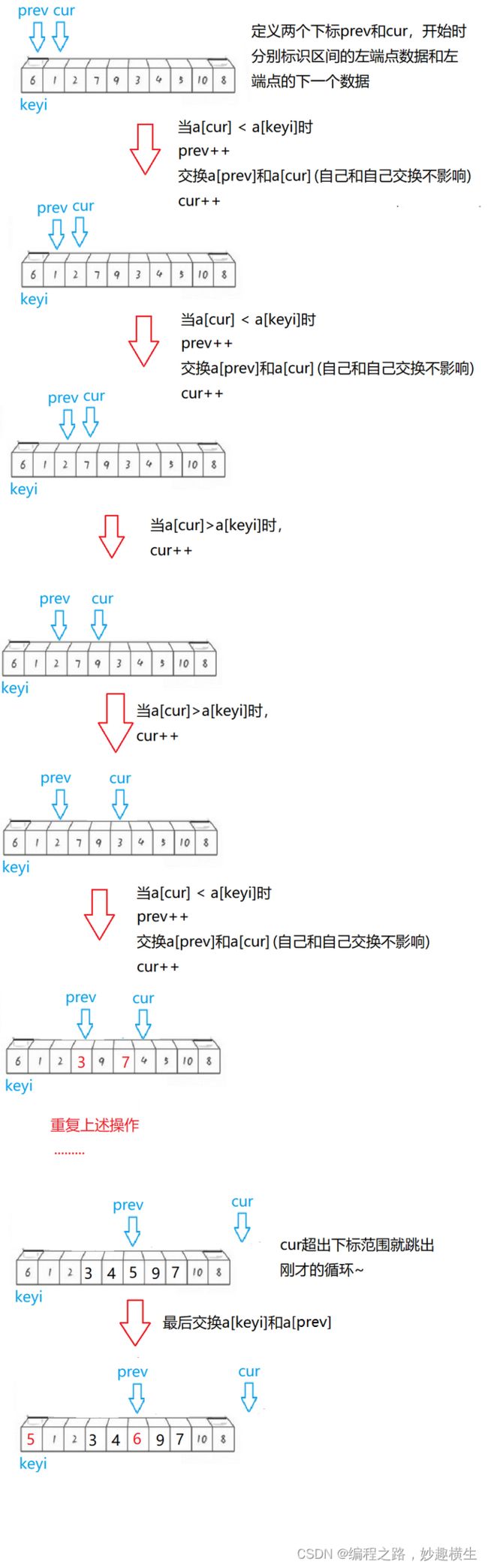
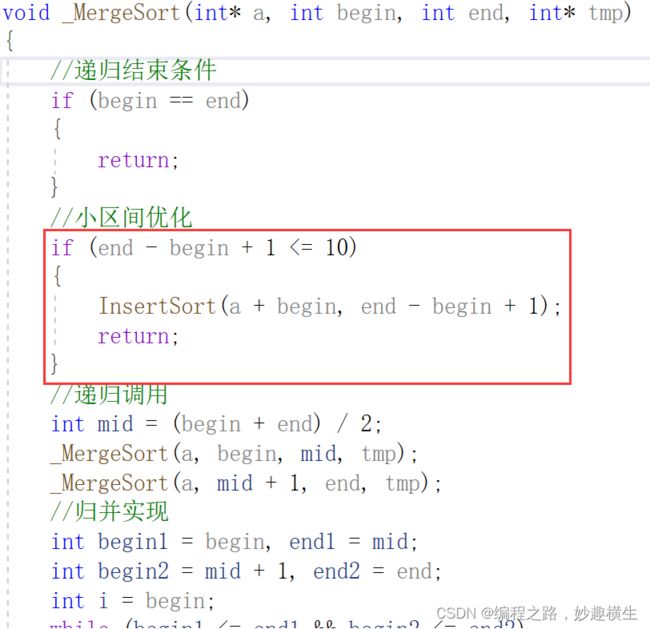
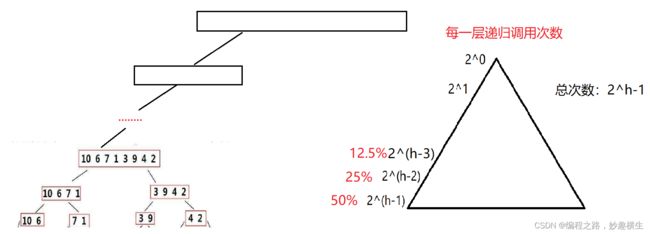
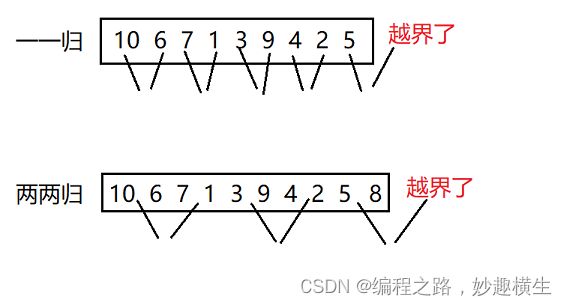
思想:倒着依次比较数组元素和tmp大小,a[end]>tmp,数组元素后移,end-- ; a[end] 关键:情况一和情况二最后均要执行 a[end+1]=tmp 该语句 代码实现: 思想:把境界一套进for循环 过程阐释:这是数组数据逐个插入排序的过程,第一个数显然不需要参与排序,tmp是每次要插入的值 两种写法的不同仅在于下标的控制而已,本质一样 //写法一: //写法二: 插入排序算法性能分析: 时间复杂度: 最坏 : 逆序最坏---O(N^2) 最好:顺序最好---O(N)(√) O(1)(×) 因为至少每个数都要和前一个数据比较一次 两大步骤: 1.预排序---使数组元素接近有序 实现预排序方法:分组,将数据每隔gap分一组,一共可以分gap组,利用直接插入排序的思想,实现每组数据有序,整体就接近有序 2.直接插入排序 每组排好序后,再用直接插入排序就可以更快地实现排序 每组数据的排序本质就是直接插入排序,但是每一组元素不是紧邻了,改一改代码即可~ 以第1组数据的排序为例: 1.类比直接插入排序即可,注意相邻元素之间下标间隔gap即可,i+=gap 2.注意i范围,由于进入循环后要执行tmp = a[i+gap] 这句代码,因此 i 写法一:三层循环(两层for,一层while) 第一层境界代码示例只解决了第1组数据排序,那其他组呢?毫无疑问,外层套上for循环 一共有gap组,外层循环j的范围就从0到gap即可,内层循环i每次从j开始即可,这样就实现了第1组数据有序--->第二组数据有序--->····················第gap组数据有序 写法二:两层循环,更加简洁 写法一是每组数据彻底排好序后才进行下一组排序,而写法二是多组并排,不同组同时进行排序 前两层境界都是在实现希尔排序的第一个步骤---预排序,第三层境界就要实现最后的总体排序了,方法就是直接插入法,难道还需要再写一段直接插入排序代码吗? no! 直接插入排序的本质其实就是gap取1,所以我们只需要让gap最终取到1,就实现了目的~ 关键代码就是 gap = gap/3+1, 因为gap最终越除越小,最后gap/3必然可以取到0,再加1就是gap=1的情况,就自动实现了最终的直接插入排序 希尔排序的特性总结: 1.希尔排序是对直接插入排序的优化 2.gap取值对排序的影响: 总结:gap>1都是预排序,gap==1时,数组已经接近有序,整体而言达到了优化的效果 细节:①gap越大,大的数可以更快到后面,小的数可以更快到前面,但越不接近有序 ②gap越小,大数据和小数据都挪动越慢,但是越接近有序 ③gap == 1, 就是直接插入排序 3.希尔排序的时间复杂度: 这是一个尚未证明的问题,有人总结出了经验公式,我们且认为是在O(n^1.25) 到 O(1.6*n^1.25) 内层循环控制比较次数,外层循环控制趟数,冒泡本质是相邻数比较,两两交换,大数下沉~ 第一层境界要比较n-1趟,无论中间排序排的如何了,甚至有序了,还是会走完余下趟数~ 而第二层境界 是当某一趟走完发现没有发生任何元素的交换,那就说明已经有序了,直接跳出 插入排序与冒泡排序算法性能比较分析 插入排序与冒泡排序时间复杂度都是经典的O(N^2),但插入更优一点,这时就要关注细节了~ 结论:插入排序比冒泡排序适应性更强,尤其是当大部分数据有序,局部无序的时候,插入排序相比冒泡排序优势就显现出来了~ 堆排序在我的博客《独树一帜的完全二叉树---堆》已经详细讲解过了,这里只给出核心代码 思想:每一轮待排序数据中选出最小的数据,依次放在最左边 第1趟遍历:选出最小放在a[0]位置;第2趟遍历:选出次小放在a[1]位置;依次类推~ 选择排序优化:每次都要遍历一趟,找出了小的,不妨也把大的找出来,小的放左边,大的放右边 避坑:当maxi和begin位置的值重合时,上述代码有问题 改进方法:在mini和begin位置元素交换完之后修正一下即可 选择排序时间复杂度:O(N^2) 选择排序在实际中没有太多应用,没有自己的一技之长~ 版本一:hoare版本 被称为二叉树结构的快速排序---实际并非二叉树,只是递归过程类似二叉树结构,并且所有操作都是在原数组上进行的(以下图示多个数组只是为了形象展示过程) 思想: 纵观全局:随机选取一个基准值key,再使得key的左区间值均小于key,右区间值均大于key。