IOS看书最终选择|源阅读转换|开源阅读|IOS自签
环境:IOS想使用 换源阅读
问题:换新手机,源阅读下架后,没有好的APP阅读小说
解决办法:自签APP + 转换源仓库书源
最终预览 :https://rc.real9.cn/
背景:自从我换了新iPhone手机,就无法使换源阅读了,于是我自用上,结果发现现在的书源发展的很快,旧版本的源阅读APP部分书源的语法不支持,于是我反复总结对比,写了一个自动转换的python程序,如上链接
解决过程:自签APP+转换书源
文章目录
-
- 1.下载 ipa:
- 2.自签IPA:
- 3.转换书源
-
- 3.1 获得书源
- 3.2 转换规则
- 3.3 转换书源
- 4.在线转换
-
- 4.1 web版源代码:
- 4.2 我还写了个docker版本的
1.下载 ipa:
下载地址我就不放了
2.自签IPA:
关于怎么自签,你们可以用轻松签、全能签,小白啥也不会就算了
3.转换书源
3.1 获得书源
源仓库也不提供了,自己搜:
https://yuedu.miaogongzi.net/
3.2 转换规则
由于这款APP版本是2021年左右的,很多新版书源不支持,我们要进行转换,我自己花了点时间总结了一点转换规则:
最常见的规则是不支持a.1@text 这种,要转换,其他参考下列
书源类型
0 文本
2 视频
3 漫画
1 音频
-------------------------------
# 选择ID
. 选择元素 class之类
> 子元素
~ 第二个,兄弟元素,同级关系
p:nth-child(2) 父元素的第n个子元素
[] 属性选择器 [class^=book] 选择class以book开头的元素
! 倒序选择器 img:!-1 选择最后一个img元素
|| 列组合选择器 col||td 选择col和td元素
( ) 分组选择器 (div,p) 选择所有div和p
, 多个选择器 .item, .active 选择item和active类
* 通用元素选择器 *.item 选择所有类名包含item的元素
n 表达式选择器 li:nth-child(3n) 按序选择li元素,每个li元素的父元素中的第 3、6、9、12等序号
a.-1@text 改为a:nth-last-child(1)@text
a.1@text a:nth-child(1)@text```
### 3.3 步骤3.3
3.3 转换书源
现在开始转换,笨的办法是用记事本替换,我写了个python脚本来自动替换
import json
import requests
def replace_selectors(json_data):
# 替换选择器的函数
def replace_selector(selector):
if "." in selector and "@" in selector:
parts = selector.split('.')
tag = parts[0]
selector_part = parts[1]
if "@" in selector_part:
num, at_text = selector_part.split('@', 1)
if ":" in num:
num, tag_after_colon = num.split(':', 1)
num = f"{num}@{tag_after_colon}"
if num.replace("-", "").replace(".", "").isdigit():
num = "1" if num == "0" else num # 处理小数点后面是0的情况
if num.startswith("-"):
num = num[1:]
return f"{tag}:nth-last-child({num})@{at_text}"
else:
return f"{tag}:nth-child({num})@{at_text}"
return selector
# 处理列表类型的 JSON 数据
if isinstance(json_data, list):
for item in json_data:
replace_selectors(item)
return
# 遍历字典类型的 JSON 数据,查找并替换选择器
for key, value in json_data.items():
if isinstance(value, str):
if "@" in value:
value = replace_selector(value)
json_data[key] = value
elif isinstance(value, dict):
replace_selectors(value)
elif isinstance(value, list):
for item in value:
if isinstance(item, dict):
replace_selectors(item)
# 增加替换规则,当"ruleExplore": []时,替换为"ruleExplore": "##"
if "ruleExplore" in json_data and not json_data["ruleExplore"]:
json_data["ruleExplore"] = "##"
if __name__ == "__main__":
# 用户输入 JSON 文件的 URL
json_url = input("请输入 JSON 文件的 URL: ")
# 下载 JSON 数据
response = requests.get(json_url)
json_data = response.json()
# 替换选择器
replace_selectors(json_data)
# 提取文件名,并保存 JSON 内容到文件
file_name = json_url.split('/')[-1]
with open(file_name, 'w', encoding='utf-8') as file:
json.dump(json_data, file, indent=4, ensure_ascii=False)
print(f"JSON 内容已按照新的替换原则进行替换并保存为文件:{file_name}")
4.在线转换
本地转换有点麻烦,我玩手机的时候电脑又不会一直在身边,我就把上面的代码改成了web版本,这些复制转换后的连接,到APP剪贴板导入就好了,效果如下:
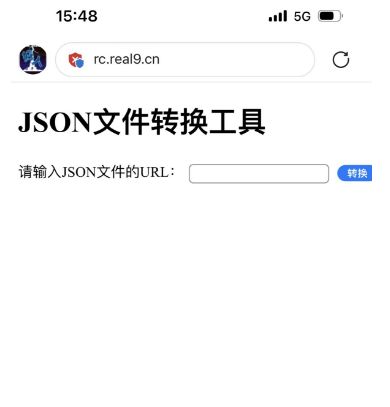
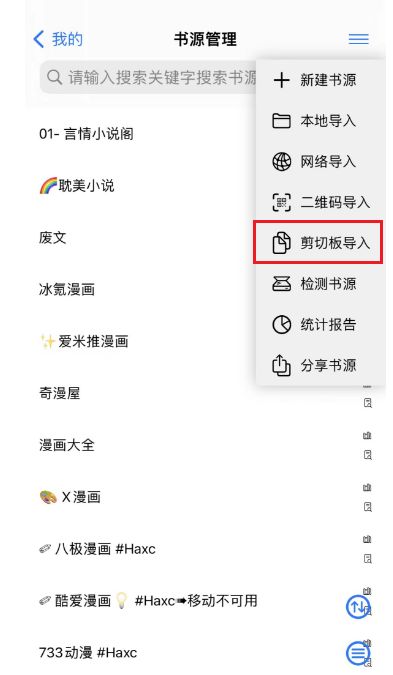

4.1 web版源代码:
import json
import os
import requests
