Titanic-知识记录
current_directory = os.getcwd()
print(current_directory)
可以通过os.getcwd()获取当前工作目录的路径
pd.read_csv()和pd.read_table()的不同


pd.read_csv()和pd.read_table()都是Pandas库中用于读取文本文件的函数,但它们在默认参数和行为上有一些不同。
-
默认参数:
pd.read_csv()的默认参数为sep=',',即默认使用逗号作为列之间的分隔符。pd.read_table()的默认参数为sep='\t',即默认使用制表符作为列之间的分隔符。
-
行为:
pd.read_csv()可以处理以逗号或其他指定分隔符分隔的文本文件。pd.read_table()可以处理以制表符或其他指定分隔符分隔的文本文件。

tsv'和'.csv'的不同
.tsv(Tab-Separated Values)是使用制表符(\t)作为列分隔符的文本文件格式。.csv(Comma-Separated Values)是使用逗号(,)作为列分隔符的文本文件格式。
什么是逐块读取?为什么要逐块读取呢?
逐块读取(Chunking)是一种将大型数据集分成较小块进行逐个读取和处理的技术。它是处理大型数据集时常用的一种策略。
逐块读取的原理是将数据分割成多个较小的部分,每次读取和处理其中一部分,而不是一次性读取整个数据集。这样做的目的有几个原因:
-
内存效率:对于大型数据集,一次性加载整个数据集可能会导致内存不足的问题。逐块读取可以将数据集分成较小的块,每次只加载一部分数据到内存中,减少内存的占用。
-
提高性能:逐块读取可以提高数据处理的效率。处理大型数据集时,一次性读取整个数据集可能需要较长的加载时间。而逐块读取可以在读取和处理每个块时并行执行操作,从而减少整体处理时间。
-
处理数据流:某些情况下,数据可能以流的形式不断产生,而不是一次性存在于文件或内存中。逐块读取可以处理这种数据流,逐个读取和处理到达的数据块。
在实际应用中,逐块读取可以通过迭代器或分块读取方法来实现。Pandas库中的read_csv()函数可以使用chunksize参数来指定逐块读取的块大小,并返回一个可迭代的数据块对象。每个数据块都可以按需处理,以减少内存占用和提高性能。
chunker(数据块)是什么类型?用for循环打印出来出处具体的样子是什么?
chunker(或数据块对象)是一个可迭代的对象
for chunk in chunker:
print(chunk)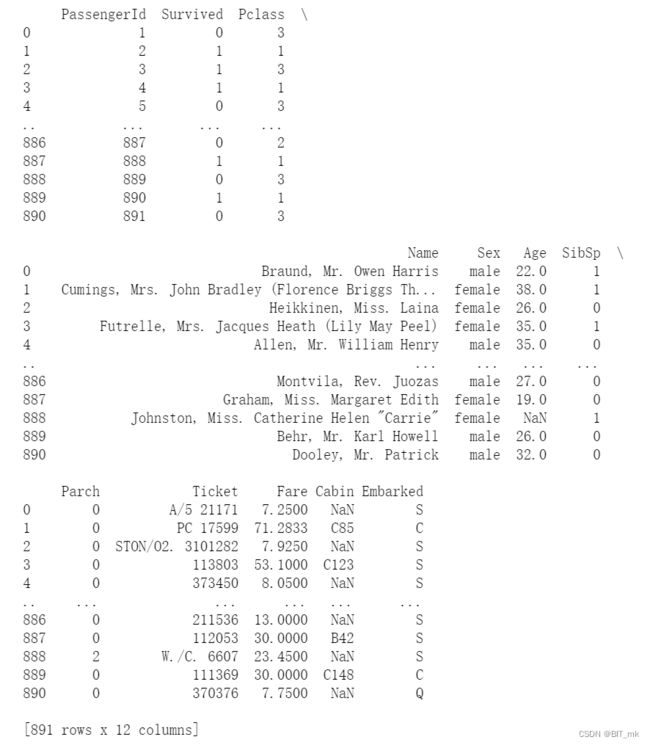
header参数
header参数是pd.read_csv()函数中的一个可选参数,用于指定哪一行作为列名行。
header参数可以取以下值:
None:表示没有列名行。数据将被解析为列索引的整数序列。0:表示第一行是列名行。- 整数值(如
n):表示第n行是列名行。 - 列名列表:传入一个字符串列表作为列名。列表的长度应与数据的列数相匹配。
df.head()
df.head()是一个Pandas DataFrame对象的方法,用于显示DataFrame的前几行数据,默认显示前5行。

