6.4.tensorRT高级(1)-UNet分割模型导出、编译到推理(无封装)
目录
-
- 前言
- 1. Unet导出
- 2. Unet推理
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-Unet分割模型导出、编译到推理(无封装)
课程大纲可看下面的思维导图
1. Unet导出
这节课我们学习 Unet 场景分割,学习如何处理场景分割的案例
1. 场景分割的预处理后处理逻辑
2. 预处理采用 warpaffine 时,后处理可以使用逆变换得到 mask
这次我们从零开始,拉取官方代码并修改导出 onnx,代码位于:https://github.com/shouxieai/unet-pytorch
源代码其实来源于 bubbliiiing 的 https://github.com/bubbliiiing/unet-pytorch
如果对 bubbliiiing 的代码风格比较熟悉的话,导出 onnx 应该相对来说比较简单
先跑个 predict 的 demo 看看能否正常预测,在运行时存在如下问题:
from torchvision.models.utils import load_state_dict_from_url
ModuleNotFoundError: No module named 'torchvision.models.utils'
查询后发现高版本的 torch 中 load_state_dict_from_url 函数已经不再位于 torchvision.models.utils 而是位于 torch.hub,因此你需要修改 vgg.py 中的模块导入部分,如下所示:
# from torchvision.models.utils import load_state_dict_from_url
from torch.hub import load_state_dict_from_url
成功执行如下所示:

预测的效果图如下所示:

可以看到模型预测正常,起码这部分还是没问题的
模型预测成功后,我们就要开始导出 onnx 了,我们直接在 unet.py 中第 91 行添加导出代码,如下所示:
def generate(self):
self.net = unet(num_classes = self.num_classes, backbone=self.backbone)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.net.load_state_dict(torch.load(self.model_path, map_location=device))
self.net = self.net.eval()
print('{} model, and classes loaded.'.format(self.model_path))
# =========== export ===========
dummy = torch.zeros(1, 3, 512, 512)
torch.onnx.export(
self.net, (dummy,), "unet.onnx", input_names=["image"], output_names=["predict"],
opset_version=11, dynamic_axes={"image": {0:"batch"}, "predict":{0:"batch"}}
)
if self.cuda:
self.net = nn.DataParallel(self.net)
self.net = self.net.cuda()
导出的 onnx 如下图所示:

可以看到导出的 onnx 一片祥和,没有什么奇怪的地方,我们之所以指定 opset>= 11 是因为像 Unsample 这样的操作会直接变成 resize 节点,有助于我们后续部署
为了方便我们理解整个任务(预处理和后处理),我们其实自己应该写个预测脚本来整理一下整体思路,代码如下所示:
from unet import unet
import torch
import cv2
import numpy as np
class MyUNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = unet(num_classes=21, backbone="vgg")
state_dict = torch.load("../unet_voc.pth", map_location="cpu")
self.model.load_state_dict(state_dict)
def forward(self, x):
y = self.model(x)
y = y.permute(0, 2, 3, 1).softmax(dim=-1)
return y
device = "cpu"
# model = unet(num_classes=21, backbone="vgg")
# state_dict = torch.load("../unet_voc.pth", map_location="cpu")
# model.load_state_dict(state_dict)
# model.eval().to(device)
model = MyUNet().eval().to(device)
image = cv2.imread("img/street.jpg")
image = cv2.resize(image, (512, 512))
# To RGB
image = image[..., ::-1] # 是一种toRGB的方法
#preprocess
image = (image / 255.0).astype(np.float32)
# totensor
image = image.transpose(2, 0, 1)[None]
image = torch.from_numpy(image).to(device)
with torch.no_grad():
prob = model(image)
torch.onnx.export(
model, (image,), "unet.onnx",
input_names=["image"], output_names=["prob"],
opset_version=11, dynamic_axes={"image":{0:"batch"}, "prob": {0:"batch"}}
)
# softmax
# 概率合并
#prob = predict.permute(0, 2, 3, 1).softmax(dim=-1) # 1, 512, 512, 21
colors = [ (0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
label_map = prob.argmax(dim=-1)
seg_img = np.reshape(np.array(colors, np.uint8)[np.reshape(label_map, [-1])], [512, 512, -1])
print(seg_img.shape)
cv2.imwrite("seg_img.jpg", seg_img)
预处理部分其实和 yolov5 没有太大差别,一样是 resize,/255.0,totesor 等操作,值得注意的是模型预测的结果是 (1, 21, 512, 512),1 代表 batch 维度,21 代表 VOC 的 20 个类别再加上背景,(512, 512) 代表图像的宽高。
模型会对每一个像素点做一个预测,可以简单理解为对像素点进行分类,给它分配一个类别标签,所以我们才看到模型的预测结果是 (1, 21, 512, 512),还有一点值得注意,我们在对像素点进行 softmax 的时候其实是对 21 这个维度,但是我们不能直接进行 softmax,还需要进行一下 permute 操作,将 21 维度放在最后,因为其实我们是对整个图像的每个像素点做的 softmax
另外之前有提到后处理尽量放在 onnx 去做,因此我们自己构建了一个 unet 网络,把 permute 和 softmax 操作塞到 onnx 里面一块导出来了,减少 tensorRT 部分的复杂度
加上后处理后导出的 onnx 如下图所示:

