数字人解决方案——NeRF实现实时对话数字人环境配置与源码
前言
1.这是一个能实时对话的虚拟数字人demo,使用的是NeRF(Neural Radiance Fields),训练方式可以看看我前面的博客。
2.文本转语音是用了VITS语音合成,项目git:https://github.com/jaywalnut310/vits .
3.语言模型是用了新开源的ChatGLM2-6B,当前的项目暂时没有加上这个接口。GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型 )
4.声音克隆用的是PaddleSpeech,这个语音克隆训练起来很快,使用的数据集也相对少一些,当前的项目暂时没有加上语音克隆。
GitHub - PaddlePaddle/PaddleSpeech: Easy-to-use Speech Toolkit including Self-Supervised Learning model, SOTA/Streaming ASR with punctuation, Streaming TTS with text frontend, Speaker Verification System, End-to-End Speech Translation and Keyword Spotting. Won NAACL2022 Best Demo Award.Easy-to-use Speech Toolkit including Self-Supervised Learning model, SOTA/Streaming ASR with punctuation, Streaming TTS with text frontend, Speaker Verification System, End-to-End Speech Translation and Keyword Spotting. Won NAACL2022 Best Demo Award. - GitHub - PaddlePaddle/PaddleSpeech: Easy-to-use Speech Toolkit including Self-Supervised Learning model, SOTA/Streaming ASR with punctuation, Streaming TTS with text frontend, Speaker Verification System, End-to-End Speech Translation and Keyword Spotting. Won NAACL2022 Best Demo Award. https://github.com/PaddlePaddle/PaddleSpeech
https://github.com/PaddlePaddle/PaddleSpeech
5.当现实现的效果:
实时对话数字人
语音合成
1.VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。VITS通过隐变量而非频谱串联起来语音合成中的声学模型和声码器,在隐变量上进行随机建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。
2.声学模型是声音合成系统的重要组成部分:
它使用预先训练好的语音编码器 (vocoder声码器) 将文本转化为语音。
3.VITS 的工作流程如下:
- 将文本输入 VITS 系统,系统会将文本转化为发音规则。
- 将发音规则输入预先训练好的语音编码器 (vocoder),vocoder 会根据发音规则生成语音信号的特征表示。
- 将语音信号的特征表示输入预先训练好的语音合成模型,语音合成模型会根据特征表示生成合成语音。
- VITS 的优点是生成的语音质量较高,能够生成流畅的语音。但是,VITS 的缺点是需要大量的训练语料来训练 vocoder 和语音合成模型,同时需要较复杂的训练流程。
4.把项目git下来后,我们试试用VITS做个语音合成,这里使用gradio来辅助创建个demo。
import os
from datetime import datetime
current_path = os.path.dirname(os.path.abspath(__file__))
os.environ["PATH"] = os.path.join(current_path, "ffmpeg/bin/") + ";" + os.environ["PATH"]
import torch
import commons
import utils
import re
from models import SynthesizerTrn
from text import text_to_sequence_with_hps as text_to_sequence
from scipy.io.wavfile import write
from pydub import AudioSegment
import gradio as gr
dir = "data/video/results/"
device = torch.device("cpu") # cpu mps
hps = utils.get_hparams_from_file("{}/configs/finetune_speaker.json".format(current_path))
hps.data.text_cleaners[0] = 'my_infer_ce_cleaners'
hps.data.n_speakers = 2
symbols = hps.symbols
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).to(device)
_ = net_g.eval()
# G_latest G_trilingual G_930000 G_953000 G_984000 G_990000 G_1004000 G_1021000
# _ = utils.load_checkpoint("C:/code/vrh/models/G_1/G_1.pth", net_g, None)
_ = utils.load_checkpoint("C:/code/vrh/models/G_1/G_1.pth", net_g, None)
def add_laug_tag(text):
'''
添加语言标签
'''
pattern = r'([\u4e00-\u9fa5,。!?;:、——……()]+|[a-zA-Z,.:()]+|\d+)'
segments = re.findall(pattern, text)
