【CHI】架构介绍
Learn the architecture - Introducing AMBA CHI
AMBA CHI协议导论--言身寸
1. AMBA CHI简介
一致性集线器接口(CHI)是AXI一致性扩展(ACE)协议的演进。它是Arm提供的高级微控制器总线架构(AMBA)的一部分。AMBA是一种免费可用、全球采用的开放标准,用于SoC中功能块的连接和管理。它有助于一次性正确开发具有大量控制器和外设的多处理器设计。
CHI适用于需要一致性的各种应用,包括移动、网络、汽车和数据中心。AMBA CHI旨在维护组件数量和流量不断增长的系统中的性能。
本导论介绍了CHI协议的前三个问题,概述了CHI,并深入探讨了几个特性。
注:多样性和包容性对Arm来说是重要的价值观。因此,我们正在重新评估我们在文档中使用的术语。较旧的Arm文档(包括AMBA AXI和ACE协议规范)使用术语主设备和从设备。本导论使用替代术语,如下所示:
• 新术语Requester(请求者)在旧文档中与master(主设备)同义
• 新术语Subordinate(从属设备)在旧文档中与slave(从设备)同义
2. CHI介绍
CHI 旨在实现可扩展性,使您能够构建小型、中型或大型系统。这些系统使用多个组件,范围从处理器集群、图形处理器和内存控制器,到 I/O 桥、PCI Express(PCIe)子系统和互联本身。
在本节中,我们将介绍 CHI 的前三个问题的基本概念。
CHI 网络拓扑
CHI 定义了 CHI 网络中的不同组件,但没有定义用于连接这些组件的拓扑。这种拓扑灵活性允许您根据性能、功耗和面积要求驱动组件连接。
拓扑有:
• 环形拓扑。在环中,每个组件直接连接到另外两个组件,形成一个所有组件都可以相互通信的环。这种拓扑的缺点是延迟随环中组件数量的增加而线性增加。这是因为事务必须遍历环,直到到达目的地。因此,环形拓扑最适合中等规模的系统。
• 网格拓扑。与环相比,网格包含更多事务到达目的地的路径,因此减少了事务的传输时间。这提供了更高的系统带宽,但是占用了更多的面积。网格拓扑最适合大规模系统。
• 交叉开关。这种拓扑允许每个节点连接到每个可能的节点。这种设计提供了最佳性能,因为每个组件都与需要通信的组件直接连接。这种拓扑的缺点是连接所有组件的成本。这是因为随着每个附加组件,系统所需的导线数量可能会显著增加。因此,交叉开关最适合小型系统。
以下图片展示了可以实现 CHI 协议的不同类型的拓扑:

在此图中,圆圈表示网络中的请求者和从组件。方形表示用于在请求者和从端之间路由事务的中间组件。
CHI 协议迭代
目前有六个版本的 CHI 协议:A 到 F。本导论描述了 A 到 C 的问题以及这三个问题之间的主要差异。
CHI-A 问题是 CHI 协议的第一个版本。它提供了一个传输层,具有减少拥塞的功能。
CHI-A 规范描述了 CHI 的基本行为。此规范包括:
• 新通道、CHI 术语和组件命名的定义
• 请求、监听过滤器和缓存状态转换的示例
• 事务排序、独占访问和分布式虚拟内存(DVM)操作的规则
CHI-B 问题扩展了 CHI-A,但不能直接向后兼容 CHI-A。它添加了支持 Armv8.1 和 Armv8.2 系统扩展的功能,例如:
• 更大的物理地址宽度
• 原子事务
• DVM 的 VMID 扩展
• 通道字段、事务结构和可靠性、可用性和可维护性(RAS)特性的描述
• 直接内存传输和直接缓存传输功能,减少内存和监听访问延迟
CHI-C 问题是 CHI-B 的次要扩展。此扩展主要添加了减少请求危险生命周期的功能。CHI-C 还添加了两个操作码,以减少完成确认的时间,并对协议进行了更改以支持这些操作码。
CHI 缓存行状态
CHI 使用了类似于 ACE 的一致性模型,增加了对监听过滤器和基于目录的系统的支持,以实现监听扩展。
CHI 还使用与 ACE 相同的术语来定义缓存状态,并添加了部分和空缓存行状态。缓存行状态术语包括:
• 有效和无效,用于描述缓存行是否存在于本地缓存中。
• 如果缓存行有效,则必须是唯一或共享的:
◦ 唯一意味着缓存行仅存在于此缓存中,而不在任何其他请求者本地缓存中。仅当缓存行处于唯一状态时,才能对本地缓存行进行存储。
◦ 共享意味着缓存行存在于此缓存中,并且可能存在于其他请求者本地缓存中,也可能不存在。
• 如果缓存行有效,它必须是Clean或Dirty的:
◦ Clean表示缓存不负责更新主内存。由于在另一个缓存中进行的先前更新,缓存行仍然可以保存与主内存不同的值。
◦ Dirty表示相对于主内存修改了缓存行。当此行从此缓存中逐出时,请求者必须确保更新主内存,或者将脏责任传递给系统中的另一个组件。
• 一行可以处于部分和空状态:
◦ 空缓存行没有有效的数据字节,但行的所有权仍然属于请求者。
◦ 部分缓存行可以具有一些有效字节,包括无字节或所有字节。这是因为状态已更新,但尚未写入有效字节,或者因为已写入所有字节,但尚未更新状态。在此状态下监听缓存行时,可以给出的响应有额外的限制。
然后将这些术语组合以描述如下图所示的七种缓存行状态:

在MOESI的基础上额外增加两个状态
该图包含以下缓存行状态:
无效(Invalid,对应I态)
缓存行不在缓存中。
唯一脏(Unique Dirty,对应M态)
此缓存行仅存在于此缓存中,并相对于主内存进行了修改。在此状态下,请求者可以对缓存行执行写操作,因为该行已处于唯一状态。如果监听指示,缓存行必须转发给请求者。
唯一脏部分(Unique Dirty Partial)
此缓存行仅存在于此缓存中,并被认为相对于主内存进行了修改。它可以具有一些有效字节,其中一些包括无字节或所有字节。在此状态下,请求者可以对缓存行执行写操作,因为该行已处于唯一状态。对于监听,即使监听指示也不能将缓存行直接转发给原始请求者。
共享脏(Shared Dirty,对应O态)
相对于主内存修改了此缓存行,而且这个特定的缓存有责任更新主内存。由于缓存行是共享的,它可能存在于一个或多个本地缓存中,但这并不是必须的。如果该行存在于多个缓存中,这些缓存将在共享干净状态下拥有此行。
唯一干净(Unique Clean,对应E态)
与主内存相比,缓存行没有被修改,并且仅存在于单个本地缓存中。它可以在不通知其他缓存的情况下进行修改。
唯一干净空(Unique Clean Empty)
缓存行仅存在于此缓存中,但没有有效字节。缓存行可以在不通知其他缓存的情况下进行修改。如果监听请求该行,则不得将该行返回给Home或直接转发给原始请求者。
共享干净(Shared Clean,对应S态)
缓存行可能存在于一个或多个本地缓存中。与主内存相比,该行可能已被修改,但此缓存不负责在逐出时将行写回内存。
3. CHI协议基础
CHI协议通过节点类型对系统中的不同组件进行分类,并提供了节点之间通信的方法。本导论的这一部分将回顾节点类型及其通信方式,然后更详细地研究协议消息,这些消息以Flits形式发送。
节点
主要有三种类型的节点:请求节点(RNs)、基节点(HNs)和从节点(SNs)。此外,还有杂项节点(MN),本节也将介绍。
RNs生成事务,如读和写请求,这些事务发送到HNs。HNs负责对请求进行排序,向SNs生成事务,并可以发出监听或处理DVM操作。
这些节点类型可以进一步分类为以下几类:
• RNs可以是完全一致的、I/O一致的或具有DVM支持的I/O一致的:
◦ 完全一致的请求节点(RN-Fs),包含一致的缓存并将接受和响应监听
◦ I/O一致的请求节点(RN-Is),没有一致的缓存,不能接受监听
◦ 具有DVM支持的I/O一致请求节点(RN-Ds),具有与RN-Is相同的功能,还可以接受DVM消息
• 基节点可以是完全一致的、非一致的或杂项的:
◦ 完全一致的基节点(HN-Fs)对一致内存的所有请求进行排序并向RN-Fs发出监听
◦ 非一致的基节点(HN-Is)对I/O子系统的请求进行排序
◦ 杂项节点(MNs)处理请求节点发送的DVM事务。这些有时作为HN-D节点实现
• 适用于普通内存或外设和普通内存的从属节点(SN-Fs):
◦ SN-Fs连接到支持一致内存空间的存储器设备。例如,内存控制器将连接到SN-F节点。
◦ 适用于外设或普通内存的SN-Fs连接到I/O外设或非一致内存
以下表格总结了每个节点类别的行为:
| RN-F, HN-F, SN-F |
RN-I, HN-I, SN-I |
I/O一致性DVM支持 |
MN |
|
| RN |
一致性缓存 |
无一致性缓存 |
- |
- |
| RN |
接受并响应监听 |
不接受或响应监听 |
在其他所有方面与RN-I相同 |
- |
| HN |
对一致性内存的请求进行排序 |
对I/O子系统的请求进行排序 |
- |
处理由RN发送的DVM事务 |
| HN |
向RN-Fs发送监听 |
- |
- |
- |
| SN |
连接支持一致性内存空间的存储器设备 |
连接I/O外设或非一致性内存 |
- |
- |
在系统中的某些组件也可以被分类为请求者或完成者,如下所述:
• 请求者是通过发出请求消息启动事务的组件。术语“请求者”可用于独立发起事务的组件。术语“请求者”也可用于互联组件,其发出下游请求消息,可独立或作为系统中正在发生的其他事务的副作用。
• 完成者是响应从其他组件接收到的事务的组件。完成者可以是互联组件(如HN或MN),也可以是位于互联之外的组件(如从属组件)。
系统地址映射
系统中的每个组件都被分配一个唯一的节点ID。CHI使用系统地址映射(SAM)将物理地址转换为目标节点ID。
为了能够确定发出请求的目标节点ID,每个RN和HN都必须具有SAM。
以下图示展示了RN SAM将物理地址映射到HN节点ID,以及HN SAM将物理地址映射到SN节点ID:

在这个图示中,事件的顺序如下:
- 地址为0x8000_0000的事务通过节点0中的RN SAM。
- RN SAM确定目标为节点5。
- 事务路由到节点5的HN。
- HN接收到事务。
- HN通过其HN SAM传递地址,并确定目标为节点2。
- 事务被路由到节点2的SN。
RN SAM必须满足以下要求:
• 它必须完全描述整个系统地址空间
• 任何不对应于物理组件的物理地址必须映射到一个可以提供适当错误响应的节点
• 所有RN必须对RN SAM有一致的视图。例如,无论是哪个RN发出的,地址0xFF00_0000必须始终指向同一个HN。
注:SAM的确切格式和结构完全由实现定义。CHI规范没有提供关于如何将地址映射到节点ID的指导。
节点通道
与ACE相比,CHI使用不同的通道:
• 请求(REQ):发送读和写请求、缓存维护请求和DVM请求
• 响应(RSP):发送各种类型消息的完成响应,范围从写和缓存管理响应到无数据监听响应和操作完成确认。
• 监听(SNP):发出监听或发送DVM操作数据传输消息和标记为DAT的,发送写和读数据,以及带数据的监听响应
注:以TX字母为前缀的通道用于发送消息,以RX字母为前缀的通道用于接收消息。
下图显示了RN-F上CHI请求者接口上的通道:

当RN-F发出读请求时,它在其TXREQ通道上发送请求。当读数据返回时,RN-F在其RXDAT通道上接收数据。每个节点上的TX信号连接到目标节点上的RX信号。在SNP通道上发生以下约束:
• 只有HN-F和MN在SNP通道上发出消息
• RN-F仅在SNP通道上接受监听
• MN仅在SNP通道上接受DVM消息监听
Flit
所有协议消息都以Flit(切片)的形式发送。Flit是一种打包的控制字段和标识符集合,用于传递协议消息。
在Flit中发送的一些控制字段包括操作码、内存属性、地址、数据和错误响应。每个通道需要不同的Flit控制字段。例如,请求通道上用于读或写的Flit需要一个地址字段,而数据通道上的Flit需要数据和字节使能字段。
与PCIe或以太网协议中的字段不同,Flit中的字段不会在多个数据包上串行化。相反,它们是并行发送的。
以下图示显示了一个请求Flit,以及Flit操作码的详细信息:
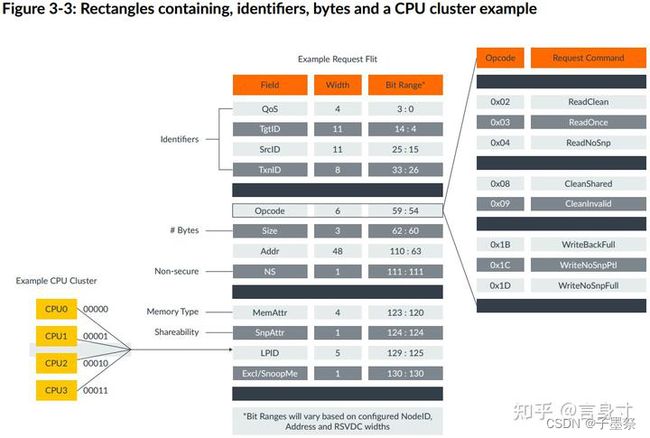
在CHI中传递Flit的握手机制与ACE中的不同。每个通道都关联有一个FLITV信号,发射器将该信号设置为高电平以表示Flit有效。然后在下一个上升CLK边沿上进行传输。只有当发射器先前收到接收器的信用时,才能发送Flit。信用通过LCRDV信号指示,并在上升的CLK边沿上确认。
为了在Flit中提供额外的信息,CHI定义了多个标识符字段。例如:
• 源ID字段(SrcID)用于在CHI网络中路由Flit。该字段标识Flit的发送者,并且每个Flit都有SrcID字段。源ID的值是发送消息的组件的节点ID。
• 目标ID字段(TgtID)也用于在网络中路由Flit。目标ID值是接收消息的节点的节点ID。除了监听Flit之外,每个Flit都包含目标ID字段。监听通道不包含目标ID的原因是CHI使用实现来确定哪些节点接收到监听。HN-F可以使用任何机制来路由监听,例如向所有RN-F广播监听,或使用监听过滤器仅针对RN-F的子集。无论使用什么机制,当监听Flit离开互连时,它已经针对特定节点。
• 事务ID字段(TxnID)出现在每个Flit中。此字段是一个8位字段,用于标识源节点和目标节点之间的每个事务。来自RN的每个未完成请求都必须具有唯一的TxnID。在任何时候,RN最多可以有256个未完成的事务。
• 请求操作码(Opcode)出现在REQ Flit中。这指定了事务类型,并且是决定事务结构的主要字段。例如,不同类型的读请求,写请求或无数据请求。
• 数据缓冲区ID(DBID)仅出现在响应和数据Flits中。目标节点使用此标识符来表示接收写数据的可用性,并释放需要完成确认的事务。
◦ 对于写操作,请求者在收到完成者的响应中的DBID值之前不能发送写数据
◦ 一些读事务以完成确认结束,这是请求者表示已收到读数据的地方。有关更多信息,请参阅事务流程。将读数据发送回请求者时,数据flit包含一个DBID值,供请求者在发送完成确认消息时使用。
以下表格总结了每种标识符可以使用哪种Flit类型:
| ID |
请求Flit(REQ) |
响应Flit(RSP) |
数据Flit(DAT) |
监听Flit(SNP) |
| SrcID |
Y |
Y |
Y |
Y |
| TgtID |
Y |
Y |
Y |
- |
| TxnID |
Y |
Y |
Y |
Y |
| DBID |
- |
Y |
Y |
- |
举一个如何在整个事务中更改这些标识符字段的示例,请参阅事务流程。
4. 事务流程
事务是节点完成请求所需的系统消息集合。本节包括以下示例:
• 在请求者和完成者之间的写请求中使用标识符
• 完成ReadNoSnp事务所需的消息序列
• 从请求节点到完成节点的WriteNoSnp事务流程
写请求和标识符在以下示例中,我们展示了在请求者和完成者之间的写请求中使用标识符。请求者被分配节点ID 1,完成者被分配节点ID 2。
以下描述了事件顺序:
- 1. 请求者向完成者发送具有事务ID(TxnID)3的写请求。请求者中的源ID(SrcID)字段填充了请求者的节点ID。目标ID(TgtID)字段填充了完成者的节点ID。此步骤如下图所示:

- 2. 完成者将请求的事务ID和源ID分配给一个可用的数据缓冲槽。在本例中,请求被分配了数据缓冲区ID(DBID)0。
- 3. 完成者向请求者发送带有TxnID 3和DBID值0的DBIDResp消息,如下图所示:

- 4. 请求者使用接收到的DBID作为事务ID向完成者发送写数据。
- 5. 当事务完成时,对应于DBID 0的缓冲槽将被释放。
ReadNoSnp事务流程
以下示例展示了完成ReadNoSnp事务所需的消息序列。请求节点0发出ReadNoSnp请求,完成节点5提供读数据。以下描述了事件顺序:
- 1. 请求节点0向CHI互连发出一个ReadNoSnp,目标为Home节点3。该事务在请求者节点的TXREQ通道上发送。此步骤如下图所示:

- 2. 基节点3在其TXREQ通道上向完成节点5发出ReadNoSnp请求,以检索数据,如下图所示:

- 3. 完成节点5在其TXDAT通道上发出CompData响应,将数据返回给基节点3,如图所示:

- 4. 基节点3将CompData响应发送给请求节点0。请求节点0在其RXDAT通道上接收数据,如图
 所示:
所示:
WriteNoSnp事务流程
本节介绍了从请求节点0到完成节点5的WriteNoSnp事务的流程。
以下描述了事件的顺序:
- 1. 请求节点0在TXREQ通道上向基节点3发送WriteNoSnp消息,如图所示:

- 2. 基节点3向请求节点0响应一个CompDBIDResp消息。此响应表明它可以接受写数据,并且WriteNoSnp对其他请求者是可观察的。此消息通过基节点的TXRSP通道发送。此步骤如下图所示:

- 3. 以下两个步骤可以按任意顺序发生:
(a)基节点3向完成节点5发出WriteNoSnp消息,并收到CompDBIDResp响应,如图所示:
(b)或者,请求节点0可以通过其TXDAT通道将WriteNoSnp的写数据发送到基节点3,如图所示:

- 4. 在收到来自完成节点的CompDBIDResp和来自请求节点的写数据后,基节点3在TXDAT通道上将写数据发送到完成节点5,如图所示:
完成确认
CHI使用完成确认响应来维护以下事务的顺序:
• 由完全一致请求节点(RN-F)发起的事务
• 由这些RN-F事务引发的监听事务
完成确认确保在一致事务完成后,按顺序在RN-F之后接收到监听事务。
HN-F可以通过暂停事务来维护事务顺序。例如,RN-F可能已经有一个正在处理的针对特定缓存行的未完成事务。如果系统中的另一个请求者发起一个导致对同一行进行监听的事务,HN-F可以暂停这个后来的事务。当原始的RN-F完成一致事务时,RN-F使用其TXRSP通道向HN-F发送完成确认(CompAck)消息。然后,HN-F解除等待完成确认的监听阻塞。
这种机制与ACE中的RACK/WACK功能类似。
并非CHI中的每个事务都需要完成确认。请求Flit包含一个ExpCompAck字段,用于表示何时需要完成确认。如果需要完成确认,RN-F在请求中将ExpCompAck设置为1,并在请求完成时发出CompAck响应。
流程如下:
- 请求节点(RN-F)发起一个具有ExpCompAck = 1的请求。
- 基节点完成请求。
- 基节点向RN-F发送Comp或CompData。
- RN-F向基节点发送CompAck。
- 基节点现在可以向RN-F发送等待中的监听。
以下示例展示了在需要读请求中的完成确认时发送的消息:
- 1. 请求者向完成者发送一个读请求,请求地址为0x8000,ExpCompAck字段设置为1,如图所示:

- 2. 完成者为读地址分配一个任意的DBID位置,阻止互连发出针对将来一致请求的监听。这个位置如图所示:

- 3. 完成者使用CompData响应回应请求者,同时表示事务完成并发送读数据。响应中的DBID字段填充了用于存储读地址的DBID位置。这一步如下图所示:

- 4. 请求者发送一个CompAck消息。CompAck使用从完成者那里接收到的DBID值作为事务ID,如图所示:

完成者清除地址0x8000的DBID位置,允许互连向该位置发出未来的监听。
带有监听的CompAck
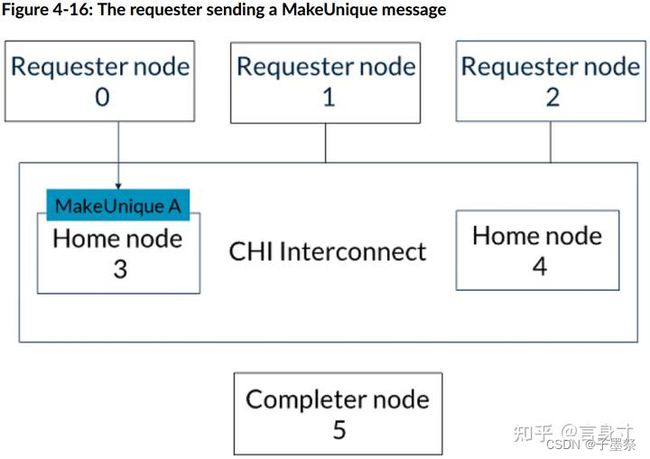
本示例展示了在需要多个请求节点访问相同可缓存内存位置的完成确认时发送的消息。在此示例中,CHI互连向所有缓存请求者广播监听。或者,它可以使用监听过滤器并仅针对本地存在该行的请求者。以下列表描述了事件的顺序:
- 1. 请求者节点0向基节点3发送地址A的MakeUnique消息。当请求者节点0向基节点3发出完成确认时,此事务完成。这一步如下图所示:
- 2. 基节点3向请求者节点1和2发送地址A的SnpMakeInvalid监听,如图所示:
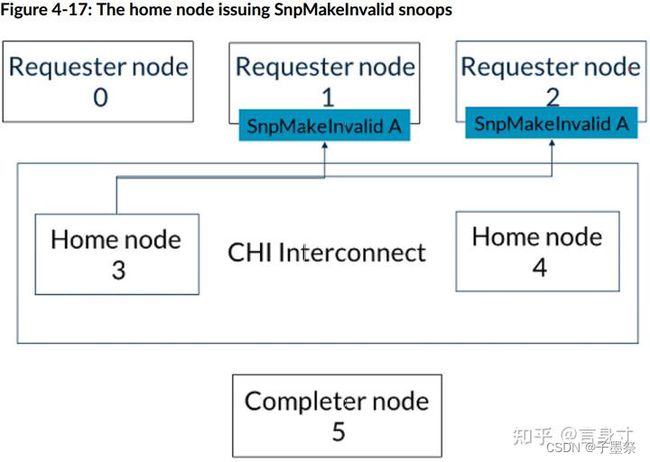
- 3. 请求者节点1和2以SnpResp_1响应。这些响应意味着地址A已失效。基节点3可以按任意顺序接收SnpResp_I。这一步如下图所示:
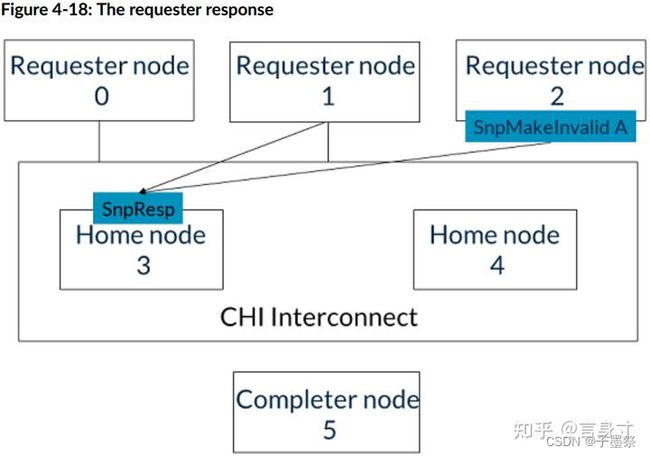
- 4. 请求者节点2向基节点3发送地址A的ReadShared请求。请注意,基节点3仍未对请求者节点0的MakeUnique消息作出回应。现在,直到请求者节点0发送MakeUnique的完成确认消息,由ReadShared请求生成的监听将被阻塞。这一步如下图所示:

- 5. 由于在步骤3中收到的监听响应,基节点3向请求节点0发送Comp_UC消息。
- 6. 请求节点0发送CompAck消息并解除对地址A的监听阻塞。
- 7. 基节点3为地址A生成向请求节点0和1的SnpShared监听。
- 8. 请求节点1以SnpResp响应,表示它没有数据。
- 9. 请求节点0以SnpRespData响应,发送地址A的最新数据。基节点3可以按任意顺序接收这两个响应。
- 10. 收到两个监听响应后,基节点3将监听数据返回给请求节点2。
- 11. 请求节点2向基节点3发送完成确认。基节点3可以向地址A生成未来的监听。
CHI中的端点顺序和请求顺序
事务可以按端点顺序和请求顺序排序,如下所述:
• 端点顺序保持从单个请求者到单个从属地址范围的事务顺序。例如,在端点顺序中,向从属的可编程寄存器组发出多个设备访问。
• 请求顺序保持来自单个请求者到同一地址的事务顺序。例如,当向重叠的非缓存地址(如Normal NC、Device-GRE和Device-nGRE)发出多个请求时,需要排序。当设置请求顺序时,CHI不要求地址匹配的精确粒度,粒度由实现定义。
注:如果设置端点顺序,请求顺序是隐含的。
请求Flit中的Order字段控制排序类型。
只有一些请求类型可以使用请求顺序和端点顺序。这些请求类型是:
• ReadNoSnp和任何ReadOnce类型的请求:
◦ 请求者发出需要排序的ReadNoSnp或ReadOnce类型请求
◦ 从属接受请求并以ReadReceipt消息回应。ReadReceipt信号表明可以发出下一个有序请求
◦ 通过发出ReadReceipt响应,从属保证按收到的顺序维护请求
• WriteNoSnp和WriteUnique类型的请求:
◦ 请求者发出需要排序的WriteNoSnp或WriteUnique类型请求
◦ 从属以DBIDResp消息回应以表示可以接受消息。DBIDResp响应表示数据缓冲区插槽可用于接受写数据,并且请求者可以发出下一个有序请求。
◦ 通过发出DBIDResp,从属保证按收到的顺序维护请求
有关请求类型的更多信息,请参阅CHI规范。
事件顺序如下:
- 请求者使用ReqOrder设置向从属发起读请求1。
- 请求者向从属发出带有ReqOrder设置的读请求2,但由于请求1仍未完成,请求者被阻止发送请求。
- 从属以ReadReceipt消息回应读请求1,表示请求已被接受。
- 以任意顺序:
- 请求者向从属发送读请求2。
- 从属将读请求1的读数据返回给请求者。
请求重试
有时目标节点可能没有足够的资源来接受请求。
为防止在资源不可用时阻塞请求通道,CHI提供了一个请求重试机制。请求重试机制使用协议信用(Protocol Credits)来指示资源可用性。确定和记录处理请求所需的协议信用(PCrd)类型是从节点的责任。
该机制可以使用不同类型的协议信用来跟踪不同的资源。例如,读请求和写请求可以使用单独的数据缓冲区,因此每个缓冲区可以使用不同类型的协议信用来指示可用性。不同类型的协议信用值由实现定义。
以下示例描述了伴随请求重试发送的消息序列。在此示例中,请求者节点1发出请求,因为完成者无法接受请求。
以下描述了事件顺序:
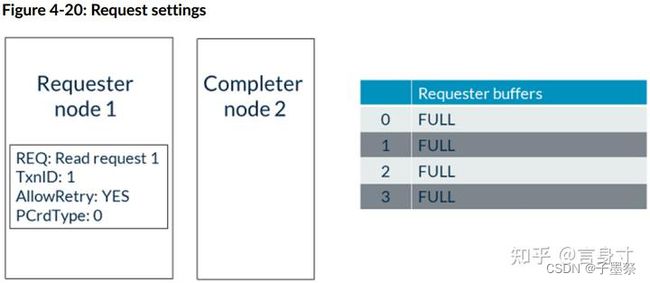
- 1. 每个请求最初都是在没有协议信用的情况下发出的。请求Flit中有一个名为AllowRetry的控制字段。第一次发送请求时将此字段设置为YES表示请求没有使用协议信用。当AllowRetry为YES时,请求中的PCrdType字段必须为0。以下图表显示了请求设置:
- 2. 在此示例中,目标节点由于请求者缓冲区已满而无法接受请求,因此返回一个RetryAck消息。
- 3. RetryAck响应Flit中设置了一个PCrdType字段,其值表示需要重试请求所需的信用类型。在此示例中,PCrdType的值为2,如图所示:

- 4. 当目标节点可以接受请求时,它在RSP通道上发送一个PCrdGrant消息。PCrdGrant响应Flit使用PCrdType字段来指示已变为可用的协议信用类型。请求者只有在PCrdGrant消息和RetryAck响应中的协议信用类型匹配时才能重试请求。在这个例子中,两个字段都必须设置为2。如果协议信用类型匹配,目标节点现在可以保证接受请求。
- 5. 请求者重新发出请求,并将AllowRetry字段设置为0。将AllowRetry字段设置为0表示向目标节点指示请求正在使用已授予的协议信用。
5. DVM操作
与ACE一样,CHI支持分布式虚拟内存(DVM)操作。DVM请求传递操作以支持维护虚拟内存系统。
DVM操作事务
CHI使用DVM操作来管理虚拟内存。
DVM操作执行以下事务:
• 事务查找边缘缓冲器(TLB)失效
• 指令缓存失效
• 分支预测器失效
• DVM同步
在CHI中,所有DVM操作都分为两部分发送到MN。这与ACE不同,在ACE中,一些DVM操作需要两部分,而其他操作只需要一部分。
以下列表描述了CHI中的部分顺序:
• DVM操作的第一部分作为请求发送给MN,Opcode字段设置为DVMOp。请求Flit使用地址字段来编码操作的属性。
• DVM的第二部分作为数据Flit发送,只有在请求节点收到MN的DBID响应后才发送。这第二部分携带了DVM操作所针对的地址。
当MN收到DVM操作的两个部分时,MN会向参与一致性域的请求节点生成DVM Snoop。MN在节点监听通道上发送两部分的DVM Snoop。
DVM Snoop的两个部分必须使用相同的TxnID和Opcode SnpDVMOp,并使用以下参数:
• 第一部分使用地址字段来编码操作属性和目标地址的高位
• 第二部分使用地址字段发送地址的其余位
为了区分这两部分,CHI要求地址字段的bit[3]设置为0以表示第一部分,设置为1表示第二部分。
DVM监听的第二部分可能在第一部分之前到达RN。
DVM操作类型
CHI定义了两种类型的DVM操作:非同步DVM(DVM Non-Sync)和同步DVM(DVM Sync)。DVM操作的属性决定了RN在响应DVM Snoop之前是否必须等待操作完成。
同步DVM仅执行同步操作,没有其他操作。
非同步DVM是TLB、指令缓存和分支预测器的失效操作。非同步DVM不需要在发出更多DVM操作之前完成DVM操作的执行。这允许有多个非同步DVM未完成。
在以下示例中,RN-F可以发出多个分支预测器或指令缓存失效,接收RN-F或RN-D不必立即执行操作:
- RN-F或RN-D接收到一个指示DVM Non-Sync的DVM Snoop。
- RN-F或RN-D向MN发出Snoop响应。Snoop响应确认收到DVM消息,但不表示请求节点已经执行了DVM操作。
- MN向发起RN-F发送完成消息,表示已接受DVM操作。
为确保所有未完成的DVM请求已执行,需要执行以下步骤:
- RN-F向MN发出同步DVM操作,也称为DVM Sync。需要在发出DVM Sync之前接收完成响应的任何DVM请求都必须先完成。
- MN在监听通道上向所有RN-F和RN-D发出DVM Sync。
- 每个目标RN确保其所有未完成的DVM操作已执行。
- 每个RN向MN发出一个Snoop响应,表示所有操作已执行。
- MN向最初发出同步DVM操作的RN-F发送DVM Sync的完成响应。
CHI DVM Sync与ACE中的DVM Sync类似。两者都检查之前发出的DVM操作是否已完成。不同之处在于,CHI不需要DVM完成消息。
注:Arm内核会因DSB指令产生DVM Sync。然而,实现可以选择仅在尚未同步的DVM操作存在时,才因DSB发出DVM Sync。
DVM操作流程
本节描述了一个TLB失效DVM请求,后续有一个同步DVM操作,并展示了以下事件:
• DVM请求的不同部分
• MN生成的监听操作
• DVM同步如何确保之前的DVM操作已执行
事件顺序如下:
- 请求节点0向MN发出一个TLB失效DVM请求。
- MN用DBIDResp消息响应,表示可以接受DVM请求的第二部分。
- 请求节点0向MN发出写数据消息。这是DVM消息的第二部分。
- MN将DVM请求的两个部分发送给请求节点1。
- 请求节点1通过向MN发送监听响应来确认DVM请求。
- MN接收到监听响应。
- MN向请求节点0发出完成消息。
- 请求节点0向MN发出一个DVM同步操作。
- MN向请求节点0发出DBIDResp消息。
- 请求节点0向MN发送写数据消息。这是DVM同步消息的第二部分。
- MN向请求节点1发出DVM同步监听操作。
- 请求节点1完成所有未完成的DVM操作。
- 请求节点1向MN发送监听响应,表示已完成所有操作。
- MN向请求节点0发出完成消息。这是对DVM同步请求的响应。
6. 缓存贮存(stashing)
缓存贮存是一种在系统内特定缓存中安装数据的机制。CHI-B引入了这个特性以提高系统性能。缓存贮存机制通过在数据即将使用的地方附近分配一个缓存行来提高系统性能。当使用数据时,这将导致更低的内存访问延迟。
通常,缓存贮存(Stash)请求由RN-I和RN-D节点发起。缓存贮存请求是一个建议,而不是一个强制性动作,即在系统中的特定缓存内安装特定的缓存行。接收缓存贮存请求的设备可以忽略该请求。
CHI支持两种主要形式的缓存贮存:包含写数据的贮存事务,以及无数据的贮存事务。两种形式的缓存贮存都可以将不同的缓存级别作为贮存目标。
缓存贮存支持已添加到ACE5-Lite协议中。CHI协议在缓存贮存方面非常灵活,允许贮存请求采用多种形式。
本导论的这一部分介绍了贮存请求的不同形式以及这些请求的消息流程。
事务流程
缓存贮存的基本事务流程如下:
- RN在请求通道上发起一个缓存贮存请求。
- 缓存贮存请求被转发给HN-F。
- HN-F可以:
• 忽略缓存贮存请求。RN-F将贮存监听视为非贮存版本并做出相应的响应。或者,
• 接受请求并生成针对RN-F的监听。RN-F响应并将缓存行提取到其缓存中。 - 被指定进行贮存的RN-F接收到一种特殊类型的noop请求,称为贮存监听。
RN-F可以:
• 使用DataPull机制提供一个充当关联缓存行读请求的监听响应
• 在不使用DataPull的情况下提供监听响应,然后为该缓存行发出独立的读请求
• 在不获取该行的情况下提供监听响应,忽略缓存贮存暗示
贮存监听请求
所有缓存贮存请求都会发送到HN-F节点。当HN-F处理缓存贮存请求时,它会向目标RN-F生成贮存监听。
CHI定义了四种不同的贮存监听请求,每种请求对应于初始缓存贮存事务。以下表格详细介绍了这些请求:
| 贮存缓存事务 |
HN-F发出的监听请求 |
RN-F采取的操作 |
| WriteUniquePtlStash |
SnpUniqueStash |
使缓存行无效并返回数据(如果数据已更改,则带有写数据) |
| WriteUniqueFullStash |
SnpMakeInvalidStash |
如果存在,则使缓存行无效(带有写数据) |
| StashOnceShared |
SnpStashShared |
针对缓存行发出共享请求(无数据) |
| StashOnceUnique |
SnpStashUnique |
针对缓存行发出唯一请求,为未来写做准备(无数据) |
缓存贮存控制字段
CHI为缓存贮存添加了请求、监听、响应和数据Flit的控制字段。这些字段表示:
• 贮存目标的NodeID
• RN-F内的特定逻辑处理器缓存,如L2缓存
• 是否使用DataPull机制
Request Flit对于缓存贮存请求使用以下字段:
• StashNID保存贮存目标的节点ID。如果RN-F被选为贮存目标,StashNID字段将填充RN-F的节点ID。
• StashNIDValid。如果在贮存时应使用StashNID字段,StashNIDValid将为1。
• StashLPID指定RN-F内的逻辑处理器ID。此字段允许将较低级别的缓存(如L2缓存)指定为贮存目标。
• StashLPIDValid。如果在贮存时应使用StashLPID字段,StashLPIDValid将为1。
Snoop Flit还包含以下字段:
• StashLPID和StashLPIDValid。如果缓存贮存请求指示StashLPID有效(StashLPIDValid = 1),监听将使用缓存状态请求中的StashLPID值。如果没有指定StashLPID(StashLPIDValid = 0),则贮存的数据可以放置在RN-F内的共享缓存中。
• DoNotDataPull:如果此字段设置为1,则贮存目标无法请求DataPull,因此无法使用DataPull机制。
带写数据的事务
如果请求者正在写入新数据并需要一个目标来存储该数据,则发出WriteUniqueStash事务。写入的数据可以是完整或部分缓存行。
CHI使用以下操作码之一来指示带有贮存暗示的写:
• WriteUniquePtlStash表示部分缓存行写
• WriteUniqueFullStash表示完整缓存行写
本节介绍I/O请求者如何发出带有写数据的贮存暗示。贮存事务的目标是系统中的RN-F。
事件顺序如下:
- 1. RN-I发出带有写数据的WriteUniqueFullStash请求。为简化起见,此示例未描述HN-F的DBIDResp。如下图所示:

- 2. HN-F接受贮存请求,然后向RN-F发出SnpMakeInvalidStash请求,如下图所示:

- 3. RN-F接收到NH-F的监听。
- 4. RN-F接受贮存暗示并发出监听响应,如图所示:

- 5. 如果使用DataPull机制,RN-F发出隐式读请求的监听响应,或者发出监听响应和单独的读请求。为简化起见,本示例中使用隐式监听响应和读请求,但未使用完整的DataPull流程。
- 6. HN-F将从RN-I接收到的写数据发送给RN-F。
无写数据的事务
请求方在将缓存用作贮存目标但不写入数据时,使用无数据贮存事务。CHI对于无数据贮存请求使用以下操作码:
• 如果预期贮存目标会读取缓存行,则发出StashOnceShared。此操作码表示在分配后,缓存行应处于共享状态。
• 如果预期贮存目标会写入缓存行,则发出StashOnceUnique。此操作码表示缓存行应处于唯一状态,从而使贮存目标在将来需要时能立即写入缓存行。
以下示例描述了没有写数据的贮存暗示。RN-I向RN-F发送贮存请求,将RN-F作为贮存目标,并且HN-F和RN-F都接受贮存暗示。
事件顺序如下:
- 1. RN-I向HN-F发出StashOnceUnique请求,指示RN-F是目标且没有写数据。以下图示显示了这个步骤:

- 2. HN-F接受贮存请求。
- 3. HN-F向主内存发出ReadNoSnp请求以获取缓存行,并向RN-F发出 SnpStashUnique 监听,如图所示:

- 4. 主内存将缓存行返回给HN-F,如图所示:
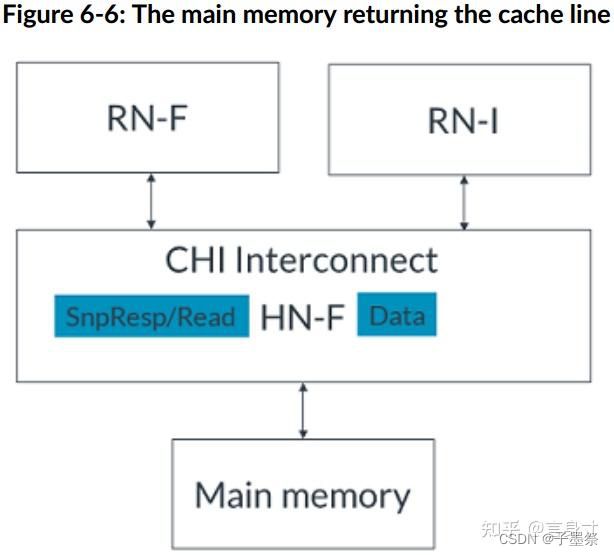
- 5. RN-F对监听作出回应,请求缓存行。
- 6. HN-F将缓存行转发给RN-F。
贮存请求不需要有效的贮存目标。如果未指定贮存目标,则请求中的目标HN-F成为贮存目标。然后,HN-F选择是否将缓存行分配到其缓存中。
以下步骤描述了无写数据的贮存暗示,目标是系统缓存。事件的顺序如下:
- RN-I向HN-F发出StashOnceShared请求。将StashNIDValid字段设置为0以定位HN-F。
- HN-F向主内存发出ReadNoSnp请求以获取指定的缓存行。
- 主内存将缓存行返回给HN-F。
- HN-F将缓存行分配到其缓存中。
DataPull机制
DataPull机制是通过Snoop响应暗示读请求的一种方式,因此不需要单独的读请求来获取要贮存的缓存行。DataPull仅适用于贮存Snoop请求,而不适用于其他任何snoop。
接收要求DataPull的请求的RN-F可以选择是否使用DataPull或发送单独的读请求。如果RN-F选择不请求DataPull,它会响应snoop,然后可以稍后发送读请求以获取缓存行。
有关DataPull允许的所有Snoop响应的信息,请参阅AMBA 5 CHI架构规范。
在本节中,我们描述了RF-F利用DataPull机制作为贮存事务的一部分接收数据的过程。DataPull的完整事务流程如下:
- HN-F发出贮存Snoop并将Snoop Flit中的DoNotDataPull字段设置为0。这表明RN-F贮存目标可以请求DataPull。
- 接收到DoNotDataPull = 0的RN-F可以选择在其Snoop响应中请求DataPull。在此示例中,RN-F选择请求DataPull。
- RN-F通过在Response Flit中设置两个字段来请求DataPull:
• 将DataPull字段设置为1
• 使用将用于返回读数据的TxnID填充DBID字段 - RN-F接收到读取的数据。
- RN-F向HN-F发送CompAck消息。
以下图示显示了StashOnceUnique事务的DataPull机制的时序:
在此图示中,示例系统包含:
• 发起请求的一个RN-D
• 一个作为贮存目标的RN-F
• 一个HN-F
• 一个SN-F
示例中的完整事务流程如下:
- RN-D向HN-F发出StashOnceUnique请求。StashNID字段的值表示RN-F1是贮存目标。
- HN-F接受贮存请求。
- HN-F发出:
• 一个ReadNoSnp请求到SN-F
• 一个SnpStashUnique Snoop到RN-F1 - HN-F向RN-D发送完成响应。
- RN-F1接受贮存暗示。
- RN-F1使用SnpResp_I_Read DataPull请求响应SnpStashUnique。SnpResp_I_Read响应表示隐式读请求。DBID字段将事务ID设置为Y。
- SN-F将缓存行返回给HN-F。
- HN-F将缓存行转发给RN-F1,其中:
• TxnID = Y
• DBID = Z - RN-F1向HN-F发出完成确认响应,TxnID = Z。
下一个示例显示了WriteUniquePtlStash事务的DataPull机制的时序:
在此示例中,系统具有:
• 一个RN-D节点
• 两个RN-F节点:RN-F1和RN-F2。当发送贮存请求时,RN-F2持有缓存行。
• 一个HN-F节点
示例中的事务流程如下:
- RN-D向HN-F发出WriteUniquePtlStash请求。贮存目标是RN-F1。
- HN-F接受贮存请求。
- HN-F向RN-D返回DBIDResp。
- HN-F生成一个SnpCleanInvalid Snoop到RN-F2。这是因为RN-F2持有缓存行,并将SnpUniqueStash发送到贮存目标RN-F1。
- RN-F2使缓存行无效。
- RN-F2返回一个带有Dirty数据的Snoop响应给HN-F。
- RN-F1发出一个带有隐式读请求的Snoop响应。DBID字段将贮存数据的TxnID设置为Y。
- HN-F接收到Snoop响应。
- HN-F向RN-D发出完成响应。
- RN-D将贮存请求的写数据发送给HN-F。HN-F现在同时拥有写数据和Snoop响应中的数据。HN-F为缓存行创建新数据。
- NH-F将缓存行的所有权发送给RN-F1。响应字段为:
• TxnID = Y
• DBID = Z - RN-F1发送一个带有TxnID = Z的CompAck响应。
7. I/O释放(Deallocation)
CHI-B为I/O请求者提供了在完全一致节点中释放(重分配)缓存行的能力。
I/O释放事务提供了一个暗示,即应该使缓存行无效,并且脏数据应该写回到内存或被丢弃。
因为这些请求仅仅是暗示,一个完全一致节点可以选择不使缓存行无效,而只是将数据返回给I/O请求者。换句话说,如果忽略了使缓存行无效的暗示,这些请求将被视为普通的ReadOnce事务。因为它们可以被忽略,I/O释放请求不是缓存维护操作的替代品。
CHI为I/O释放定义了两种请求类型:ReadOnceCleanInvalid和ReadOnceMakeInvalid。这两种请求都有助于避免缓存污染,因为在不久的将来不再使用这些数据。这两种请求类型的区别在于,ReadOnceMakeInvalid不需要将脏数据写入到下一级内存,这可能导致系统中的脏数据被丢弃。这意味着在使用这种类型的请求时必须谨慎。
I/O释放事务示例
本节描述了两个事务流程的示例。第一个示例使用ReadOnceCleanInvalid并将脏数据写回主内存。第二个示例使用ReadOnceMakeInvalid并丢弃脏数据。
这两个示例中的系统都有:
• 完全一致请求节点(RN-F)设备。RN-F以脏状态持有请求的缓存行
• I/O一致请求节点(RN-I)设备
• CHI互连
• 主存
在第一个示例中,ReadOnceCleanInvalid事务流程读取数据使其无效,并将其写回主存。
此示例的完整事务如下:
- 1. RN-I向HN-F发出ReadOnceCleanInvalid事务,如图所示:
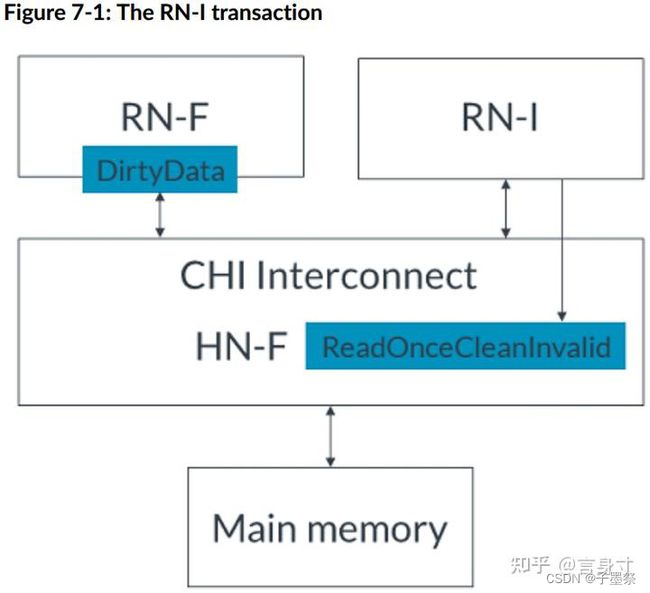
- 2. HN-F向RN-F发送SnpUnique请求,请求缓存行,如下图所示:
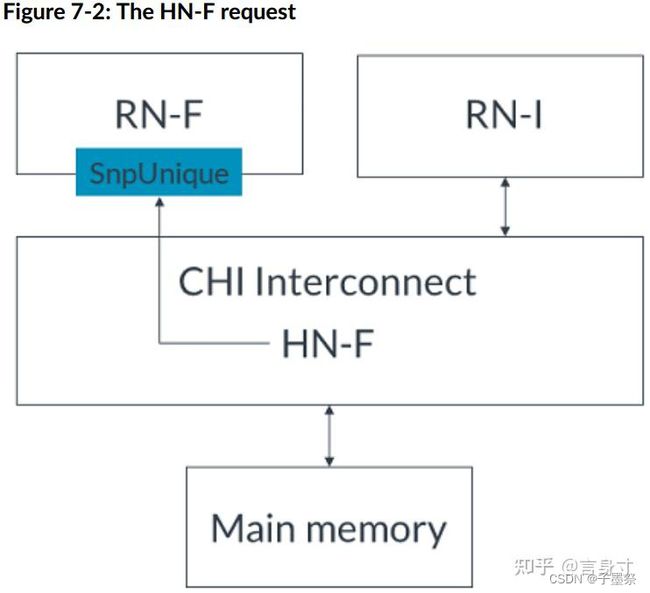
- 3. RN-F使缓存行无效并将脏数据发送到HN-F。
- 4. HN-F将数据返回给RN-I并将数据写入主内存,使其保持干净状态。
在第二个示例中,ReadOnceMakeInvalid事务读取数据并使RN-F中的缓存行无效,但是并没有将脏数据写入主内存,而是丢弃了数据。
此示例的完整事务流程如下:
- 1. RN-I向HN-F发出ReadOnceMakeInvalid事务,如图所示:
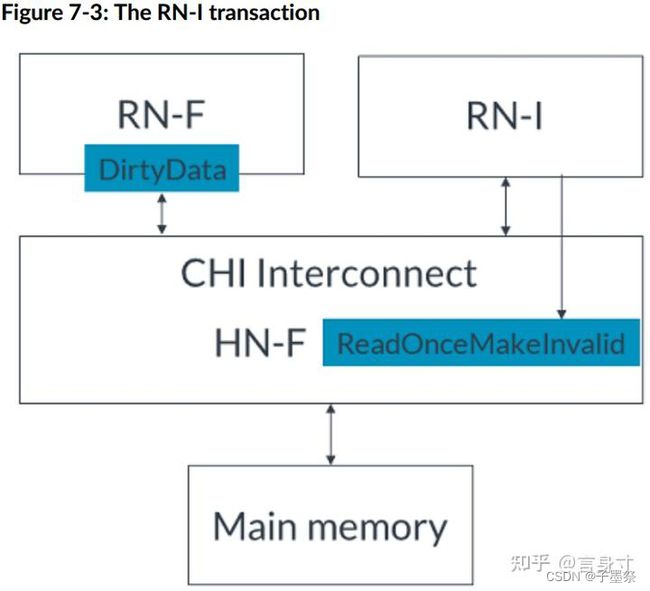
- 2. HN-F向RN-F发送SnpUnique请求,请求缓存行,如下图所示:
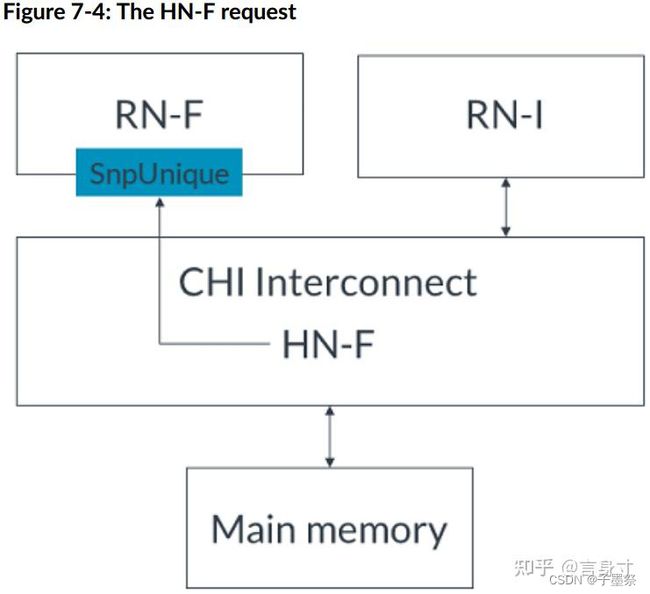
- 3. RN-F使缓存行无效并将脏数据发送到HN-F。
- 4. HN-F将数据返回给RN-I,然后丢弃脏数据。
注:如果在代理读取已失效的脏缓存行之前将其覆盖,ReadOnceMakeInvalid请求可能导致数据丢失。仅在您知道将来不再使用此数据时才使用此事务。
8. DMT、DCT和PrefetchTgt
在CHI-A中,读数据和Snoop数据都通过Home Node传输,然后发起请求的节点才接收到它。通过Home Node的传输增加了这些请求的访问延迟。为了减少这种延迟,CHI-B增加了直接内存传输(DMT)和直接缓存传输(DCT)机制
下表总结了CHI-A和CHI-B中从SN或RN到RN的数据传输差异:
| SN到RN |
RN到RN |
|
| CHI-A |
从SN读取的数据必须在返回RN的途中经过HN |
从RN获取的Snoop数据必须在返回RN的途中经过HN |
| CHI-B |
直接内存传输(DMT):SN数据绕过HN,直接传输到RN |
直接缓存传输(DCT):RN数据绕过HN,直接传输到RN |
为了支持DMT和DCT操作,在请求、Snoop和数据flit中添加了额外的标识符。这些额外的字段指定了以下信息,以便正确地将数据和任何需要的响应路由到正确的端点:
• 读数据的最终目标
• 原始请求的TxnID
• 向SN-F发出请求的HN,或者向RN-F发出Snoop的HN。HN仍然需要CompAck通知,说明DMT或DCT已完成。
CHI-B问题还增加了Prefetch Target(PrefetchTgt)事务,以减少内存访问的访问延迟。PrefetchTgt事务直接从RN-F发送到SN-F,不需要返回任何数据。存储器控制器可以将此作为提示,并为PrefetchTgt请求缓冲数据。如果在数据位于缓冲区时收到对该数据的普通请求,缓冲区将提供更快的访问时间。
本节描述了DMT、DCT和PrefetchTgt的事务流程。本节还描述了每个flit中的额外标识符字段,并使用示例说明如何在每个消息中分配标识符字段。
直接内存传输
在以下示例中,您可以比较读请求在有DMT和没有DMT的情况下,读取数据所采取的路径。
对于没有DMT的读请求,事务流程如下:
- 1. CPU向HN-F发出读请求,如图所示:
图8-1:CPU发出读请求
- 2. HN-F在地址上发生缓存未命中,并向内存控制器发出读请求,如下图所示:
图8-2:HN-F缓存未命中
- 3. 内存控制器获取读请求的数据,然后将数据发送回HN-F。
- 4. HN-F将读取的数据返回给请求缓存行的CPU。在到达目的地之前,读取的数据需要返回到HN-F。
在第二个示例中,使用了DMT,事务流程修改如下:
- 1. CPU向HN-F发出读请求,如图所示:
图8-3:CPU发出读请求
- 2. HN-F在地址上发生缓存未命中,并向内存控制器发出读请求,如下图所示:
图8-4:HN-F缓存未命中
- 3. 内存控制器获取读请求的数据
- 4. 内存控制器将数据发送到发起CPU,而不是HN-F
使用DMT时,读取的数据绕过HN-F,直接发送给发出读请求的CPU。大多数读请求都可以使用DMT机制,包括由缓存存储操作产生的隐式DataPull读。
不能使用DMT的请求包括:
• 独占访问
• ReadNoSnp 请求,其中 ExpCompAck = 0 且 Order != 0