如此key值就被调整到了正确位置,接下来对左右区间进行相同的操作,显然就是递归调用函数了~ 庖丁解牛:如何让每一个区间选取的key来到正确位置呢?(注:hoare版本的key一般都选取区间左端点值或右端点值),下面以key取区间左端点为例 接下来整个数组将被分成三部分:[begin,keyi-1] keyi [keyi+1, end],对左右区间进行递归~ 代码:(以下代码存在问题) 细节阐释:递归的结束条件: 当区间中只有一个数时就不需要排序了,即begin == end 当区间不存在时也应该结束递归 即begin > end 坑1:left起始位置可以是begin+1(×) 因此left下标必须从begin开始,不能从begin+1开始 但是代码仍存在问题,以下是某些特殊情况的分析(坑2与坑3) 坑:2:死循环 填坑:>改>= , <改 <= 坑3:越界 一波刚平,一波又起,就在刚在填了坑1和坑2之后坑3就产生了,下标有可能会越界 填坑:内层while循环加入left与right大小判断 到此为止,坑就填完了,代码也已经全部正确~ hoare版本难点分析: 问:当left和right相遇之后,会交换a[left]和a[keyi],如何保证相遇位置的值一定比a[keyi]要小? 答:当keyi取的是区间左端点的时候,要让right先走,同理,当keyi取的是区间右端点的时候,要让left先走 证明:(以keyi选取左端点下标为例) left和right相遇,只有两种情况: 1. right处于停止状态,left遇right ; right停止,说明right遇到了比a[keyi]小的值,此时left遇right, a[left] 就 < a[keyi] 2. left处于停止状态, right遇left ; right遇left,则在相遇的这一轮left没有动,left之前可能压根没动或者交换了一些轮次 ①left 没动的话,就是keyi的位置,那么right也就来到了keyi位置,自己和自己交换结果不受影响 ②交换了一些轮次的话,则left始终存储了比keyi小的值~ 版本二:挖坑法(更好理解,"坑"也更少)---hoare版本的变形---代码大同小异 为什么说挖坑法更好理解,因为整个过程left和right其中一个必然是坑,无论是right找到了小,还是left找到了大,直接填坑即可,然后形成新的坑~ 代码: 版本三:前后指针法(最推荐的版本)---天才设想 第一轮操作如下图所示,后序仍然是递归调用自己~ 前后指针法本质分析: 无论a[cur]与a[keyi]大小关系如何,cur一直向后走;而a[cur] 这就导致如果prev和cur中间间隔数据,那么这些数据必然比a[keyi]要大,因此当cur遇到比a[keyi]小的数据就交换prev后面一个数据和当前cur的值,使得小数换到前面,大数去到后面, 所以大数会跳跃式的往后移动,小数也会跳跃式的往前移动~ 当cur越界跳出循环时,prev前面的所有值就都比a[keyi]小了,再交换a[prev]与a[keyi],就使得左区间 代码实现 主要体现在选key上,我们默认都是区间左端点值做key,但是当数组有序的时候每次左区间不存在,右区间长度减少1,因此时间复杂度就是标准的等差数列---O(N^2),效率低下~ 1.三数取中:区间的左端点值,右端点值,中间位置的值三个数中选大小适中的数作为key 三数取中代码实现: 三个版本在函数开始加上这两句代码就实现了三数取中的优化方案~ 2.随机数选key---三数取中进一步优化 3.三路划分---专门解决快速排序遇到有大量重复元素的问题 大量重复元素会导致什么问题呢? 大量重复元素导致的问题和数组有序导致的问题有异曲同工之处,都是每次右区间长度只减少1,导致了时间复杂度是标准的等差数列---O(N^2),而三路划分可以解决这个问题 三路划分: 三路划分核心逻辑: 1.a[cur] 2.a[cur]>key,交换a[cur]和a[right],--right 3.a[cur] == key ,++cur 理解:left一直指向了key的位置,而整个过程本质是把left甩左边,right甩右边,把和key相等的值往中间推的过程 代码: ps:三路划分中key的选取同样可以采用随机数选key来实现 "梅须逊雪三分白,雪却输梅一段香",快速排序递归法外强中干,却有着栈溢出的风险~,高手写代码,能用非递归,不用递归~ 递归无非也是在递归每段区间罢了,利用栈的后进先出,我们同样可以采用循环处理每段区间 思想:每次从栈里面拿出一段区间,单趟分割处理,左右区间入栈 用栈处理区间实现快速排序过程示意图 四大问题: 1.一段区间如何入栈? 答:分成右端点和坐端点依次入栈即可(左端点先入栈,右端点后入栈也可以) 2.