深入解析人脸识别技术:原理、应用与未来发展

人脸识别技术:从原理到应用
- 引言
-
- 人脸识别技术的重要性和应用领域
- 人脸识别的基本原理
-
- 图像采集与预处理
- 特征提取与表征
- 数据匹配与比对
- 传统人脸识别方法
-
- 主成分分析(PCA)
- 线性判别分析(LDA)
- 小波变换在人脸识别中的应用
- 深度学习与人脸识别
-
- 卷积神经网络(CNN)的基本原理
- 深度学习在人脸检测和识别中的优势
- 人脸验证与人脸识别的区别
- 基于Python实现人脸识别参考代码
引言
人脸识别技术的重要性和应用领域
人脸识别技术在当今社会中具有重要性和广泛的应用领域。它不仅在商业和安全领域发挥着关键作用,还为各行各业带来了许多创新和便利。
在商业领域,人脸识别技术被用于市场调研和客户分析,帮助企业了解消费者的偏好和行为,从而改进产品和服务,提高客户满意度和忠诚度。此外,它还用于零售业的支付系统,实现了便捷的刷脸支付,简化了购物体验。
在安全领域,人脸识别技术被广泛应用于监控和访问控制系统。它可以识别并验证个体身份,确保只有授权人员才能进入特定区域,提高了安全性和防范能力。在执法和公共安全方面,人脸识别有助于追踪犯罪嫌疑人,加强社会治安。
此外,人脸识别技术在医疗保健领域也有应用,如用于疾病诊断和治疗计划的制定。它可以分析患者的面部特征,辅助医生进行更准确的诊断和个性化的治疗。
虽然人脸识别技术在许多领域都带来了巨大的潜力,但也需要考虑隐私和道德问题,确保其合法和透明的使用,以平衡技术创新和社会价值。
人脸识别的基本原理
图像采集与预处理
图像采集与预处理是人脸识别技术的重要步骤。在图像采集阶段,摄像头或其他设备用于捕捉人脸图像。预处理是在采集的图像上进行的一系列操作,旨在优化图像质量和准确性。以下是图像采集与预处理的一般步骤:
- 图像采集:使用合适的设备(如摄像头、手机摄像头等)来获取人脸图像。采集时需要注意光线条件和拍摄角度,以确保图像质量足够好,有助于后续的处理和分析。
- 图像质量评估:在采集后,可能需要进行图像质量评估,筛选掉低质量的图像,以减少后续处理中的噪声和误差。
- 人脸检测:使用人脸检测算法,自动定位图像中的人脸区域。这是识别的基础,确保后续处理只集中在人脸区域。
- 人脸对齐:人脸图像可能因为拍摄角度和姿势的不同而产生变化。在预处理过程中,常用的方法是对齐人脸,使得眼睛、鼻子和嘴巴等特征点在图像中的位置保持一致,从而降低后续识别的难度。
- 图像增强:对图像进行增强处理,例如去噪、对比度增强、直方图均衡化等,以改善图像质量和增强人脸特征。
- 特征提取:在预处理后,可以使用特征提取算法,将图像中的人脸特征转化为数学向量表示,便于后续的识别和比对。
特征提取与表征

特征提取与表征是指将图像中的人脸特征转化为数学向量表示的过程。在这一步骤中,采用不同的算法和技术来提取人脸的关键特征,使得这些特征能够有效地表征人脸,从而方便后续的识别和比对。常用的特征提取方法包括但不限于:
- 主成分分析(PCA):通过对数据进行降维处理,找到最能代表原始数据的主要特征。
- 线性判别分析(LDA):在降维的同时,优化类内距离和类间距离,以增强特征的区分度。
- 局部二值模式(LBP):通过对图像中的像素进行编码,捕捉局部纹理信息。
- 非负矩阵分解(NMF):将数据分解为非负的基础模式和系数,用于特征提取和表征。
这些方法可以将人脸图像转化为具有固定维度的向量,其中包含了人脸的重要特征信息。这些向量可以用于人脸识别、人脸检测、人脸表情分析等应用中,为后续任务提供更简洁、高效的数据表示。
数据匹配与比对
数据匹配与比对是一个关键的任务,常用的方法包括但不限于:
- 欧氏距离:计算向量之间的欧氏距离,越接近0表示相似度越高。
- 余弦相似度:通过计算向量之间的夹角余弦值,来衡量它们的相似程度。
- 皮尔逊相关系数:用于衡量两个变量之间的相关性,适用于特征之间相关的情况。
- 汉明距离:主要用于比较两个等长字符串之间的差异,适用于特征向量为二进制的情况。
