One-4-All: Neural Potential Fields for Embodied Navigation 论文阅读
论文信息
题目:One-4-All: Neural Potential Fields for Embodied Navigation
作者:Sacha Morin, Miguel Saavedra-Ruiz
来源:arXiv
时间:2023
Abstract
现实世界的导航可能需要使用高维 RGB 图像进行长视野规划,这对基于端到端学习的方法提出了巨大的挑战。
目前的半参数方法通过将学习的模块与环境的拓扑记忆相结合来实现长范围导航,通常表示为先前收集的图像上的图形。
然而,在实践中使用这些图需要调整一些修剪启发法。这些启发式对于避免虚假边缘、限制运行时内存使用以及在大型环境中保持相当快速的图形查询是必要的。
我们提出了 One-4-All (O4A),这是一种利用自监督和流形学习来获得无图、端到端导航管道的方法,其中目标被指定为图像。导航是通过贪婪地最小化在图像嵌入上连续定义的势函数来实现的。我们的系统在 RGB 数据和控件的非专家探索序列上进行离线训练,并且不需要任何深度或姿势测量。

Introduction
导航问题的特点是机器人能够识别给定环境中起始姿势和目标姿势之间最有效和可行的路径。
标准方法包括首先在环境中驾驶机器人来构建度量地图(通常使用范围传感器),然后使用此表示进行规划 [1]。然而,这些方法的记忆复杂性随着环境的大小而扩展得很差,并且它们不利用语义信息或视觉线索[2]。
作为替代方案,基于学习的方法(也称为体验式学习 [3])由于能够直接处理高维数据(例如图像)并推理场景中的非几何概念而获得了发展势头。此外,这些方法对于非专业用户来说使用起来更加直观,因为它们允许使用地点或对象的图像而不是度量空间中的坐标来指定目标位置[4]。然而,端到端的体验式学习通常会学习一个将图像直接映射到动作的全局控制器,无法推理长期目标。此外,它们因数据效率低下而闻名
为了克服长视距导航的挑战,拓扑记忆表示[7]被用来将导航问题分为两部分。
首先,内存表示用于生成全局一致的导航计划,
然后使用学习的或经典的本地控制器[8]逐个航路点地跟踪该计划。
结合了基于记忆和学习的组件的方法被称为半参数,而仅依赖于学习的方法被称为全参数。
虽然半参数方法已被证明对于室内 [9]、[10]、[4]、[11] 和室外 [12]、[13] 基于图像的导航有效,但它们仍然遇到内存问题。这是拓扑记忆通常被编码为图的结果,其节点表示访问的状态,边表示可遍历性。随着环境规模的增加,图中需要更多的节点和边,从而增加内存需求。
此外,图中的虚假连接可能会阻碍导航性能,因为它们可能代表物理世界中不可行的转换,从而导致全局规划阶段的故障模式。
为了解决这些限制,我们提出了 One-4-All (O4A),一种用于图像目标导航的端到端全参数方法。
O4A 使用 RGB 数据和控件的非专家探索序列进行离线训练。
我们首先依靠自我监督学习来识别相邻的 RGB 观察值。有了这种连通性的概念,我们计算一个图来为我们的规划模块导出流形学习目标[14]、[15],我们将其称为测地线回归器。
测地线回归器将学习预测成对 RGB 图像之间的最短路径长度,从这个意义上说,对环境的几何形状进行编码并充当我们的内存模块 。虽然我们在训练期间计算临时图,但我们将其丢弃以进行导航,并发现它不需要现有半参数方法的手工图修剪启发式方法。直观上,我们用图中潜在大量的节点和边来换取固定数量的可学习参数,从而减轻半参数方法的内存限制。推理也得到了改进:图查询被神经网络中的高效前向传递所取代。
我们的主要贡献是:
• 使用 RGB 数据和控制的非专家探索序列的离线自我监督训练程序,无需任何深度或姿势测量。
• 无图、端到端的导航管道,避免调整图修剪启发法;
• 一个潜在的基于实地的规划器,由于经过多种学习目标训练的测地线吸引子,可以避免局部极小值并达到长期目标;
• 一个可解释的系统,即使在没有任何姿态信息的情况下,也可以恢复其潜在空间中的环境拓扑。
Related work
这部分就是Introduction的详细版,暂时不需要过多关注
Method
Problem Definition
我们考虑一个具有离散动作空间 A = { S T O P , F O R W A R D , R O T A T E _ R I G H T , R O T A T E _ L E F T } A = \{STOP, FORWARD, ROTATE\_RIGHT, ROTATE\_LEFT\} A={STOP,FORWARD,ROTATE_RIGHT,ROTATE_LEFT} 的机器人来执行图像目标导航任务 [31]。利用我们对机器人几何形状的了解和适当的外感受机载传感器(例如,前置激光扫描仪),我们假设可以估计一组无碰撞动作。
当提示目标图像 o g o_g og 时,智能体应仅使用 RGB 观测值 o t o_t ot 和 A f r e e A_{free} Afree 估计在部分可观察的设置中导航到目标位置。
代理还需要通过在目标附近自动调用 STOP 来确定何时达到目标
Data
我们的目标是使用深度神经网络参数化的学习模块来实现图像目标导航。对于任何给定的环境,我们假设一些先前收集的观测轨迹 τ o = { o t } t = 1 T τ_o = \{o_t\}^T_{t=1} τo={ot}t=1T 和相应的动作 τ a = { a t } t = 1 T τ_a = \{a_t\}^T_{t=1} τa={at}t=1T 可用。为了符号简洁性,我们考虑来自单一环境的单一轨迹,但实际上使用来自不同环境的多个数据轨迹(图 2)。我们不需要专家的数据收集策略,数据集可以是远程操作、自我探索或随机游走的产物,只要它充分覆盖环境的自由空间即可。
值得注意的是,我们在无监督的环境中处理导航,并且不假设可以访问每个图像观察的姿势估计,这极大地简化了数据收集。此外,我们不收集任何深度测量结果,仅在运行时依靠前置激光扫描仪进行简单的碰撞检查。
System
Overview
我们在图 2 中说明并展示了我们系统的概述。我们首先依靠自监督学习来学习与连接头配对的 RGB 主干,以推断 τ o τ_o τo 中所有图像的图形。然后,该图将用于导出正向运动学模块和测地线回归器的训练目标。

Local Backbone
本地主干学习从原始图像到低维嵌入 h : O R G B → X h : O_{RGB} → X h:ORGB→X 的映射。为了简单起见,我们将提取的特征表示为 x = h(o)。函数 h 将具有双重目的:
1)提取 X = Rn 中的低维特征,将其用作其他模块的输入;
2)学习定义为

鉴于训练数据中缺乏姿势信息,h 通过自我监督学习进行训练。我们使用经常用于训练暹罗架构的对比损失函数的变体:

方程 2 是时间对比学习的一个实例:我们知道连续观察(正对)在姿态方面确实很接近,因此鼓励其与 X 中的距离恰好为 m+ 。负数被推到至少 m− 的距离,反映了这样一个事实:即使现阶段未知它们之间的确切距离,它们也不应该共享相同的邻域。这一最新的观察激发了术语“局部度量”[15],因为实际距离 dh 仅在应用于潜在空间中接近的正对时才提供信息。应该强调的是,dh 通常无法预测负对之间的距离,因为它往往在 m− 附近饱和,如[15]中所述。
Inverse Kinematics Head
组件 f † : X × X → A ∪ { N O T _ C O N N E C T E D } f^† : X × X → A ∪ \{NOT\_CONNECTED\} f†:X×X→A∪{NOT_CONNECTED} 预测两个嵌入之间移动所需的操作,或者当认为单个操作中的转换不可行时返回 N O T _ C O N N E C T E D NOT\_CONNECTED NOT_CONNECTED 标记。因此, f † f^† f† 既充当闭环模块又充当逆运动学预测器。
它是使用 τ a τ_a τa 中观察到的动作的标准交叉熵损失进行训练的。我们使用等式 2 中的相同负数 N 来训练 NOT_CONNECTED 类。
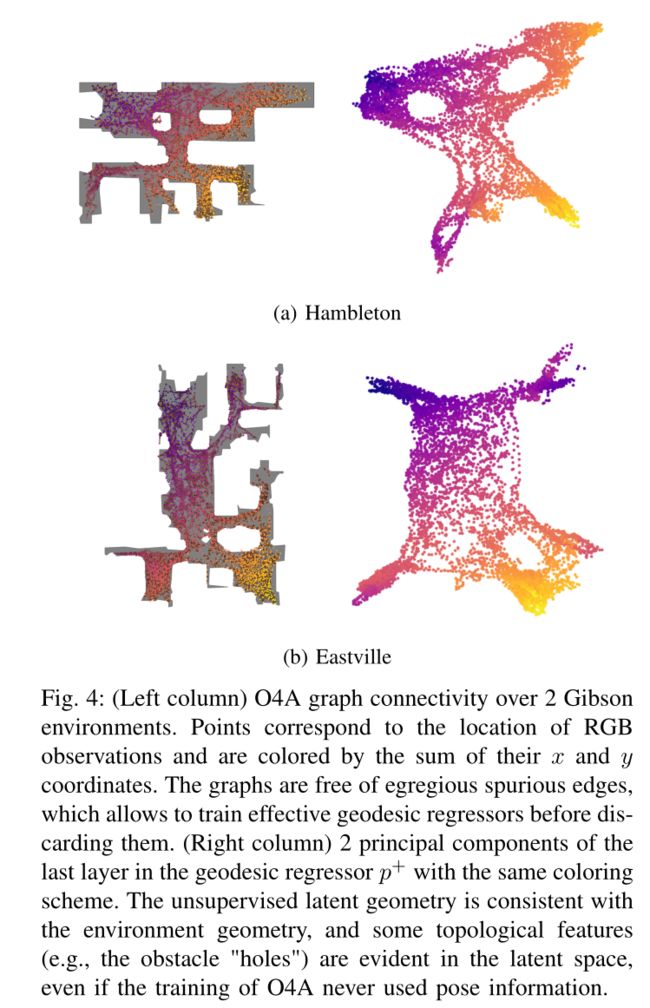
即使 N 中的大多数负例都是真负例(从某种意义上说,观察结果与一个操作步骤无法连接),h 和 f † f^† f† 在训练过程中也可能会遇到偶尔的假负例。例如,如果同一位置被访问两次,则引发的观察结果可能在时间上不连续,然后可能出现在 N 中。这些漏报实际上对应于经过训练的系统应该在数据中发现的闭环。在实践中,事实证明,假阴性并不会阻止 f † f^† f† 学习良好的连接性(图 4)。
Graph Construction
配备了 h 和 f † f^† f†,我们现在可以构建一个有向图 G,其边使用 dh 进行加权(等式 1)。我们首先将收集的数据视为具有观察到的边 E o = ( o t , o t + 1 ) : o t , o t + 1 ∈ τ o Eo = {(ot, ot+1) : ot, ot+1 ∈ τo} Eo=(ot,ot+1):ot,ot+1∈τo 的链图,然后运行成对计算以获得新的闭环边 Ep = {(ot, os ) : ot, os ε τo, f †(xt, xs) ε A}。最终的图形是 G = (τo, Eo ∪ Ep)。不需要对图进行额外的后处理,这与现有方法[9]、[10]、[12]、[26]相反,现有方法可能需要调整大量超参数来管理节点和边。
Forward Kinematrics Head
正向运动学头由 f : X × A → X f : X × A → X f:X×A→X 表示,并使用来自 G 的边/过渡进行训练。对于训练期间 G 中的任何边 ( o t , o s ) (o_t, o_s) (ot,os),使用均方误差损失来训练模块以逼近函数 ( x t , f † ( x t , x s ) ) → x s (x_t, f^†(x_t, x_s)) → x_s (xt,f†(xt,xs))→xs,使用反向运动学头 f † f^† f† 提供输入动作,即使没有观察到。因此,f 将受益于 E p E_p Ep 中最初未在 E o E_o Eo 中观察到的额外跃迁。上面是一个称为协同训练的半监督学习实例[33],其中函数 h 和 f † f^† f† 用于标记训练集中看不见的转换,从而增强用于训练 f 的监督信号。
Geodesic Regressor
最终组件和核心规划模块 p + : X × X → R + p^+ : X × X → \mathbb{R}^+ p+:X×X→R+ 学习预测 G 上的最短路径长度。我们将这些距离表示为 d G ( o t , o g ) d_G(o_t, o_g) dG(ot,og) 并使用 Dijkstra 算法计算它们。 d G d_G dG 是在来自 G 的离散顶点集的观察对上定义的。我们的目标是将其扩展到连续潜在空间 X 上,以在运行时预测任何图像对的最短路径长度。测地线回归器的训练损失为

将观测结果解释为来自嵌入高维 RGB 空间中的流形的样本,主干 h 学习局部欧几里德邻域 (dh) 的嵌入,这些邻域通过图搜索链接在一起以计算整个流形上的测地线(固有)距离。方程 3 实际上对应于流形学习目标 ,我们将在图 4 中以可解释的环境可视化形式显示 O4A 训练结果。
一旦所有组件都经过训练,G 就可以被丢弃,并且在部署系统时不再需要 G。事实上,f 和 p + p^+ p+ 都将提供图像目标导航所需的所有信息,我们将在第 IIID 小节中详细介绍。事实上,测地线回归量 p + p^+ p+ 可以解释为对 G 的几何形状进行编码,从而用潜在的大量节点和边换取固定数量的可学习参数。
Multiple Environment Setting
当考虑 k 个环境时,我们在整个数据上训练 h 和 f † f^† f†。为了给模型提供更具挑战性的任务,我们从相同环境或不同环境中采样负样本 N。然后,h 和 f † f^† f† 可用于闭环并计算一组图 { G i } i = 1 k \{G_i\}^k_{i=1} {Gi}i=1k,每个环境一个。然后使用所有图表的转换来训练正向运动学 f。最后,每个 G i G_i Gi 用于训练测地线回归器 p i + p^+_i pi+ 。总之,h、 f † f^† f† 和 f 是跨环境共享的,而 p i + p^+_i pi+ 是特定于环境的。
Navigation
在本节中,我们讨论如何部署 O4A 进行导航。我们的方法受到人工势场 (APF) 方法 [20] 的强烈启发,
该方法通过定义
A)目标周围的吸引势和
B)障碍物周围的排斥势来规划代理配置空间上的运动
从而使代理能够最小化通过梯度下降的总势函数在避开障碍物的同时达到目标。
与 APF 一样,O4A 将通过最小化位于目标处的吸引子来进行导航。
由于实际的代理和目标状态是未观察到的,因此潜在的计算发生在潜在空间 X 上,即代理和目标 RGB 观察值的嵌入。
作为吸引子,我们使用测地回归器 p+ 来估计到目标的测地距离。
至关重要的是,这种吸引子会影响环境几何形状,例如,可以将智能体驱出死胡同,到达欧几里得距离接近但测地距离较远的目标(参见图 3)。

在实践中,我们发现仅最小化 p+ 不足以成功导航。由于吸引子景观中的局部最小值,代理通常会在两个姿势之间摇摆,这可能是由于学习错误和离散动作空间而发生的。因此,我们发现定义一个潜在排斥函数很有用,该函数仅在特定半径 m r ∈ R + m_r ∈ \mathbb{R}^+ mr∈R+ 内有效:

详细的导航过程如算法 1 所示。在导航过程中,我们的智能体通过在由碰撞检测函数 γ 估计的集合 Af ree 上使用正向运动学寻找最佳候选动作,贪婪地最小化 P。这与 APF 形成鲜明对比,因为我们将引发碰撞的动作列入黑名单,而不是明确地建模障碍物周围的斥力。在实践中,由于代理在原地旋转,我们假设只有FORWARD动作才能引起碰撞,这大大简化了碰撞检测γ:我们只需根据机器人的几何形状在机器人前面定义一个扫描碰撞框。
还应该注意的是,STOP 操作从未包含在 Af ree 中。相反,我们发现对本地指标 dh 进行阈值设置是在目标附近调用 STOP 的更可靠方法。

Experiments
我们在模拟和现实环境中评估我们的方法。该代理是一个差动驱动机器人,配有两个 RGB 摄像头,一个朝前,另一个朝后,每个摄像头的视野均为 90°。每张图像的分辨率为 96×96 像素。与[34]一致,机器人向前移动0.25m,旋转15°


Conclusion
虽然经过训练的 O4A 是无图的,但我们仍然需要为每个环境学习测地线回归器来对几何进行编码(就像当前的方法需要构建特定于环境的图一样)。
跨环境推广测地线回归是一个有前途的研究领域,因为它可以允许在新设置中完全跳过图形构建阶段。此外,现实世界的实验表明,O4A 很难最大限度地减少旋转动作的数量,并且仍然存在一定数量的垃圾。我们认为,这可能是由 15° 离散旋转动作引起的:如果机器人理想情况下需要转动 7.5°,它可能会在向左和向右之间振荡,因为事实上每个步骤都是贪婪地采取行动,而不是明确地遵循一个长的动作。短期计划。进一步调整负势或具有连续动作空间的实现应该可以解决这个问题。
最后,与许多现有的导航和 SLAM 系统一样,O4A 不考虑动态或半静态对象