dataframe对象
DataFrame对象是Pandas库中的一种数据结构,它提供了一种二维的、标记的数据结构,类似于表格或电子表格的形式。
DataFrame由行和列组成,每一列可以包含不同的数据类型(例如数值、字符串、布尔值等)。它类似于一个二维的表格,每列有一个唯一的列名,每行有一个唯一的索引。
DataFrame的主要特点包括:
-
标签索引:DataFrame的行和列都可以使用标签进行索引,可以通过标签轻松访问和操作数据。
-
灵活的数据操作:DataFrame提供了多种方法来操作和处理数据,包括数据筛选、切片、分组、合并等功能。
-
处理缺失值:DataFrame内置了处理缺失值的方法,可以轻松地处理和填充缺失的数据。
-
数据对齐:DataFrame可以根据行和列的索引自动对齐数据,使数据的操作更加方便和准确。
-
丰富的功能和工具:Pandas库为DataFrame提供了许多功能和工具,例如统计分析、数据可视化、数据导入和导出等。
DataFrame对象是Pandas库中最常用的数据结构之一,它提供了方便且高效的方式来处理和分析结构化数据。可以通过pd.DataFrame()函数创建DataFrame对象,也可以通过读取外部文件(如CSV、Excel等)获得DataFrame对象。
df.info()
查看数据信息

df.isnull().head()判断是否为空值

保存数据
df.to_csv('train_chinese.csv')series
Series是Pandas库中的一种数据结构,它是一维标记的数组,类似于带有标签的列表。
Series由两部分组成:索引(index)和值(values)。索引是一组标签,用于唯一标识Series中的每个元素,而值则是相应的数据。
Series的主要特点包括:
-
一维结构:Series是一维的数据结构,类似于一个带有索引的数组。
-
标签索引:每个值都有一个与之关联的索引标签,通过索引可以快速定位和访问对应的值。
-
不同数据类型:Series可以包含不同的数据类型,如整数、浮点数、字符串、布尔值等。
-
向量化操作:Series支持向量化操作,可以对整个Series进行快速的数值计算和操作。
-
缺失值处理:Series提供了对缺失值的处理方法,例如通过NaN(Not a Number)表示缺失值。
-
自动对齐数据:在进行数据操作时,Series会自动根据索引对齐数据,使得操作更加方便和准确。
可以使用pd.Series()函数创建Series对象,传递一个列表或数组作为数据,并可以选择性地指定索引。此外,许多Pandas函数和操作返回的结果也是Series对象。
dataframe和series的例子

查询每列的名称

查询船票信息这列的值--两种方式

删除多余列的方式
-
使用
del关键字:可以使用del关键字直接从DataFrame中删除列。例如:del test_1['a'] test_1.head(3) -
使用
pop()方法:pop()方法可以删除指定列,并返回删除的列作为一个Series对象。例如:removed_col = df.pop('列名') -
使用
drop()函数并指定columns参数:可以使用drop()函数来删除多个列,通过指定columns参数传递要删除的列名列表。例如:df = df.drop(columns=['列名1', '列名2', ...]) -
使用布尔索引:可以通过布尔索引选择要保留的列,而忽略其他列。例如:
columns_to_keep = ['列名1', '列名2', ...] df = df[columns_to_keep]
将['PassengerId','Name','Age','Ticket']这几个列元素隐藏,只观察其他几个列元素
df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
axis参数的作用
在Pandas中,axis参数可以取两个值:
-
axis=0:表示沿着行的方向进行操作。当指定axis=0时,drop()方法将删除指定的行。 -
axis=1:表示沿着列的方向进行操作。当指定axis=1时,drop()方法将删除指定的列。
如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了
df.drop(['PassengerId','Name','Age','Ticket'], axis=1, inplace=True)
在这种情况下,原始的DataFrame将被修改,删除了指定的列,不再包含这些列。这样可以避免创建新的DataFrame对象,节省内存空间。
需要注意的是,使用inplace=True参数时要谨慎,因为就地修改是不可逆的,无法恢复到原始数据结构。因此,在使用inplace=True时,建议在操作前确保对数据结构的修改是正确和符合预期的。
以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。

