TDengine 3.0 性能如何?教你一键复现 IoT 场景 TSBS 测试结果
不久前,基于 TSBS,我们发布了 TDengine 3.0 测试报告系列第一期——《DevOps 场景下 TDengine 3.0 对比测试报告》,报告验证了 TDengine 基于时序数据场景所设计的独特架构,在 DevOps 场景下带来的性能优势以及成本控制水平。本期我们继续探寻在 IoT 场景下,TDengine 对比 TimescaleDB、InfluxDB 在写入和查询上的性能表现——《IoT 场景下 TDengine 3.0 性能对比分析报告来啦!》,给有时序数据库(Time Series Database)选型需求的开发者做参考。
本期报告显示,在全部的五个场景中,TDengine 写入性能均优于 TimescaleDB 和 InfluxDB。写入性能最大达到 TimescaleDB 的 3.3 倍,InfluxDB 的 16.2 倍;此外,TDengine 在写入过程中消耗了最少计算(CPU)资源和磁盘 IO 开销。在查询方面,对于大多数查询类型,TDengine 的性能均优于 InfluxDB 和 TimescaleDB,在复杂的混合查询中 TDengine 展现出巨大的优势——其中 avg-load 和 breakdown-frequency 的查询性能是 InfluxDB 的 426 倍 和 53 倍;daily-activity 和 avg-load 的查询性能是 TimescaleDB 的 34 倍和 23 倍。
为了便于大家对报告结果进行验证,本篇文章将会对测试数据及环境搭建等环节进行一一阐述,方便有需要的开发者取用复制。此外,本测试报告中的数据在准备好物理环境后,可以由脚本一键执行生成,测试步骤在本文中也有涉及。
一、测试背景
1、测试场景介绍
在本期测试报告中,我们使用了 TSBS 的 IoT 场景作为基础数据集,在TSBS 框架下模拟虚拟货运公司车队中一组卡车的时序数据,针对每个卡车的诊断数据(diagnostics)记录包含 3 个测量值和 1 个(纳秒分辨率)时间戳、8 个标签值;卡车的指标信息(readings)记录包含 7 个测量值和 1 个(纳秒分辨率)时间戳,8 个标签值。数据模式(schema)见下图,每 10 秒对生成的数据进行一条记录。由于 IoT 场景引入了环境因素,所以每个卡车存在无序和缺失的时间序列数据。
 样例数据
样例数据
在整个基准性能评估中,涉及以下五个场景,每个场景的具体数据规模和特点见下表,由于存在数据缺失,所以单个卡车数据记录取记录均值:
| 场景一 |
场景二 |
场景三 |
场景四 |
场景五 |
|
| 数据间隔 |
10 秒 |
10 秒 |
10 秒 |
10 秒 |
10 秒 |
| 持续时间 |
31 天 |
4 天 |
3 小时 |
3 分钟 |
3 分钟 |
| 卡车数目 |
100 |
4000 |
100,000 |
1,000,000 |
10,000,000 |
| 单个卡车记录数 |
241,145 |
31,118 |
972 |
16 |
16 |
| 数据集记录数 |
48,229,186 |
248,944,316 |
194,487,997 |
32,414,619 |
324,145,090 |
从上表可以看到,五个场景的区别主要在于数据集所包含的单个卡车记录数量以及卡车总数的差异,数据时间间隔均维持在 10 秒。整体上看,五个场景的数据规模都不大,数据规模最大的是场景五,数据规模最小的是场景四。在场景四和场景五中,由于卡车数量相对较多,所以数据集仅覆盖了 3 分钟的时间跨度。
2、数据建模
在 TSBS 框架中, TimescaleDB 和 InfluxDB 会自动创建相应的数据模型并生成对应格式的数据。本文不再赘述其具体的数据建模方式,只介绍 TDengine 的数据建模策略。 TDengine 一个重要的创新是其独特的数据模型——为每个设备创建独立的数据表(子表),并通过超级表(Super Table)在逻辑上和语义上对同一采集类型的设备进行统一管理。针对 IoT 场景的数据内容,我们为每个卡车创建了两张表(后文中设备和卡车同义),用来存储诊断信息和指标信息的时序数据。在上述数据记录中,truck name 可以作为每个卡车的标识 ID,因为有两张超级表,因此在 TDengine 中使用 truck name 拼接 d(r)作为子表的名称。我们使用如下的语句创建名为 diagnostics 和 readings 的超级表,分别包含 3 、7 个测量值和 8 个标签。