一个区间划分为左右区间后哪个区间先入栈? 答:都可以,就看你想先处理左区间还是想先处理右区间 先处理左区间---右区间先入栈;先处理右区间---左区间先入栈; 3.什么时候压栈结束? 答:当区间左端点>=右端点,即不需要再划分区间也就不需要区间入栈了 4.什么时候循环结束? 答:栈为空 代码(以先处理左区间为例)---栈的实现参考我的博客《别样的数据结构---栈》 1.时间复杂度: 最好:每次找到的key都是中位数,快排过程的逻辑结构就是完美的二叉树---O(N*logN) 最坏:数组有序(若选取左端点做key)---O(N^2) 按理来说时间复杂度是按照最坏情况来算的,但是快排的时间复杂度是O(N*logN),因为我们一般不会直接选取左端点选key,而是采取随机数选k或者三数取中进行了优化 2.空间复杂度: O(logN)---递归调用消耗logN层栈帧 其实归并排序的思想本质就是二叉树遍历方法中后序的思想---左右子树遍历完才遍历根 那么“归并”二字体现在哪?就体现在左右区间有序之后的合并过程从而使整体有序 而归并肯定要新建一个数组,归并好了之后拷贝回原数组,直接在原数组归并会产生覆盖值的问题 代码: 1.递归结束条件:begin == end ,也就是区间只有一个数;begin不可能>end, 因为区间划分是[begin, mid] [mid+1, end] ,而mid=(begin+end) / 2 , 当begin和end相等时mid最大等于end,而此时就是区间只有一个数的情况,已经不需要再分了 2.memcpy函数要注意src和dest位置,因为每次二分区间之后区间下标不一定是从0开始;还要注意数据个数,不是i, i是单纯的下标,应该用end-begin+1来算 归并排序复杂度分析: 时间复杂度:O(N*logN)---完美的二叉树 空间复杂度:O(N) 开辟tmp数组:O(N) ; 递归调用:O(logN) 总共:O(N+logN)---O(N) 归并排序递归优化版本:小区间优化 归并排序每次都是把区间一分为二,然后递归,但是慢慢到后面,一个区间数据就很少了,这时仍然去递归调用归并排序效率就比较低了,这时可以调用插入排序函数解决剩下的排序~ 区间长度小于多少开始调用插入函数不是固定的,一般取10差不多 进阶理解:可以看到,最下面三层递归调用次数占了总次数的87.5%,而倒数第四层每组数据差不多就是10个,因此没必要再提前调用插入函数了,意义不大~ 思路:通过控制归并每组数据个数gap的值,实现不断地归并,直至整个数组有序 代码建立一:gap取特定值时归并实现 好风凭借力,送我上青天~,cv一下归并核心代码 注意归并的两组数据每组数据是gap个,因此归并的两段区间begin与end位置要注意改一改(画图) 代码建立二:控制gap变化实现归并排序 8个数据测试确实没有问题,但是当测试9个数据,10个数据的时候,程序直接崩溃了 错误分析:越界问题,只要当数据个数不是2^N次方都会越界~ 打印区间下标分析越界情况: 错误解决方案1:遇到越界情况直接break跳出for循环 错误原因:因为最后要把tmp数组拷贝回a数组,如果直接break跳出循环,则tmp数组最后面数据就是随机值了,拷贝回原数组,不但后面数据没有排序,还覆盖了原数据 正确解决方案1:归并一段,拷贝一段 无非就是要处理越界的三种情形,可以发现,情形1,2属于一类,都是要归并的右区间整个不在数组范围内,压根不需要归并,直接break即可;而情形3的右区间部分越界,因此我们重新修正一下边界end2取值,使其等于数组最后一个数据下标即可(n-1),然后归并之后往回拷贝时只拷贝在数组的那一段就行 ps:归并的两数组并没有要求数据个数相同~ 错误解决方案2:仍采用归并完一趟后整体拷贝的方法,若越界,则修正边界到n-1 打印边界下标分析错误原因: 正确解决方案2:修正边界,直接使得右区间不存在,就不会执行归并相关逻辑代码,直接把第一个区间数据拷依次拷贝到tmp中 归并排序的硬伤在于数据拷贝~ 归并排序复杂度 时间复杂度:O(N*logN) 空间复杂度:O(N) 计数排序相比其他七大排序就比较特别了,因为其他七大排序都用到了数据的比较,也就是数据都要比大小,但是计数排序的实现不用比较数据大小,计数就是统计数据出现个数 步骤: 1.统计每个数据出现的个数 2.根据统计次数排序 初阶理解:绝对映射 进阶理解:相对映射 代码: 计数排序复杂度分析: 时间复杂度:O(N+range) --- 当N >> range --- O(N) 空间复杂度:O(Range) 计数排序缺陷: 缺陷1:依赖数据范围,适用于范围集中的数组 缺陷2:只能用于整形数据排序 问世间情为何物,不过是一物降一物,除了及个别排序外,剩下的排序都是各有千秋的~ 比较排序具有普适性,可以适用于任意数据样本,而非比较排序---计数排序就比较挑剔了~ 排序稳定性: 简单来说,数组中有若干相同的值,排序完之后这些相同的值前后位置保持不变,就说该排序是稳定的,否则就是不稳定的 稳定性意义何在?