以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = df[(df['Age'] > 10) & (df['Age'] < 50)]
将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage = midage.reset_index(drop=True)
-
midage.reset_index():reset_index()方法用于重置DataFrame对象的索引。它会创建一个新的DataFrame对象,其中包含原始DateFrame的值,并为每个值分配一个默认的整数索引,并将原来的索引作为新的列添加到DataFrame中。 -
drop=True:drop=True参数是reset_index()方法的一个可选参数,用于指定是否丢弃原来的索引列。当设置为True时,将丢弃原来的索引列,仅保留新的整数索引列。如果设置为False,则保留原来的索引列作为新的列。

使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.loc[[100,105,108],['Pclass','Name','Sex']] 
使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.iloc[[100,105,108],[3,4,5]]
对比iloc和loc的异同
异同点如下:
-
索引类型:
iloc使用基于整数的位置索引,通过传递整数索引值来选择数据。例如,df.iloc[0]选择第一行的数据。loc使用基于标签的索引,通过传递标签值来选择数据。例如,df.loc[0]选择标签索引为0的行的数据。
-
索引范围:
iloc使用基于0的整数索引范围,可以使用切片或整数列表来选择多个连续或不连续的行或列。例如,df.iloc[1:5]选择索引为1到4的行。loc使用基于标签的索引范围,可以使用切片或标签列表来选择多个连续或不连续的行或列。例如,df.loc[1:5]选择标签索引为1到5的行。
-
用法:
iloc主要用于基于位置进行选择和索引,适用于对行和列进行数值索引的情况。loc主要用于基于标签进行选择和索引,适用于对行和列进行标签索引的情况。
数据清洗简述
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的样子。
缺失值观察
(1) 请查看每个特征缺失值个数
df.info()
df.isnull().sum()
(2) 请查看Age, Cabin, Embarked列的数据 以上方式都有多种方式,所以建议大家学习的时候多多益善
df[['Age', 'Cabin', 'Embarked']].head(3)
对缺失值进行处理
(1)处理缺失值一般有几种思路