然后 ,我们使用如下语句创建名为 r_truck_1和 d_truck_1 的子表:

由此可知,对于 100 个设备(CPU)的场景一,我们将会建立 100 个子表;对于 4000 个设备的场景二,系统中将会建立 4000 个子表用以存储各自对应的数据。在 TSBS 框架生成的数据中,我们发现存在标签信息 truck 为 null 的数据内容,为此建立了 d_truck_null(r_truck_null) 的表,用以存储所有未能标识 truck 的数据。
3、软件版本和配置
本报告比较 TDengine、InfluxDB 与 TimeScaleDB 三种类型的数据库,下面对使用的版本和配置做出说明。
01 TDengine
我们直接采用 TDengine 3.0,从 GitHub 克隆 TDengine 代码编译版本作为性能对比的版本。 gitinfo: 1bea5a53c27e18d19688f4d38596413272484900 在服务器上编译安装运行:

在 TDengine 的配置文件中设置了六个涉及查询的配置参数:
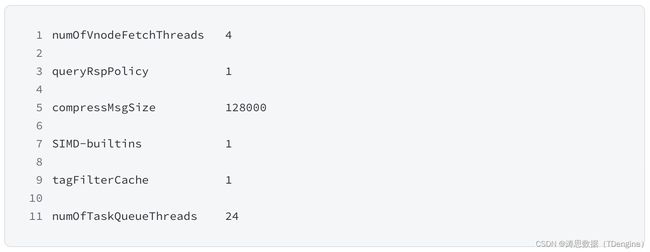
第一个参数 numOfVnodeFetchThreads 作用是设置 Vnode(virtual node) 的 Fetch 线程数量为 4 个;第二个参数 queryRspPolicy 用于打开 query response 快速返回机制;第三个参数 compressMsgSize 让 TDengine 在传输层上大于 128000 bytes 的消息自动进行压缩;第四个参数的作用是在 CPU 支持的情况下启用内置的 FMA/AVX/AVX2 硬件加速;第五个参数用于开启 tag 列的过滤缓存;第六个参数用于设置任务队列的线程数量为 24。
由于 IoT 场景下表数目是卡车规模数的二倍,所以 TDengine 建库默认创建 12 个 vnodes,即创建的表会按照表名随机分配到 12 个虚拟节点中,将 LRU 缓存设置为 last_row 缓存模式。对于场景一和场景二,stt_trigger 设置为 1,此时 TDengine 会准备一个 Sorted Time-series Table (STT) 文件,用于容纳单表写入量小于 minimum rows 时的数据,当 STT 文件中无法容纳新数据时,系统会将 STT 中的数据进行整理,再写入到数据文件中。在本次报告中,场景三配置 stt_trigger 为 8,场景四和场景五 stt_trigger 设置为 16 ,即允许最多生成 16 个 STT 文件。针对低频表多的场景,需要适度增加 STT 的值,以此来获得更好的写入性能。
02 TimescaleDB
为确保结果具有可比性,我们选用 TimescaleDB version 2.10.1。为获得较好的性能,TimescaleDB 需要针对不同的场景设置不同的 Chunk 参数,不同场景下参数的设置如下表所示。
| 场景一 |
场景二 |
场景三 |
场景四 |
场景五 |
|
| 设备数目 |
100 |
4000 |
100,000 |
1,000,000 |
10,000,000 |
| Chunk 数目 |
12 |
12 |
12 |
12 |
12 |
| Chunk 持续时间 |
2.58 天 |
8 小时 |
15 分 |
15 秒 |
15 秒 |
| Chunk 内记录数 |
2,009,550 |
10,372,680 |
8,103,667 |
1,350,610 |
13,506,045 |
关于上述参数的设置,我们充分参考了[TimescaleDB vs. InfluxDB]对比报告中推荐的配置参数设置,以确保能够最大化写入性能指标。 TimescaleDB vs. InfluxDB: Purpose Built Differently for Time-Series Data:https://www.timescale.com/blog/timescaledb-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/
03 InfluxDB
针对 InfluxDB,本报告选用的是 version 1.8.10。这里没有使用 InfluxDB 最新的 2.x 版本是因为 TSBS 没有对其进行适配,所选用的 1.8.10 版本是 InfluxDB 能够运行 TSBS 框架的最新版本。在配置上,仍然采用[TimescaleDB vs. InfluxDB]对比报告中推荐的方式对其进行配置,将缓冲区配置为 80GB,以便 1000W 设备写入时能够顺利进行,同时开启 Time Series Index(TSI)。 配置系统在系统插入数据完成 30s 后开始进行数据压缩:

二、测试步骤
1、硬件准备
为与[TimescaleDB vs. InfluxDB]对比报告的环境高度接近,我们使用亚马逊 AWS 的 EC2 提供的 r4.8xlarge 类型实例作为基础运行平台,包括 1 台服务器、1 台客户端共两个节点构成的环境。客户端与服务器硬件配置完全相同,客户端与服务器使用 10 Gbps 网络连接。配置简表如下:
| CPU |
Memory |
Disk |
|
| 服务器 |
Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz 32vCPU |
244GiB |
800G SSD,3000 IOPS. 吞吐量上限是 125 MiB/Sec |
| 客户端 |
Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz 32vCPU |
244GiB |
800G SSD,3000 IOPS. 吞吐量上限是 125 MiB/Sec |
2、服务器环境准备
为运行测试脚本,服务器 OS 需要是 ubuntu20.04 以上的系统。AWS EC2 的服务器系统信息如下:
- OS:Linux tv5931 5.15.0-1028-aws #32~20.04.1-Ubuntu SMP Mon Jan 9 18:02:08 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
- Gcc:gcc version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04)
- 基础环境,版本信息为:Go1.16.9 , python3.8 , pip20.0.2 (无需手动安装,测试脚本将自动安装)
- 编译依赖:gcc , cmake, build-essential, git, libssl-dev (无需手动安装,测试脚本将自动安装)
此外,还要做下面两个配置:
- client 和 server 配置 ssh 访问免密,以便脚本可不暴露密码,可参考免密配置文档:https://blog.csdn.net/qq_38154295/article/details/121582534。
- 保证 client 和 server 之间所有端口开放。
3、获取测试脚本
为便于重复测试,隐藏繁琐的下载、安装、配置、启动、汇总结果等细节,整个 TSBS 的测试过程被封装成一个测试脚本。重复本测试报告,需要先下载该测试脚本,脚本暂支持 ubuntu20.04 的系统。以下操作要求具有 root 权限。 在客户端机器,进入测试目录拉取代码,默认进入 /usr/local/src/ 目录:

需要修改配置文件 test.ini 中服务端和客户端的 IP 地址(这里配置 AWS 的私网地址即可)和 hostname,如果服务器未配置免密,还需要配置服务器端的 root 密码。由于本次测试在 IoT 场景下,故修改 caseType 为 iot。
4、一键执行对比测试
执行以下命令:

测试脚本将自动安装 TDengine、InfluxDB、TimescaleDB 等软件,并自动运行各种对比测试项。在目前的硬件配置下,整个测试跑完需要大约三天的时间。测试结束后,将自动生成 CSV 格式的对比测试报告,并存放在客户端的 /data2 目录,对应 load 和 query 前缀的文件夹下。
三、结语
阅读完毕,你一定更加深入地了解了 TDengine 的数据建模、三大数据库测试版本和配置,以及如何运用测试脚本进行一键复现。如果有小伙伴想要验证三大数据库在 IoT 场景下的测试结果,欢迎按照上述步骤进行操作,检验测试结果,有任何问题都欢迎大家和我们及时沟通。现在你也可以添加小T vx:tdengine1,申请加入 TDengine 用户交流群,和更多志同道合的开发者一起聊技术、聊实战。