操作系统之进程管理(上),研究再多高并发,都不如啃一下操作系统进程!!!...
目录:
进程管理
-
程序运行过程
进程实体的组成
进程的组织
进程的状态与转换
进程控制
-
为什么需要原语?
原语的实现?
中断机制
进程通信
-
共享内存
管道通信
消息传递
小结
线程
-
三种线程模型
多对一模型
一对一模型
多对多模型
小结
进程调度
-
进程调度的时机
进程的切换与过程
进程调度方式
调度算法的评价指标
调度算法
进程管理
我从哪儿来?先问一个原始问题,程序是如何运行的?
先唠叨一下程序和进程的区别:
程序:是静态的,就是个存放在磁盘里的可执行文件,就是一系列的指令集合。
进程(Process):是动态的,是程序的一次执行过程,同一个程序多次执行会对应多个进程。
程序运行过程
 程序编译成机器代码
程序编译成机器代码 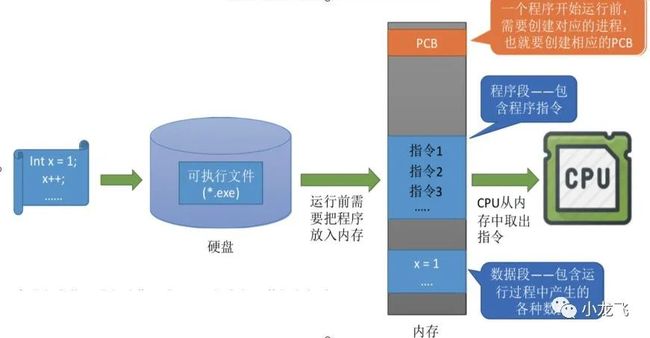 程序运行
程序运行
由图可知程序会先由编译器编译成机器指令,运行之前先把程序放入内存,在内存中创建一个进程实体。一个进程实体(进程映像)由PCB、程序段、数据段组成。然后CPU从内存中取出指令,来运行程序。
进程实体的组成
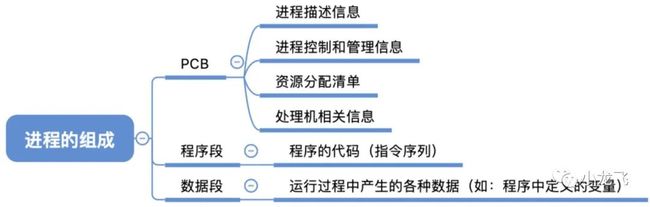 进程实体的组成
进程实体的组成
同时挂三个QQ号,会对应三个QQ 进程,它们的PCB、数据段各不相 同,但程序段的内容都是相同的 (都是运行着相同的QQ程序)
PCB 是给操作系统用的; 程序段、数据段是给进程自己用的。
引入进程实体的概念后,可把进程定义为: 进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单位
进程的组织
Linux进程使用 struct task_struct 来定义管理进程,源码字段如下:
struct task_struct {
/*
* offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long flags; /* per process flags, defined below */
int sigpending;
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
int lock_depth; /* Lock depth */
/*
* offset 32 begins here on 32-bit platforms. We keep
* all fields in a single cacheline that are needed for
* the goodness() loop in schedule().
*/
long counter;
long nice;
unsigned long policy;
struct mm_struct *mm;
int processor;
...
