显示类型转换 const_cast, static_cast, dynamic_cast, teinterpret_cast的使用
文章目录
- const_cast :: 对const和volatile限定符进行擦除
- static_cast ::常用隐式转型的显示使用
- dynamic_cast ::检查安全向下转型(继承关系)
- reinterpret_cast::跨越无关类型的转换
-
-
-
- reinterpret_cast有何作用
- 当reinterpret_cast面对const
-
-
const_cast :: 对const和volatile限定符进行擦除
- 主要作用
将const和volatile的限定作用擦除(没有真的去除这个变量的限定类型,而实使用另一个变量去承接一个没有这个限定类型的变量)。
举例:
#include "head.h"
using namespace std;
int main(){
const int a = 4;
// int &b1 = a;
//报错:
//binding reference of type ‘int&’ to ‘const int’ discards qualifiers
// int *p1 = &a;
//报错;
//invalid conversion from ‘const int*’ to ‘int*’ [-fpermissive]
int &b = const_cast<int&>(a);
int *p = const_cast<int*>(&a);
b = 3;
return 0;
}
通过const_cast运算符,也只能将const type转换为type,将const type&转换为type&。
也就是说源类型和目标类型除了const属性不同,其他地方完全相同。
static_cast ::常用隐式转型的显示使用
- 编译器隐式执行的任何类型转换都可以由static_cast来完成,比如int与float、double与char、enum与int之间的转换等。
double a = 1.999;
int b = static_cast<double>(a); //相当于a = b ;
当编译器隐式执行类型转换时,大多数的编译器都会给出一个警告:
e:\vs 2010 projects\static_cast\static_cast\static_cast.cpp(11):
warning C4244: “初始化”: 从“double”转换到“int”,可能丢失数据
使用static_cast可以明确告诉编译器,这种损失精度的转换是在知情的情况下进行的,也可以让阅读程序的其他程序员明确你转换的目的而不是由于疏忽。
把精度大的类型转换为精度小的类型,static_cast使用位截断进行处理。
- 使用static_cast可以找回存放在void指针中的值*。
double a = 1.999;
void * vptr = & a;
double * dptr = static_cast<double*>(vptr);
cout<<*dptr<<endl;//输出1.999
- static_cast也可以用在于基类与派生类指针或引用类型之间的转换。
然而它不做运行时的检查,不如dynamic_cast安全。static_cast仅仅是依靠类型转换语句中提供的信息来进行转换,而dynamic_cast则会遍历整个类继承体系进行类型检查,因此dynamic_cast在执行效率上比static_cast要差一些。现在我们有父类与其派生类如下:
class ANIMAL
{
public:
ANIMAL():_type("ANIMAL"){};
virtual void OutPutname(){cout<<"ANIMAL";};
private:
string _type ;
};
class DOG:public ANIMAL
{
public:
DOG():_name("大黄"),_type("DOG"){};
void OutPutname(){cout<<_name;};
void OutPuttype(){cout<<_type;};
private:
string _name ;
string _type ;
};
此时我们进行派生类与基类类型指针的转换:注意从下向上的转换是安全的,从上向下的转换不一定安全。
int main()
{
//基类指针转为派生类指针,且该基类指针指向基类对象。
ANIMAL * ani1 = new ANIMAL ;
DOG * dog1 = static_cast<DOG*>(ani1);
//dog1->OutPuttype();//错误,在ANIMAL类型指针不能调用方法OutPutType();在运行时出现错误。
//基类指针转为派生类指针,且该基类指针指向派生类对象
ANIMAL * ani3 = new DOG;
DOG* dog3 = static_cast<DOG*>(ani3);
dog3->OutPutname(); //正确
//子类指针转为派生类指针
DOG *dog2= new DOG;
ANIMAL *ani2 = static_cast<DOG*>(dog2);
ani2->OutPutname(); //正确,结果输出为大黄
//
system("pause");
}
- static_cast可以把任何类型的表达式转换成void类型。
另外,与const_cast相比,static_cast不能转换掉变量的const属性,也包括volitale或者__unaligned属性。
dynamic_cast ::检查安全向下转型(继承关系)
