kafka:java client使用总结塈seek() VS commitSync()的区别(三)
最近一段日子接触了kafka这个消息系统,主要为了我的开源中间件项目simplemq增加kafka支持(基于kafka-client【java】),如今总算完成,本文是对这个过程中对kafka消息系统的使用总结
线程安全
关于线程安全,kafka-client的代码注释有明确说明,
KafkaProducer是线程安全的
The producer is thread safe and sharing a single producer instance across threads will generally be faster than having multiple instances.
– from Java Comment of org.apache.kafka.clients.producer.KafkaProducer
也就是说在工程实践中,KafkaProducer实例可以使用单例模式。不需要为了发送一条消息而频繁创建KafkaProducer实例。
KafkaConsumer不是线程安全的
Multi-threaded Processing
The Kafka consumer is NOT thread-safe. All network I/O happens in the thread of the application
making the call. It is the responsibility of the user to ensure that multi-threaded access
is properly synchronized. Un-synchronized access will result in {@link ConcurrentModificationException}.
– from Java Comment of org.apache.kafka.clients.consumerKafkaConsumer
在工程实践中,如果希望对订阅的主题单独管理,那么对于订阅的每一个主题(topic)必须创建一个单独的KafkaConsumer实例负责接收消息。并且要注意对KafkaConsumer实例的多数方法也只能在消息接收线程中。
分区
KafkaConsumer.poll()方法返回拉取的消息对象迭代对象(Iterable),迭代元素类型为ConsumerRecord,从ConsumerRecord返回的字段可知包括了key,value,offset,partition,partition即为分区。
也就是说,如果topic有多个分区,那么每次摘取的一批消息可能是来自不同分区的。所以不能想当然认为每一批消息都是一个分区的。
每批次拉取的消息同一个分区的消息的消息偏移值都是连续的。即[33,34,35]这样的连续数字,
不同的分区的偏移值没有相关性
手动提交
创建KafkaConsumer实例时如果不指定enable.auto.commit参数为true,默认KafkaConsumer是自动提交的。
自动提交模式没啥好说的,不会存在重复消费和遗漏消息的问题。
如果要使用手动提交模式,调用方就要自己维护分区的偏移,以确保不会出现重复消费和遗漏消息问题。
本节讲述手动提交模式下,设计需要注意的问题
团进团出
团进团出是旅游行业的一个术语,即要求一个旅行团,整团出发入境时是多少人,返程出境时要一个不少的回来
在这里的意思就是手动提交模式下每次KafkaConsumer.poll()方法每次拉取一批消息(数量不等),处理完消息后,就要对这批消息进行手动提交处理。提交完成后,才能继续拉取下一批消息。不能在上一批消息还没有完成提交的时候,就调用KafkaConsumer.poll()方法拉取下一批消息。
所以如果你的项目中消息处理是异步的,那么一定要同步等待当前这批消息被处理完,才能再次执行KafkaConsumer.poll()方法拉取消息。
前面说过如果主题有多个分区,每批拉取的消息可能是来自不同分区的。
为方便举例,我们以如下格式表示收到的一条消息
0-100-true
消息由-号三段数字字母代表,
- 第一段数字代表分区,
- 第二段数字为偏移,
- 最后的
true/false代表该消息是否正确处理并提交确认,
为true的需要提交,
false则是因为各种原因处理失败不需要提交,希望下一轮拉取消息继续处理。
完整提交
如下面的分区0,如果一批消息中同一个分区的所有消息都被正确处理需要提交,那么它就是完整提交
[0-100-true,0-101-true,0-103-true]
如下调用 KafkaConsumer.commitSync方法就可以了。
/** 分区完整提交,提交偏移为最后一个偏移+1 */
// 分区0
TopicPartition topicPartition = new TopicPartition(topic_name, 0);
long lastTrueOffset = 103;
/** 提交的偏移指向最后偏移量的下一条记录 */
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(lastTrueOffset+1);
consumer.commitSync(Collections.singletonMap(topicPartition, offsetAndMetadata));
不完整提交
如下面的分区1,如果一批消息中同一个分区的消息有部分消息标记为false不能提交,那么它就是不完整提交。
[1-41-true,1-42-false,1-43-false,1-44-true]
对于不完整提交,我们只能从将第一个false之前的记录下次循环不用再处理,第一个false及之后的消息只能留给下次循环拉取消息再处理。如下使用seek()方法修改分区偏移
/**
* 分区不完整提交:
* 记录本轮第一个标记为false的记录之后所有提交标记为true的偏移
* 下一轮拉取消息从第一个标记为false的偏移开始
*/
// 分区1
TopicPartition topicPartition = new TopicPartition(topic_name, 1);
long firstFalseOffset =42;
consumer.seek(topicPartition,firstFalseOffset);
在不完整提交的状态下,下次执行poll()方法拉取的消息中包含上一批消息为标记为true的消息,所以还需要有机制记录上一轮拉取的消息中不完整提交中标记为true的消息,这些消息不需要再被处理,否则就会出现重复消费问题。
重复消费问题
即使如上面所说在程序中有机制记录上次不完整提交中标记为true的消息,在下次循环拉取消息后,对上次已经标记为true的消息不再被重复处理,还是无法完全避免重复消费问题。因为这只是解决当前消费者实例在当前消费循环中的重复消费问题。
在消息循环结束前最后一次拉取消息如果是不完整提交,如果这些不完整提交的数据没有持久化保存,那么在下次创建的消费者实例还是会有已经被确认消费的消息被重复消费的情况。
所以如果要完全解决重复消费问题,需要应用层对不完全提交的消息进行额外处理:
- 将确认为false的消息存储到缓冲区或持久化存储中:在处理确认为false的消息时,你可以将这些消息存储到缓冲区或持久化存储中,例如内存队列、数据库或文件系统。这样,下次启动消费者时,可以从缓冲区或存储中加载这些消息,并进行再次处理。
- 使用定时任务重新处理消息:你可以设置一个定时任务,定期检查确认为false的消息,并重新进行处理。定时任务可以根据需要从缓冲区或持久化存储中获取这些消息,并重新发送给消费者进行处理。
seek() VS commitSync()
seek()方法和commitSync()方法的作用都是通过更新分区的偏移值,控制拉取消息的位置,但这两个方法肯定是有区别的否则不可能设计两个方法干同样的事儿。
commitAsync()与commitSync()方法作用是一样的,区别在于commitAsync()是异步提交
事实上我通过输出日志的方式发现commitAsync()执行结束调用OffsetCommitCallback对象时所在线程与commitAsync()执行在同一线程,也就是说commitAsync()可能也是同步提交
我通过反复的实验,对它们的差别有了初步的判断。但并不太确定。
于是,关于seek()方法和commitSync()方法的区别我问了bito机器人,这是它的回答,证实了我的想法,与我的实验结论是一致的。
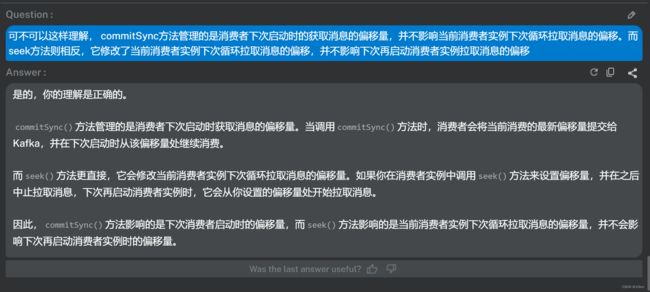
我在机器人回答的基础上再做一些示例补充就是如下完整的说明:
commitSync() 方法管理的是消费者下次启动时获取消息的偏移量。当调用 commitSync() 方法时,消费者会将当前消费的最新偏移量提交给Kafka,并在下次启动时从该偏移量处继续消费。
比如:本次poll拉取了 100,101,102三条消息,commitSync提交偏移101,那么下次一轮执行poll拉取消息会从偏移103开始,此刻如果中止拉取消息,下次再重新启动消费者时拉取偏移为101。
而 seek() 方法更直接,它会修改当前消费者实例下次循环拉取消息的偏移量。如果你在消费者实例中调用 seek() 方法来设置偏移量,并在之后中止拉取消息,下次再启动消费者实例时,它会从你设置的偏移量处开始拉取消息。
还以上例,本次poll拉取了 100,101,102三条消息,seek修改偏移101,那么下次一轮执行poll拉取消息会从偏移101开始,如果此刻中止拉取消息,下次再重新启动消费者时拉取偏移为100,因为我们没有执行commitSync将偏移量持久化。
因此, commitSync() 方法影响的是下次消费者启动时的偏移量,而 seek() 方法影响的是当前消费者实例下次循环拉取消息的偏移量,并不会影响下次再启动消费者实例时的偏移量。