}
 进程组织
进程组织
Linux 把所有的进程使用双向链表连接起来。
进程的状态与转换
 进程的状态
进程的状态
创建态:进程正在被创建时,它的状态是“创建态”,在这个阶段操作系统会为进程分配资源、初始化PCB;
就绪态:当进程创建完成后,便进入“就绪态”, 处于就绪态的进程已经具备运行条件, 但由于没有空闲CPU,就暂时不能运行;
运行态:如果一个进程此时在CPU上运行,那么这个进程 处于“运行态”。CPU会执行该进程对应的程序(执行指令序列);
运行态:在进程运行的过程中,可能会请求等待某个事件的发生(如等待 某种系统资源的分配,或者等待其他进程的响应)。在这个事件发生之前,进程无法继续往下执行,此时操作系统会 让这个进程下CPU,并让它进入“阻塞态”。当CPU空闲时,又会选择另一个“就绪态”进程上CPU运行;
终止态:一个进程可以执行 exit 系统调用,请求操作系统终止该进程。此时该进程会进入“终止态”,操作系统会让该进程下CPU, 并回收内存空间等资源,最后还要回收该进程的PCB。当终止进程的工作完成之后,这个进程就彻底消失了。
 进程状态的转换
进程状态的转换
进程之间的转换, 就绪运行和阻塞三种状态之间的转换,大部分人总是记不住,其实很简答,死背硬记肯定是不行的,只需要记住下面几条,这个转换关系自己就能在脑海中画出来。
注意点:
阻塞态->就绪态 不是进程自身能控制的,是一种被动行为;(程序一直阻塞着等待获取某种资源或者信号,一旦获取了资源或者有信号通知阻塞态进程,那么他就可以变成就绪态等待CPU来执行它)运行态->阻塞态是一 种进程自身做出的主动行为;(程序运行到一半需要等待资源(临界资源、临界区等); 或者需要进行 I/O输入输出、读写内存,都是程序主动的行为)不能由阻塞态直接转换为运行态,也不能由就绪态直接转换为阻塞态(因为进入阻塞态是进程主动请求的,必然需要进程在运行时才能发出这种请求)
就绪态、阻塞态、运行态本质区别:
阻塞态:进程停止,缺必要的资源,给CPU调度机会也不能运行
就绪态:进程停止,资源都不缺,就缺CPU调度,给CPU调度就能运行
运行态:什么都不缺,正在运行的进程
进程控制
为什么需要原语?
进程控制的主要功能是对系统中的所有进程实施有效的管理,它具有创建新进程、撤销已有进程、实现进程状态转换等功能。
如何实现进程的控制?答:用“原语实现”。
 进程控制相关的原语
进程控制相关的原语  计算机系统的层次结构
计算机系统的层次结构
原语的执行具有“原子性”,一气呵成。那么,为何进程控制(状态转换)的过程要“一气呵成”?
举个栗子:假设PCB中的变量 state 表示进程当前所处状态,1表示就绪态,2表示阻塞态...
 就绪阻塞队列
就绪阻塞队列
假设此时进程2等待的事件发生了,则操作系统中,负责进程控制的内核程序至少需要做这样两件事:
将PCB 2的 state 设为 1;
将PCB 2从阻塞队列放到就绪队列;
完成了第一步后收到中断信号,那么PCB 2 的 state=1,但是它却被放在阻塞队列里,主要原因就是第一,第二步操作不是一个原子操作。
那么,这个原语厉害呀,lua脚本也可以实现这种原子操作redis,那么这个原语的原子性是怎么实现的呢?
原语的实现?
中断机制
中断机制
再说这个之前,我们有必要先了解一下中断机制。
关中断和开中断其实就是像我们生活中的开关一样。关中断是为了保护一些不能中途停止执行的程序而设计的,计算机的CPU进行的是时分复用,即每个时钟周期内,CPU只能执行一条指令。
在多道程序设计的环境下(就是我们通常所说的多个程序同时运行时),CPU是不断地交替地将这些程序的指令一条一条的分别执行,这样从宏观上看我们就感觉多个程序是在同时执行,但从微观上看则是CPU在不同的时间段(极短)内执行着不同程序的单条指令。
而CPU在这些指令之间的切换就是通过中断来实现的。关中断就是为了让CPU在一段时间内执行同一程序的多条指令而设计的,比如在出现了非常事件后又恢复正常时,CPU就会忙于恢复非常事件出现之前计算机的工作环境(通常叫做恢复现场),在恢复现场的时候,CPU是不允许被其他的程序打扰的,此时就要启动关中断,不再相应其他的请求。当现场恢复完毕后,CPU就启动开中断,其他等待着的程序的指令就开始被CPU执行,计算机恢复正常。
中断的分类这里就不列举了,感兴趣的宝宝可以自己去搜索一下。
原语实现
可以用 “关中断指令”和“开中断指令”这两个特权指令实现原子性。
正常情况:CPU每执行完一条指令都会例行检查是否有中断信号需要处理,如果有,则暂停运行当前这段程序,转而执行相应的中断处理程序。CPU执行了关中断指令之后,就不再例行 检查中断信号,直到执行开中断指令之后 才会恢复检查。
 原语实现
原语实现
以下四张图是进程创建,终止,阻塞和唤醒,切换时候的原语操作
 进程的创建
进程的创建  进程的终止
进程的终止 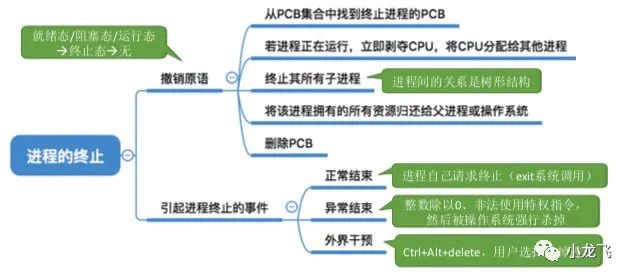 进程的阻塞和唤醒
进程的阻塞和唤醒  进程的切换
进程的切换
无论哪个进程控制原语,要做的无非三类事情:
更新PCB中的信息
所有的进程控制原语一定都会修改进程状态标志;
剥夺当前运行进程的CPU使用权必然需要保存其运行环境;
某进程开始运行前必然要恢复其运行环境;
将PCB插入合适的队列
分配/回收资源
进程通信
 进程通信
进程通信
进程通信分为共享存储,消息传递,管道通信。
顾名思义,进程通信就是指进程之间的信息交换。进程是分配系统资源的单位(包括内存地址空间),因此各进程拥有的内存地址空间相互独立。
共享内存
 内存地址空间独立
内存地址空间独立
为了保证安全,一个进程不能直接访问另一个进程的地址空间。但是进程之间的信息交换又是必须实现的。那么该怎么共享呢?如果看过我前几期分享内存管理和文件系统的,应该会有思路。
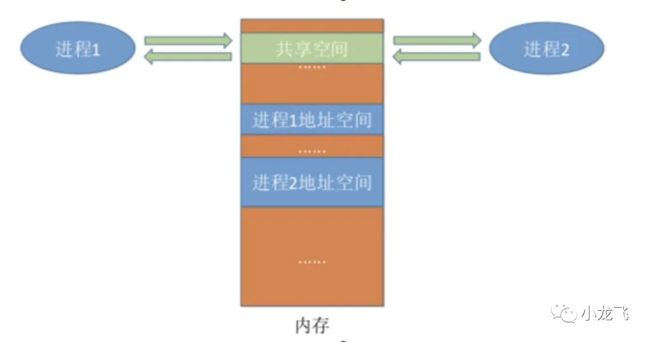 开辟共享内存
开辟共享内存
注意点:
两个进程对共享空间的访问必须是互斥的(互斥访问通过操作系统提供的工具实现)。
操作系统只负责提供共享空间 和同步互斥工具(如P、V操作)
共享存储分为两种方式:
基于数据结构的共享:比如共享空间里只能放一个长度为10的数组。这种共享方式速度慢、限制多,是一种低级通信方式;
基于存储区的共享:在内存中画出一块共享存储区,数据的形式、存放位置都由进程控制,而不是操作系统。相比之下,这种共享方式速度更快,是一种高级通信方式。
管道通信
 管道通信
管道通信
“管道”是指用于连接读写进程的一个共享文件,又名pipe 文件。其实就是在内存中开辟 一个大小固定的缓冲区。
管道只能采用半双工通信,某一时间段内只能实现单向的传输。如果要实现双向同时通信,则需要设置两个管道;
各进程要互斥地访问管道;
数据以字符流的形式写入管道,当管道写满时,写进程的write()系统调用将被阻塞,等待读进程将数据取走。当读进程将数据全部取走后,管道变空,此时读进程的read()系统调用将被阻塞;
如果没写满,就不允许读。如果没读空,就不允许写;
数据一旦被读出,就从管道中被抛弃,这就意味着读进程最多只能有一个,否则可能会有读错数据的情况。
消息传递
进程间的数据交换以格式化的消息(Message)为单位。进程通过操作系统提供的“发送消息/接收消息”两个原语进行数据交换。
消息包括消息头和消息体,消息头包括:发送进程ID、接受进程ID、消息类型、消息长 度等格式化的信息(计算机网络中发送的“报文”其实就是一种格式化的消息)。
消息直接挂到接收进程的消息缓冲队列上, 消息要先发送到中间实体(信箱)中,因此也称“信箱通信方式”。Eg:计网中的电子邮件系统。
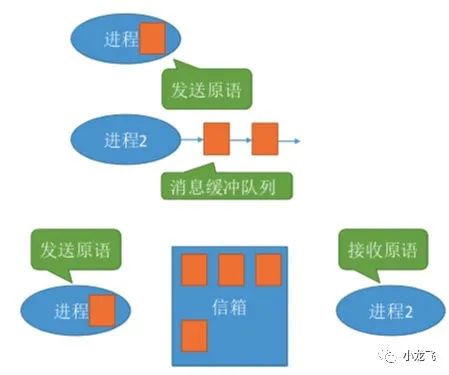 消息传递
消息传递
小结
 进程通信
进程通信
线程
 线程属性
线程属性
线程的属性又不了解的可以看看上面的图。
 线程
线程
三种线程模型
每一种线程模型的实现我们都围绕四个话题展开:
线程的管理工作由谁来完成?
线程切换是否需要CPU变态?
操作系统是否能意识到用户级线程的存在?
这种线程的实现方式有什么优点和缺点?
多对一模型
历史背景:早期的操作系统(如:早期Unix)只支持进程,不支持线程。当时的“线程”是由线程库实现的。
 早期线程实现方式
早期线程实现方式
多对一模型:多个用户级线程映射到一个内核级线程。且一个进程只被分配一个内核级线程。
线程模拟实现代码如下:
 模拟线程实现
模拟线程实现
从代码的角度看,线程其实就是一段代码逻辑。上述三段代码逻辑上可以看作三个“线程”。while 循环就是一个最弱智的“线程库”,线程库完成了对线程的管理工作(如调度)。
很多编程语言提供了强大的线程库,可以实现应用线程的创建、销毁、调度等功能。
多对一模型特点:
用户级线程由应用程序通过线程库实现,所有的线程管理工作都由应用程序负责(包括线程切换)
用户级线程中,线程切换可以在用户态下即可完成,无需操作系统干预。
在用户看来,是有多个线程。但是在操作系统内核看来,并意识不到线程的存在。“用户级线程”就是“从用户视角看能看到的线程”
优缺点
优点:用户级线程的切换在用户空间即可完成,不需要切换到核心态,线程管理的系统开销小,效率高
缺点:当一个用户级线程被阻塞后,整个进程都会被阻塞,并发度不高。多个线程不可在多核处理机上并行运行。
注意:操作系统只“看得见”内核级线程,因此只有内核级线程才是处理机分配的单位。
一对一模型
大多数现代操作系统都实现了内核级线程,如 应用 Windows、Linux。
 一对一模型
一对一模型
一对一模型: 一个用户级线程映射到一个内核态核级线程。每个用户进程有与用户级线程同数量的内核级线程。
一对一模型特点:
内核级线程的管理工作由操作系统内核完成;
线程调度、切换等工作都由内核负责,因此内核级线程的切换必然需要在核心态下才能完成;
操作系统会为每个内核级线程建立相应的 TCB(Thread Control Block,线程控制块), 通过TCB对线程进行管理。“内核级线程”就是“从操作系统内核视角看能看到的线程”;
优缺点
优点:当一个线程被阻塞后,别的线程还可以继续执行,并发能力强。多线程可在多核处理机上并行执行。
缺点:一个用户进程会占用多个内核级线程,线程切换由操作系统内核完成,需要切换到核心态,因此线程管理的成本高,开销大。
值得注意的是,一对一模型由于每创建一个用户线程就要创建一个相应的内核线程,由于创建内核线程的开销会影响应用程序的性能,所以这种模型的大多数实现限制了系统支持的线程数量。Linux,还有 Windows 操作系统的家族,都实现了一对一模型。
Java使用的就是一对一线程模型,它的一个线程对应于一个内核线程,调度完全交给操作系统来处理,所以切换线程的代价很大,线程数调参是Java工程里面重要的一个环节。
多对多模型
 多对多模型
多对多模型
多对多模型:n个用户级线程映射到m个内核级线程(n >= m)。每个用户进程对应 m 个内核级线程。
内核级线程才是处理机分配的单位。例如:多核CPU环境下,左边这个进程最多能被分配两个核。
多对多模型特点:
克服了多对一模型并发度不高的缺点(一个阻塞全体阻塞),又克服了一对一模型中一个用户进程占用太多内核级线程,开销太大的缺点;
内核级线程中可以运行任意一个有映射关系的用户级线程代码,只有两个内核级线程中正在运行的代码逻辑都阻塞时,这个进程才会阻塞;
虽然多对多模型允许开发人员创建任意多的用户线程,但是由于内核只能一次调度一个线程,所以并未增加并发性。
当一个用户线程执行阻塞系统调用时,内核可以调度另一个用户线程来执行。
区别于一对一模型,它的进程里的所有用户线程并不与内核线程一一绑定,而是可以动态绑定内核线程, 当某个内核线程因为其绑定的用户线程的阻塞操作被内核调度让出CPU时,其关联的进程中其余用户线程可以重新与其他内核线程绑定运行。
这个是GO语言这些年这么火热的基础,Go语言中的协程goroutine调度器就是采用的这种实现方案,在Go语言中一个进程可以启动成千上万个goroutine,goroutine非常轻量,一个goroutine只占几KB,并且这几KB就足够goroutine运行完,这就能在有限的内存空间内支持大量goroutine,支持了更多的并发。
 golang的GMP调度器模型
golang的GMP调度器模型
小结
 线程小结
线程小结
了解这些线程模型,对每种语言的机制,以及对那些高并发机制,优缺点,其实就会有更加深刻的理解。
进程调度
调度这个地方由于和开发比较远,不需要太深入,我这边浅浅的讲一下调度。
当有一堆任务要处理,但由于资源有限,这些事情没法同时处理。这就需要确定某种规则来决定处理这些任务的顺序,这就是“调度”研究的问题。
 进程调度
进程调度
先关注三个问题, 进程调度的时机,进程的切换与过程,进程调度方式。
进程调度的时机
进程调度(低级调度),就是按照某种算法从就绪队列中选择一个进程为其分配处理机。
 需要进行进程调度和切换的情况
需要进行进程调度和切换的情况  不能进行进程调度与切换的情况
不能进行进程调度与切换的情况
这个地方,不能调度大多数是不能被外力打断的情况下,需要原子操作,但是进程在普通临界区中是可以进行调度、切换的。
解释一下两个名词:
临界资源:一个时间段内只允许一个进程使用的资源。各进程需要互斥地访问临界资源。
临界区:访问临界资源的那段代码。
进程的切换与过程
广义的进程调度包含了选择一个进程和进程切换两个步骤。进程切换的过程主要完成了:
对原来运行进程各种数据的保存
对新的进程各种数据的恢复 (如:程序计数器、程序状态字、各种数据寄存器等处理机现场信息,这些信息一般保存在进程控制块)
进程调度方式
非剥夺调度方式,又称非抢占方式。即,只允许进程主动放弃处理机。在运行过程中即便有更紧迫的任务到达,当前进程依然会继续使用处理机,直到该进程终止或主动要求进入阻塞态。
实现简单,系统开销小但是无法及时处理紧急任务,适合于早期的批处理系统.
剥夺调度方式,又称抢占方式。当一个进程正在处理机上执行时,如果有一个更重要或更紧迫的进程需要使用处理机,则立即暂停正在执行的进程,将处理机分配给更重要紧迫的那个进程。
可以优先处理更紧急的进程,也可实现让各进程按时间片轮流执行的功能(通过时钟中 断)。适合于分时操作系统、实时操作系统.
 进程调度
进程调度
调度算法的评价指标
 进程调度算法评价指标
进程调度算法评价指标
很多指标看名称就能知道,这个地方我重点说一下CPU利用率和系统吞吐量,这两个指标也是现在很多架构并发,或者 java 垃圾回收器主要考虑的两个指标。
「CPU利用率」
CPU利用率: 指CPU “忙碌”的时间占总时间的比例。
利用率 = 忙碌的时间 / 总时间
Eg:某计算机只支持单道程序,某个作业刚开始需要在CPU上运行5秒, 再用打印机打印输出5秒,之后再执行5秒,才能结束。在此过程中, CPU利用率=(5+5)/(5+5+5)
「系统吞吐量」
对于计算机来说,希望能用尽可能少的时间处理完尽可能多的作业。系统吞吐量:单位时间内完成作业的数量
系统吞吐量= 总共完成了多少道作业 / 总共花了多少时间
Eg:某计算机系统处理完10道作业,共花费100秒,则系统吞吐量为? 10/100 = 0.1 道/秒.
没有最好的调度算法,只有最合适的算法,实际应用中取什么算法,主要根据自身场景是更加追求响应时间,还是系统吞吐量。
例如:垃圾回收器中,CMS是响应时间有优先,以获取最小停顿时间为目的,为了减少STW,牺牲了一定的吞吐量。在一些对响应时间有很高要求的应用或网站中,用户程序不能有长时间的停顿,CMS 可以用于此场景;UseParalleGC+UseParalleoldGC 垃圾回收器是吞吐量优先,但是需要长时间的STW。
调度算法
Tips:各种调度算法的学习思路
算法思想
算法规则
这种调度算法是用于作业调度还是进程调度?
抢占式?非抢占式?
优点和缺点
是否会导致饥饿
「适合早起批处理系统」
 进程调度算法
进程调度算法
这几种算法主要关心对用户的公平性、平均周转时间、平均等待时间等评价系统整体性能的指标,但是不关心“响应时间”,也并不区分任务的紧急程度,因此对于用户来说,交互性很糟糕。因此这三种算法一般适合用于早期的批处理系统,当然,FCFS算法也常结合其他的算法使用,在现在也扮演着很重要的角色。
「适合交互式系统」
 进程调度算法
进程调度算法
比起早期的批处理操作系统来说,由于计算机造价大幅降低,因此之后出现的交互式操作系统(包括 分时操作系统、实时操作系统等)更注重系统的响应时间、公平性、平衡性等指标。而这几种算法恰好也能较好地满足交互式系统的需求。因此这三种算法适合用于交互式系统。(比如UNIX使用的就是多级反馈队列调度算法)
具体的算法这里不展开,如果后期宝宝们反馈多的话再考虑展开。
这个是上篇,下一篇着重讲进程同步互斥,下一篇的目录预告如下:
 进程同步互斥
进程同步互斥
有收获的欢迎点赞,分享,在看,喜欢的话可以关注我公主号,文章首发均在这~~~
❝往期推荐:
❞
1.操作系统之内存管理,高能预警!!!
2.操作系统之文件管理,一切皆文件!!!
3.一文弄懂什么是DevOps,妈妈语气讲解