• ReadOnce 请求,其中 ExpCompAck = 0 且 Order != 0
为了支持DMT,CHI包含以下标识符字段:
• 请求Flit使用返回节点ID(ReturnNID)和返回事务ID(ReturnTxnID)字段
• 数据Flit使用基节点ID(HomeNID)字段
下面的示例中的图示显示了DMT事务流程的时序,重点关注标识符字段的使用:
在此示例系统中有:
• 具有节点ID 1的RN-F(RN-F_NID1)
• 具有节点ID 2的HN-F(HN-F_NID2)
• 具有节点ID 3的SN-F(SN-F_NID3)
示例中的DMT事务流程以如下方式使用标识符字段:
• RN-F向HN-F发送具有TxnID = A和ExpCompAck = 1的ReadOnce请求
• HN-F的缓存中没有请求的数据,因此它向SN-F发出ReadNoSnp请求。ReadNoSnp请求包括:
◦ TxnID = B
◦ ReturnNID = 1。这表示应将读取的数据发送到具有节点 ID 1 的 RN-F
◦ ReturnTxnID = A。这与原始 ReadOnce 请求的 TxnID 匹配。
• 当SN-F准备好返回读取的数据时,它发送带有以下内容的CompData_UC消息:
◦ TxnID = A。这与SN-F收到的ReturnTxnID的值匹配
◦ HomeNID = 2。这是HN-F的节点 ID
◦ DBID = B。这与HN-F发送的ReadNoSnp的TxnID匹配
• RN-F向HN-F发送具有TxnID = B的CompAck消息。这与CompData_UC消息中的DBID字段匹配。
• HN-F收到CompAck后,可以停止跟踪它发送给SN-F的ReadNoSnp消息。
在 CHI-B 中,针对某些 ReadOnce 和 ReadNoSnp 事务,包含了一种优化的 DMT 序列。该序列要求 SN-F 节点识别请求 Order 字段中的值 0x1,并向 HN-F 发送 ReadReceipt 响应。此项新增功能可减少 HN-F 节点处事务的生命周期,从而有可能释放资源。
相比之下,CHI-A 在 Order 字段中将值 0x1 标记为保留,并且不要求 SN-F 提供 ReadReceipt。允许发送 ReadReceipt 响应的唯一节点是 HN 至 RN 和 SN-I 至 HN-I。
下图显示了一个 ReadOnce 事务的优化 DMT 序列示例,其中 HN-F 缓存中没有请求的地址:
在此示例中,事务流程如下:
- RN-F向HN-F发出TxnID = A的ReadOnce请求。
- HN-F向SN-F发出具有以下内容的ReadNoSnp请求:
• Order = 0x01
• TxnID = B - ReturnNID 字段获取RN-F的节点ID。
- ReturnTxnID字段获取原始ReadOnce请求的TxnID。
- SN-F接受事务。
- SN-F向HN-F发出ReadReceipt。
- 当数据准备好时,SN-F使用原始TxnID将读数据发送到RN-F。
HN-F 收到 Read Receipt 后,立即取消分配请求。这种取消分配减少了 HN-F 处事务的生命周期,并释放了资源。如果这是 CHI-A,那么 HN-F 需要等待从 RN-F 收到 CompAck 响应,然后才能停止跟踪 ReadNoSnp 事务。
预取目标
为了进一步增强直接内存传输,CHI-B提供了预取目标(PrefetchTgt)请求,以减少SN-F处内存访问延迟。
PrefetchTgt消息是从RN直接发送到SN-F的提示。该请求不需要响应,因此RN不会将其作为未完成请求进行跟踪。SN-F可以选择忽略请求,或者获取指定地址的数据。
如果SN-F决定获取数据,它会将数据缓冲,直到收到该地址的正常读请求。假设在不久的将来,通过完全相干家节点HN-F的正常路径上会有一个单独的读事务。
在SN-F处对数据进行缓冲可减少读事务的内存访问延迟,并隐藏HN-F系统缓存中首先进行的本地查找的任何额外延迟。
由于不需要响应,PrefetchTgt中的TxnID字段不适用,CHI-B要求在发送请求时将其设置为0。例如,RN向SN-F发出请求。这是完成PrefectTgt事务所需的唯一步骤,双方都不会发送其他Flit。
PrefetchTgt请求可能会提前很长时间发送,以至于SN-F会将缓冲数据驱逐出去,为其他读请求腾出空间。为了避免PrefetchTgt请求造成拥塞,CHI-B使用Data Flit中的DataSource字段来报告使用PrefetchTgt的有效性。此字段由内存控制器设置,表示读取的数据是否受益于之前的PrefetchTgt提示。DataSource字段可能的值为:
• 0x6表示PrefetchTgt请求有用
• 0x7表示读取的数据未从PrefetchTgt中受益,且无效
如果足够多的PrefetchTgt请求被确定为无效,RN可以停止发出这些请求。
通常,RN只实现RN系统地址映射(RN SAM)。此SAM针对HN-F,且不知道SN-F节点ID。为了支持PrefetchTgt事务,RN也需要HN系统地址映射。HN SAM将地址转换为SN-F TgtID。
例如,PrefetchTgt提示可以优化DMT。CPU在DMT读取未命中之前发出PrefetchTgt请求。在PrefetchTgt事务之后,当DDR控制器收到读请求时,已经准备好读数据。示例中的完整流程如下:
- CPU向DDR控制器发出PrefetchTgt提示。
- DDR控制器接受提示并开始检索数据的过程。
- 两件事情并行发生:
• CPU向HN-F发出与PrefetchTgt相同地址的读请求。
• DDR控制器开始接收读数据并将其缓冲,以备后续读取。 - CPU向HN-F发出读请求
- 读请求在HN-F处导致缓存未命中。
- HN-F向DDR内存发出读请求。
- 由于数据已经在DDR控制器处缓冲,DDR立即将读取的数据返回给CPU。通过使用PrefetchTgt请求,DMT读事务在DDR内存访问中几乎没有延迟。
直接缓存传输
为了减少监听命中延迟,CHI-B使用直接缓存传输机制(DCT)。DCT类似于对监听的DMT,并允许从RN-F的监听数据绕过HN-F,直接到达原始请求者。当数据需要在请求者之间来回传输时,此机制有助于提高系统性能。
受益于DCT的用例包括信号量(semaphores)和生产者-消费者工作负载。
例如,您可以比较读请求在使用和不使用DCT的情况下读数据的路径。在没有DCT的情况下,整个系统级流程如下:
- CPU A向HN-F发出读请求。
- 该请求在HN-F处导致缓存未命中。
- HN-F向CPU B发出监听,后者持有缓存行。
- CPU B将缓存行的数据返回给HN-F。
- HN-F将数据返回给最初请求它的CPU A。
使用相同的初始事务并添加DCT,整个系统级流程进行如下优化:
- CPU A向HN-F发出读请求。
- 该请求在HN-F处导致缓存未命中。
- HN-F向CPU B发出监听,后者持有缓存行。
- CPU B绕过HN-F,直接将数据返回给发出读请求的CPU A。
通过使用DCT,监听命中的访问延迟得到降低。
转发监听请求
为了支持DCT,CHI-B添加的元素之一是转发监听请求。
转发监听请求告诉被监听的RN-F将监听数据直接发送到原始请求者。除了原子事务和独占读取外,所有可监听的读都可以使用DCT。
转发类型的监听在监听Flit中引入了新的标识符字段,如下所示:
• 转发节点ID(FwdNID),其功能类似于DMT中的ReturnNID。它保存原始请求者的节点ID。
• 转发事务ID(FwdTxnID),其功能类似于DMT中的ReturnTxnID。它保存原始读请求的TxnID。
• 返回源(RetToSrc)指示RN-F将监听数据发送到HN-F,此外还要发送给请求的RN-F。将数据发送到RN-F可以使将来针对该地址的请求在HN-F缓存中命中,并避免产生额外的监听。
在响应转发监听时,响应和数据Flit都使用新的转发状态(FwdState)字段。该字段告诉HN-F在任何本地监听过滤器跟踪中,向请求RN-F提供了什么缓存状态。
被监听的RN-F中的缓存状态,即转发监听的结果,会像往常一样在RESP字段中提供给请求RN-F。
原始请求者会在CompData消息中接收到监听数据,作为正常的读数据响应,如下图所示:
在此图中,响应包含与DMT响应相同的HomeNID和DBID字段:
• HomeNID字段包含被绕过的HN-F的节点ID
• DBID字段包含转发监听的TxnID
然后,RN-F将这些字段用作发送给HN-F的CompAck响应的TgtID和TxnID。
以下两个示例展示了当RetToSrc设置为0或1时,标识符字段如何填充。
这些示例中的系统具有:
• 两个具有节点ID 1和2(RN-F_NID1和RN-F_NID2)的RN-F
• 在两个实例中,RN-F2都在其缓存中保存了所请求的地址
• 一个具有节点ID 3的HN-F
以下图示显示了当RetToSrc = 0时,DCT的事务流程:
在此图中,事务流程如下:
- RN-F_NID1向HN-F发出ReadNotSharedDirty请求。该请求具有TxnID = A。
- 该请求在HN-F处导致缓存未命中。
- HN-F向RN-F_NID2发出SnpNotSharedDirtyFwd监听。
监听具有:
• TxnID = B
• FwdNID = 1。该值与RN-F_NID1的节点ID匹配。表示它是监听数据的目的地。
• FwdTxnID = A。该值与读请求的原始TxnID匹配。
• RetToSrc = 0 - 由于请求中的RetToSrc设置为0,RN-F_NID2使用SnpRespFwded消息回应HN-F。此响应中有两个重要字段:
• RESP显示缓存行从UC状态转移到SC状态
• FwdState告诉HN-F发送给原始请求者的缓存状态。在此示例中,即SC状态。 - RN-F_NID2向RN-F_NID1发送CompData消息,其中包括:
• TxnID = A。这是监听请求中的FwdTxnID值。
• HomeNID = 3。这是HN-F的节点ID。
• DBID = B。这是监听请求的TxnID
• RESP = SC(Shared Clean)。这显示了数据以SC状态提供,与监听响应中的FwdState字段值相匹配。 - RN-F_NID1向HN-F发送CompAck消息,TxnID = B。这完成了ReadNotSharedDirty请求。
下面的图示中的第二个示例显示了相同的ReadNotSharedDirty请求,但RetToSrc = 1:

在此图中,事务流程如下:
- RN-F_NID1向HN-F发出具有TxnID = A的ReadNotSharedDirty请求。
- 请求在HN-F处导致缓存未命中。
- HN-F向RN-F_NID2发出SnpNotSharedDirtyFwd监听。监听具有:
• TxnID = B
• FwdNID = 1
• FwdTxnID = A
• RetToSrc = 1 - RN-F_NID2使用CompData消息将缓存行转发到RN-F_NID1,其中包含以下字段:
• TxnID设置为监听中的FwdTxnID值。
• DBID设置为监听中的TxnID值。
• RESP显示返回的缓存行可以在SC状态下缓存。 - 由于RetToSrc = 1,RN-F_NID2将缓存行发送到HN-F。缓存行以SnpRespDataFwded消息发送,其中FwdState = SC(共享干净)和RESP = SC_PD(共享干净_传递脏)。RESP中的此值告诉HN-F,缓存行在RN-F2处于SC状态,且RN-F2将该缓存行的回写责任传递给HN-F。
- 收到监听数据后,RN-F_NID1向HN-F发送带有TxnID = B的CompAck响应。
9. 原子操作
为了支持Armv8.1架构中添加的原子指令,CHI-B提供了原子事务。互连使用原子事务将原子操作及其操作数从一个设备传输到另一个设备。使用原子操作而不是独占访问可以减少其他代理无法访问数据的时间。
原子事务可以执行多个原子操作,并且可以在处理器内部或外部执行。
本节介绍原子事务的基本概念。未来的导论将包含有关原子操作的更详细信息。
原子操作是在没有另一个请求者干扰的情况下执行的读-修改-写序列。与AXI中的独占访问一样,原子事务允许请求者修改内存的特定区域的数据,同时确保其他请求者的写入不会破坏数据。
在AXI3和4以及CHI-A中,请求者获取数据,执行操作,然后将结果写回以完成原子访问。CHI-B包含将原子操作传输到互连的选项,这允许操作更靠近数据所在位置执行。这提高了效率,减少了数据对其他请求者不可访问的时间。
为了执行原子操作,目标需要一个算术逻辑单元(ALU)。也就是说,要使用原子操作,HN、SN或两者都需要一个ALU。来自CHI-B的原子事务支持是可选的,因此HN和SN并不总是需要具有ALU。请求者有一个配置引脚BROADCASTATOMIC,可以用于在下游系统不支持原子事务时阻止请求者生成原子事务。
完整的原子事务结构是:
• 请求者向互连发出原子事务
• HN或SN具有ALU,因此它执行原子操作
• 根据操作,互连可能将地址的原始数据返回给请求者
10. RAS特性
CHI-B添加了可靠性、可用性和可维护性(RAS)特性,以支持Armv8 RAS规范。RAS特性有助于错误检测和系统调试,并在以下列表中进行描述:
• 数据损坏和数据检查表示数据已损坏
• 追踪标记功能用于性能分析和调试
数据损坏和数据检查
典型的系统只能检测到多位错误,而无法纠正。这就是为什么多位错误通常被称为不可纠正的错误。相比之下,许多系统可以纠正单位错误。
Arm RAS规范允许在不立即引发异常的情况下,将不可纠正的错误从生产者传播到消费者。为了允许传递损坏的数据,CHI-B包含了数据损坏和数据检查的RAS特性。这两个特性都表明数据在系统的某个点已经损坏。
CHI-B允许数据包中Poison、Datacheck和RespErr字段之间的互操作性。有关在这些RAS特性之间进行转换的更多信息,请参阅CHI Issue B Architecture Specification。
将数据标记为已损坏,并不立即表示发生了错误,这使得数据可以在系统中传播,直到数据被消耗。推迟错误指示意味着系统不必在每次检测到不可纠正的错误时引发异常。相反,可以将Poison字段分配给与相应缓存行一起的缓存。这允许系统访问和使用未损坏的数据。
数据损坏以64位粒度进行操作,这意味着数据包中的Poison字段为每64位数据设置一个位,以表示它已损坏。例如,一个256位数据字段将具有一个4位宽的Poison字段。
数据损坏必须对数据的有效部分进行准确处理。如果一个64位的数据Flit无效,那么该Flit的Poison将返回一个不关心值。
在发生以下情况之一时,损坏的数据被认为已消耗:
• 数据用于计算
• 数据传播到不支持数据损坏的组件。因为这个组件不能使用Poison字段,所以它将停止跟踪被损坏的数据。为了跟踪该数据,系统必须得到一个异常。
数据检查特性为数据字段提供奇偶校验保护。实现可以在互连的各个点测试DataCheck字段以查找损坏的数据。DataCheck以8位粒度操作,因此DataCheck字段中的每个位对应于数据字段中的一个字节。
追踪标记
CHI-B包含TraceTag字段以帮助调试和性能分析。TraceTag的宽度只有1位,并且该字段被添加到每个通道。
如果Flit中的TraceTag字段被设置,它表示向系统指示该Flit被标记为追踪目的。事务中的所有后续Flit也必须设置TraceTag。这包括从原始请求生成的所有新事务。
例如,如果从RN-F到HN-F的请求中设置了TraceTag,那么从HN-F到SN-F的读请求也必须设置TraceTag字段。
请求节点可以在初始请求中设置TraceTag,或者可以在互连的中间点设置TraceTag。例如,可以对互连的观察点进行编程,以在HN-F处为地址A的请求设置TraceTag。这个编程为HN-F处发出的任何针对地址A的Flit设置TraceTag,但从RN到HN-F的初始请求可能没有设置TraceTag。
例如,初始TraceTag在互连中设置,然后为后续Flit设置。互连被编程以跟踪MakeUnique请求。
事务流程如下:
- 1. 请求节点0向主节点发出地址A的MakeUnique请求,如下图所示:
图10-1:请求节点发出MakeUnique请求