from flask import Flask, render_template, request, send_from_directory, url_for
from werkzeug.utils import secure_filename
app = Flask(__name__)
def replace_selectors(json_data):
# 替换选择器的函数
def replace_selector(selector):
if "." in selector and "@" in selector:
parts = selector.split('.')
tag = parts[0]
selector_part = parts[1]
if "@" in selector_part:
num, at_text = selector_part.split('@', 1)
if ":" in num:
num, tag_after_colon = num.split(':', 1)
num = f"{num}@{tag_after_colon}"
if num.replace("-", "").replace(".", "").isdigit():
num = "1" if num == "0" else num # 处理小数点后面是0的情况
if num.startswith("-"):
num = num[1:]
return f"{tag}:nth-last-child({num})@{at_text}"
else:
return f"{tag}:nth-child({num})@{at_text}"
return selector
# 处理列表类型的 JSON 数据
if isinstance(json_data, list):
for item in json_data:
replace_selectors(item)
return
# 遍历字典类型的 JSON 数据,查找并替换选择器
for key, value in json_data.items():
if isinstance(value, str):
if "@" in value:
value = replace_selector(value)
json_data[key] = value
elif isinstance(value, dict):
replace_selectors(value)
elif isinstance(value, list):
for item in value:
if isinstance(item, dict):
replace_selectors(item)
# 增加替换规则,当"ruleExplore": []时,替换为"ruleExplore": "##"
if "ruleExplore" in json_data and not json_data["ruleExplore"]:
json_data["ruleExplore"] = "##"
if __name__ == "__main__":
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
json_url = request.form['json_url']
response = requests.get(json_url)
json_data = response.json()
replace_selectors(json_data)
# 提取文件名,并保存 JSON 内容到文件
file_name = json_url.split('/')[-1]
json_dir = os.path.join(os.path.dirname(__file__), 'json')
if not os.path.exists(json_dir):
os.makedirs(json_dir)
json_path = os.path.join(json_dir, file_name)
with open(json_path, 'w', encoding='utf-8') as file:
json.dump(json_data, file, indent=4, ensure_ascii=False)
# 生成下载链接
download_link = url_for('download', file_name=file_name)
return render_template('result.html', json_data=json_data, download_link=download_link)
return render_template('form.html')
@app.route('/json/', methods=['GET'])
def download(file_name):
json_dir = os.path.join(os.path.dirname(__file__), 'json')
file_path = os.path.join(json_dir, file_name)
return send_from_directory(json_dir, file_name, as_attachment=True)
app.run(host='0.0.0.0', port=5000, debug=True)
4.2 我还写了个docker版本的
docker pull realwang/booksource_transios:latest
docker run -d --name transios -p 5000:5000 booksource_transios
# 使用python3环境作为基础镜像
FROM python:3
# 设置工作目录
WORKDIR /app
# 安装git,用于从GitHub下载代码
#RUN apt-get update && apt-get install -y git
# 从GitHub下载代码
RUN git clone https://ghproxy.com/https://github.com/wangrui1573/booksource_transIOS.git /app
# 切换到代码目录
WORKDIR /app
# 安装python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 将容器5000端口映射到主机的5000端口
EXPOSE 5000
# 启动Python应用程序
CMD ["python", "api/conv_book_web.py"]
# docker run -d -p 5000:5000 booksource_transios
源代码:https://github.com/wangrui1573/booksource_transIOS