阿里巴巴java开发手册笔记
目录
1、java修饰符访问权限...
2、http与socket的区别...
3、java深拷贝与浅拷贝...
4、java equals与hashcode.
5、hashmap底层原理...
6、Java序列化作用...
7、POJO类介绍...
8、集合转数组、数组转集合注意事项...
9、foreach循环里不要进行元素的remove/add操作...
10、java ArrayList的sublist()方法...
11、几种集合类的区别...
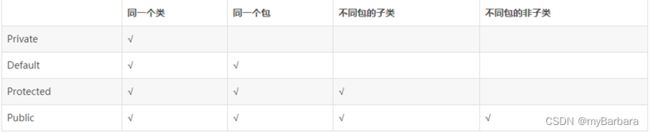
1、java修饰符访问权限
Default是包权限。Protected权限比default宽泛。
2、http与socket的区别
Http是应用层的协议,是基于tcp/ip协议的,它规范了数据传输的格式。而soceket就是tcp/ip的封装,socket建立连接直接就是建立tcp连接。可以说,http的实现是基于socket的。
3、java深拷贝与浅拷贝
浅拷贝是会将对象的每个属性进行依次复制,但是当对象的属性值是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
深拷贝复制变量值,对于引用数据,则递归至基本类型后,再复制。深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
因此慎用 Object 的 clone 方法来拷贝对象。 因为对象的 clone 方法默认是浅拷贝,若想实现深拷贝需要重写 clone 方法实现域对象的 深度遍历式拷贝。
参考博客Java浅拷贝和深拷贝_狂奔的蜗牛已被占用的博客-CSDN博客_java浅拷贝
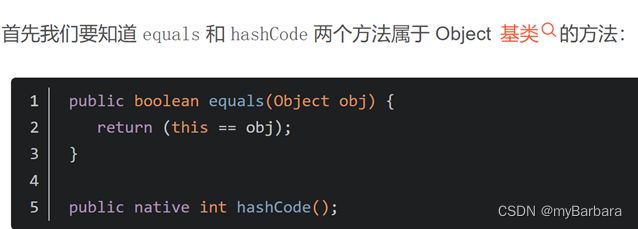
4、java equals与hashcode
equals与hashcode都是Object类的方法。Object源码中,equals方法比较的是地址(equals就是用==实现的),hashcode返回的是对象的内存地址。但在java中,所有引用数据类型都重写了equals方法,使之比较的是内容是否相同,比如String就重写了equals方法。因此自己在定义新的引用类型时,要注意是否要重写equals方法,不重写比较的就是地址。
equals与==:
对于基本数据类型,==比较的是值;对于引用类型,==比较的是地址。
对于引用类型,==比较的是地址,未经重写的equals比较的也是地址。重写后的equals比较两个对象内容是否相同。
hashCode 方法的作用和意义?
我们可简单认为hashcode方法返回的是元素的存储地址。(其实集合内部还做了进一步的运算,以保证尽可能的均匀分布)。比如set在判断重复时,怎么判断一个元素是否已经存在容器中了呢?容器已经很大了,这时不可能用equals一个个比较。而是先调用Hashcode判断该位置是否有元素,没有就代表无重复,如果该位置已经有元素,那再调用equals方法判断两个元素是否相同。
在 Java 中 hashCode 的存在主要是用于提高容器查找和存储的快捷性,如 HashSet, Hashtable,HashMap 等,hashCode是用来在散列存储结构中确定对象的存储地址的。
因此,在阿里巴巴java开发手册中规定:

参考博客:equals和hashCode详解_缘起指尖的博客-CSDN博客_equals和hashcode(写得很好)
5、hashmap底层原理
Hashmap底层是由 数组+链表/红黑树 组成的。
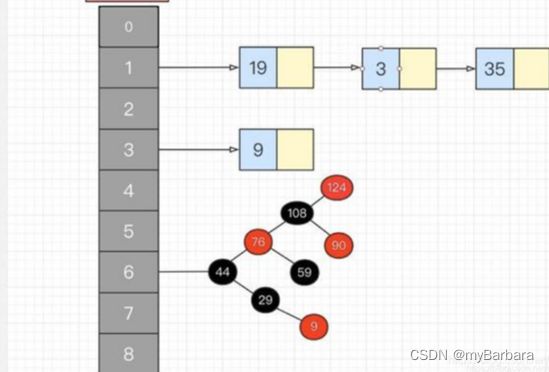
当链表长度大于8时,链表自动转为红黑树(jdk8以后)。
红黑树是一个近似平衡的二叉搜索树,因此查找效率很高,查找效率接近二分查找,为O(logn);而链表的查找效率是O(n)。
Tips:二叉搜索树的查找效率不一定与二分查找相同,因为它不平衡,比如一颗二叉搜索树只有右子树时,其查找效率就是O(n)。只有平衡的二叉搜索树,其查找效率才接近二分查找,而红黑树就是近似平衡的二叉搜索树。
红黑树除了增加元素慢一些,其他都比链表快。因为往红黑树插入一个元素时,红黑树结构会被破坏,需要调整结构使其保持红黑树特性(红黑树具体特性可查看下列博客)。
数组:查找和修改效率高,增删效率低。
链表:增删效率高,查找和修改效率低。
哈希表:结合了数组和链表的优点,增删改查效率都高。(因为查找只需查找一部分,增删是在链表上操作)
HashMap的key,需要重写hashcode和equals方法,Set的元素也要重写hashcode和equals方法。因为他们判重时根据hashcode和equals方法的。
put(k,v)方法步骤:会先调用key的hashcode方法得到哈希值,再通过哈希函数将哈希值转化为数组下标。如果数组下标上没有元素,则可以put;如果数组上有元素(链表),则调用equals方法比较链表上每一个元素的key,如果没有相同的,就put(头插法);如果有相同的,就修改对应的value。
哈希冲突:调用hashcode()生成的哈希值相同。HashMap应对哈希冲突的方法就是链地址法。
参考博客:HashMap底层实现原理解析_Qblue666的博客-CSDN博客_hashmap底层实现原理(写得很好)
6、Java序列化作用
数据持久化、实现远程通信
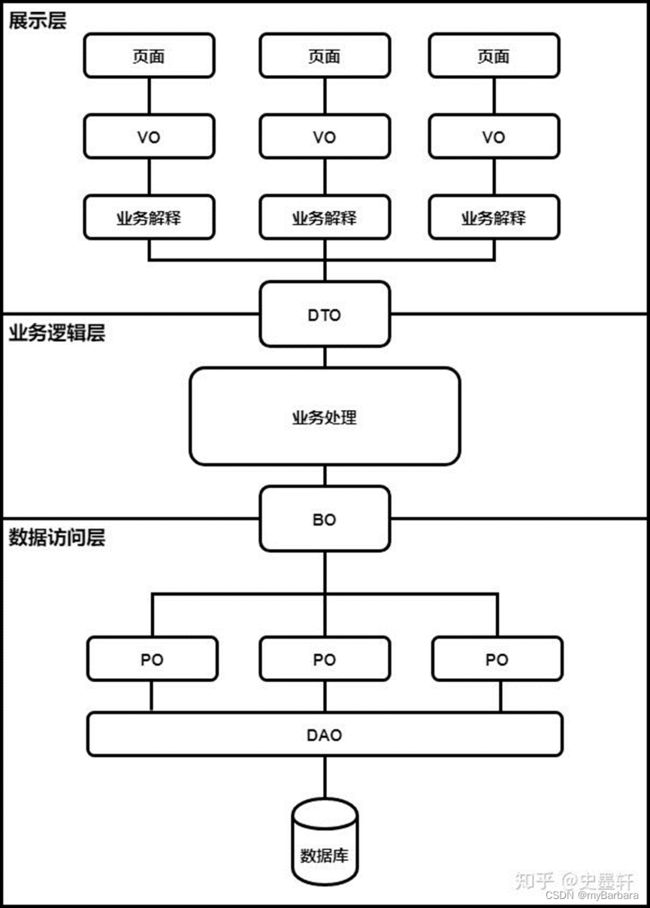
7、POJO类介绍
POJO是 DO/DTO/BO/VO 的统称。
DO(Data Object):等同于PO(Persistent Object),对应数据库中的一张表。
BO(Business Object):PO的组合,多个PO。
DTO(Data Transfer Object):这个传输通常指的前后端之间的传输对象。
VO(View Object):最后展示时用的数据。
8、集合转数组、数组转集合注意事项
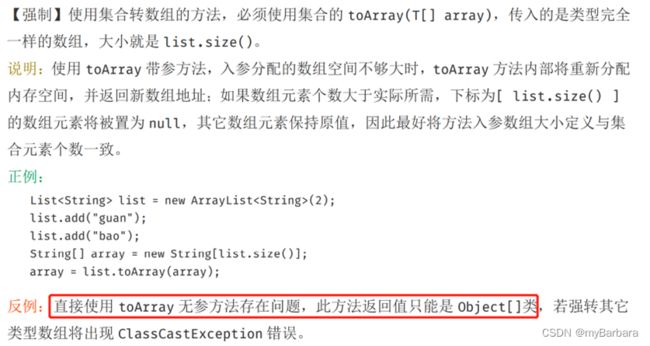

9、foreach循环里不要进行元素的remove/add操作

把”1”换成“2”后,会报错ConcurrentModificationException。因为在foreach循环中,集合遍历是通过iterator进行的,但是元素的add/remove却是直接使用集合类自己的方法,这就导致Iterator在遍历的时候会发现有一个元素在自己不知不觉的情况下被添加/删除了,就会抛出一个异常,用来提示用户可能发生了并发修改。
解决办法:
(1)直接使用普通for循环遍历
因为普通for循环并没有使用Iterator的遍历,所以压根就没有进行fail-fast的检验
(2)直接使用Iterator 遍历
直接使用iterator提供的add/remove方法,就不会再抛出这个异常了。
10、java ArrayList的sublist()方法
Arraylist的sublist方法,返回的是父list的一个视图,从fromIndex(包含),到toIndex(不包含)
父视图发生 “非结构性修改”,同时影响子视图;子视图发生 “非结构性修改”,同时影响父视图;“非结构性修改”:是指不改变集合的结构(长度),“结构性修改”:就是改变集合的结构(长度)
子视图发生 “结构性修改”,同时影响父视图;父视图发生 “结构性修改”,子视图失效(再次使用则会发生异常)
原文链接:https://blog.csdn.net/shijiujiu33/article/details/100052596
因此,在阿里巴巴java开发手册中规定:
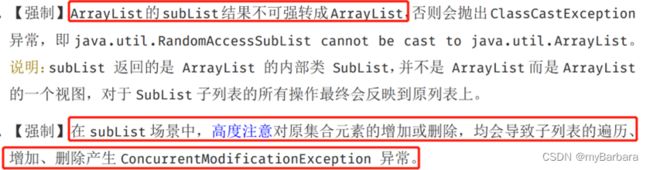
11、几种集合类的区别
ArrayList无序稳定,HashMap无序不稳定,TreeMap有序稳定
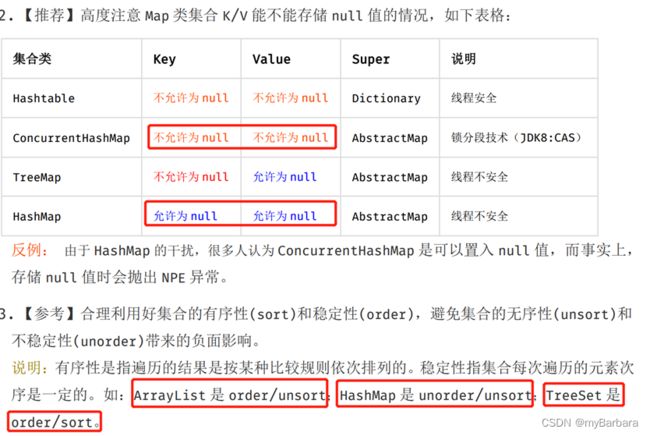
其他疑问:
18页 4 、卫语句
19页 8. 【推荐】接口入参保护
23页 10、使用 JDK8 的 Optional 类来防止 NPE 问题。
23页 12、跨应用间 RPC 调用优先考虑使用 Result 方式
26页 15、多层条件语句建议使用卫语句、策略模式、状态模式等方式重构。
对异常日志、并发处理、数据库索引这几个模块比较生疏,有较多不理解的地方。