- 2. 互连在由MakeUnique请求生成的监听和监听响应中设置TraceTag。
- 3. 请求节点2向主节点3发送地址A的ReadShared请求。从ReadShared生成的监听没有设置TraceTag。这一步如下图所示:
图10-2:请求节点2的请求

- 4. HN-F向请求节点0发送完成信号。完成信号已设置TraceTag。
在此示例中,MakeUnique和ReadShared都针对地址A,但是只有在主节点3看到MakeUnique请求后才设置了TraceTag字段。为ReadShared请求生成的所有Flit都未被标记为追踪。
11. 协议迭代和扩展
本节介绍了从CHI A版到C版的变化,并提供了一些新增功能的示例。
从CHI-A到CHI-B的变化
以下表格描述了在CHI-B中所做的添加
| CHI-B新增 |
描述 |
| MESI协议支持 |
CHI-B增加了对MESI一致性协议的支持。这支持不使用Owned或Shared Dirty缓存状态的RN-F以及简化的Snoop过滤器。此更改添加了新的操作码ReadNotSharedDirty和SnpNotSharedDirty,它们保证数据不会以SharedDirty状态返回。SNP Flit还添加了字段DoNotGoToSD,以确保被监听的RN-F不会使缓存行处于SharedDirty状态。 |
| SharedClean状态返回 |
CHI-B增加了以Shared Clean状态返回缓存行的功能。HN-F可以通过在非转发类型的Snoops中使用RetToSrc字段来请求Shared Clean状态的缓存行副本。如果多个RN-Fs持有缓存行,HN-F仅为一个被监听的RN-F设置RetToSrc字段。这鼓励系统缓存中存在更多共享数据,而不仅仅是在CPU缓存中。这有助于减小监听RN-F以获取缓存行副本时存在的延迟。 |
| WriteDataCancel操作码允许取消写请求 |
此操作码在Data Flit上发布,仅适用于三种事务:WriteUniquePtl、WriteUniquePtlStash和WriteNoSnpPtl。为避免死锁情况,CHI-A允许系统中的一个RN使用Streaming Ordered WriteUniques Optimization(WUO)。使用WriteDataCancel操作码,可以在多个RN使用WUO时打破死锁情况。当使用WriteDataCancel时:• 为完成事务,仍必须发送所有响应和Data Flit。• 必须发送具有清零的Data和BE字段的WriteDataCancel消息 |
| CleanSharedPersist |
为了将缓存行清理到持久性点,Armv8.2中添加了DC CVAP指令。有关持久性点的更多信息,请参阅Armv8-A架构配置文件的Arm架构参考手册Armv8。为支持Persistent Memory Transactions,添加了CleanSharedPersist操作码。执行DC CVAP指令会生成一个CleanSharedPersist事务。对持久性内存的支持是可选的,由配置输入引脚BROADCASTPERSIST指示:• 如果BROADCASTPERSIST = 1,可以向下游发布CleanSharedPersist事务。• 如果BROADCASTPERSIST = 0,请求方必须将CleanSharedPersist事务转换为CleanShared事务 |
| CMO传播到SN |
可以将Cache Maintenance Operations从HN传播到SN。这允许SN支持HN下游的缓存。可以通过支持可选的BROADCASTCACHEMAINTENANCE、BROADCASTINNER和BROADCASTOUTER信号来控制CMO传播。当所有这些信号都存在且未触发时,CleanShared,CleanInvalid和MakeInvalid事务不会向下游发出。 |
| DVM增强 |
虚拟机标识符字段从8位扩展到16位。为支持此增强功能,SNP Flit中添加了VMIDExt字段以传输额外的8位(VMID[15:8])。此字段在DVM Snoops的第一部分中填充,第二部分中设置为0。VMID[15:8]在DVM请求的第二部分中传输,填充数据字段的位63:56。 |
以下功能在CHI-B中已弃用
• 屏障事务和内部及外部共享域。由DMB或DSB指令生成的所有屏障事务必须在内核内终止。CHI-B互连不支持屏障,因此RN不应向外部发出它们。
• 内部和外部共享域。请求仅标记为可Snoop或不可Snoop。由于仅支持两种类型,Request Flit的SnpAttr字段从2位减少到1位。
从CHI-B到CHI-C的变化
以下表格描述了在CHI-C中添加的内容
| CHI-C新增 |
描述 |
| CompAck响应更早发送 |
CHI-C中的RN在接收到第一个数据Flit后可以发出CompAck消息。以前,RN需要等待所有读数据Flit到达后才能发出CompAck响应。 |
| 数据Flit操作码字段宽度增加 |
数据Flit的操作码字段大小从3位增加到4位。这使得数据Flit宽度比CHI-B多1位。更宽的操作码字段需要支持新的数据消息DataSepResp。由于数据Flit增加了1位,CHI-C设备与CHI-B设备不直接兼容 |
| 合并写数据和CompAck |
CHI-C添加了一条新消息NCBWrDataCompAck,允许将CompAck响应与WriteUnique事务的写数据一起发送。 |
| 将读的响应和数据分开 |
读事务可以接收完成和读数据的独立响应。为支持此功能,添加了两个新消息:• 在RSP通道上发送的RespSepData消息。此消息表示读已达到序列化点。HN将此消息发送给RN。此消息缩短了HN处的读请求寿命,因为RN可以在无序读后立即发送CompAck响应。从RN到HN的有序读有几个限制:◦ RN必须在发送CompAck给HN的有序读之前至少等待一个DAT Flit。◦ HN不得发送ReadReceipt响应,因为RespSepData消息充当ReadReceipt。• 在数据通道上发送的DataSepResp消息。这是仅发送读数据的数据消息。此消息可以由HN或SN发送,具体取决于是否使用DMT。 |
读事务示例
读序列使用ReadNoSnpSep请求,该请求旨在与数据内存传输(DMT)一起使用,并从HN发送到SN。当SN看到此请求时,它知道要使用DataSepResp消息将读数据返回给RN
独立响应和数据读序列可用于大多数读类型。此新序列的例外情况是
• 原子事务
• 排他访问
• 需要排序且无完成确认的ReadNoSnp或任何ReadOnce变体
以下两个示例演示了使用独立响应和数据消息的读序列。
第一个示例显示了SN-F单独发送数据。第二个示例显示了HN-F执行相同操作。
在这两种情况下,系统由以下部分组成:
• 一个RN-F,RN-F_NID1
• 一个HN-F,HN-F_NID2
• 一个SN-F,SN-F_NID3
以下图表显示了当响应来自HN,数据来自SN时的完整事务流程:
在此图表中,事务流程如下:
- RN-F向HN-F发出具有TxnID = A的ReadNotShareDirty请求。
- HN-F向SN-F发出ReadNoSnpSep请求,表明它不应向RN-F发送CompData响应。这意味着SN-F需要使用DataSepResp消息返回读取的数据,并将Order字段设置为1。这类似于优化的DMT序列。
- HN-F对请求进行序列化。
- HN-F向RN-F发出RespSepData消息。TxnID与原始请求的TxnID匹配,DBID字段与ReadNoSnpSep的TxnID匹配。
- SN-F确认请求并向HN-F发送ReadReceipt消息作为响应。
- RN-F接收到RespSepData。
- RN-F在未等待读数据的情况下向HN-F发出CompAck消息。
- 当数据可用时,SN-F使用DataSepResp消息将读数据发送给RN-F。 DataSepResp消息的TxnID,HomeNID和DBID字段与DMT序列相同。
在之前的CHI版本中,RN-F必须等到接收到ReadNotSharedDirty请求的数据后才能发送CompAck。通过使用单独的响应和数据序列,显著减少了HN-F处事务的生命周期。
在这第二个示例中,读数据通过DataSepResp消息由HN-F返回。以下图表显示了响应和数据都来自HN时的完整事务流程:
在此图表中,事务流程如下:
- RN-F向HN-F发出ReadClean请求。
- HN-F用RespSepData消息回应RN-F。
- 与前一个示例不同,HN-F向SN-F发送普通ReadNoSnp。
- RN-F接收到RespSepData响应。
- RN-F向HN-F发送CompAck消息。
- SN-F使用CompData消息将数据发送给HN-F。
- HN-F使用DataSepResp消息将数据发送给RN-F。字段值为:
• TxnID与原始请求匹配。
• HomeNID为2,是HN-F的节点ID。
• DBID字段为B。
与第一个示例一样,在接收到CompAck消息后,HN-F能够停止跟踪ReadClean请求。使用单独的响应和数据序列,HN-F在RN-F接收到数据之前收到了CompAck消息。
组合写数据和CompAck示例
CHI-C提供了一种合并了CompAck响应和写数据的消息,称为NCBWrDataCompAck,其中NCBW代表非拷贝写回。
这个新消息可以用于:
• 任何WriteUnique变体
• 流式有序WriteUnique
由于NCBWrDataCompAck传输写数据,因此必须在数据通道上发送。
在发送数据之前,RN必须等待:
• 一个DBIDResp消息
• 一个Comp响应
Comp和DBIDResp消息可以作为两个单独的响应发送,也可以作为组合的CompDBIDResp发送。
我们来看两个关于NCBWrDataCompAck如何工作的示例。第一个示例使用组合的CompDBIDResp消息,第二个示例使用单独的消息。示例系统有一个RN-F和一个HN-F。
这个例子使用组合的CompDBIDResp:
• RN-F向HN-F发送一个WriteUniqueFull请求,值为:
◦ TxnID = A
◦ ExpCompAck = 1
• HN-F发送CompDBIDResp,其中:
◦ TxnID与原始请求相同。
◦ DBID = B
• RN-F发送了结合CompAck与写数据的NCBWCompAck消息。
以下图表显示了组合CompDBIDResp事务流程:
在第二个示例中,系统保持不变,但HN-F发送单独的Comp和DBIDResp消息。
• RN-F向HN-F发送WriteUniqueFull请求,值为:
◦ TxnID = A
◦ ExpCompAck = 1
• HN-F执行两个操作:
◦ 发送与WriteUniqueFull的TxnID匹配的Comp消息
◦ 发送DBIDResp响应,表示它可以接收写数据。TxnID与Write请求的TxnID匹配,DBID = B
• RN-F接收两个消息。
• RN-F发送具有TxnID = B的NCBWrDataCompAck消息。
以下图表显示了单独的Comp和DBIDResp事务流程: