如何用好强大的 TDengine 集群 ? 先了解 RAFT 在 3.0 中的应用
大家都知道:由于单机数据库在数据规模、并发访问量等方面存在瓶颈,无法满足大规模应用的需求。因此才有了把数据切割分片,分布存储分布处理在多个节点上的数据库,也就是分布式数据库的由来。
而为了实现数据库的高可用,又有了多副本的概念,副本之间的数据需要用特定算法保持一致,从而可以随时切换身份对外提供高可用服务——TDengine 就是一款这样的分布式时序数据库(Time Series Database)。
选择什么样的一致性或者共识算法,可以直接代表一款数据库的产品思路。
一.Why RAFT
在 3.0 之前,结合时序数据的十大特点(《我为何要开发一个专用的物联网大数据平台,还开源它?》),我们针对性地创造了多项时序数据处理专利,使得 TDengine 对大时序数据的处理能力与当时世界上的同类型产品拉开了巨大的性能优势。而在 3.0 ,我们则引入了标准的 RAFT 算法,以更通用标准的实现方式,去适用更广泛的应用场景。
通过 RAFT 算法所保障数据一致的多个节点,被称为一个 RAFT 组(group);这些节点,被称为这个RAFT组的成员(member)节点。
在 RAFT 组中,每个节点都维护了一份连续的日志(Log),用于记录数据写入、变更、或删除等操作的所有指令。日志是由一系列有序的日志条目 (Log Entry) 组成,每个 Log Entry 都有唯一的编号(Index),用于标识日志协商或执行的进度。
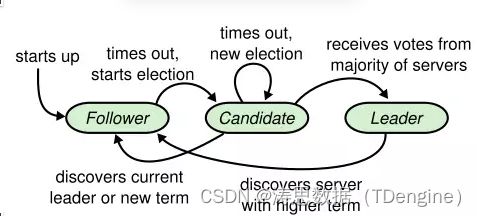
此外,每个 RAFT 节点都有自己的角色,它们可以是 Follower(跟随者)、Candidate(候选人)、Leader(领导者)。
二. Raft in TDengine
对于 TDengine 来说,一个虚拟节点组(vgroup)就构成了一个 RAFT 组;而这个虚拟节点组的虚拟数据节点(vnode),便是该 RAFT 组的成员节点,我们也称之为副本(全部管理节点(mnode)也构成一个 RAFT 组)。Leader 角色的 vnode/mnode 按照协议机制负责提供读写服务,在容忍故障节点不超过半数的情况下保证集群的高可用性;此外,即使发生了节点重启及 Leader 节点重新选举等事件后,RAFT 也能够始终保证新产生的 Leader 节点可以提供已经写入成功的全部完整数据的读写服务。
对于 TDengine 来说,每一次对数据库的变更请求( 比如 insert into test.d1 values(now,1,2,3) ),都对应一个 RAFT 日志记录(Log Entry)。在持续写入数据的过程中,TDengine 会按照协议机制在每个成员节点上产生完全相同的日志记录,并且以相同的顺序执行数据变更操作,以 WAL 的形式,存储在数据文件目录中。
而每一个 Log Entry 携带的 Index ,就代表此前讲过的数据或数据变更的版本号(从 TDengine 存储引擎的变化探讨——为何大家应尽快切换 3.0 版本?)。

当一个数据写入请求发出后,必定至少过半数节点上完成写入才会把“写入成功”返回给客户端。这部分涉及 Log entry 的两种重要的状态,committed 和 applied。
对应到 TDengine 中,只有当过半数的节点把该条 SQL 的写入信息追加到文件系统上的 WAL(即图中的步骤 2),并且收到确认消息之后,这条 Log entry 才会被 Leader 认为是安全的。此时该日志进入 committed 状态,并通知 Follower 节点,完成数据的插入(即图中的步骤 4),随后该 Log Entry 便被标记为 applied 的状态。
applied——表示数据变更已经被应用,即该 SQL 执行完毕。
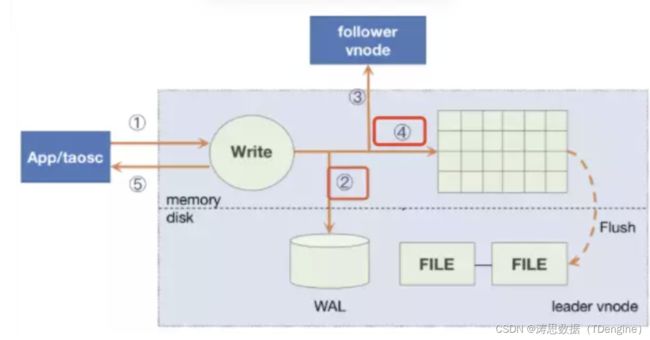
数据的整体写入流程可以参考官方文档 整体架构 | TDengine 文档 | 涛思数据。如果需要更多了解 RAFT 细节可以参考论文《 In Search of an Understandable Consensus Algorithm 》
三. 注意事项
对于用户而言,数据的同步方式其实是无需感知的,大家只需要关心最终结果即可。但是关于选主流程大家有必要了解一些,因为它涉及到服务的压力负载是否均衡,以及到遇到突发情况后解决问题的思路。
在 RAFT 的标准实现下,每个节点都拥有随机的选举超时时间(election timeout),当任意一个 Follower 超过这个时间没有收到 Leader 发来的心跳后,便会变成 Candidate 并发起申请成为 Leader 的选举请求。
可见,每一个 Vgroup 的选举结果都完全随机的,所以这样会低概率出现很多 Leader Vnode 集中在某一个节点的场景,比如在集群启动时、滚动升级时(企业版)。由于 RAFT 的读写全部只能由 Leader 节点来提供(2.0 版本 TDengine 的 Follower 也可提供查询服务),因此这会导致单个节点的工作压力较大。
为了优化这种特殊情况,企业版 TDengine 提供了一种简便易用的命令,能够使集群的负载再次实现均衡。
balance vgroup Leader;
开源版则可以通过重启服务重新选主刷新选举结果。(相比 2.0 版本,优化后的 3.0 即便是体量很大的集群也可以迅速启停)
此外,由于 RAFT 的选举流程规定只需得到半数以上节点的投票就可以选出 Leader,所以在 3.0 版本,原则上讲,只需要半数以上节点正常便可以提供服务。(2.0 需要节点全部启动才可从无到有选出 Leader ,后续才会按照半数以上的多数派原则提供高可用服务)

