K8S基础篇:概念与架构
1.Kubernetes是什么
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。k8s 这个缩写是因为 k 和 s 之间有八个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。Kubernetes 建立在 Google 在大规模运行生产工作负载方面拥有十几年的经验 的基础上,结合了社区中最好的想法和实践。
Kubernetes 是Google 开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
你可以试想一下QPS为百万级别的应用(eg:电商)要部署多少节点、多少个容器服务才能扛得住这么大的并发流量?答案肯定是一个庞大的容器集群,那么随之带来的问题就是这么大容器集群怎么编排、管理、做到自动化、可伸缩部署?
对于容器编排管理技术,最具代表性的容器编排工具,当属 Docker 公司的 Compose+Swarm 组合,以及 Google 与 RedHat 公司共同主导的 Kubernetes 项目,当然今天Compose+Swarm已经无人问津了,因为和Kubernetes比起来黯然失色。
应用的部署大概经历以下几个时代:
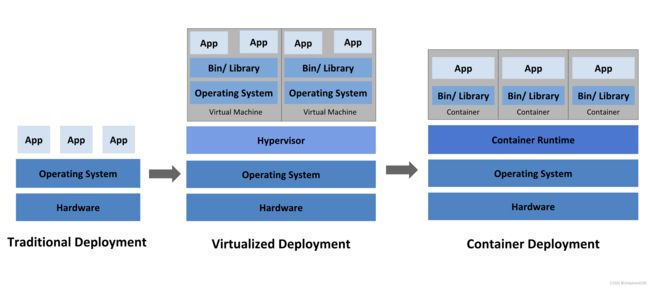
传统部署时代:
早期,各个组织机构在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。 例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降。 一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展, 并且维护许多物理服务器的成本很高。
虚拟化部署时代:
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。 虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全,因为一个应用程序的信息 不能被另一应用程序随意访问。虚拟化技术能够更好地利用物理服务器上的资源,并且因为可轻松地添加或更新应用程序 而可以实现更好的可伸缩性,降低硬件成本等等。每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器(容器是一种特殊的进程,详见再谈docker容器)类似于 VM,但是它们具有被放宽的隔离属性,可以在应用程序之间共享操作系统(OS)。 因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来。下面列出的是容器的一些好处:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
但是今天容器已经不在核心热门技术了,因为容器技术已经成熟普遍应用了,而能够定义容器组织和管理规范的“容器编排”技术,则当仁不让地坐上了容器技术领域的"头把交椅"
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记 交流探讨群:Shepherd_126
2.Kubernetes能做什么
从一开始,Kubernetes 项目就没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。而 Kubernetes 项目要着重解决的问题,则来自于google的 Borg 系统的研究人员在论文中提到的一个非常重要的观点:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 为你提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
-
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
-
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
-
自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
-
自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
-
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
3.Kubernetes架构
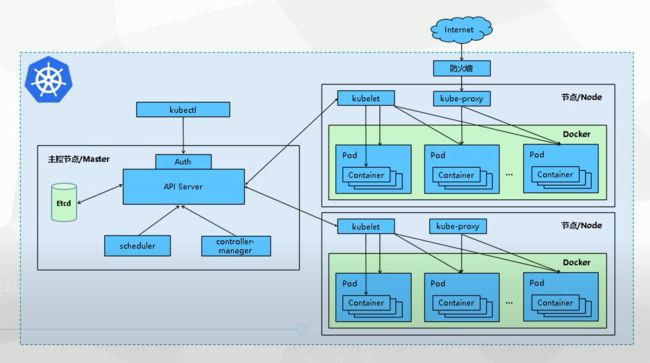
我们可以看到,Kubernetes 项目的架构,都由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
其中,控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Etcd 中。