根据具体的数据类型和应用场景,选择合适的比对方法可以提高匹配准确度和效率。比对的结果可以用于判定两个数据是否相同或相似,进而在人脸识别、指纹识别、文本相似度匹配等领域得到应用。
传统人脸识别方法
主成分分析(PCA)

主成分分析(Principal Component Analysis,简称PCA)是一种常用的降维技术,用于将高维数据转换为低维数据,同时保留最重要的特征信息。PCA的目标是找到原始数据中最具信息量的主成分,以实现数据压缩和简化。PCA的步骤如下:
- 数据标准化:对原始数据进行标准化处理,使得各个维度具有相同的重要性,避免因为不同维度的量纲差异而影响分析结果。
- 计算协方差矩阵:对标准化后的数据计算协方差矩阵,该矩阵反映了数据各个维度之间的相关性。
- 计算特征值和特征向量:通过对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征向量即为数据的主成分,特征值表示各主成分的重要性。
- 选择主成分:根据特征值的大小选择最重要的前k个主成分,其中k为降维后的维度。
- 投影数据:将原始数据投影到选定的k个主成分上,得到降维后的数据表示。
PCA在很多领域中都有广泛的应用,如图像处理、数据压缩、特征提取等。通过PCA可以将高维数据转换为低维表示,减少数据维度的同时保留了数据中的主要特征,有助于提高数据处理的效率和准确性。
线性判别分析(LDA)

线性判别分析(LDA)是一种常见的模式识别和数据降维方法,主要用于在分类任务中找到最优的投影方向,以使不同类别的数据在投影后有更好的可分性。LDA的步骤如下:
- 计算类内散度矩阵:对每个类别内部的数据计算协方差矩阵,然后将这些协方差矩阵相加,得到类内散度矩阵。
- 计算类间散度矩阵:计算各类别的均值向量,并计算类别间的协方差矩阵,然后将这些协方差矩阵相加,得到类间散度矩阵。
- 计算广义特征值问题:通过求解广义特征值问题(类内散度矩阵和类间散度矩阵的比值)来得到投影方向的特征值和特征向量。
- 选择主成分:根据特征值的大小选择最重要的前k个特征向量作为投影方向,其中k为降维后的维度。
- 投影数据:将原始数据投影到选定的k个特征向量上,得到降维后的数据表示。
LDA的目标是最大化类别间的差异,同时最小化类内的差异,从而实现更好的分类效果。LDA在许多模式识别和机器学习任务中有广泛的应用,特别适用于有监督学习的场景。
小波变换在人脸识别中的应用

小波变换在人脸识别中的应用可以通过以下方式进行展现
- 特征提取:小波变换可以将人脸图像分解成不同尺度和频率的子图像。通过对这些子图像进行小波变换,我们可以提取出图像的局部特征,例如纹理、边缘等信息。这些特征可以用于训练模型或者与数据库中的人脸特征进行比对。
- 人脸对齐:由于不同的人脸可能存在姿态、尺度和角度的差异,因此在进行人脸识别之前需要对人脸进行对齐。小波变换可以通过调整图像的尺度和角度,使得人脸在空间上具有一致的位置和大小。这种对齐操作可以提高人脸识别的准确性。
- 图像重构:小波变换可以将人脸图像分解为不同的频率分量,在重构过程中,我们可以保留感兴趣的频率分量,同时抑制噪声和不相关的分量。通过对重构后的图像进行处理和分析,可以更好地区分人脸的特征。
- 纹理分析:小波变换可以提取出人脸图像的纹理信息,例如皱纹、斑点等。这些纹理信息可以用于人脸识别任务中的纹理分析,帮助提高人脸识别的准确性和鲁棒性。
小波变换在人脸识别中的应用主要体现在特征提取、人脸对齐、图像重构和纹理分析等方面。通过利用小波变换的优势,可以提高人脸识别系统的性能和鲁棒性,实现更准确、稳定的人脸识别结果。
深度学习与人脸识别
深度学习是一种机器学习的方法,通过构建多层神经网络模型来学习和表示复杂的数据特征。在人脸识别领域,深度学习已经取得了重要的突破,成为当前最先进的人脸识别技术之一。
卷积神经网络(CNN)的基本原理
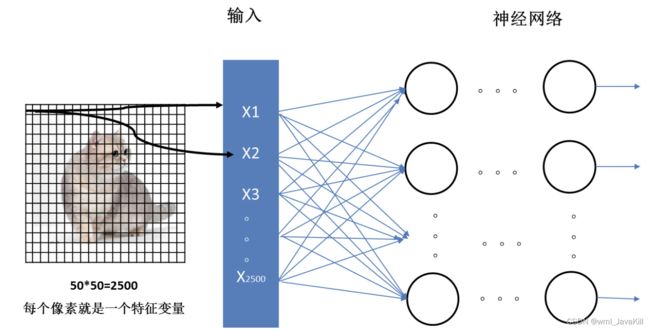
卷积神经网络(Convolutional Neural Network, CNN)是一种深度学习模型,特别适用于处理具有网格结构的数据,如图像和语音等。以下是CNN的基本原理:
- 卷积操作:CNN中最重要的操作是卷积操作。卷积操作通过滑动滤波器(也称为卷积核)在输入数据上进行局部感知,从而提取出输入数据的特征。滤波器与输入数据进行点积运算,得到特征图(也称为卷积特征)。卷积操作不仅能够捕捉局部的空间特征,还能保留特征的空间位置关系。
- 激活函数:在卷积层之后,通常会应用激活函数来引入非线性。激活函数对卷积层输出进行逐元素的非线性变换,增加网络的表达能力。常用的激活函数包括ReLU(修正线性单元)、Sigmoid和Tanh等。
- 池化操作:池化操作通过减少特征图的尺寸和参数数量,提高计算效率,并在一定程度上对输入数据的空间不变性进行建模。常见的池化操作是最大池化,在每个局部区域选择最大值作为输出。池化操作可以降低特征图的空间维度,同时保留重要的特征信息。
- 多层结构:CNN通常由多个卷积层、激活函数层和池化层交替组成。通过多层次的卷积、非线性变换和池化操作,网络可以逐渐学习到更高层次、更抽象的特征表示。深层CNN具有更强大的表达能力,可以处理更复杂的任务。
- 全连接层:在经过多层卷积和池化操作后,最后一层通常是全连接层。全连接层将前一层的所有特征图展平为一维向量,并通过矩阵乘法和激活函数产生最终的输出结果。全连接层可以对特征进行高维度的组合和映射,以便进行分类、回归或其他任务。
- 反向传播算法:CNN的训练通常使用反向传播算法来更新网络参数。反向传播通过计算损失函数关于各层参数的梯度,并沿着梯度方向对参数进行调整。这样,在大规模数据集上反复迭代训练,CNN可以学习到有效的特征表示和分类器。
深度学习在人脸检测和识别中的优势
深度学习在人脸检测和识别中具有以下几个优势
- 高准确性:深度学习模型可以通过大规模数据集进行训练,从而学习到更准确的人脸特征表示。相比传统的基于手工设计特征的方法,深度学习可以自动学习到更丰富、更抽象的特征表示,从而提高了人脸检测和识别的准确性。
- 鲁棒性:深度学习模型对于光照、表情、姿态等变化具有较强的鲁棒性。深度学习网络通过多层次的非线性变换和池化操作,可以提取出对这些变化具有不变性的人脸特征。这使得深度学习在各种复杂环境下都能够实现准确的人脸检测和识别。
- 可扩展性:深度学习模型可以通过增加网络的深度和宽度来提高性能。随着计算资源的增加,可以构建更深、更复杂的深度学习网络,从而进一步提升人脸检测和识别的能力。此外,深度学习还支持分布式训练和模型压缩等技术,可以在大规模数据和高效计算环境下进行训练和推断,具有较好的可扩展性。
- 多任务学习:深度学习模型可以同时进行人脸检测、人脸关键点定位、人脸属性分析等多个任务的学习。通过在同一个网络结构中引入多个任务的监督信号,可以有效地共享特征表示,提高模型的泛化能力和学习效率。这种多任务学习的方式使得深度学习在人脸检测和识别中更加全面和高效。
深度学习在人脸检测和识别中具有高准确性、鲁棒性、可扩展性和多任务学习的优势。这些优势使得深度学习成为当前人脸领域最主流和有效的技术手段,并在人脸识别、人脸搜索、人脸认证等场景中取得了显著的应用效果。
人脸验证与人脸识别的区别
人脸验证和人脸识别是两个不同的人脸技术应用,它们的区别主要体现在以下几个方面:
- 定义:人脸验证是通过比对输入的人脸图像与已知的人脸图像进行对比,判断它们是否属于同一个人。而人脸识别是将输入的人脸图像与一个人脸数据库中的多个人脸进行比对,从中找出最相似的人脸,并判断其身份。
- 应用场景:人脸验证通常应用于需要确认一个人身份的场景,例如手机解锁、电子支付等,只需要验证输入人脸是否匹配即可。而人脸识别则适用于需要对多人进行身份识别或者搜索的场景,例如人脸考勤、门禁系统等,需要在多个数据库中辨识出对应的身份。
- 数据库规模:人脸验证一般只需要对比输入人脸与少数几个(通常是一个)已知的人脸进行匹配,所需数据库规模较小。而人脸识别需要对比大规模的人脸数据库,其中可能包含成千上万个人的人脸信息。
- 准确性与安全性要求:由于人脸验证只需判断输入人脸与已知人脸是否匹配,因此对准确性和安全性的要求相对较低。而人脸识别则需要在大规模数据库中进行搜索和比对,对准确性和安全性的要求更高。