值不都相同嘛,在前在后有意义吗?当然有! 比如说考试3个同学成绩相同,那么根据交卷时间前后就可以分出一二三等奖~ 再比如说两个同学总分相同,但语文成绩高低不同,这时要排名的话,可以先按照语文成绩排序,然后采用一个稳定的排序算法对总分排序,那么总分相同的同学排名高低立现~ 本篇博客关于排序算法的分享就到这了,日拱一卒无有尽,功不唐捐终入海,不弃微末,久久为功,欢迎大家交流指正~ 
void InsertSort(int* a, int n)
{
int tmp;//一堆已经有序的数中插入tmp
int end;//end为数组中最后一个数的下标
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
第二层境界:一组数据从乱序到升序(真正的插入排序)(第一层境界的变形~)
void InsertSort(int* a, int n)
{
for (int i = 1;i < n;i++)
{
int tmp = a[i];
int end = i - 1;
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}void InsertSort(int* a, int n)
{
for (int i = 0;i < n-1;i++)
{
int tmp = a[i+1];//保存待比较数据,防止数据被覆盖丢失
int end = i;
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
二、希尔排序
第一层境界:gap组数据之每组数据的排序
void ShellSort(int* a, int n)
{
int gap = 3;
for (int i = 0;i < n - gap;i += gap)
{
int end = i;
int tmp = a[i + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}第二层境界:循环实现gap组数据的各组排序
void ShellSort(int* a, int n)
{
int gap = 3;
for (int j = 0;j < gap;j++)
{
for (int i = j;i < n - gap;i += gap)
{
int end = i;
int tmp = a[i + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}void ShellSort(int* a, int n)
{
int gap = 3;
for (int i = 0;i < n - gap;i++)
{
int end = i;
int tmp = a[i + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
第三层境界:gap组数据的最终排序算法
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
//也可以写成gap = gap / 2;
for (int i = 0;i < n - gap;i++)
{
int end = i;
int tmp = a[i + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
三、冒泡排序
第一层境界:傻傻比较走全程
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void BubbleSort(int* a, int n)
{
for (int i = 0;i < n - 1;i++)
{
for (int j = 0;j < n - 1 - i;j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], a[j + 1]);
}
}
}
}
第二层境界:边走边看中途停(第一层境界的优化)
void BubbleSort(int* a, int n)
{
for (int i = 0;i < n - 1;i++)
{
bool exchange = true;
for (int j = 0;j < n - 1 - i;j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], a[j + 1]);