Master 节点一般包括四个组件,apiserver、scheduler、controller-manager、etcd,他们分别的作用是什么:
-
Apiserver:上知天文下知地理,上连其余组件,下接ETCD,提供各类 api 处理、鉴权,和 Node 上的 kubelet 通信等,只有 apiserver 会连接 ETCD。
-
Controller-manager:控制各类 controller,通过控制器模式,致力于将当前状态转变为期望的状态。
-
Scheduler:调度,打分,分配资源。
-
Etcd:整个集群的数据库,也可以不部署在 Master 节点,单独搭建。
Node 节点一般也包括三个组件,docker,kube-proxy,kubelet
- Docker:具体跑应用的载体。
- Kube-proxy:主要负责网络的打通,早期利用 iptables,现在使用 ipvs技术。
- Kubelet:agent,负责管理容器的生命周期
而计算节点node上最核心的部分,则是一个叫作 kubelet 的组件。在 Kubernetes 项目中,kubelet 主要负责同容器运行时(比如 Docker 项目)打交道。而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface)的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
这也是为何,Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。而具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI 请求翻译成对 Linux 操作系统的调用(操作 Linux Namespace 和 Cgroups 等)。
此外,kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
而 kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。
在常规环境下,这些应用往往会被直接部署在同一台机器上,通过 Localhost 通信,通过本地磁盘目录交换文件。而在 Kubernetes 项目中,这些容器则会被划分为一个“Pod”,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。Pod 是 Kubernetes 项目中最基础的一个对象。
而对于另外一种更为常见的需求,比如 Web 应用与数据库之间的访问关系,Kubernetes 项目则提供了一种叫作“Service”的服务。像这样的两个应用,往往故意不部署在同一台机器上,这样即使 Web 应用所在的机器宕机了,数据库也完全不受影响。可是,我们知道,对于一个容器来说,它的 IP 地址等信息不是固定的,那么 Web 应用又怎么找到数据库容器的 Pod 呢?所以,Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个 Service 服务的主要作用,就是作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址。
这样,对于 Web 应用的 Pod 来说,它需要关心的就是数据库 Pod 的 Service 信息。不难想象,Service 后端真正代理的 Pod 的 IP 地址、端口等信息的自动更新、维护,则是 Kubernetes 项目的职责。
像这样,围绕着容器和 Pod 不断向真实的技术场景扩展,我们就能够摸索出一幅如下所示的 Kubernetes 项目核心功能的“全景图”
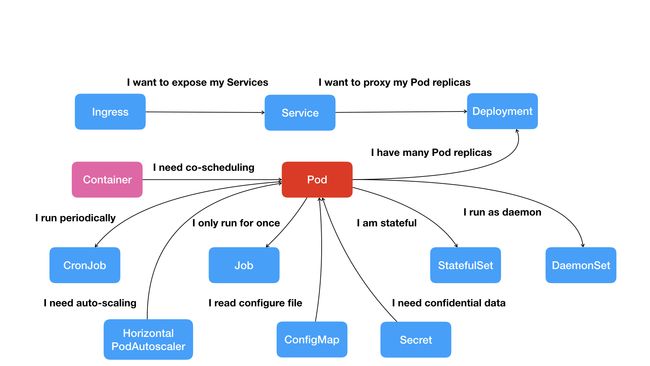
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;有了 Pod 之后,我们希望能一次启动多个应用的实例,这样就需要 Deployment 这个 Pod 的多实例管理器;而有了这样一组相同的 Pod 后,我们又需要通过一个固定的 IP 地址和端口以负载均衡的方式访问它,于是就有了 Service。
4.Kubernetes运行容器实例
-
直接使用kubectl指令
部署一个nginx服务
kubectl create -f deployment nginx --image=nginx
-
使用指令配置式
首先先编写一个配置文件:deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
然后执行下面的命令:
kubectl apply -f deploy.yaml
这样,三个完全相同的 Nginx 容器副本就被启动了。
最后说一下Kubernetes在linux中怎么部署:使用 kubeadmin,这是 k8s 社区推荐的可以部署生产级别 k8s 的工具,具体部署教程参照:kubeadm部署Kubernetes(k8s)完整版详细教程
Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具