for i in range(len(segments)):
segment = segments[i]
if re.match(r'^[\u4e00-\u9fa5,。!?;:、——……()]+$', segment):
segments[i] = "[ZH]{}[ZH]".format(segment)
elif re.match(r'^[a-zA-Z,.:()]+$', segment):
segments[i] = "[EN]{}[EN]".format(segment)
elif re.match(r'^\d+$', segment):
segments[i] = "[ZH]{}[ZH]".format(segment) # 数字视为中文
else:
segments[i] = "[JA]{}[JA]".format(segment) # 日文
return ''.join(segments)
def get_text(text, hps):
text_cleaners = ['my_infer_ce_cleaners']
text_norm = text_to_sequence(text, hps.symbols, text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def infer_one_audio(text, speaker_id=94, length_scale=1):
'''
input_type: 1输入自带语言标签 2中文 3中英混合
length_scale: 语速,越小语速越快
'''
with torch.no_grad():
stn_tst = get_text(text, hps)
x_tst = stn_tst.to(device).unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
sid = torch.LongTensor([speaker_id]).to(device) # speaker id
audio = \
net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=length_scale)[
0][0, 0].data.cpu().float().numpy()
return audio
return None
def infer_one_wav(text, speaker_id, length_scale, wav_name):
'''
input_type: 1输入自带语言标签 2中文 3中英混合
length_scale: 语速,越小语速越快
'''
audio = infer_one_audio(text, speaker_id, length_scale)
write(wav_name, hps.data.sampling_rate, audio)
print('task done!')
def add_slience(wav_path, slience_len=100):
silence = AudioSegment.silent(duration=slience_len)
wav_audio = AudioSegment.from_wav(wav_path)
wav_audio = wav_audio + silence
wav_audio.export(wav_path, format="wav")
pass
# if __name__ == '__main__':
# infer_one_wav(
# '觉得本教程对你有帮助的话,记得一键三连哦!',
# speaker_id=0,
# length_scale=1.2)
def vits(text):
now = datetime.now()
timestamp = datetime.timestamp(now)
file_name = str(timestamp%20).split('.')[0]
audio_path = dir + file_name + ".wav"
infer_one_wav(text,0,1.2,audio_path) #语音合成
return audio_path
inputs = gr.Text()
outputs = gr.Audio(label="Output")
demo = gr.Interface(fn=vits, inputs=inputs, outputs=outputs)
demo.launch()

合成视频
1.RAD-NeRF是可以对视频中所出现的说话者进行实时的人像合成。它是一种基于神经网络从一组二维图像重建三维体景。
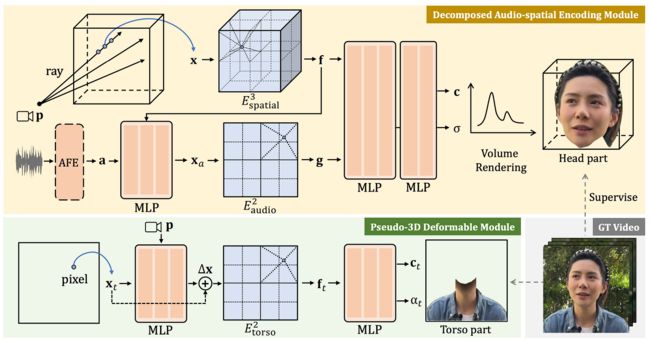
RAD-NERF网络概述
RAD-NeRF使用一个网络来预测正在可视化的相机视点的所有像素颜色和密度,当镜头围绕主题旋转时,想要显示的所有视点都是这样做的,这是非常需要计算力的,因为在每次学习预测图像中每个坐标的多个参数。此外,在这种情况下,这不仅仅是一个NeRF产生一个3D场景。还必须匹配音频输入,使嘴唇、嘴巴、眼睛和动作与人说的话相匹配。
网络不再预测所有像素的密度和颜色与特定帧的音频相匹配,而是使用两个独立的新压缩空间,称为网格空间,或基于网格的NeRF。再将坐标转换成较小的3D网格空间,将音频转换成较小的2D网格空间,然后将其发送到渲染头部。这意味着网络永远不会将音频数据与空间数据合并在一起,这将以指数方式增加大小,为每个坐标添加二维输入。因此,减少音频特征的大小,同时保持音频和空间特征的分离,将使这种方法更加有效。
但是,如果使用包含较少信息的压缩空间,结果如何会才能更好呢?在NeRF中添加一些可控制的特征,如眨眼控制,与以前的方法相比,模型将学习更真实的眼睛行为。这对能还原更加真实的人尤其重要。

RAD-NeRF所做的第二个改进(模型概述中的绿色矩形)是使用相同的方法用另一个 NERF 建模躯干,而不是试图用用于头部的相同 NERF 建模躯干,这将需要更少的参数和不同的需求,因为这里的目标是动画移动的头部而不是整个身体。由于躯干在这些情况下是相当静态的,他们使用一个更简单和更有效的基于 NERF 的模块,只在2D 中工作,直接在图像空间中工作,而不是像平时通常使用 NERF 那样使用摄像机光线来产生许多不同的角度,这对躯干来说是不需要的。然后,重新组合头部与躯干,以产生最后的视频。
头像调整演示操作
2.当模型训练完之后,只需要data目录下的transforms_train.json文件和微调身体的后的模型文件就可以开始写推理代码了。步骤如下:
- 输入语音或文字(这里为了方便演示,只写了文字输入的接口)