exchange = false;
}
}
if (exchange)
{
break;
}
}
}
四、堆排序
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child+1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0;i--)
{
AdjustDown(a, n, i);
}
//向下调整
int end = n - 1;
while (end >= 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
五、选择排序
void SelectSort(int* a, int n)
{
for (int i = 0;i < n;i++)
{
int mini = i;
for (int j = i + 1;j < n;j++)
{
if (a[mini] > a[j])
{
mini = j;
}
}
Swap(&a[mini], &a[i]);
}
}void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mini = begin;
int maxi = end;
//该循环确定每一趟中的最大值下标和最小值下标
for (int i = begin;i <= end;i++)
{
if (a[mini] > a[i])
{
mini = i;
}
if (a[maxi] < a[i])
{
maxi = i;
}
}
//循环结束后应该交换最小值和begin位置元素,交换最大值和end位置元素
Swap(&a[begin], &a[mini]);
Swap(&a[end], &a[maxi]);
//缩小区间范围
begin++;
end--;
}
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mini = begin;
int maxi = end;
//该循环确定每一趟中的最大值下标和最小值下标
for (int i = begin;i <= end;i++)
{
if (a[mini] > a[i])
{
mini = i;
}
if (a[maxi] < a[i])
{
maxi = i;
}
}
//循环结束后应该交换最小值和begin位置元素,交换最大值和end位置元素
Swap(&a[begin], &a[mini]);
//处理特殊情况---maxi和begin重叠
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
//缩小区间范围
begin++;
end--;
}
}
六、快速排序
第一层境界:递归实现(三大版本)


int PartSort1(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
while (a[right] > a[keyi])
{
right--;
}
while (a[left] < a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
return left;
}
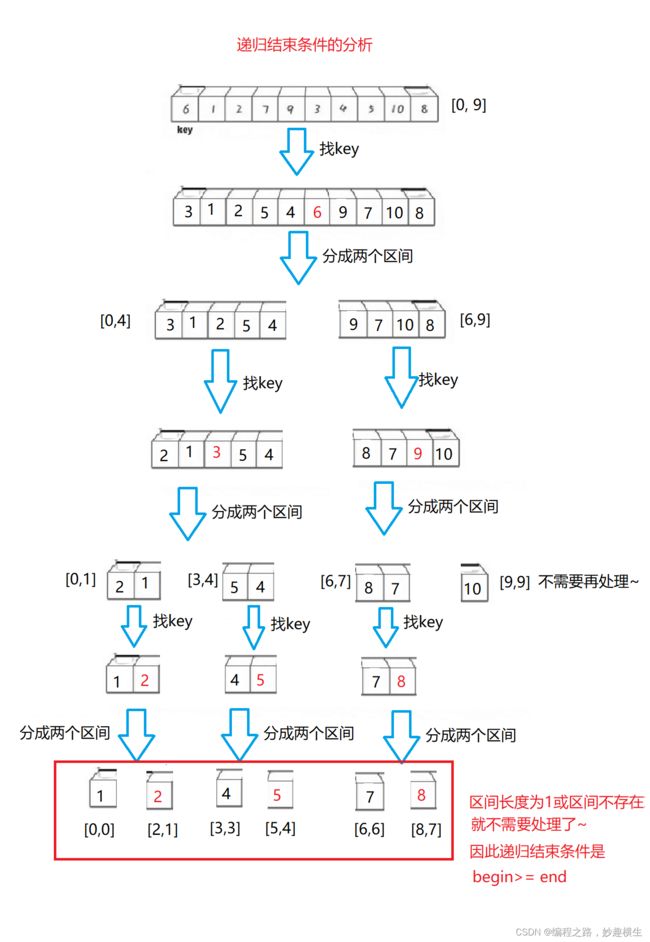
void QuickSort(int* a, int begin, int end)
{
//结束条件两种情况
//1.区间长度为0,代表只剩下一个数据
//2.区间不存在
if (begin >= end)
{
return;
}
int keyi = PartSort1(a, begin, end);
//区间划分:[begin,keyi-1] && keyi && [keyi+1, end]
//递归
PartSort1(a, begin, keyi - 1);
PartSort1(a, keyi + 1, end);
}
避坑:
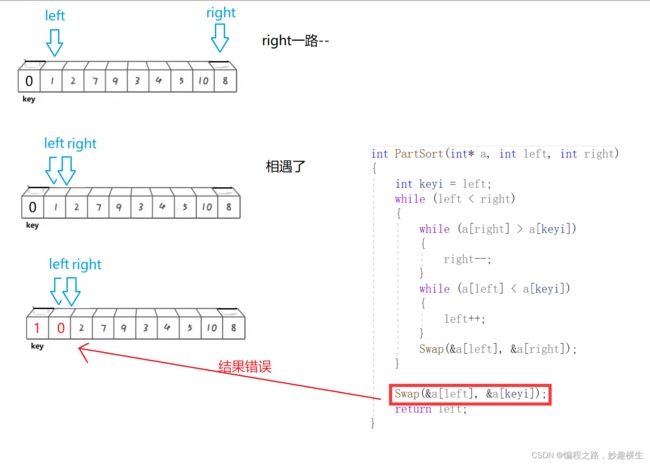

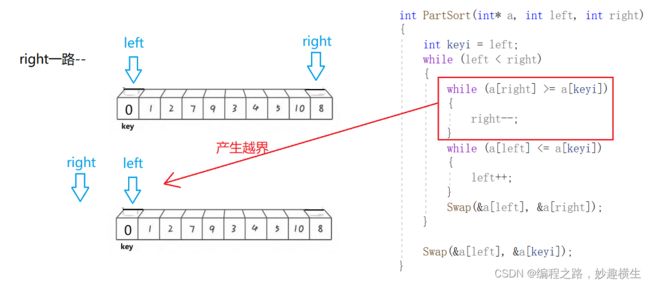
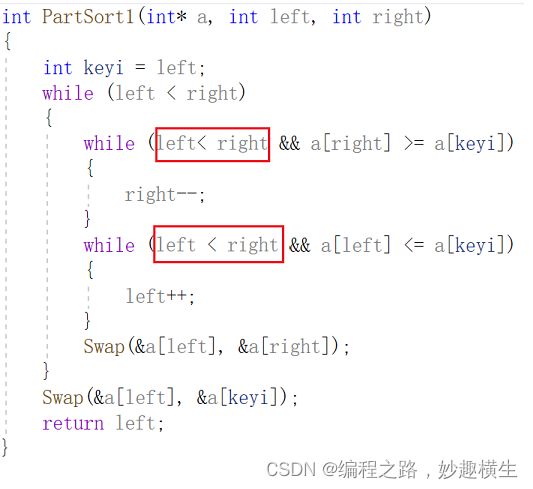
int PartSort1(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
while (left< right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