四.常见问题:
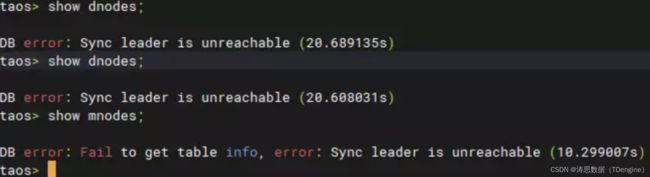
问题 1 :“Sync leader is unreachable”(3.0.3.1 版本之前,该错误码为 sync not Leader )
该报错的具体逻辑是:由于 RAFT 要求只有 Leader 才可以提供读写服务,一个请求发现自己访问的 vnode/mnode 不是 Leader 后,会把请求重定向到新的 vnode/mnode 上 。 如果最终还是没有找到Leader 才会返回客户端错误: “Sync leader is unreachable ”,所以本质上这个报错是由于 Leader 不存在导致的。
问题现象及处理思路:
- 数据库/mnode 在没有设置 3 副本的情况下出现故障:这时需要打开debugFlag 143 , 生成高级别日志,通过日志信息判断问题所在,或者检查硬件。
- 多副本情况无法选出 Leader :同样需要打开debugFlag 143 , 生成高级别日志,通过日志信息判断问题所在,或者检查硬件。
- 数据库主程序出现bug导致程序无法启动,因此无法选出 Leader :这种情况需要通过微信群或 github 联系官方团队协助处理。
除此之外,但凡在日志中发现 “not leader ” 相关字样的报错信息,都可以按照上述思路排查。
常见问题 2 : Sync leader is restoring。
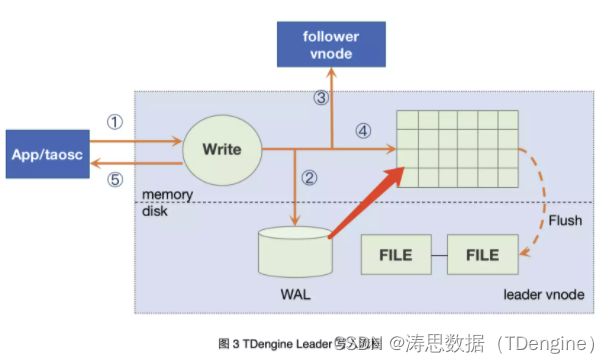
该报错的具体逻辑是:假如数据库节点出现了断电,或其他原因导致数据库进程异常中止。这样内存中的数便会被清空,数据库需要把已经写入磁盘的 WAL 数据再次执行,使内存恢复到异常发生之前的状态。(上图红色箭头部分)
这个时候,该 vnode 便处于 restoring 的状态,需要完全恢复后才可以正常提供服务,在恢复完成之前如果访问了这个 vnode 数据就会报错 “Sync leader is restoring”。
通常我们不认为这是一个异常情况,而是数据库的正常恢复行为,此时我们可以观察日志中该条输出的 “items”,直到归 0 即可恢复正常使用,如果恢复较慢,或中途出现其它问题,通过微信群或 github 联系我们官方即可。

五.结语
RAFT 的引入是 3.0 大规模重构中最大的亮点之一,在保住了 TDengine 的性能优势的前提下,使得 TDengine 能以更标准的方式处理数据的一致性问题。
在存储引擎,一致性协议,查询引擎全部做了大规模重构之后,TDengine 3.0 将会在更广泛的时序数据处理场景中发挥作用,欢迎大家加入我们一起探索可能。