dynamic_cast是四个强制类型转换操作符中最特殊的一个,它支持运行时识别指针或引用。
首先,dynamic_cast依赖于RTTI信息,其次,在转换时,dynamic_cast会检查转换的source对象是否真的可以转换成target类型,
这种检查不是语法上的,而是真实情况的检查。
dynamic_cast主要用于“安全地向下转型”
dynamic_cast用于类继承层次间的指针或引用转换。主要还是用于执行“安全的向下转型(safe downcasting)”,
也即是基类对象的指针或引用转换为同一继承层次的其他指针或引用。
至于“先上转型”(即派生类指针或引用类型转换为其基类类型),本身就是安全的,尽管可以使用dynamic_cast进行转换,但这是没必要的, 普通的转换已经可以达到目的,毕竟使用dynamic_cast是需要开销的。
总结就是一句话:
向上转型不需要dynamic_cast的检查,他一定是安全的;
向下转型的话,
如果一个指向子类的基类指针转向该子类,是安全的;
如果一个指向基类的基类指针转向某一子类,一定是不安全的,
如果一个指向子类的基类指针转向其他子类,是不安全的;
1 class Base
2 {
3 public:
4 Base(){};
5 virtual void Show(){cout<<"This is Base calss";}
6 };
7 class Derived:public Base
8 {
9 public:
10 Derived(){};
11 void Show(){cout<<"This is Derived class";}
12 };
13 int main()
14 {
15 Base *base ;
16 Derived *der = new Derived;
17 //base = dynamic_cast(der); //正确,但不必要。
18 base = der; //先上转换总是安全的
19 base->Show();
20 system("pause");
21 }
- dynamic_cast与继承层次的指针
对于“向下转型”有两种情况。
-
一种是基类指针所指对象是派生类类型的,这种转换是安全的;
-
另一种是基类指针所指对象为基类类型,在这种情况下dynamic_cast在运行时做检查,转换失败,返回结果为0;
#include "stdafx.h"
#include运行结果:
- dynamic_cast和引用类型
在前面的例子中,使用了dynamic_cast将基类指针转换为派生类指针,也可以使用dynamic_cast将基类引用转换为派生类引用。
同样的,引用的向上转换总是安全的:
Derived c;
Derived & der2= c;
Base & base2= dynamic_cast<Base&>(der2);//向上转换,安全
base2.Show();
所以,在引用上,dynamic_cast依旧是常用于“安全的向下转型”。与指针一样,引用的向下转型也可以分为两种情况,与指针不同的是,并不存在空引用,所以引用的dynamic_cast检测失败时会抛出一个bad_cast异常:
int main()
{
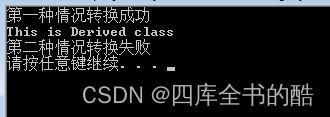
//第一种情况,转换成功
Derived b ;
Base &base1= b;
Derived &der1 = dynamic_cast<Derived&>(base1);
cout<<"第一种情况:";
der1.Show();
cout<<endl;
//第二种情况
Base a ;
Base &base = a ;
cout<<"第二种情况:";
try{
Derived & der = dynamic_cast<Derived&>(base);
}
catch(bad_cast)
{
cout<<"转化失败,抛出bad_cast异常"<<endl;
}
system("pause");
}
运行结果:

- 使用dynamic_cast转换的Base类至少带有一个虚函数
当一个类中拥有至少一个虚函数的时候,编译器会为该类构建出一个虚函数表(virtual method table),虚函数表记录了虚函数的地址。如果该类派生了其他子类,且子类定义并实现了基类的虚函数,那么虚函数表会将该函数指向新的地址。虚表是C++多态实现的一个重要手段,也是dynamic_cast操作符转换能够进行的前提条件。当类没有虚函数表的时候(也即一个虚函数都没有定义),dynamic_cast无法使用RTTI,不能通过编译(个人猜想…有待验证)。
reinterpret_cast::跨越无关类型的转换
reinterpret_cast运算符是用来处理无关类型之间的转换;它会产生一个新的值,这个值会有与原始参数(expressoin)有完全相同的比特位。
什么是无关类型?我没有弄清楚,没有找到好的文档来说明类型之间到底都有些什么关系(除了类的继承以外)。后半句倒是看出了reinterpret_cast的字面意思:重新解释(类型的比特位)。我们真的可以随意将一个类型值的比特位交给另一个类型作为它的值吗?其实不然。
IBM的C++指南里倒是明确告诉了我们reinterpret_cast可以,或者说应该在什么地方用来作为转换运算符:
从指针类型到一个足够大的整数类型
从整数类型或者枚举类型到指针类型
从一个指向函数的指针到另一个不同类型的指向函数的指针
从一个指向对象的指针到另一个不同类型的指向对象的指针
从一个指向类函数成员的指针到另一个指向不同类型的函数成员的指针
从一个指向类数据成员的指针到另一个指向不同类型的数据成员的指针
