论文阅读 A full data augmentation pipeline for small object detection based on gan
文章目录
-
- A full data augmentation pipeline for small object detection based on generative adversarial networks
-
- abstract
- 1. Introduction
- 2. Related work
- 3. Small object data augmentation
-
- 3.1. Small object generation
-
- 3.1.1. Downsampling GAN (DS-GAN)
- 3.1.2. Object segmentation
- 3.2. Small object integration
-
- 3.2.1. Position selector
- 3.2.2. Inpainting
- 3.2.3. Insertion and blending
- 4. Experiments
- 5. Conclusions
A full data augmentation pipeline for small object detection based on generative adversarial networks
abstract
小目标物体(像素大小低于32 × 32像素的物体)的目标检测准确率,落后于较大物体的准确率。为了解决这个问题,人们设计了新的架构并发布了新的数据集。尽管如此,许多数据集中小目标物体的数量还不足以进行训练。生成对抗网络(GANs)的出现为训练架构提供了一种新的数据增强可能性,而无需对小目标物体进行大规模数据标注。在本文中,我们提出了一个完整的小目标物体检测数据增强流程,将基于GAN的物体生成器与目标分割、图像修复和图像融合技术相结合,以实现高质量的合成数据。我们流程的主要组成部分是DS-GAN,一种新颖的基于GAN的架构,它可以从较大物体生成逼真的小目标物体。实验结果表明,我们的整体数据增强方法将现有最先进模型的性能在UAVDT数据集上提高了最多11.9%的AP@.5s,在iSAID数据集上提高了4.7%的AP@.5s,无论是对small objects subset还是对训练实例数量有限的场景都有效。
1. Introduction
随着大规模训练数据集的发布和卷积神经网络(CNNs)架构的持续改进,目标检测器的准确性每年都在不断取得进步。这一进步与GPU计算能力的不断增强密切相关。在这方面,小目标物体检测作为一个独立领域越来越受到关注。主要原因是许多下游任务需要尽早检测到物体以快速采取行动:例如自动驾驶汽车或无人机上的避障应用需要尽可能早地检测到远处的物体,或者卫星图像分析,其中几乎所有物体的大小都只有几个像素。也就是说,所有之前提到的应用都要求尽早识别物体,即在图像中它们几乎看不见的时候。
近期的基于CNN的目标检测器在处理小目标时通常表现不佳。检测这种小目标的问题有两个方面:(i) 在深度CNN架构中,通常情况下,特征图越深,分辨率越低,当目标非常小以至于可能在处理过程中丢失时,这是得不偿失的;(ii) 最流行的数据集,如MS COCO或ImageNet,更多地关注较大的物体。尽管为了解决第一个问题,每年都提出了新的解决方案,但解决第二个问题大多需要费时费力地生成新的数据集。
我们已经注意到,为了训练一个小目标检测器,公共数据集中需要更多的小目标。首先,包含小目标的图像相对较少会潜在地导致任何检测模型更加关注中等和大型目标。其次,小目标中稀缺的特征阻碍了模型的泛化,使其缺乏大量的变异性。最后目标越小,可能出现的位置就越多,增加了目标背景的多样性,需要更多的context variability进行训练。
此外,一些证据表明,良好的数据增强可以提升深度模型,实现最先进的性能,而无需改变网络架构。尽管数据增强已被证明可以显著提高图像分类的性能,但对于目标检测,其潜力尚未得到深入探究。因此,考虑到为目标检测标注图像所需的额外成本,数据增强可能在提高通用目标检测性能方面发挥着关键作用。
生成对抗网络(GANs)的出现为数据增强领域带来了一种新的方法。这种模型通过对抗训练的方式进行训练,其中一个网络(生成器)试图通过生成新图像来欺骗另一个网络(判别器)。生成器努力提供越来越类似于真实世界中图像的示例。