检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
在Pandas中,np.nan和None都用于表示缺失值。对于检索空缺值,一般使用.isnull()方法。
-
np.nan是NumPy库中定义的特殊值,用于表示缺失值或不可用值。它通常在Pandas中被用作缺失值的标识。可以使用np.isnan()函数来检测np.nan值。 -
None是Python中的空值对象,常用于表示缺失值或未知值。在Pandas中,当将Python的None值用于Series或DataFrame时,Pandas会自动将其转换为np.nan。 -
.isnull()方法是Pandas的DataFrame和Series对象的方法,用于检测缺失值。它返回一个布尔值的DataFrame或Series,指示哪些元素是缺失值(为True)。
通常情况下,推荐使用.isnull()方法来检索缺失值,原因如下:
-
一致性:
.isnull()方法适用于Pandas的DataFrame和Series对象,提供了一致的方式来检测缺失值,无论是使用np.nan还是None表示。 -
灵活性:
.isnull()方法可以与其他Pandas函数和方法(如过滤、填充等)结合使用,方便进行数据清洗和处理。 -
兼容性:
.isnull()方法可以检测多种类型的缺失值,包括np.nan和由None转换的np.nan。
如果某个特定方式无法找到缺失值,可能是因为以下原因:
-
当使用其他方式(如直接比较等)时,可能无法正确处理
np.nan值或None值,导致无法准确检测缺失值。 -
在特定情况下,数据中的缺失值可能以其他形式表示,而不是
np.nan或None。这可能导致使用.isnull()方法时无法找到缺失值。
在读取数值列的数据后,空缺值的数据类型通常会被解析为float64。在这种情况下,使用None进行索引可能无法准确地找到缺失值,因为None通常被解析为object类型。
相比之下,使用np.nan作为缺失值的表示更加适用于数值列,因为np.nan是专门用来表示缺失值的浮点数。在处理数值数据时,通常使用np.nan来标记缺失值,并进行相应的缺失值处理操作。
当使用np.nan时,可以使用.isnull()方法来检测缺失值。.isnull()方法会正确地识别出np.nan值,并返回一个布尔值的DataFrame或Series,指示哪些元素是缺失值(为True)。
df.dropna().head(3)使用dropna()方法删除包含缺失值的行
dropna()
-
axis:指定删除的轴方向。默认值为0,表示删除包含缺失值的行;设置为1表示删除包含缺失值的列。 -
how:指定删除的方式。可选值包括:'any':如果行或列中存在任何缺失值,则删除。'all':只有当行或列中的所有元素都是缺失值时才删除。
-
subset:指定需要进行缺失值检查的列或行的子集。可以传递一个列名或多个列名组成的列表。默认值为None,表示检查所有列或行。 -
thresh:指定每行或每列至少要包含的非缺失值数量。当非缺失值数量低于该阈值时,对应的行或列将被删除。 -
inplace:指定是否对原始DataFrame进行就地修改。默认值为False,表示返回一个新的DataFrame对象;设置为True时,将就地修改原始DataFrame。
import pandas as pd
# 创建DataFrame对象
data = {'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)
# 删除包含缺失值的行
df.dropna(axis=0, how='any', subset=['A', 'B'], inplace=True)
print(df)
df.fillna(0).head(3)
fillna(0):fillna()方法用于填充缺失值。在这个例子中,使用参数0表示将缺失值填充为0。
fillna()
-
value:指定用于填充缺失值的值。可以是一个具体的数值、字符串、字典或Series对象。常见的取值包括数字(如0、1)、字符串(如'Unknown')或列的平均值等。 -
method:指定用于填充缺失值的方法。常用的取值包括:'pad'或'ffill':使用前一个非缺失值进行前向填充。'backfill'或'bfill':使用后一个非缺失值进行后向填充。
-
axis:指定填充的轴方向。默认为0,表示沿着索引的垂直方向(按列填充)。设置为1时,表示沿着列的水平方向(按行填充)。 -
inplace:指定是否对原始DataFrame进行就地修改。默认为False,表示返回一个新的填充后的DataFrame对象;设置为True时,将就地修改原始DataFrame。 -
limit:指定在连续缺失值的情况下,要填充的最大连续缺失值数量。
import pandas as pd
# 创建含有缺失值的DataFrame
data = {'A': [1, None, 3, None, 5],
'B': [None, 'x', 'y', None, 'z']}
df = pd.DataFrame(data)
# 填充缺失值为0
filled_df = df.fillna(0)
# 使用前向填充方法填充缺失值
ffilled_df = df.fillna(method='ffill')
# 沿着行的方向,使用前一个非缺失值进行填充
filled_df_along_axis = df.fillna(method='ffill', axis=1)
print(filled_df)
print(ffilled_df)
print(filled_df_along_axis)
查看数据中的重复值
df[df.duplicated()]duplicated()方法用于检测DataFrame中的重复行。默认情况下,它会检查所有列,并将重复的行标记为True,非重复的行标记为False。

对整个行有重复值的清理
df = df.drop_duplicates()
df.head()
特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
分箱操作,也称为离散化或区间划分,是将连续的数值数据分割成离散的区间或箱子的过程。它将连续的数值范围划分为不同的间隔或区间,将数据映射到相应的区间中。
分箱的主要目的是将连续的数值数据转化为离散的分类变量,以便更好地理解和分析数据。通过将数据分组到不同的箱子中,可以发现数据的分布特征、提取统计信息,并减少数据的噪声和复杂性。
在分箱操作中,需要选
择适当的分箱策略和方法。常见的分箱方法包括等宽分箱和等频分箱:
-
等宽分箱(等距分箱):将数据范围均匀地划分为固定数量的箱子,每个箱子的宽度相等。这种方法适用于数据分布均匀的情况,但可能无法准确地捕捉到数据的分布特征。
-
等频分箱:将数据分为具有相同数量观测值的箱子,以确保每个箱子内的观测数量大致相等。这种方法适用于处理数据分布不均匀的情况,可以更好地捕捉到数据的分布特征。
df['AgeBand'] = pd.cut(df['Age'], 5, labels=[1, 2, 3, 4, 5])