不过我在Xcode中测试了一下,事实上reinterpret_cast的使用并不局限在上边所说的几项的,任何类型的指针之间都可以互相转换,都不会得到编译错误。上述列出的几项,可能 是Linux下reinterpret_cast使用的限制,也可能是IBM推荐我们使用reinterpret_cast的方式
所以总结来说:reinterpret_cast用在任意指针(或引用)类型之间的转换;以及指针与足够大的整数类型之间的转换;从整数类型(包括枚举类型)到指针类型,无视大小。
(所谓"足够大的整数类型",取决于操作系统的参数,如果是32位的操作系统,就需要整形(int)以上的;如果是64位的操作系统,则至少需要长整形(long)。具体大小可以通过sizeof运算符来查看)。
reinterpret_cast有何作用
从上边对reinterpret_cast介绍,可以感觉出reinterpret_cast是个很强大的运算符,因为它可以无视种族隔离,随便搞。但就像生物的准则,不符合自然规律的随意杂交只会得到不能长久生存的物种。随意在不同类型之间使用reinterpret_cast,也之后造成程序的破坏和不能使用。
比如下边的代码
typedef int (*FunctionPointer)(int);
int value = 21;
FunctionPointer funcP;
funcP = reinterpret_cast<FunctionPointer> (&value);
funcP(value);
我先用typedef定义了一个指向函数的指针类型,所指向的函数接受一个int类型作为参数。然后我用reinterpret_cast将一个整型的地址转换成该函数类型并赋值给了相应的变量。最后,我还用该整形变量作为参数交给了指向函数的指针变量。
这个过程编译器都成功的编译通过,不过一旦运行我们就会得到"EXC_BAD_ACCESS"的运行错误,因为我们通过funcP所指的地址找到的并不是函数入口。
由此可知,reinterpret_cast虽然看似强大,作用却没有那么广。IBM的C++指南、C++之父Bjarne Stroustrup的FAQ网页和MSDN的Visual C++也都指出:
错误的使用reinterpret_cast很容易导致程序的不安全,只有将转换后的类型值转换回到其原始类型,这样才是正确使用reinterpret_cast方式。
这样说起来,reinterpret_cast转换成其它类型的目的只是临时的隐藏自己的什么(做个卧底?),要真想使用那个值,还是需要让其露出真面目才行。那到底它在C++中有其何存在的价值呢?
MSDN的Visual C++ Developer Center 给出了它的使用价值:用来辅助哈希函数。下边是MSNDN上的例子:
// expre_reinterpret_cast_Operator.cpp
// compile with: /EHsc
#include 这段代码适合体现哈希的思想,暂时不做深究,但至少看Hash函数里面的操作,也能体会到,对整数的操作显然要对地址操作更方便。在集合中存放整形数值,也要比存放地址更具有扩展性(当然如果存void *扩展性也是一样很高的),唯一损失的可能就是存取的时候整形和地址的转换(这完全可以忽略不计)。
不过可读性可能就不高,所以在这种情况下使用的时候,就可以用typedef来定义个指针类型:
typedef unsigned int PointerType;
这样不是更棒,当我们在64位机器上运行的时候,只要改成:
typedef unsigned long PointerType;
当reinterpret_cast面对const
IBM的C++指南指出:reinterpret_cast不能像const_cast那样去除const修饰符。 这是什么意思呢?代码还是最直观的表述:
int main()
{
typedef void (*FunctionPointer)(int);
int value = 21;
const int* pointer = &value;
//int * pointer_r = reinterpret_cast (pointer);
// Error: reinterpret_cast from type 'const int*' to type 'int*' casts away constness
FunctionPointer funcP = reinterpret_cast<FunctionPointer> (pointer);
}
例子里,我们像前面const_cast一篇举到的例子那样,希望将指向const的指针用运算符转换成非指向const的指针。但是当实用reinterpret_cast的时候,编译器直接报错组织了该过程。这就体现出了const_cast的独特之处。
但是,例子中还有一个转换是将指向const int的指针付给指向函数的指针,编译顺利通过编译,当然结果也会跟前面的例子一样是无意义的。
如果我们换一种角度来看,这似乎也是合理的。因为
const int* p = &value;
int * const q = &value;
这两个语句的含义是不同的,前者是"所指内容不可变",后者则是"指向的地址不可变"(具体参考此处)。因此指向函数的指针默认应该就带有"所指内容不可变"的特性。
毕竟函数在编译之后,其操作过程就固定在那里了,我们唯一能做的就是传递一些参数给指针,而无法改变已编译函数的过程。所以从这个角度来想,上边例子使用reinterpret_cast从const int * 到FunctionPointer转换就变得合理了,因为它并没有去除const限定