return left;
}
void QuickSort(int* a, int begin, int end)
{
//结束条件两种情况
//1.区间长度为0,代表只剩下一个数据
//2.区间不存在
if (begin >= end)
{
return;
}
int keyi = PartSort3(a, begin, end);
//区间划分:[begin,keyi-1] && keyi && [keyi+1, end]
//递归
PartSort3(a, begin, keyi - 1);
PartSort3(a, keyi + 1, end);
}
int PartSort2(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
void QuickSort(int* a, int begin, int end)
{
//结束条件两种情况
//1.区间长度为0,代表只剩下一个数据
//2.区间不存在
if (begin >= end)
{
return;
}
int keyi = PartSort2(a, begin, end);
//区间划分:[begin,keyi-1] && keyi && [keyi+1, end]
//递归
PartSort2(a, begin, keyi - 1);
PartSort2(a, keyi + 1, end);
}
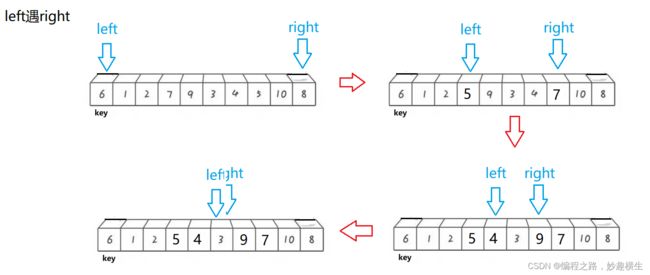
int PartSort3(int* a, int left, int right)
{
int prev = left;
int cur = left + 1;
int keyi = left;
while (cur <= right)
{
if(a[cur] < a[keyi])
{
prev++;
Swap(&a[prev], &a[cur]);
}
//更好的if写法
if(a[cur] < a[keyi] && ++prev != cur) //自己和自己交换没有意义
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[keyi], &a[prev]);
return prev;
}
void QuickSort(int* a, int begin, int end)
{
//结束条件两种情况
//1.区间长度为0,代表只剩下一个数据
//2.区间不存在
if (begin >= end)
{
return;
}
int keyi = PartSort3(a, begin, end);
//区间划分:[begin,keyi-1] && keyi && [keyi+1, end]
//递归
PartSort3(a, begin, keyi - 1);
PartSort3(a, keyi + 1, end);
}
以上三个版本代码缺陷:
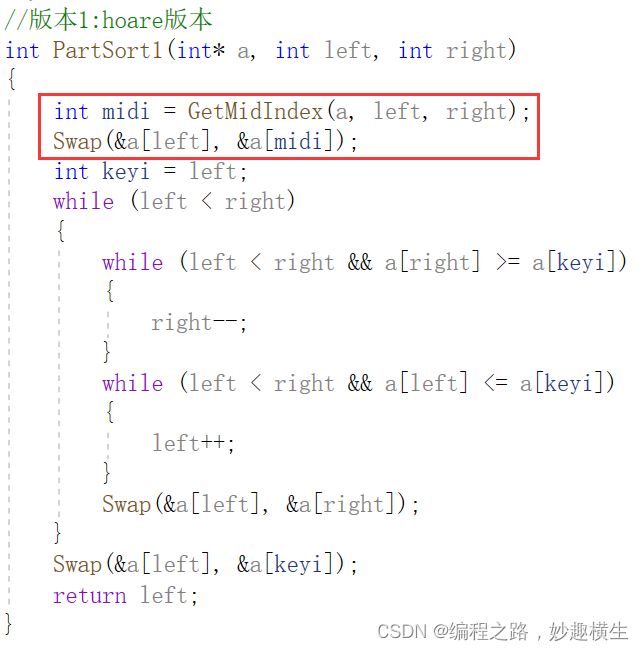
快速排序递归版本选key优化
int GetMidIndex(int* a, int left, int right)
{
int midi = (left + right) / 2;
if (a[left] < a[midi])
{
if (a[midi] < a[right])
{
return midi;
}
else if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
else//a[left] > a[midi]
{
if (a[midi] > a[right])
{
return midi;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
int GetMidIndex(int* a, int left, int right)
{
int midi = left + (rand() % (right - left));
if (a[left] < a[midi])
{
if (a[midi] < a[right])
{
return midi;
}
else if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
else //a[left] > a[midi]
{
if (a[midi] > a[right])
{
return midi;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
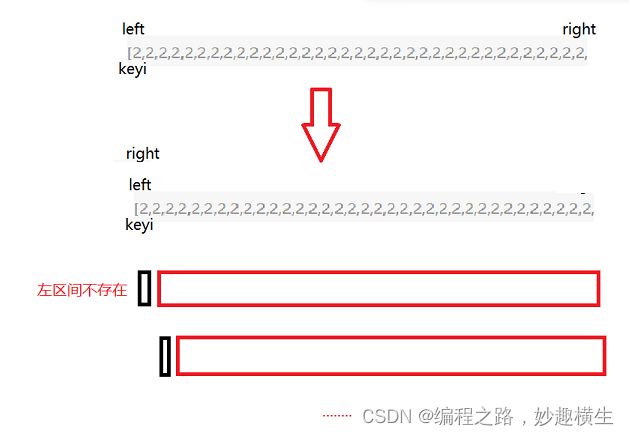

//三路划分实现快排
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int left = begin;
int right = end;
int cur = left + 1;
int key = a[left];
while (cur <= right)
{
if (a[cur] < key)
{
Swap(&a[left], &a[cur]);
++left;
++cur;
}
else if (a[cur] > key)
{
Swap(&a[right], &a[cur]);
--right;
}
else
{
cur++;
}
}
//子区间
//[begin, left-1], [left, right], [right+1, end]
//递归调用
QuickSort(a, begin, left - 1);
QuickSort(a, right + 1, end);
}第二层境界:非递归实现(借助栈)
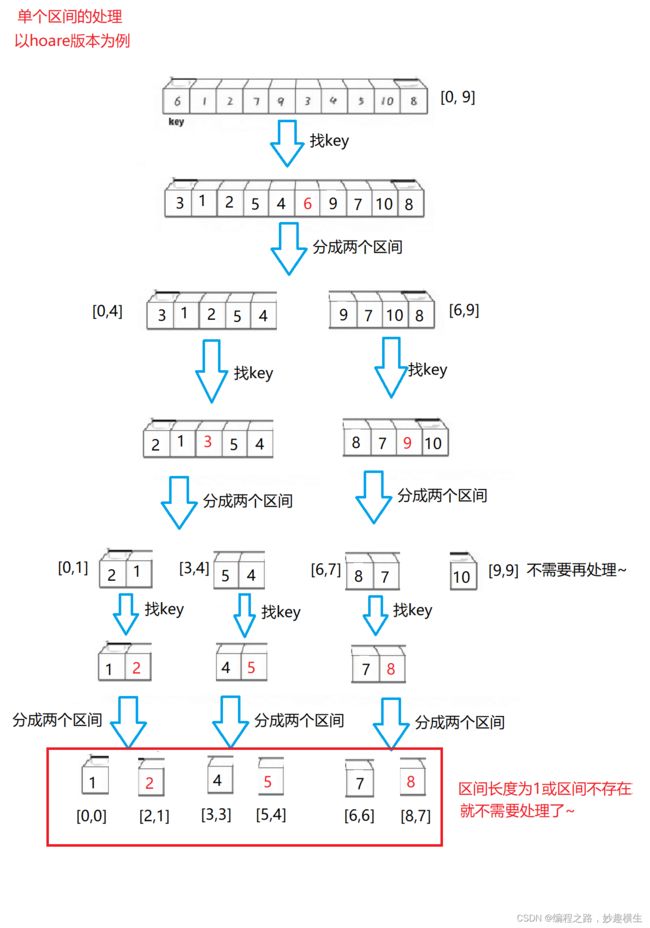
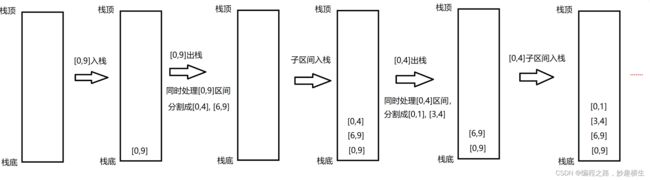
#include"Sort.h"
#include"Stack.h"
void PrintArray(int* a, int n)
{
for (int i = 0;i < n;i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
int PartSort3(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
prev++;
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
STInit(&st);
STPush(&st, end);
STPush(&st, begin);
while (!STEmpty(&st))
{
int left = STTop(&st);
STPop(&st);
int right = STTop(&st);
STPop(&st);
int keyi = PartSort3(a, left, right);
if (keyi+1 < right)
{
STPush(&st, right);
STPush(&st, keyi + 1);
}
if (left < keyi - 1)
{
STPush(&st, keyi-1);
STPush(&st, left);
}
}
STDestroy(&st);
}快速排序复杂度分析
七、归并排序
第一层境界:递归实现
思想:数组一分为二,整体有序则需左右有序,左右有序则递归即可~
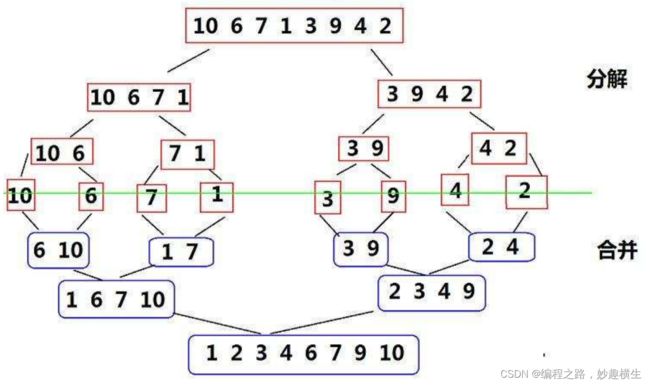


//归并排序递归实现
void _MergeSort(int* a, int begin, int end, int* tmp)
{
//begin不可能>end
if (begin == end)
{
return;
}
//分割区间
int mid = (begin + end) / 2;
//[begn,mid] [mid + 1, end]
//递归
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//归并
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
//取小的尾插
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//有一个走完了,还有一个没走完
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//拷贝数据
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}代码要点:
第二层境界:非递归实现(循环实现)

void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
//gap表示要归并的两个组的每个组的数据个数
//gap ==1 表示一一归
int gap = 1;
int j = 0;
for (int i = 0; i < n;i+=2*gap)
{
//每组数据的归并
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end1)
{
tmp[j++] = a[begin2++];
}
}