pd.cut()
-
x:要进行分箱操作的数据。可以是一维的Series对象或NumPy数组。 -
bins:指定分箱的方式。可以传递整数、序列或标量。常见的取值包括:- 整数:表示要将数据划分为等宽的指定数量的箱子。
- 序列:表示要使用自定义的箱子边界,序列中的值指定每个箱子的边界。
- 标量:表示要使用指定的算法来计算箱子的数量和边界。
-
labels:指定分箱后每个箱子的标签。可以是一个列表或数组,用于标识每个分箱区间的名称或类别。 -
right:指定分箱区间的闭合方式。默认为True,表示右闭合(包含右边界),False表示左闭合(不包含右边界)。 -
include_lowest:指定是否将最小值包含在第一个箱子中。默认为False,表示不包含最小值。 -
precision:指定分箱边界的精度。默认为0,表示保留整数精度。
import pandas as pd
data = [1, 3, 5, 2, 4, 6, 8, 7, 9, 10]
bins = [0, 3, 6, 9, 10]
# 执行分箱操作
result = pd.cut(data, bins, labels=['Low', 'Medium', 'High', 'Very High'])
print(result)


对文本变量进行转换
(1) 查看文本变量名及种类
series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
value_counts()是Pandas中的一个函数,用于计算一个Series中每个唯一值的频数。它返回一个新的Series对象,其中索引是唯一值,而值是对应的频数。
series:要计算频数的Series对象。
参数:
-
normalize:默认为False。如果设置为True,则返回频数的相对频率,而不是绝对频数。 -
sort:默认为True。如果设置为True,则按频数进行排序。如果设置为False,则不进行排序。 -
ascending:默认为False。如果设置为True,则按频数升序排序。如果设置为False,则按频数降序排序。 -
bins:仅适用于数值数据。如果指定了bins参数,则将数值数据分箱,并计算每个箱子的频数。 -
dropna:默认为True。如果设置为True,则排除缺失值(NaN)并计算非缺失值的频数。如果设置为False,则包括缺失值并计算缺失值的频数。


unique()获取包含唯一值的数组,nunique()获取包含唯一值的个数
将类别文本转换为数字
方法一:

方法二:
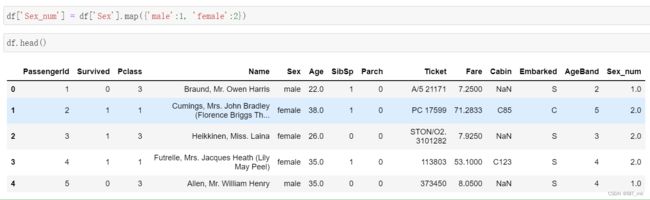
方法三 :
map()方法
series.map(arg, na_action=None)
-
arg:可以是一个字典、函数或可迭代对象。用于指定映射关系或转换规则。- 字典:将字典的键作为原始值,字典的值作为映射结果。
- 函数:将函数应用于每个元素,并将结果作为映射结果。
- 可迭代对象:根据可迭代对象中的顺序依次映射每个元素。
-
na_action:可选参数,用于指定处理缺失值(NaN)的方式。默认为None,表示保留缺失值。可设置为ignore,表示忽略缺失值。
df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))
astype() 是 Pandas 中的一个方法,用于将 Series 或 DataFrame 中的数据转换为指定的数据类型。
lbl.fit_transform()
fit_transform() 是 LabelEncoder 类中的一个方法,用于对数据进行拟合(fit)和转换(transform)的组合操作。它常用于将分类特征转换为数值编码。