- 获取输入的信息,调LLM(大型语文模型)来回答 (该项目当前还没有引入LLM,只写了几句固定的回答,之后有时间会把LLM与本地知识库加上)。
- 对获取的回答进行语音合成,并生成用于驱动视频的.npy文件。
- 使用.npy与transforms_train.json里面的数据合成视频,输出。
import gradio as gr
import base64
import time
import json
import gevent
from gevent import pywsgi
from geventwebsocket.handler import WebSocketHandler
from tools import audio_pre_process, video_pre_process, generate_video, audio_process
import os
import re
import numpy as np
import threading
import websocket
from pydub import AudioSegment
from moviepy.editor import VideoFileClip, AudioFileClip, concatenate_videoclips
import cv2
import pygame
from datetime import datetime
import os
dir = "data/video/results/"
audio_pre_process()
video_pre_process()
current_path = os.path.dirname(os.path.abspath(__file__))
os.environ["PATH"] = os.path.join(current_path, "ffmpeg/bin/") + ";" + os.environ["PATH"]
import torch
import commons
import utils
import re
from models import SynthesizerTrn
from text import text_to_sequence_with_hps as text_to_sequence
from scipy.io.wavfile import write
device = torch.device("cpu") # cpu mps
hps = utils.get_hparams_from_file("{}/configs/finetune_speaker.json".format(current_path))
hps.data.text_cleaners[0] = 'my_infer_ce_cleaners'
hps.data.n_speakers = 2
symbols = hps.symbols
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).to(device)
_ = net_g.eval()
# G_latest G_trilingual G_930000 G_953000 G_984000 G_990000 G_1004000 G_1021000
_ = utils.load_checkpoint("C:/code/vrh/models/G_1/G_1.pth", net_g, None)
def add_laug_tag(text):
'''
添加语言标签
'''
pattern = r'([\u4e00-\u9fa5,。!?;:、——……()]+|[a-zA-Z,.:()]+|\d+)'
segments = re.findall(pattern, text)
for i in range(len(segments)):
segment = segments[i]
if re.match(r'^[\u4e00-\u9fa5,。!?;:、——……()]+$', segment):
segments[i] = "[ZH]{}[ZH]".format(segment)
elif re.match(r'^[a-zA-Z,.:()]+$', segment):
segments[i] = "[EN]{}[EN]".format(segment)
elif re.match(r'^\d+$', segment):
segments[i] = "[ZH]{}[ZH]".format(segment) # 数字视为中文
else:
segments[i] = "[JA]{}[JA]".format(segment) # 日文
return ''.join(segments)
def get_text(text, hps):
text_cleaners = ['my_infer_ce_cleaners']
text_norm = text_to_sequence(text, hps.symbols, text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def infer_one_audio(text, speaker_id=94, length_scale=1):
'''
input_type: 1输入自带语言标签 2中文 3中英混合
length_scale: 语速,越小语速越快
'''
with torch.no_grad():
stn_tst = get_text(text, hps)
x_tst = stn_tst.to(device).unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
sid = torch.LongTensor([speaker_id]).to(device) # speaker id
audio = \
net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=length_scale)[
0][0, 0].data.cpu().float().numpy()
return audio
return None
def infer_one_wav(text, speaker_id, length_scale, wav_name):
'''
input_type: 1输入自带语言标签 2中文 3中英混合
length_scale: 语速,越小语速越快
'''
audio = infer_one_audio(text, speaker_id, length_scale)
write(wav_name, hps.data.sampling_rate, audio)
print('task done!')