2. Unet推理
onnx 导出完成后,接下来看看 C++ 推理时的代码
二话不说先执行 make run -j64 看下效果,运行后出现如下错误:
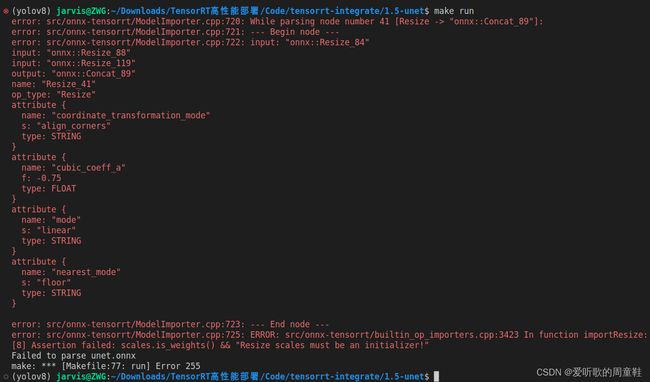
Resize 节点解析错误,老问题了,我们需要使用 onnxsim 来优化下,代码如下所示:
# pip install onnxsim
import onnx
from onnxsim import simplify
onnx_model = onnx.load("unet.onnx")
model_simp, check = simplify(onnx_model)
assert check, "Simplified ONNX model could not be Validated"
onnx.save(model_simp, "unet.sim.onnx")
修改后的模型可以正常被 tensorRT 解析了,运行效果如下:


可以看到和 pytorch 方式差不多,接下来我们简单解读下代码
首先是 build_model 没啥说的,和之前一样
inference 部分使用 warpAffine 完成预处理同时拿到逆矩阵,预处理部分和 yolov5 差不多,就 /255.0、bgr2rgb 就行了,接着把图片塞到模型里面推理拿到推理结果,通过 post_process 完成后处理,如下所示:
static tuple<cv::Mat, cv::Mat> post_process(float* output, int output_width, int output_height, int num_class, int ibatch){
cv::Mat output_prob(output_height, output_width, CV_32F);
cv::Mat output_index(output_height, output_width, CV_8U);
float* pnet = output + ibatch * output_width * output_height * num_class;
float* prob = output_prob.ptr<float>(0);
uint8_t* pidx = output_index.ptr<uint8_t>(0);
for(int k = 0; k < output_prob.cols * output_prob.rows; ++k, pnet+=num_class, ++prob, ++pidx){
int ic = std::max_element(pnet, pnet + num_class) - pnet;
*prob = pnet[ic];
*pidx = ic;
}
return make_tuple(output_prob, output_index);
}
上述代码用于对 Unet 分割网络输出的特征图进行后处理的函数。它接受 Unet 网络预测的数据指针以及输出图像的宽高、类别数和当前批次索引作为参数。函数的主要功能是将输出特征图转换为概率图和类别索引图,在后处理过程中,对于每个像素,找到具有最大概率值的类别,并将该概率值存储在概率图中,同时将类别索引存储在类别索引图中。
拿到概率和索引后将其打成一个 tuple 返回去,拿到的 prob 和 iclass 都是 512x512 的大小,然后通过逆变换矩阵 d2i 将它变换成原始输入图像的大小,最后通过 render 函数渲染一下,如下所示:
static void render(cv::Mat& image, const cv::Mat& prob, const cv::Mat& iclass){
auto pimage = image.ptr<cv::Vec3b>(0);
auto pprob = prob.ptr<float>(0);
auto pclass = iclass.ptr<uint8_t>(0);
for(int i = 0; i < image.cols*image.rows; ++i, ++pimage, ++pprob, ++pclass){
int iclass = *pclass;
float probability = *pprob;
auto& pixel = *pimage;
float foreground = min(0.6f + probability * 0.2f, 0.8f);
float background = 1 - foreground;
for(int c = 0; c < 3; ++c){
auto value = pixel[c] * background + foreground * _classes_colors[iclass * 3 + 2-c];
pixel[c] = min((int)value, 255);
}
}
}
渲染函数主要通过遍历图像的每个像素,依次获取当前像素的类别索引 iclass 和概率值 probability,根据概率值去计算前景值 foreground 和背景值 background,其中前景值用于调整像素的颜色,使其更加鲜艳。对于每个通道(B、G、R),通过插值计算新的颜色值 value,并将其存储在像素 pixel 中
我们主要是通过前景和背景的权重来进行渲染,可以看到渲染后的图像边缘并不是光滑的,这是因为标签 iclass 并没有去进行插值,它做插值是没有任何意义的
实际工作中使用知道拿到 prob 和 iclass 就可以了,反向变换有的时候需要有点时候不需要,而 render 大部分时候是不需要的
OK,那关于场景分割的讲解就到这里了
总结
本次课程学习了场景分割网络 Unet 的导出、编译到推理,分割网络和检测网络略有不同,模型的预测可以看作对每个像素点进行分类,拿到一个新的网络后,首先需要我们导出 onnx,检查导出的 onnx 是否存在问题,如果存在我们需要修改,同时遵循把复杂的后处理部分添加到 onnx 中,可以减少我们在 C++ 上的工作量。
其次你还需要先在 pytorch 中自己实现整个推理流程,包括预处理和后处理,这将帮助你理解整个模型推理的全部过程,同时也有利于我们在 C++ 上去实现