基于Python实现人脸识别参考代码
基于Python实现人脸识别,可以使用OpenCV和dlib这两个库来进行人脸检测和特征提取,然后使用机器学习算法(如支持向量机)对人脸特征进行分类。
import cv2
import dlib
# 加载人脸检测器和特征提取器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat') # 需要下载预训练模型
# 加载人脸识别模型
face_recognition_model = dlib.face_recognition_model_v1('dlib_face_recognition_resnet_model_v1.dat') # 需要下载预训练模型
# 加载已知人脸数据库
known_faces = [] # 存储已知人脸的特征向量
known_names = [] # 存储已知人脸的名称
def train_face_recognition():
# 读取已知人脸图像,进行特征提取
for image_path in known_images:
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
rects = detector(gray, 0)
if len(rects) == 1:
shape = predictor(gray, rects[0])
face_descriptor = face_recognition_model.compute_face_descriptor(gray, shape)
known_faces.append(face_descriptor)
known_names.append("known_name") # 替换为已知人脸的名称
def recognize_faces(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
rects = detector(gray, 0)
for rect in rects:
shape = predictor(gray, rect)
face_descriptor = face_recognition_model.compute_face_descriptor(gray, shape)
# 比对人脸特征向量
distances = []
for known_face in known_faces:
distance = np.linalg.norm(np.array(face_descriptor) - np.array(known_face))
distances.append(distance)
min_distance = min(distances)
min_distance_index = distances.index(min_distance)
# 判断识别结果是否满足阈值
if min_distance < threshold:
recognized_name = known_names[min_distance_index]
cv2.rectangle(img, (rect.left(), rect.top()), (rect.right(), rect.bottom()), (0, 255, 0), 2)
cv2.putText(img, recognized_name, (rect.left(), rect.top() - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Face Recognition', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
上述示例代码中需要使用到dlib库和相关的预训练模型,可以通过pip来安装dlib库,然后从dlib官方网站下载shape_predictor_68_face_landmarks.dat和dlib_face_recognition_resnet_model_v1.dat这两个预训练模型。