将类别文本转换为one-hot编码
for feat in ['Age', 'Embarked']:
x = pd.get_dummies(df[feat], prefix=feat)
df = pd.concat([df, x], axis=1)
df.head()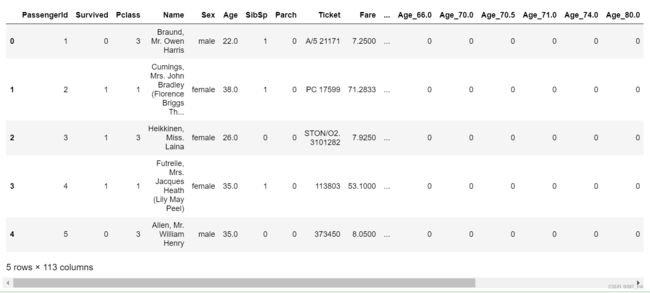
从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)

使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()
使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result
list_down = [text_left_down, text_right_down]
result_down = pd.concat(list_down, axis=1)
result_down.head()result = pd.concat([result_up, result_down], axis=0)
result.head()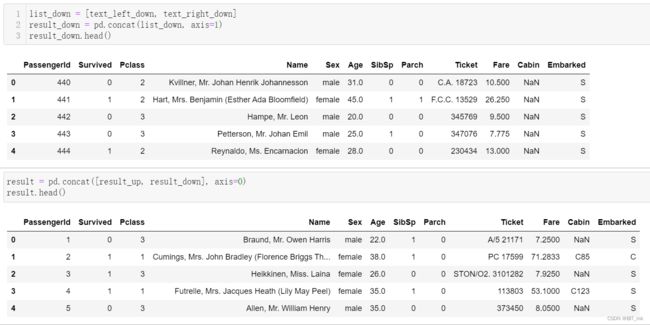
使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务

使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()
left_on和right_on:可选参数,表示左右 DataFrame 中用于合并的列名。当左右DataFrame 中的列名不同时,可以使用这两个参数指定各自的列名。left_index和right_index:可选参数,默认为 False,表示是否使用索引进行合并。如果设置为 True,则表示使用索引进行合并,而不使用列名。
将我们的数据变为Series类型的数据
unit_result=text.stack().head(20)
unit_result.head()DataFrame.stack() 函数,它用于将 DataFrame 进行堆叠操作,将列标签转换为行索引,生成一个多层次索引的 Series。
import pandas as pd
data = {'Name': ['John', 'Alice', 'Bob'],
'Age': [25, 30, 22],
'City': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
# 将 DataFrame 进行堆叠操作
stacked_series = df.stack()
print(stacked_series)
输出结果:
0 Name John
Age 25
City New York
1 Name Alice
Age 30
City London
2 Name Bob
Age 22
City Paris
dtype: object
groupby机制:和SQL里group by的机制一样
计算泰坦尼克号男性与女性的平均票价
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means统计泰坦尼克号中男女的存活人数
survived_sex = text['Survived'].groupby(text['Sex']).sum()
survived_sex计算客舱不同等级的存活人数
survived_pclass = text['Survived'].groupby(text['Pclass']).sum()
survived_pclassagg()
在 Pandas 中,agg() 函数用于对 DataFrame 或 Series 进行聚合计算,它允许你同时应用多个聚合函数(如求和、均值、最大值、最小值等)来对数据进行汇总或统计。
这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。
text.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns=
{'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
统计在不同等级的票中的不同年龄的船票花费的平均值
text.groupby(['Pclass','Age'])['Fare'].mean().head()
得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
survived_age = text['Survived'].groupby(text['Age']).sum().head()
找出存活人数最多的年龄段
survived_age[survived_age.values==survived_age.max()] survived_age.values==survived_age.max():这部分代码执行一个比较操作,检查 survived_age 中的每个值是否等于存活人数最多的年龄段的幸存者的年龄。返回的结果是一个布尔类型的数组,其中值为 True 表示对应位置的年龄与存活人数最多的年龄相同,值为 False 表示不相同。
_sum = text['Survived'].sum()
print("sum of person:"+str(_sum))
precetn =survived_age.max()/_sum
print("最大存活率:"+str(precetn))