}//归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
//gap表示要归并的两个组的每个组的数据个数
//gap ==1 表示一一归
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n;i += 2 * gap)
{
//每组数据的归并
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
}
//每合并一次把数据拷贝回原数组
memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}

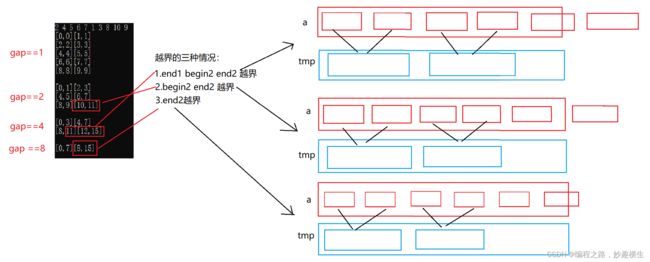
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
//gap表示要归并的两个组的每个组的数据个数
//gap ==1 表示一一归
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n;i += 2 * gap)
{
//每组数据的归并
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//处理越界情况1、2
if (end1 >= n || begin2 >= n)
{
break;
}
//处理越界情况3
//修正end2边界
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
//每归并一段,就拷贝该段到原数组
memcpy(a+i, tmp+i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
}void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
//gap表示要归并的两个组的每个组的数据个数
//gap ==1 表示一一归
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n;i += 2 * gap)
{
//每组数据的归并
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (end1 >= n)
{
end1 = n - 1;
begin2 = n - 1;
end2 = n - 1;
}
else if (begin2 >= n)
{
begin2 = n - 1;
end2 = n - 1;
}
else if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
}
memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}


void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
//gap表示要归并的两个组的每个组的数据个数
//gap ==1 表示一一归
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n;i += 2 * gap)
{
//每组数据的归并
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (end1 >= n)
{
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
else if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
}
memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}
八、计数排序
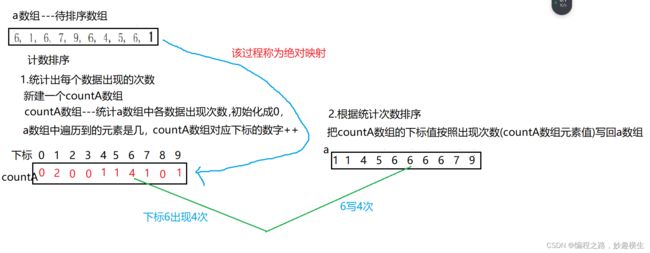
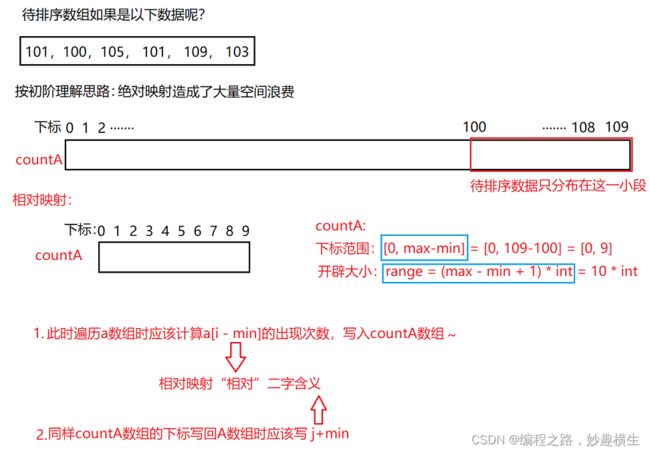
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];
for (int i = 0;i < n;i++)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;
int* countA = (int*)malloc(sizeof(int) * range);
memset(a, 0, sizeof(int) * range);
//统计次数
for(int i = 0;i
九、八大排序总结