目标检测的数据增强面临两个主要挑战:(i)生成新物体和(ii)将这些物体整合到新的场景中。前者主要通过在不同位置重复使用已有的物体或通过调整它们的尺度来解决。然而,已经证明常见的尺度调整函数会导致伪影,与真实世界中的物体相比,重新缩放的物体会被明显扭曲。后者可以通过目标分割方法来处理,通过清除原始背景并在合理的位置插入物体,同时调整颜色一致性。在处理小目标时,目标分割方法的性能显著降低。此外,许多流行的数据集没有包含足够的分割ground truth数据,以适当地训练分割模型。
基于上述种种原因,本文提出了一个完整的小目标数据增强流程。我们的流程以video dataset作为输入,并返回相同的数据集,但其中包含了新的合成小目标(图1)。我们的假设是,从大量数据集中获得的较大物体的视觉特征中,可以生成高质量的合成小目标,并将其放置在现有图像中。为此,该流程包括以下几个阶段:(i)通过GAN从大物体生成小物体;(ii)通过光流寻找图像中的合理位置;(iii)通过修复和融合技术整合小物体。本文的主要贡献如下:
- 一个完整的小目标数据增强流程,能够自动地使用较大物体生成小目标,并将它们以一致的方式放置在现有背景中。
- Downsampling GAN (DS-GAN),一种生成对抗网络架构,能够将大尺寸物体转换成高质量的小目标。
- 通过在视频数据集UAVDT 和图像数据集iSAID上进行广泛的实验,我们改进了最先进方法的base results。
2. Related work
大部分略过
Image Inpainting 图像修复(Image Inpainting)是一种修复过程,通过填充受损、恶化或缺失的部分来呈现一个完整的图像。类似于图像超分辨率,生成对抗网络(GANs)的引入也为图像修复带来了更好的结果,因为判别器强制生成器在数据集内部填充连贯的数据。具体而言,Pathak等人引入了Context Encoder,它以L2像素级重建损失和生成对抗损失作为objective function,用于完成固定大小的大中心区域。最近,Yu等人提出了一种新颖的上下文注意力层,在训练过程中从远距离的空间位置借用特征,以提高最终性能。
Image blending 图像融合(Image blending)的目标是通过叠加(部分或完整)一个或多个源图像,优化空间和颜色一致性,使合成图像看起来尽可能自然。图像融合的一个特定实例是将源图像中的前景区域粘贴到目标背景的指定位置。默认的方式是从源图像中复制像素并粘贴到目标图像中,但这样会产生明显的伪影,因为在合成边界处会出现突然的强度变化。
Burt和Adelson 引入了拉普拉斯金字塔(Laplacian pyramid),这是图像的多分辨率表示方法。源图像被分解成一组band-pass滤波的组件图像,然后在每个分辨率层内独立地连接,最后将各个级别相加。因此,当粗糙特征出现在边界附近时,它们在相对较大的距离上逐渐融合,而不会模糊或降低边界附近更细的图像细节
3. Small object data augmentation
图2展示了用于小目标检测数据增强的流程的架构。该架构的目的是增加视频数据集中小目标的数量。我们的系统由两个过程组成:small object generation 和small object integration到图像中。小目标生成包括目标降采样和目标分割,而小目标融合则包括位置选择、目标修复和目标融合。

通过这些组件,系统能够从真实高分辨率(HR)目标生成相应的低分辨率(SLR)目标;这些SLR目标将具有与真实低分辨率(LR)目标类似的特征。然后,它们被插入到图像中的合理位置,而不需要在帧之间强制任何时间上的一致性。以下是应用于输入视频数据集的流程执行的步骤:
- 小目标生成过程 从HR目标中生成相应的SLR目标和它们对应的masks
- object downsampling 从HR目标及其上下文生成SLR目标
- object segmentation 计算输入HR目标的分割mask,并将其转换为适合SLR目标的mask
- 小目标融合过程选择最佳位置来插入SLR目标到图像中
- position selector选择可能存在真实低分辨率(LR)目标的位置,这些LR目标可能出现在之前或之后的帧中,通过optical flow和overlap比较LR和HR目标的方向和形状来优化位置和SLR目标的匹配
- object inpainting删除将被替换的目标
- object blending在匹配的位置上进行每个SLR目标的复制粘贴,并进行融合操作,以减轻场景中的突然边界变化和颜色强度
我们系统提供的最终结果是一个新的数据集,该数据集由相同的视频图像组成,但增加了大量的SLR目标,取代了固定数量的LR目标
3.1. Small object generation
3.1.1. Downsampling GAN (DS-GAN)
我们设计了一种降采样生成对抗网络(DS-GAN),旨在克服诸如双线性插值或nearest neighbor等众所周知的方法在获取超低分辨率(SLR)对象方面的不佳表现。DS-GAN是一种生成对抗网络,它学习将高分辨率(HR)对象正确degrade为低分辨率对象,从而增加目标检测的训练集。
在这个降采样问题中,目标是从输入的高分辨率对象估计出一个降采样因子为r的低分辨率对象。这个问题是一个unpaired问题,高分辨率对象没有相应的低分辨率对,但网络需要学习整个低分辨率子集的特征分布,同时保持原始高分辨率对象的类似视觉appearance。对于一个有C个颜色通道的图像,高分辨率对象的大小为W × H × C,而LR和SLR由W/r × H/r × C描述。因此,为了训练所提出的GAN,需要两个不同的图像集:(i)由真实大型对象(高分辨率对象)组成的高分辨率子集,以及(ii)由真实小型对象(低分辨率对象)组成的低分辨率子集。如果需要更多样本,LR和HR子集都可以来自同一个数据集或任何其他数据集。
我们的DS-GAN架构如图3所示。生成器网络(G)将一个HR图像与一个噪声向量(z)连接在一起作为输入,并生成一个比输入图像小4倍的SLR图像(r = 4)。例如,一个128×128的目标将生成一个32×32的目标。噪声向量从正态分布中随机采样,并附加到输入图像上。这允许从单个HR图像生成大量的SLR目标,因此模拟了HR图像受到多种类型的LR噪声影响的情况。我们进一步定义了一个鉴别器网络(D),并与生成器(G)一起交替优化。

generator是一个编码-解码网络,如图3所示,由六组残差块组成。每组有两个相同维度的残差块,采用了预激活和批归一化。为了实现4×的降采样,每个前四组的末尾都有四个2×的下采样步骤,采用池化层实现,而每个后两组的末尾都有两个2×的上采样步骤,采用反卷积层实现。
discriminator 如图3所示,遵循相同的残差块结构(不包含批归一化),后面跟着一个全连接层和一个sigmoid函数。鉴别器包含六个残差块和两个2×的下采样步骤。两个网络架构的详细组成如图3中所示。
通过这种架构,我们的目标是训练生成器G,在给定HR样本的条件下生成SLR样本。为了实现这一目标,我们选择了适用于adversarial loss的目标函数——hinge loss(判别器D的损失函数):

其中PLR是低分辨率(LR)子集的分布,PG是通过交替优化学习的生成器分布。PG通过sˆ = G(b, z) | b ∈ PHR来定义,其中PHR是高分辨率HR子集。该公式的基本思想是它允许通过训练G来欺骗D,而D则是被训练用于区分SLR图像和LR图像。通过这种方法,我们的生成器可以学习创建与真实LR图像非常相似的SLR样本,从而使得D难以对其进行分类。
相应地,我们通过优化损失函数L来训练G,该损失函数定义为
![]()
其中,lGadv是对抗性损失,lpixel是L2像素损失,λ是用于平衡两个组件权重的参数。
对抗性损失lGadv基于鉴别器的概率定义:

在这里,PHR是高分辨率(HR)子集,z是噪声向量。对抗性损失以无配对方式计算,使用低分辨率(LR)子集使得SLR目标受到真实世界的artefacts污染。
lpixel通过最小化输入HR图像与输出SLR图像之间的L2距离来实现:
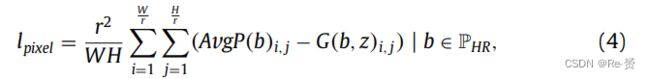
其中,W和H表示输入高分辨率(HR)图像的尺寸,r是降采样因子,AvgP是一个平均池化函数,将HR输入映射到输出G(b, z)的分辨率。lpixel以成对的方式计算,即在SLR目标和通过平均池化层降采样到输出SLR分辨率的HR目标之间进行比较。这样做的目的是确保生成的SLR目标与HR目标之间的L2距离尽可能小,从而提高生成的SLR目标的质量。
3.1.2. Object segmentation
为了将SLR目标整合到新场景中,必须将前景目标从其背景中提取出来。我们选择的目标分割方法是对Mask R-CNN框架进行调整,并在公共数据集MS COCO上进行训练,以获取来自HR目标的mask(图4)。由于小目标的分割结果表现较差,我们建议从大目标中获取掩码并调整适应小目标,只需通过缩放因子r来调整大小。这是可能的,因为像素损失(公式4)迫使生成器保持视觉目标的外观,即姿势、方向、大小等。图4展示了从HR到SLR目标的掩码适应性。
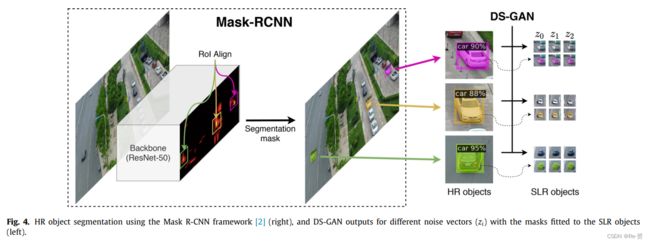
通过添加这个过程解决了三个问题:(i) pipeline的性能不受具有mask ground truth的对象的限制,而在许多流行的数据集中这些标注很昂贵;(ii) 小目标的分割被优化,因为分割方法对小目标的性能下降很严重;(iii) 不需要使用SLR对象来生成分割掩码–SLR对象没有足够的上下文来获得正确的掩码(图4)。
3.2. Small object integration
3.2.1. Position selector
在进行目标检测的数据增强时,选择图像中的位置是一个关键问题。如果此位置是随机选择的,那么围绕目标的新上下文可能会产生反效果,即背景不匹配可能导致更多的误报。这是因为检测器不仅学习目标特征,还会利用背景的prior knowledge来辅助自己。
为了根据图像背景采样合适的位置,必须满足三个前提条件:(i) 必须有一个合理的背景,例如,汽车必须放置在道路上;(ii) 方向必须适合场景 ,例如,汽车的方向必须与道路的方向相匹配;(iii) 尺度必须符合画面的消失点,例如,小物体不能放置在前景。如上所述,不需要在帧之间要求目标的时间一致性;我们只需要在画面内让目标有一个合理的空间位置。使用时间一致性将限制object-background对的数量,导致数据增强系统的效果不如预期。
为了满足这些要求,我们提出的位置选择方法基于三种技术:objects的spatial memory来获得合理的背景,, optical flow来匹配方向,overlap来匹配尺度。objects的空间记忆旨在收集在当前帧中放置SLR对象的合理位置。当前帧中LR对象的所有位置都是有效的候选位置。此外,前一帧和后一帧中的LR对象位置也是候选位置,只要它们与当前帧中的对象没有重叠。optical flow和overlap旨在将每个候选位置与最接近其方向和大小的SLR对象进行配对。我们利用optical flow来计算两帧之间对象的视觉运动(图5):(i) 我们检测FAST关键点;(ii) 通过透视变换稳定相机运动;(iii) 使用光流在ft−1和ft之间链接每个边界框内的特征点;(iv) 通过平均所有点得到ft中每个对象的运动向量的运动角度。两个对象之间的重叠通过IoU计算。

根据运动方向的角度和与HR和LR对象相关联的大小,每个可能的位置从其衍生的LR对象和每个SLR对象的原始HR对象中获得这些信息。然后,通过最大化它们之间的重叠和运动方向角度的相似性来给出每个位置和SLR对象的配对。算法展示了每个视频的位置选择器方法。

- Input:算法的输入是数据集中在每个时间 t 的帧 f 中的所有对象的总集合(GT),包括LR子集和HR子集,以及由DS-GAN生成器 G 从HR对象生成的所有SLR对象的总集合,以及搜索范围τ。
- Ouput:算法返回每个空白区域(ej)的一个SLR对象(ŝi)的association(A),ŝi 可能与多个 ej 关联。
- Spatial memory(第4至17行):给定时间 t 的帧 f,在空间记忆步骤中,可以将SLR对象(ŝi)放置在可能的空白区域(Et)中。可能的空白区域是指在时间段(ft−τ,ft+τ)中存在LR对象(sj)的位置(第4行)。对于时间段(ft−τ,ft+τ)中的每个帧ft’,算法检查LRt’对象是否与当前帧(GTt’)的任何对象或已选择的任何空白区域(Et)重叠(第9至15行)。如果没有,st’i 将添加为新的空白区域Et(第17行)。因此,每个可能的空白区域etj 对应于一个LR对象的位置(st’i)。τ 的值将受到视频数据集,更具体地说是摄像机运动的影响。摄像机运动越大,τ 的值就越小,以避免背景不匹配。如果摄像机运动过快,前后帧中的对象位置可能与图像中的错误位置相对应例如,人行道上的汽车。
- Object association 通过maximizing the motion direction和overlap来计算每个空白区域etj中最合适的ŝi。
- Optical flow:对于视频数据集中的每个ground truth LR和HR对象,通过光流计算与其运动向量相关联的角度(α)(见图5,第20和22行)。与segmentation步骤类似,可以通过其原始HR对象bi来获取ŝi的运动向量(OpticalFlow(ŝi) = OpticalFlow(bi))。考虑到SLR和LR子集,每对ŝi和sj的motion similarity由以下公式给出

- Overlap 同样,可以通过其原始HR对象bi来获取ŝi的大小(w(ŝi) = w(bi) / r; h(ŝi) = h(bi) / r)。然后,使用IoU计算ŝi和sj之间的重叠。最后,填充位置etj的第i个SLR对象将由以下公式给出:
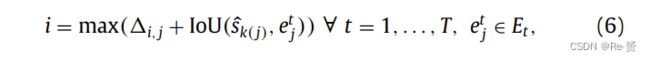
- Optical flow:对于视频数据集中的每个ground truth LR和HR对象,通过光流计算与其运动向量相关联的角度(α)(见图5,第20和22行)。与segmentation步骤类似,可以通过其原始HR对象bi来获取ŝi的运动向量(OpticalFlow(ŝi) = OpticalFlow(bi))。考虑到SLR和LR子集,每对ŝi和sj的motion similarity由以下公式给出
解释一下伪代码1 Algorithm 1: Position selector
输入:GT(Ground Truth)表示原始图像数据集中的所有对象
LR表示低分辨率对象的数据集(包含在GT中)
HR表示高分辨率对象的数据集(也包含在GT中)
SLR表示通过DS-GAN生成的所有SLR对象的数据集
Search range τ
输出:A是一个字典,其中包含了每个时间步t中SLR对象与其对应的空白区域的关联。
ŝk(i)表示选择用来填充et区域的SLR对象
et表示一个空白区域
初始化一个空集合A来存储所有时间步t中SLR对象的关联。
对于每个时间步t,初始化一个空集合Et来存储可能的空白区域。
对于时间步t的每个前后时间步t`(从max(0, t-τ)到min(T, t+τ)),检查是否有LR对象在时间步t`的位置上。如果有,将其添加到Et中。
对于Et中的每个位置,检查是否与当前帧t的GT对象重叠。如果没有重叠,将该位置添加到Et中。
然后,对于每个Et中的位置,通过光流计算其方向,同时计算与所有SLR对象的重叠度量,找到最合适的SLR对象,将该位置与该SLR对象添加到A中。
重复上述步骤,直到处理完所有时间步t。
返回A作为输出,其中包含了每个时间步t中SLR对象与其对应的空白区域的关联。
3.2.2. Inpainting
在位置选择过程中,将每个t中的stj视为一个空白区域etj,以便填充ŝi。在这些情况下,在插入新的SLR对象之前,必须通过inpainting来删除与etj相关联的stj。这确保新生成的对象具有均匀的背景混合。为此,我们使用DeepFill进行image inpainting。DeepFill是一种基于generative model-based的方法,可以利用周围图像特征合成新的图像结构。
DeepFill的输入是帧ft和对应的mask mt,返回的结果是相同的图像f’t,但empty区域已经被填充。为了生成与帧ft相关联的mask mt,我们将使用选定的LR对象stj∈Et的边界框,并将其中的像素标记为1(mt = 1)。
DeepFill生成器由两个编码器-解码器网络组成,用于两种不同的目的。第一个网络(粗糙网络)旨在进行初始的粗糙预测,而第二个网络(精细化网络)以粗糙预测为输入,并预测最终的修复结果f’t。这两个网络的原因是直观的:精细化网络看到的是一个比原始图像具有缺失区域的更完整的场景,因此它的编码器可以更好地学习特征表示。
由于LRt可能被其他对象包围,因此从图像中借用不包含对象的远程图像特征是有意义的。DeepFill通过两个并行的精细化网络编码器来解决这个问题,并将它们连接到一个单独的解码器。标准编码器专门用于通过逐层(扩张)卷积来精炼局部内容,而注意力编码器试图捕捉背景感兴趣的特征。
3.2.3. Insertion and blending
作为最后一步,该流程将通过公式(6)得到的相应SLR对象ŝi混合到之前步骤中得到的f’t inpainted image中,每个位置etj都将生成f ∗t 。首先,将分割后的对象ŝi放置在所选位置etj中。然后,需要进行blending step ,以改善颜色一致性并使对象边缘变得柔和,从而使复合图像看起来尽可能自然。我们采用了Burt和Adelson引入的拉普拉斯金字塔方法将SLR对象混合到视频帧中。
该blending方法以inpainted后的视频帧f’t、复制粘贴的图像f’'t和掩码图像m’t作为输入,用于指示混合的位置。在inpainting阶段,mt中的标记像素是边界框ground truth内的像素,但在m’t中,标记像素是SLR分割像素。算法详细描述了获取最终合成视频帧的过程

-
首先,将每个ŝtk(i)对象从eti复制粘贴到f’t中,生成临时图像f’'t (第3行)。然后,通过标记属于ŝtk(i)对象的像素,生成掩码m’t (第4行)。
-
对f’t、f’'t和m’t分别计算p级高斯金字塔 (第5-9行)。每个高斯金字塔级别是通过对前一个级别进行模糊处理和下采样得到的。
-
基于高斯金字塔,计算f’t和f’'t的拉普拉斯金字塔 (第10-13行)。每个拉普拉斯金字塔级别是通过将相应高斯金字塔级别与上采样和模糊处理的前一个级别相减得到的。拉普拉斯金字塔中的最小级别与高斯金字塔中的最小级别相同。
-
接下来,根据相应高斯金字塔级别的m’t,混合每个拉普拉斯金字塔级别 (第16行)。在此之前,掩码集合(M’t)被翻转以匹配尺寸 (第14行)。
-
最后,通过对每个级别进行上采样和模糊处理,并将其添加到下一个级别,从混合的金字塔中重构输出图像f∗t (第18-21行)。
解释一下伪代码2 Insertion and blending algorithm
输入: At表示一组包含每个空白位置et和对应SLR对象ŝk(i)的元组。其中i的范围是从1到n,表示一共有n个空白位置。
f't表示已经完成修复的图像。
p表示金字塔的级别。
输出: f∗t表示最终的合成图像。
首先,将f't(已经完成修复的图像)复制给f``t,并初始化一个空的mask m`t(用于表示哪些像素需要进行混合)。
接下来,根据金字塔的级别p,计算图像f`t、f``t和m`t的高斯金字塔(PyramidDown)。高斯金字塔是一种多尺度图像表示方法,通过逐步降采样和高斯模糊来获得不同尺度的图像。
然后,根据高斯金字塔计算图像f`t和f``t的拉普拉斯金字塔(PyramidUp)。拉普拉斯金字塔表示图像在不同尺度上的细节信息。
接着,将每个级别的拉普拉斯金字塔与相应的mask m`t进行混合操作。这里使用的是逐元素乘法和逐元素加法。
最后,通过逐级上采样和混合,得到最终的合成图像f∗t。
4. Experiments
略过
5. Conclusions
We have designed a novel a pipeline for data augmentation for small object detection. The pipeline takes a dataset as input and returns the same dataset with the images populated with annotated small synthetic objects. The proposed pipeline requires both HR and LR objects to train the DS-GAN and, also, a trained object segmentation system for HR objects. The approaches based on super-resolution through GANs also need both HR and LR objects for training [21–24]. However, our proposal has an advantage over super-resolution-based approaches, as the GAN only has to be executed during the training stage in order to generate the synthetic LR objects, so at inference time —small object detection— only the object detector has to be run. On the other hand, super-resolutionbased pipelines require both the execution of the generator of the GAN and the object detector at the inference stage.