def add_slience(wav_path, slience_len=100):
silence = AudioSegment.silent(duration=slience_len)
wav_audio = AudioSegment.from_wav(wav_path)
wav_audio = wav_audio + silence
wav_audio.export(wav_path, format="wav")
pass
def play_audio(audio_file):
pygame.mixer.init()
pygame.mixer.music.load(audio_file)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
pygame.mixer.music.stop()
def answer(message, history):
global dir
history = history or []
message = message.lower()
if message=="你好":
response = "你好,有什么可以帮到你吗?"
elif message=="你是谁":
response = "我是虚拟数字人幻静,你可以叫我小静或者静静。"
elif message=="你能做什么":
response = "我可以陪你聊天,回答你的问题,我还可以做很多很多事情!"
else:
response = "你的这个问题超出了我的理解范围,等我学习后再来回答你。"
history.append((message, response))
save_path = text2video(response,dir)
return history,history,save_path
def text2video(text,dir):
now = datetime.now()
timestamp = datetime.timestamp(now)
file_name = str(timestamp%20).split('.')[0]
audio_path = dir + file_name + ".wav"
infer_one_wav(text,0,1.1,audio_path) #语音合成
audio_process(audio_path)
audio_path_eo = dir+file_name+"_eo.npy"
save_path = generate_video(audio_path_eo, dir, file_name,audio_path)
return save_path
with gr.Blocks(css="#chatbot{height:300px} .overflow-y-auto{height:500px}") as rxbot:
with gr.Row():
video = gr.Video(label = "数字人",autoplay = True)
with gr.Column():
state = gr.State([])
chatbot = gr.Chatbot(label = "消息记录").style(color_map=("green", "pink"))
txt = gr.Textbox(show_label=False, placeholder="请输入你的问题").style(container=False)
txt.submit(fn = answer, inputs = [txt, state], outputs = [chatbot, state,video])
rxbot.launch()运行代码,然后打开http://127.0.0.1:7860/ ,然后输入文字就可得到回答合成的视频。
源码
1.当前的源码包含了语音合成与视频合成两个模型,环境依赖最难装的部分应该是pytorch3d,这个可以参考我之前的博客:
数字人解决方案——基于真人视频的三维重建数字人源码与训练方法_知来者逆的博客-CSDN博客
2.源码在win10,cuda 11.7,cudnn 8.5,python3.10,conda环境下测试运行成功。源码下载地址:
https://download.csdn.net/download/matt45m/88078575
下载源码后,创建conda环境:
cd vrh
#创建虚拟环境
conda create --name vrh python=3.10
activate vrh
#pytorch 要单独对应cuda进行安装,要不然训练时使用不了GPU
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
#安装所需要的依赖
pip install -r requirements.txt
windows下安装pytorch3d,这个依赖还是要在刚刚创建的conda环境里面进行安装。
git clone https://github.com/facebookresearch/pytorch3d.git
cd pytorch3d
python setup.py install如果下载pytorch3d很慢,可以使用这个百度网盘下载:链接:https://pan.baidu.com/s/1z29IgyviQe2KQa6DilnRSA 提取码:dm4q
如果安装中间报错退出,这里建议安装vs 生成工具。Microsoft C++ 生成工具 - Visual Studio编辑https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/ https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/3.如果对该项目感兴趣或者在安装的过程中遇到什么错误的的可以加我的企鹅群:487350510,大家一起探讨。
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/3.如果对该项目感兴趣或者在安装的过程中遇到什么错误的的可以加我的企鹅群:487350510,大家一起探讨。